pandas
常用数据类型
- Series 一维,带标签数组
- DataFrame 二维,Series容器
Series创建
Series 一维,带标签数组
import pandas as pd
t = pd.Series([1,2,31,12,3,4])
print(t)
#结果为:
0 1
1 2
2 31
3 12
4 3
5 4
dtype: int64
import pandas as pd
t = pd.Series([1,2,31,12,3,4],index=list('abcdef'))
print(t)
#结果为:
a 1
b 2
c 31
d 12
e 3
f 4
dtype: int64
import pandas as pd
dict_temp = {'name':'zzz','age':18,'sex':'man'}
t =pd.Series(dict_temp)
print(t)
#结果为:
name zzz
age 18
sex man
dtype: object

Series切片和索引
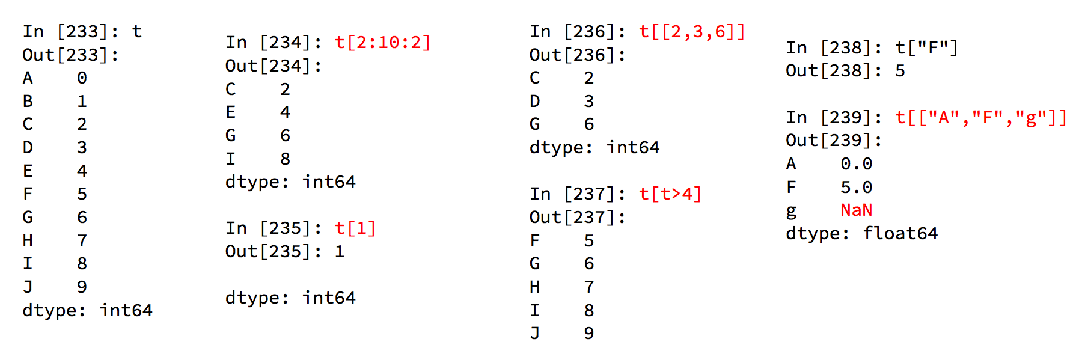

查看索引值与值:

DataFrame
读取外部数据
数据存在csv中,我们直接使用pd. read_csv即可
对于数据库比如mysql或者mongodb中数据,pd.read_sql(sql_sentence,connection)
dataframe创建

DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
d1 = [{'name':'sss','age':16},{'name':'zzz','age':19},{'name':'ttt','age':18}]
d2 = {'name':['ccc','ggg'],'age':[12,15]}
t1 = pd.DataFrame(d1)
t2 = pd.DataFrame(d2)
print(t1)
print(t2)
#结果为:
name age
0 sss 16
1 zzz 19
2 ttt 18
name age
0 ccc 12
1 ggg 15
d1 = [{'name':'sss','age':16},{'name':'zzz','age':19},{'name':'ttt','age':18}]
d2 = {'name':['ccc','ggg'],'age':[12,15]}
d3 = np.arange(12).reshape(3,4)
t1 = pd.DataFrame(list(d1[0:2]))
t2 = pd.DataFrame(d2)
t3 = pd.DataFrame(d3,index=list('abc'),columns=list('qwer'))
print(t1)
print(t2)
print(t3)
#结果为:
name age
0 sss 16
1 zzz 19
name age
0 ccc 12
1 ggg 15
q w e r
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
dataframe基本属性查询

展示部分:
d1 = [{'name':'sss','age':16},{'name':'zzz','age':19},{'name':'ttt','age':18}]
t1 = pd.DataFrame(list(d1[0:2]))
print(t1)
print(t1.shape)
print(t1.values)
print(t1.dtypes)
#结果为:
name age
0 sss 16
1 zzz 19
(2, 2)
[['sss' 16]
['zzz' 19]]
name object
age int64
dtype: object
排序
按年龄排序:
d1 = [{'name':'sss','age':16},{'name':'zzz','age':19},{'name':'ttt','age':18}]
t1 = pd.DataFrame(d1)
t2 = t1.sort_values(by='age',ascending=False)
print(t2)
取行列
1、方法一:
取行:方括号中写数组
取列:写字符串
d1 = [{'name':'sss','age':16},{'name':'zzz','age':19},{'name':'ttt','age':18}]
t1 = pd.DataFrame(d1)
t2 = t1.sort_values(by='age',ascending=False)
print(t2[:2])
print(t2['name'])
#结果为:
name age
1 zzz 19
2 ttt 18
1 zzz
2 ttt
0 sss
Name: name, dtype: object
2、方法二:loc与iloc
df.loc 通过标签索引行数据
df.iloc 通过位置获取行数据
d1 = np.arange(12).reshape(3,4)
t1 = pd.DataFrame(d1,index=list('abc'),columns=list('wxyz'))
print(t1)
s = t1.loc['a','x']
s1 = t1.loc['a',:]
s2 = t1.loc[['a','c'],:]
print(s)
print(s1)
print(s2)
#结果为:
w x y z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
1
w 0
x 1
y 2
z 3
Name: a, dtype: int32
w x y z
a 0 1 2 3
c 8 9 10 11
d1 = np.arange(12).reshape(3,4)
t1 = pd.DataFrame(d1,index=list('abc'),columns=list('wxyz'))
print(t1)
s = t1.iloc[:,2]
s1 = t1.iloc[[0,1],:]
print(s)
print(s1)
#结果为:
w x y z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
a 2
b 6
c 10
Name: y, dtype: int32
w x y z
a 0 1 2 3
b 4 5 6 7
布尔索引
两个条件时不可以写在一起,两个条件必须用括号括起来,必须分开用&或|连接,并且打印的是该条信息:

d1 = np.arange(12).reshape(3,4)
t1 = pd.DataFrame(d1,index=list('abc'),columns=list('wxyz'))
print(t1)
print()
print(t1[(4<t1['z'])&(t1['z']<10)])
#结果为:
w x y z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
w x y z
b 4 5 6 7
字符串方法

缺失数据处理
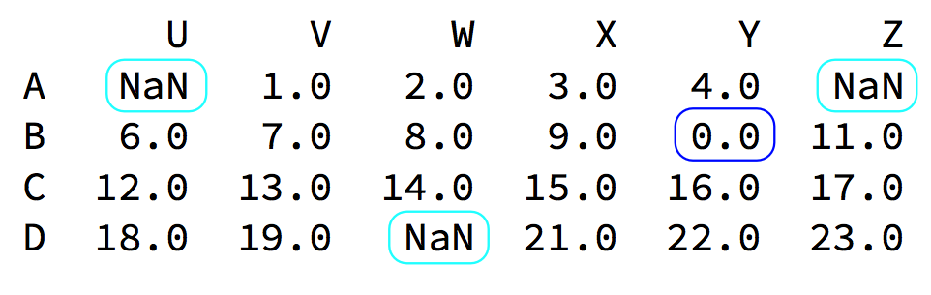
我们的数据缺失通常有两种情况:
一种就是空,None等,在pandas是NaN(和np.nan一样)
另一种是我们让其为0,蓝色框中
- 对于NaN的数据
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how=‘any’, inplace=False)
处理方式2: 填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
只填充某一列,则将t换成t[“标签”]
- 处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会










