1、File类的使用
java.io.File类:文件和文件目录路径的抽象表示形式,与平台无关。
File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身, 则需要使用输入/输出流。
想要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对 象,但是Java程序中的一个 File对象,可能没有一个真实存在的文件或目录。
构造方法:
public File(String pathname) 以pathname为路径创建File对象,可以是绝对路径或者相对路径,如 果pathname是相对路径,则默认的当前路径在系统属性user.dir中存储。 绝对路径:是一个固定的路 径,从盘符开始相对路径:是相对于某个位置开始
public File(String parent,String child)以parent为父路径,child为子路径创建File对象。
public File(File parent,String child)根据一个父File对象和子文件路径创建File对象。
常用方法:
listFiles():方法介绍文件都存放在目录(文件夹)中,那么如何获取一个目录中的所有文件或者目录中 的文件夹呢?那么我们先想想,一个目录中可能有多个文件或者文件夹,那么如果File中有功能获取到一 个目录中的所有文件和文件夹,那么功能得到的结果要么是数组,要么是集合。
文件过滤器:通过上述方法,我们可以获取到一个目录下的所有文件和文件夹,但能不能对其进行过滤 呢?比如我们只想要一个目录下的指定扩展名的文件,或者包含某些关键字的文件夹呢?我们是可以先 把一个目录下的所有文件和文件夹获取到,并遍历当前获取到所有内容,遍历过程中在进行筛选,但是 这个动作有点麻烦,Java给我们提供相应的功能来解决这个问题。查阅File类的API,在查阅时发现File类 中重载的listFiles方法,并且接受指定的过滤器。
2、IO流
I/O是Input/Output的缩写, I/O技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文 件,网络通讯等。
Java程序中,对于数据的输入/输出操作以“流(stream)”的方式进行。
IO原理:输入input:读取外部数据到程序(内存)中
输出output:将程序(内存)数据输出到磁盘、光盘等存储社保中。
流的分类:按照数据单位来分:字节流,字符流
按照流向来分:输入流,输出流。
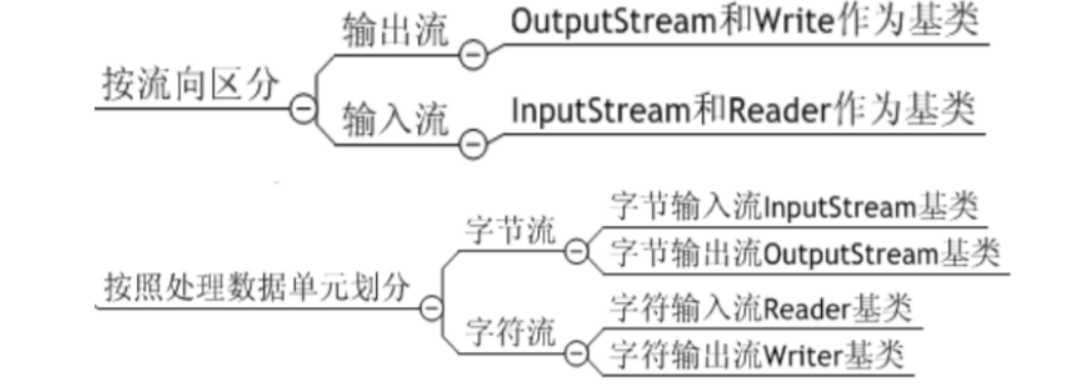

流的体系:

3、InputStream和Reader
InputStream和Reader是所有输入流的基类
InputStream典型实现是FileInputStream。常用方法read()方法【int read(); int read(byte[] b) ;int read(byte[] b, int off, int len) 】
Reader典型实现是FileReader。常用方法read()方法【int read(); int read(byte[] b) ;int read(byte[] b, int off, int len) 】
程序中打开的文件 IO 资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件 IO 资源。
FileInputStream 从文件系统中的某个文件中获得输入字节。FileInputStream 用于读取非文本数据之类 的原始字节流。要读取字符流,需要使用 FileReader。
InputStream方法介绍:
int read():从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因为已经到 达流末尾而没有可用的字节,则返回值 -1。
int read(byte[] b):从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。如果因为已经 到达流末尾而没有可用的字节,则返回值 -1。否则以整数形式返回实际读取的字节数。
int read(byte[] b, int off,int len):将输入流中最多 len 个数据字节读入 byte 数组。尝试读取 len 个 字节,但读取的字节也可能小于该值。以整数形式返回实际读取的字节数。如果因为流位于文件末尾而 没有可用的字节,则返回值 -1。
public void close() throws IOException关闭此输入流并释放与该流关联的所有系统资源。
Reader方法介绍:
int read()读取单个字符。作为整数读取的字符,范围在 0 到 65535 之间 (0x00-0xffff)(2个字节的 Unicode码),如果已到达流的末尾,则返回 -1
int read(char[] cbuf)将字符读入数组。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符 数。
int read(char[] cbuf,int off,int len)将字符读入数组的某一部分。存到数组cbuf中,从off处开始存 储,最多读len个字符。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。
public void close() throws IOException关闭此输入流并释放与该流关联的所有系统资源。
4、OutputStream和Writer
OutputStream 和 Writer 也非常相似:
void write(int b/int c);
void write(byte[] b/char[] cbuf);
void write(byte[] b/char[] buff, int off, int len);
void flush();
void close(); 需要先刷新,再关闭此流。
因为字符流直接以字符作为操作单位,所以 Writer 可以用字符串来替换字符数组,即以 String 对象作 为参数
void write(String str);
void write(String str, int off, int len);
FileOutputStream 从文件系统中的某个文件中获得输出字节。FileOutputStream 用于写出非文本数据 之类的原始字节流。要写出字符流,需要使用 FileWriter。
5、缓冲流
为了提高数据读写的速度,Java API提供了带缓冲功能的流类,在使用这些流类时,会创建一个内部缓 冲区数组,缺省使用8192个字节(8Kb)的缓冲区。
缓冲流要“套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
BufferedInputStream 和 BufferedOutputStream
BufferedReader 和 BufferedWriter
当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区
当使用BufferedInputStream读取字节文件时,BufferedInputStream会一次性从文件中读取8192个 (8Kb),存在缓冲区中,直到缓冲区装满了,才重新从文件中读取下一个8192个字节数组。
向流中写入字节时,不会直接写到文件,先写到缓冲区中直到缓冲区写满,BufferedOutputStream才 会把缓冲区中的数据一次性写到文件里。使用方法flush()可以强制将缓冲区的内容全部写入输出流
关闭流的顺序和打开流的顺序相反。只要关闭最外层流即可,关闭最外层流也会相应关闭内层节点流
flush()方法的使用:手动将buffer中内容写入文件
如果是带缓冲区的流对象的close()方法,不但会关闭流,还会在关闭流之前刷新缓冲区,关闭后不能再 写出
6、转换流
转换流提供了在字节流和字符流之间的转换。
Java API提供了两个转换流:
InputStreamReader:将InputStream转换为Reader
OutputStreamWriter:将Writer转换为OutputStream
字节流中的数据都是字符时,转成字符流操作更高效。
很多时候我们使用转换流来处理文件乱码问题。实现编码和解码的功能
字符编码:常见的编码表
ASCII:美国标准信息交换码。用一个字节的7位可以表示。
ISO8859-1:拉丁码表。欧洲码表用一个字节的8位表示。
GB2312:中国的中文编码表。最多两个字节编码所有字符
GBK:中国的中文编码表升级,融合了更多的中文文字符号。最多两个字节编码
Unicode:国际标准码,融合了目前人类使用的所有字符。为每个字符分配唯一的字符码。所有的文字 都用两个字节来表示。
UTF-8:变长的编码方式,可用1-4个字节来表示一个字符
7、标准输入、输出流
System.in和System.out分别代表了系统标准的输入和输出设备
默认输入设备是:键盘,输出设备是:显示器
System.in的类型是InputStream
System.out的类型是PrintStream,其是OutputStream的子类
FilterOutputStream 的子类
重定向:通过System类的setIn,setOut方法对默认设备进行改变。
public static void setIn(InputStream in)
public static void setOut(PrintStream out)
8、对象流
ObjectInputStream和OjbectOutputSteam:用于存储和读取基本数据类型数据或对象的处理流。它的强 大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
序列化:用ObjectOutputStream类保存基本类型数据或对象的机制。
反序列化:用ObjectInputStream类读取基本类型数据或对象的机制。
对象的序列化:对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种 二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取 了这种二进制流,就可以恢复成原来的Java对象。序列化的好处在于可将任何实现了Serializable接口的 对象转换为字节数据,使其在保存和传输时可被还原。序列化是RMI(Remote Method Invoke-远程方法 调用)过程的参数和返回值都必须实现的机制。而RMI是javaEE的基础,因此序列化机制是JavaEE平台的 基础。如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某 个类是可序列化的,该类必须实现如下两个接口之一,否则会抛出NotSerializableException。通常实现 Serializable
凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:
private static final long serialVersionUID;
serialVersionUID用来表明类的不同版本间的兼容性。简言之,其目的是以序列化对象进行版本控制, 有关各版本反序列化时是否兼容。
如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的实 例变量做了修改,serialVersionUID 可能发生变化。故建议,显式声明。
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行 反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比 较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。 (InvalidCastException)。
若某个类实现了 Serializable 接口,该类的对象就是可序列化的:
创建一个 ObjectOutputStream
调用 ObjectOutputStream 对象的 writeObject(对象) 方法输出可序列化对象
注意写出一次,操作flush()一次。
反序列化
创建一个 ObjectInputStream
调用 readObject() 方法读取流中的对象
强调:如果某个类的属性不是基本数据类型或 String 类型,而是另一个引用类型,那么这个引用类型必 须是可序列化的,否则拥有该类型的Field 的类也不能序列化。
谈谈你对Serializable接口的理解
瞬态关键字
当一个类的对象需要被序列化时,某些属性不需要被序列化,这时不需要序列化的属性可以使用关键字 transient修饰。只要被transient修饰了,序列化时这个属性就不会琲序列化了。同时静态修饰也不会被 序列化,因为序列化是把对象数据进行持久化存储,而静态的属于类加载时的数据,不会被序列化。










