一、时间复杂度和空间复杂度
(一)时间复杂度
- 之前学过很多次,但都搞的不是很清楚
- 时间复杂度:用来评估算法运行效率的一个式子,也就是评估算法相对运行时间,不同的代码时间复杂度不同,如简单的输入一行代码是O(1),一层for循环是O(n),三层for循环是n的三次方


但这时可能有人问如果输入三行是不是就是3,其实不是这样的
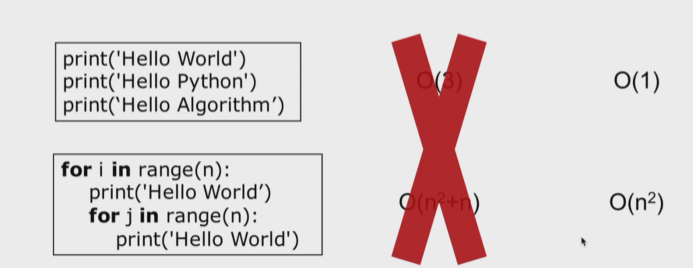
- 因为在计算机的高速运行状态下,我们的时间复杂度是一个大概的量级,向O(3)就约等于O(1),而n2+n就约等于n2

- 有时候我们会遇到题目让我们判断算法复杂度,这时我们有可以根据情况进行判断

(二)空间复杂度
空间复杂度和时间复杂度主要思维相似,用来评估算法对内存占用的大小
一般在算法中习惯用“空间换时间”

二、查找算法
- 这次主要学了顺序查找和二分查找

(一)顺序查找
- 顺序查找也叫线性查找,从列表第一个元素开始,顺序进行搜索,直到找到元素或搜索到列表的最后一个元素为止,就是暴力查找,一个一个查,知道查到或者查完了也没有就截止
- 附代码

(二)二分查找
- 二分查找就是利用排序好的列表,从中间进行分割,取low和high以及中间值mid,每次将查找数据和中间值相对比,如果小于中间值就说明查找的值就在前半段,也就是low和mid中间,如果大于同理在后半段,然后不断的取中间值不断的比较,当mid=查找的元素或者列表走完的时候,查找结束。
- 附代码
def binary_search(li,val):
left=0
right=len(li)-1
while left<=right:
mid=(right+left)//2
if li[mid]==val:
return mid
elif li[mid]<=val:
left=mid+1
elif li[mid]>=val:
right=mid-1
else:
return None
三、排序
- 本次主要讲6种排序,分别是三种相对较慢的排序:冒泡排序,选择排序,插入排序。
- 三种相对较快的排序:快速排序,堆排序,归并排序

(一)冒泡排序
- 冒泡排序就是从列表第一个数开始,将每两个相邻的数进行对比,如果前面比后面大,就交换这两个数,每当一趟排序后,最大的数就到了最后面,也就是有序区,无序区就减少一个数,再对无序区进行排序,遍历直到全部有序
- 附代码
def bubble_sort(li):
for i in (len(li)-1):
exchange=False
for j in len(li)-1-i:
if li[j]>li[j+1]:
li[j],li[j+1]=li[j+1],li[j]
exchange=True
if not exchange:
return
(二)选择排序
- 选择排序的思想就是首先遍历一遍列表,找出最小值和第一个值交换,然后在从第二个值开始查找最小值,放到第二个数,一直遍历到最后,即可排序完成
- 附代码
def select_sort(li):
for i in range(len(li)-1):
min_d=i
for j in range(i+1,len(li)):
if li[j]<li[min_d]:
min_d=j
if min_d!=i:
li[j],li[min_d]=li[min_d],li[j]
print(li)
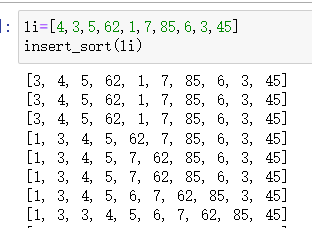
(三)插入排序
- 首先从列表中选一个数拿出来,然后从列表中在拿一个数和第一个数比较,小于放到左边,大于放到右边,然后不断遍历到最后,后面的数从后往前比较,当大于的时候就停止,不断遍历,完成排序
- 附代码
def insert_sort(li):
for i in range(1,len(li)):
tmp=li[i]
j=i-1
while j>=0 and li[j]>tmp:
li[j+1]=li[j]
j-=1
li[j+1]=tmp
print(li)
(四)快速排序
- 快速排序相对复杂,其思想在于将列表不断拆分,然后归位一个元素,使该元素左边都小于它,右边都大于它,然后利用递归完成排序

- 所以快速排序代码分为两个部分,一个部分用于递归,一个部分用于元素归位
- 归位代码
def quarrtion(li,left,right):
tmp=li[left]
while left<right:
while left<right and li[right]>=tmp:
right-=1
li[left]=li[right]
while left<right and li[left]<=tmp:
left+=1
li[right]=li[left]
print(li)
li[left]=tmp
return left
- 递归代码
def quick_sort(li,left,right):
while left<right:
mid=quarrtion(li,left,right)
quick_sort(li,left,mid-1)
quick_sort(li,mid+1,right)
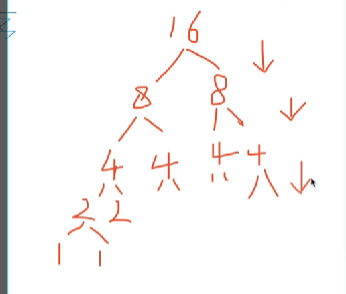
- 快速排序之所以叫快速排序,在于其时间复杂度小为O(nlogn)
如图每一层都是n,有logn层,故时间复杂度为O(nlogn)
- 而上面三个排序的时间复杂度均为O(n*2)
- 当n的数量级很大时,快速排序会比以上三种快很多
- 下面要讲的堆排序和归并排序时间复杂度也为O(nlogn)
(五)堆排序
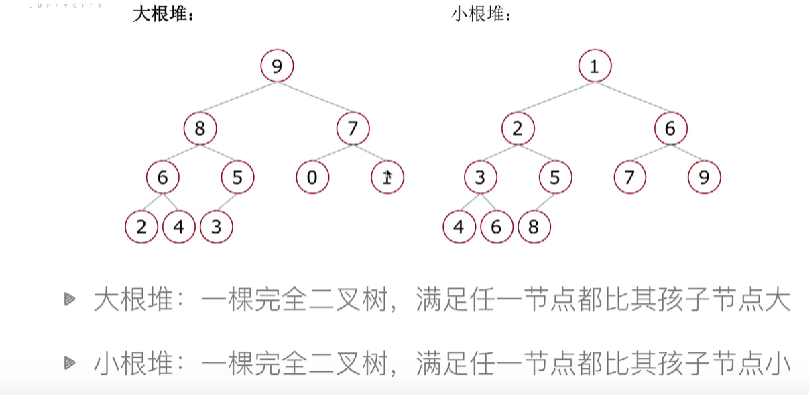
- 堆排序相对复杂,利用树的原理进行排序,这里有几个概念要了解一下
- 堆是一种特殊的完全二叉树结构,分为以下两种堆情况
堆排序分为以下几个过程

- 其实就是先挨个出数,每出一个数将最后一个元素放到顶部,然后还原成堆,直到所有的数都出去,即可完成堆排序
- 所以我们的堆排序就是分为两个部分,一个是构造堆,一个是挨个出数
def sift(li,low,high):#构造堆的函数部分
#param li:列表
#param low:
#param high:堆的最后一个元素的位置
i=low# i最开始指向根节点
j=i*2+1#j开始是左孩子
tmp=li[low]#把堆顶存起来
while j<=high:#只要j位置有数
if j+1<=high and li[j+1]>li[j]:
j=j+1#j指向右孩子
if li[j]>tmp:
li[i]=li[j]
i=j
j=2*i+1
else:
li[i]=tmp
break
else:
li[i]=tmp#把tmp放到叶子节点上
def heap_sort(li):#堆排序的函数部分
n=len(li)
for i in range((n-2)//2,-1,-1):
# i表示建堆的时候调整的部分的根的下标
sift(li,i,n-1)
#建堆完成了
for i in range(n-1,-1,-1):
#i指向当前堆的最后一个元素
li[0],li[i]=li[i],li[0]
sift(li,0,i-1)#i-1是新的high
- sift函数时间复杂度为logn
- heap_sort时间复杂度为n
- 故堆排序时间复杂度也为O(nlogn)
堆排序代码非常复杂,在python中也有相应的模块


(六)归并排序
- 归并排序分为两个部分,分别是归并merge,和排序
- 运用递归的思想,将列表分解

如图
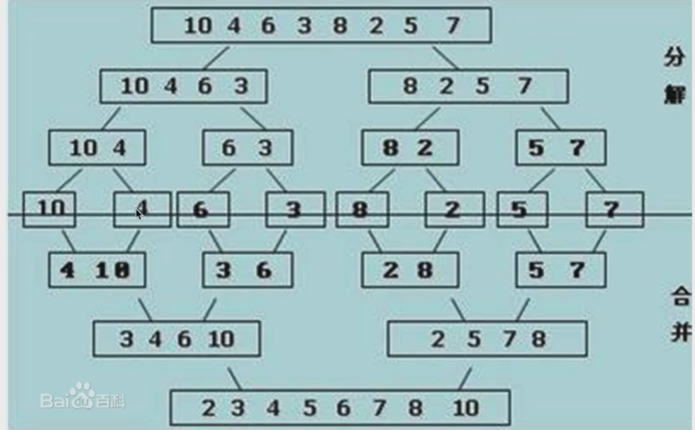
首先是merge(一次归并)部分
def merge(li,low,mid,high):
i=low
j=mid+1
ltmp=[]
while i<=mid and j<=high:#只要左右两边都有数
if li[i]<li[j]:
ltmp.append(li[i])
i+=1
else:
ltmp.append(li[j])
j+=1
#while执行完,肯定有一部分没有数了
while i<=mid:
ltmp.append(li[i])
i+=1
while j<=high:
ltmp.append(li[j])
j+=1
li[low:high+1]=ltmp#将ltmp写回li
- 再是递归归并的部分
def merge_sort(li,low,high):
if low<high:#至少有两个元素才进行归并
mid=(low+high)//2
merge_sort(li,low,mid)#排序好左边
merge_sort(li,mid+1,high)#排序好右边
merge(li,low,mid,high)#排序
*归并排序的时间复杂度也为O(nlogn)
七、排序总结
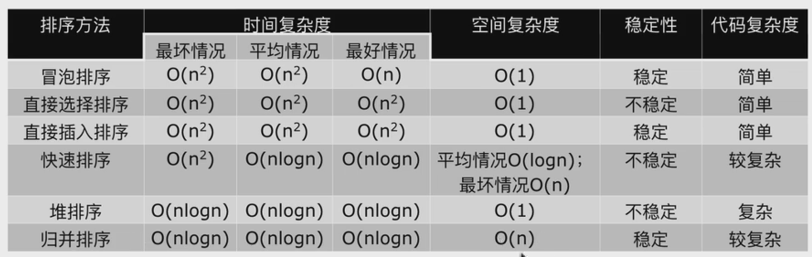
三种较快的排序对比

六种排序总结
本次学习就到这里,寒假加油!









