基本思想:手中有块Jetson Xavier NX开发板,难得对比一下yolov5在相同模型下,不同形式下的加速性能
一、在ubuntu20.04的基础上,简单做一下对比实验,然后在使用 Jetson Xavier NX进行Deepstream进行目标检测;
(1)下载yolov5(tag6)代码(开发板) RTX2060 测试Pytorch gpu
nvidia@nvidia-desktop:~$ git clone https://github.com/ultralytics/yolov5.git
使用了最快的模型yolo5n.pt
nvidia@nvidia-desktop:~/yolov5$ wget https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5n.pt
测试图片使用tensorrt_inference中的yolov5中example图片
git clone https://github.com/linghu8812/tensorrt_inference.git
测试结果
ubuntu@ubuntu:~/yolov5$ python3 detect.py --weights yolov5n.pt --source ../tensorrt_inference/yolov5/samples/ --device 0
detect: weights=['yolov5n.pt'], source=../tensorrt_inference/yolov5/samples/, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=0, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 🚀 v6.0-88-g80cfaf4 torch 1.10.0+cu113 CUDA:0 (GeForce RTX 2060, 5931MiB)
Fusing layers...
Model Summary: 213 layers, 1867405 parameters, 0 gradients
image 1/7 /home/ubuntu/tensorrt_inference/yolov5/samples/bus.jpg: 640x480 4 persons, 1 bus, 1 skateboard, Done. (0.038s)
image 2/7 /home/ubuntu/tensorrt_inference/yolov5/samples/dog.jpg: 480x640 1 bicycle, 1 car, 1 dog, Done. (0.011s)
image 3/7 /home/ubuntu/tensorrt_inference/yolov5/samples/eagle.jpg: 448x640 1 bird, Done. (0.012s)
image 4/7 /home/ubuntu/tensorrt_inference/yolov5/samples/giraffe.jpg: 640x640 1 zebra, 1 giraffe, Done. (0.013s)
image 5/7 /home/ubuntu/tensorrt_inference/yolov5/samples/horses.jpg: 448x640 3 horses, 2 cows, Done. (0.007s)
image 6/7 /home/ubuntu/tensorrt_inference/yolov5/samples/person.jpg: 448x640 1 person, 1 dog, 1 horse, 1 cow, Done. (0.008s)
image 7/7 /home/ubuntu/tensorrt_inference/yolov5/samples/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.011s)
Speed: 0.5ms pre-process, 14.2ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp
(2) Deepstream 配置环境
ubuntu@ubuntu:~$ sudo apt-get install libgstreamer1.0-0 gstreamer1.0-plugins-base gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav gstreamer1.0-doc gstreamer1.0-tools gstreamer1.0-x gstreamer1.0-alsa gstreamer1.0-gl gstreamer1.0-gtk3 gstreamer1.0-qt5 gstreamer1.0-pulseaudio
ubuntu@ubuntu:~$ sudo aptitude install libssl-dev
ubuntu@ubuntu:~$ sudo apt install libgstrtspserver-1.0-0 libjansson4
继续配置环境 安装librdkafka
ubuntu@ubuntu:~$ git clone https://github.com/edenhill/librdkafka.git
ubuntu@ubuntu:~$ cd librdkafka
ubuntu@ubuntu:~$ git reset --hard 7101c2310341ab3f4675fc565f64f0967e135a6a
ubuntu@ubuntu:~/librdkafka$ ./configure
ubuntu@ubuntu:~/librdkafka$ make
ubuntu@ubuntu:~/librdkafka$ sudo make install
ubuntu@ubuntu:~/librdkafka$ sudo mkdir -p /opt/nvidia/deepstream/deepstream-5.0/lib
ubuntu@ubuntu:~/librdkafka$ sudo cp /usr/local/lib/librdkafka* /opt/nvidia/deepstream/deepstream-5.0/lib
下载deepstream5.1的.tar文件,进行安装。官网下载地址 https://developer.nvidia.com/deepstream-sdk-download-tesla-archived
链接:https://pan.baidu.com/s/1KcxQULbv5ZvVKCQxPjuX3w
提取码:ryui
1、解压到指定目录:
ubuntu@ubuntu:~$ tar -jxvf deepstream_sdk_v5.1.0_x86_64.tbz2 -C /
若需卸载之前应用,则使用下面方式:
ubuntu@ubuntu:~$ cd /opt/nvidia/deepstream/deepstream-5.1
ubuntu@ubuntu:~$ sudo vim uninstall.sh
//打开后,设置PREV_DS_VER=5.1
ubuntu@ubuntu:~$ sudo ./uninstall.sh
2、安装deepstream:
ubuntu@ubuntu:~$ cd /opt/nvidia/deepstream/deepstream-5.0/
ubuntu@ubuntu:~$ sudo ./install.sh
ubuntu@ubuntu:~$ sudo ldconfig
配置环境变量
ubuntu@ubuntu:~$ sudo vi /etc/ld.so.conf
/opt/nvidia/deepstream/deepstream-5.1/lib/ //在文本后边添加该路径
ubuntu@ubuntu:~$ sudo ldconfig //执行ldconfig立即生效
测试结果
ubuntu@ubuntu:~$ sudo gedit /etc/ld.so.conf
(gedit:1302304): Tepl-WARNING **: 11:29:05.109: GVfs metadata is not supported. Fallback to TeplMetadataManager. Either GVfs is not correctly installed or GVfs metadata are not supported on this platform. In the latter case, you should configure Tepl with --disable-gvfs-metadata.
ubuntu@ubuntu:~$ sudo ldconfig
ubuntu@ubuntu:~$ deepstream-app --version-all
deepstream-app version 5.1.0
DeepStreamSDK 5.1.0
CUDA Driver Version: 11.2
CUDA Runtime Version: 11.1
TensorRT Version: 7.2
cuDNN Version: 8.1
libNVWarp360 Version: 2.0.1d3
ubuntu@ubuntu:~$
(1)测试一下deepstream使用
ubuntu@ubuntu:~$ sudo gedit /opt/nvidia/deepstream/deepstream-5.1/samples/configs/deepstream-app/source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
修改 [sink0],将 enable 改为 0
修改 [sink1],将 enable 改为 1:
ubuntu@ubuntu:~$ sudo deepstream-app -c /opt/nvidia/deepstream/deepstream-5.1/samples/configs/deepstream-app/source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
ubuntu@ubuntu:/opt/nvidia/deepstream/deepstream-5.1/sources/apps/sample_apps/deepstream-test1$ sudo make
cc -c -o deepstream_test1_app.o -I../../../includes -I /usr/local/cuda-11.1/include -pthread -I/usr/include/gstreamer-1.0 -I/usr/include/glib-2.0 -I/usr/lib/x86_64-linux-gnu/glib-2.0/include deepstream_test1_app.c
cc -o deepstream-test1-app deepstream_test1_app.o -lgstreamer-1.0 -lgobject-2.0 -lglib-2.0 -L/usr/local/cuda-11.1/lib64/ -lcudart -L/opt/nvidia/deepstream/deepstream-5.1/lib/ -lnvdsgst_meta -lnvds_meta -lcuda -Wl,-rpath,/opt/nvidia/deepstream/deepstream-5.1/lib/
ubuntu@ubuntu:/opt/nvidia/deepstream/deepstream-5.1/sources/apps/sample_apps/deepstream-test1$ ./deepstream-test1-app ../../../../samples/streams/sample_720p.h264
Running...
Frame Number = 0 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 1 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 2 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 3 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 4 Number of objects = 5 Vehicle Count = 3 Person Count = 2
Frame Number = 5 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 6 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 7 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 8 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 9 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 10 Number of objects = 7 Vehicle Count = 5 Person Count = 2
Frame Number = 11 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 12 Number of objects = 7 Vehicle Count = 5 Person Count = 2
Frame Number = 13 Number of objects = 5 Vehicle Count = 3 Person Count = 2
Frame Number = 14 Number of objects = 5 Vehicle Count = 3 Person Count = 2
Frame Number = 15 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 16 Number of objects = 6 Vehicle Count = 4 Person Count = 2
Frame Number = 17 Number of objects = 5 Vehicle Count = 3 Person Count = 2
Frame Number = 18 Number of objects = 5 Vehicle Count = 3 Person Count = 2
Frame Number = 19 Number of objects = 5 Vehicle Count = 3 Person Count = 2
Frame Number = 20 Number of objects = 8 Vehicle Count = 6 Person Count = 2
Frame Number = 21 Number of objects = 8 Vehicle Count = 6 Person Count = 2
Frame Number = 22 Number of objects = 8 Vehicle Count = 6 Person Count = 2
Frame Number = 23 Number of objects = 8 Vehicle Count = 6 Person Count = 2
Frame Number = 24 Number of objects = 8 Vehicle Count = 6 Person Count = 2
....
测试安装的deepstream时没有问题~
(3)、将pt模型转onnx模型,并且简化一下
ubuntu@ubuntu:~/yolov5$ python3 export.py --weights yolov5n.pt --img 640 --batch 1 --device 0
export: data=data/coco128.yaml, weights=yolov5n.pt, imgsz=[640], batch_size=1,
ONNX: export success, saved as yolov5n.onnx (7.9 MB)
ONNX: run --dynamic ONNX model inference with: 'python detect.py --weights yolov5n.onnx'
Export complete (4.93s)
Results saved to /home/ubuntu/yolov5
Visualize with https://netron.app
ubuntu@ubuntu:~/yolov5$ python3 -m onnxsim yolov5n.onnx yolov5n_sim.onnx
Simplifying...
Checking 0/3...
Checking 1/3...
Checking 2/3...
Ok!
测试结果
ubuntu@ubuntu:~/yolov5$ python3 detect.py --weights yolov5n.onnx ../tensorrt_inference/yolov5/samples/
detect: weights=['yolov5n.onnx', '../tensorrt_inference/yolov5/samples/'], source=data/images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 🚀 v6.0-88-g80cfaf4 torch 1.10.0+cu113 CUDA:0 (GeForce RTX 2060, 5931MiB)
Loading yolov5n.onnx for ONNX Runtime inference...
/home/ubuntu/.local/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py:350: UserWarning: Deprecation warning. This ORT build has ['CUDAExecutionProvider', 'CPUExecutionProvider'] enabled. The next release (ORT 1.10) will require explicitly setting the providers parameter (as opposed to the current behavior of providers getting set/registered by default based on the build flags) when instantiating InferenceSession.For example, onnxruntime.InferenceSession(..., providers=["CUDAExecutionProvider"], ...)
warnings.warn("Deprecation warning. This ORT build has {} enabled. ".format(available_providers) +
image 1/2 /home/ubuntu/yolov5/data/images/bus.jpg: 640x640 4 class0s, 1 class5, Done. (7.235s)
image 2/2 /home/ubuntu/yolov5/data/images/zidane.jpg: 640x640 2 class0s, 1 class27, Done. (0.016s)
Speed: 5.0ms pre-process, 3625.7ms inference, 41.3ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp3
(3)onnx--->trt 修改tensorrt_inference 中yolov5中的CMakeLists.txt本地路径 ...里面没有yolov5n.pt-yolov5n.trt的代码
# TensorRT
set(TENSORRT_ROOT /home/ubuntu/NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3)
修改config.yaml路径,生成trt模型 config.yaml
yolov5:
onnx_file: "/home/ubuntu/yolov5/yolov5s.onnx"
engine_file: "/home/ubuntu/yolov5/yolov5s.trt"
labels_file: "../coco.names"
BATCH_SIZE: 1
INPUT_CHANNEL: 3
IMAGE_WIDTH: 640
IMAGE_HEIGHT: 640
obj_threshold: 0.4
nms_threshold: 0.45
strides: [8, 16, 32]
num_anchors: [3, 3, 3]
anchors: [[10,13], [16,30], [33,23], [30,61], [62,45], [59,119], [116,90], [156,198], [373,326]]
错误一 使用不简化的模型出现的错误
ubuntu@ubuntu:~/tensorrt_inference/yolov5/build$ ./yolov5_trt ../config.yaml ../samples/
loading filename from:/home/ubuntu/yolov5/yolov5n.trt
[11/17/2021-17:20:31] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
deserialize done
[11/17/2021-17:20:31] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
engine->getNbBindings()===5
yolov5_trt: /home/ubuntu/tensorrt_inference/yolov5/yolov5.cpp:58: bool YOLOv5::InferenceFolder(const string&): Assertion `engine->getNbBindings() == 2' failed.
Aborted (core dumped)
后来查询代码知道和查询相关问题知道
https://forums.developer.nvidia.com/t/assertion-engine-getnbbindings-2-failed-when-after-doing-int8-calibration/183732
貌似是根据输入输出的数量对不上 因为输入1+输出4 应该等于=5 c++代码需要修改(太菜了 先查查有没有人遇到)
或者简化之后转模型也会遇到错误
ubuntu@ubuntu:~/tensorrt_inference/yolov5/build$ ./yolov5_trt ../config.yaml ../samples/
----------------------------------------------------------------
Input filename: /home/ubuntu/yolov5/yolov5n.onnx
ONNX IR version: 0.0.7
Opset version: 13
Producer name: pytorch
Producer version: 1.10
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
[11/15/2021-13:26:29] [W] [TRT] onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
terminate called after throwing an instance of 'std::out_of_range'
what(): Attribute not found: axes
Aborted (core dumped)
后来查询知道 貌似是pt转onnx存在op的维度有问题
原onnx模型
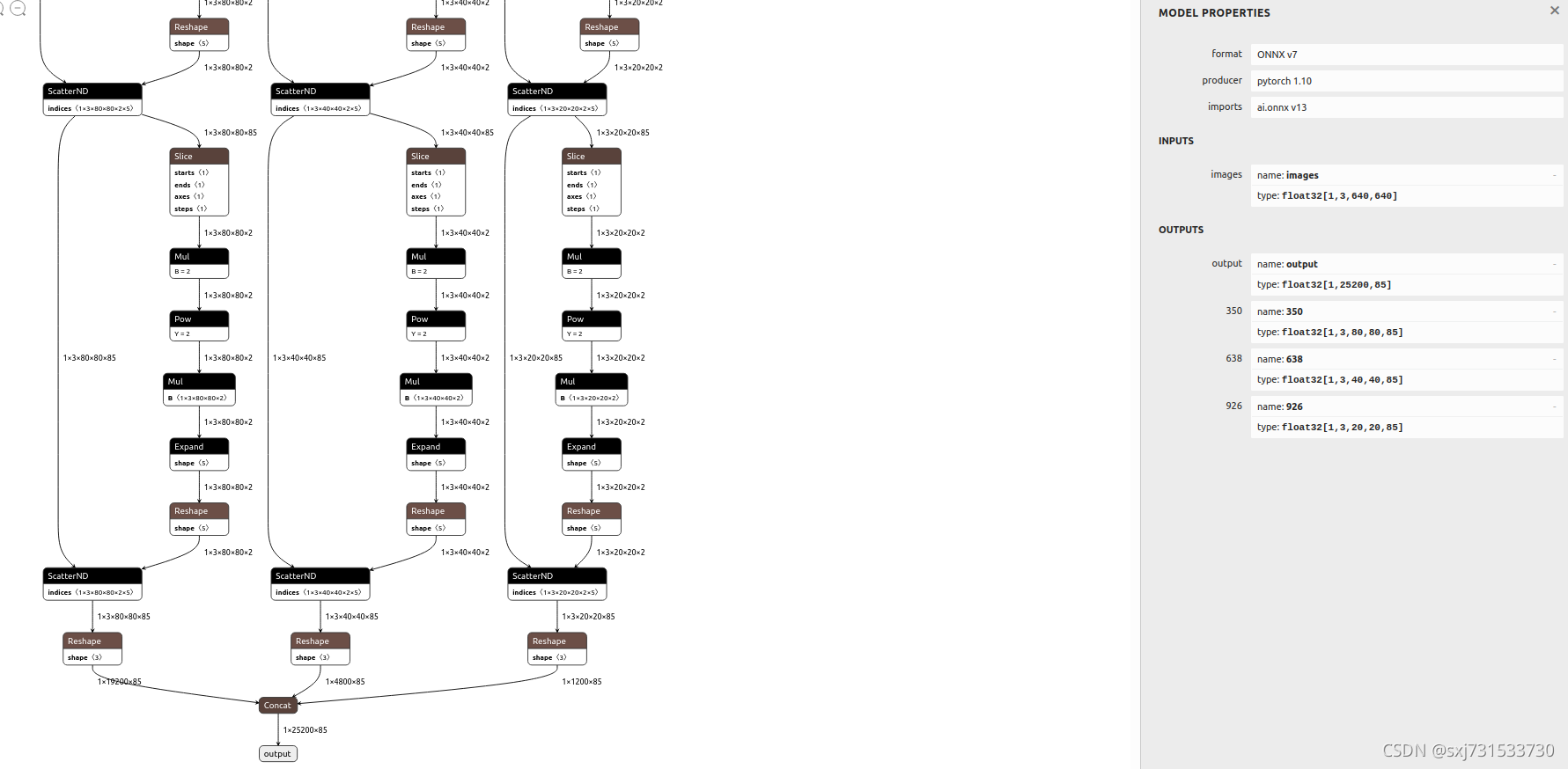
处理后的onnx模型
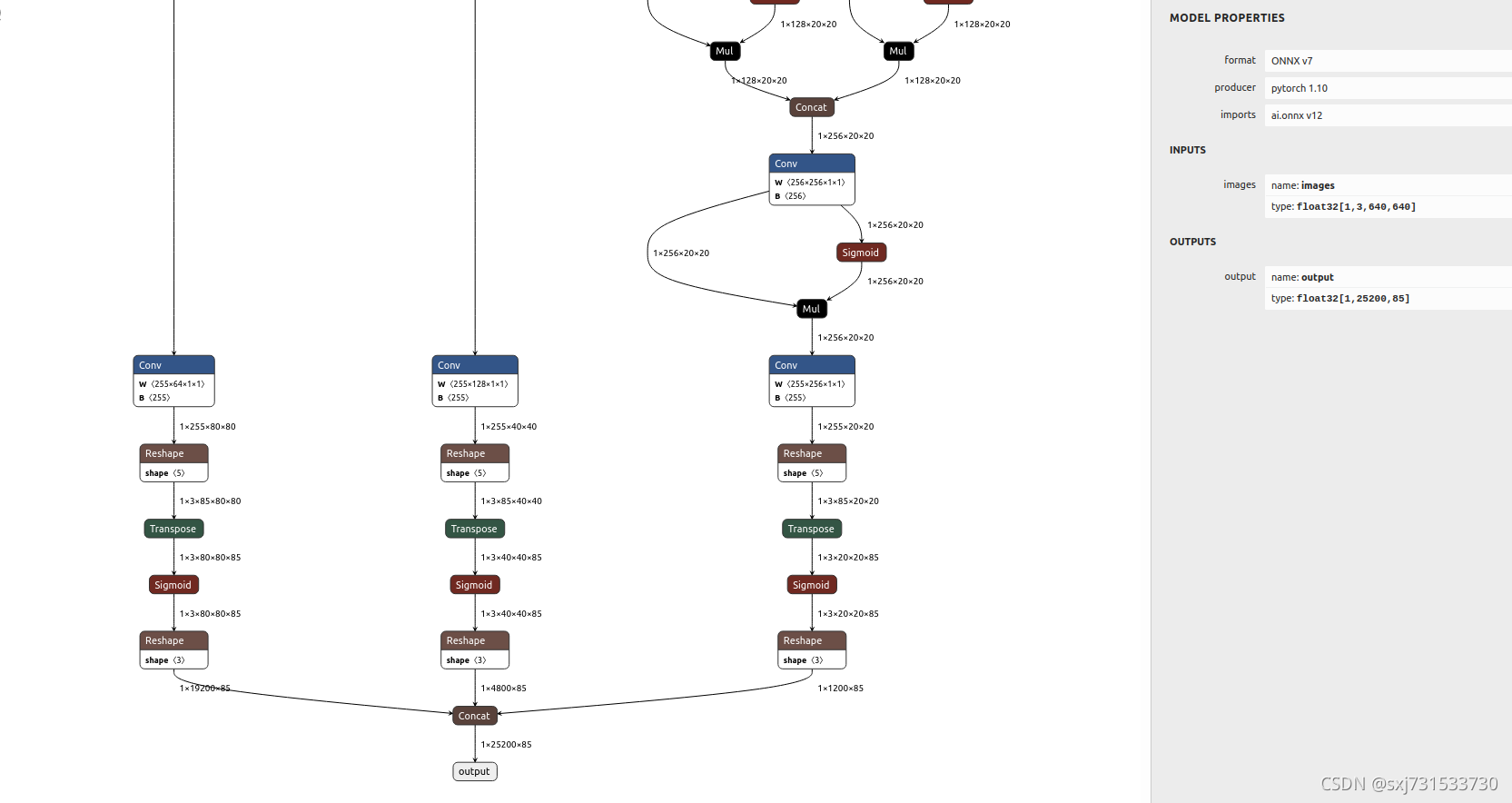
测试结果
ubuntu@ubuntu:~/tensorrt_inference/yolov5/build$ ./yolov5_trt ../config.yaml ../samples/
----------------------------------------------------------------
Input filename: /home/ubuntu/models/yolov5/yolov5n_sim.onnx
ONNX IR version: 0.0.7
Opset version: 12
Producer name: pytorch
Producer version: 1.10
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
[11/17/2021-16:56:22] [W] [TRT] onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
start building engine
[11/17/2021-16:56:22] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[11/17/2021-16:59:21] [I] [TRT] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[11/17/2021-17:00:29] [I] [TRT] Detected 1 inputs and 4 output network tensors.
[11/17/2021-17:00:29] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
build engine done
writing engine file...
save engine file done
[11/17/2021-17:00:29] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
.....
Inference take: 1.1703 ms.
execute success
device2host
post process
Post process take: 6.44929 ms.
../samples//person_.jpg
Average processing time is 12.9103ms
测试结果 1.1703ms

(4)、使用python代码将yolov5s.onnx 转TesorRT模型 https://github.com/ycdhqzhiai/yolov5_tensorRT.git
import tensorrt as trt
import sys
import argparse
logger = trt.Logger(trt.Logger.WARNING)
def convert():
explicit_batch = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH) # trt7
with trt.Builder(logger) as builder, builder.create_network(explicit_batch) as network, trt.OnnxParser(network, logger) as parser:
builder.max_workspace_size = 1 << 28
builder.max_batch_size = 1
if args.floatingpoint == 16:
builder.fp16_mode = True
with open(args.model, 'rb') as f:
print('Beginning ONNX file parsing')
if not parser.parse(f.read()):
for error in range(parser.num_errors):
print("ERROR", parser.get_error(error))
print("num layers:", network.num_layers)
network.get_input(0).shape = [1, 3, 640, 640] # trt7
# last_layer = network.get_layer(network.num_layers - 1)
# network.mark_output(last_layer.get_output(0))
# reshape input from 32 to 1
engine = builder.build_cuda_engine(network)
with open(args.output, 'wb') as f:
f.write(engine.serialize())
print("Completed creating Engine")
if __name__ == '__main__':
desc = 'Compile Onnx model to TensorRT'
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('-m', '--model', default='yolov5n.onnx', help='onnx file location')
parser.add_argument('-fp', '--floatingpoint', type=int, default=16, help='floating point precision. 16 or 32')
parser.add_argument('-o', '--output', default='yolov5.trt', help='name of trt output file')
args = parser.parse_args()
convert()
生成trt模型结果
ubuntu@ubuntu:~/yolov5_tensorRT$ python3 onnx_tensorrt.py -m ~/yolov5/yolov5n_sim.onnx -o ~/yolov5/yolov5n_sim.trt
Beginning ONNX file parsing
[TensorRT] WARNING: onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[TensorRT] WARNING: onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
num layers: 281
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
Completed creating Engine
然后测试一下速度,如果在运行中必要的so 文件,那就从库里拷贝到/usr/lib中
ubuntu@ubuntu:~$ sudo cp NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/targets/x86_64-linux-gnu/lib/libnvinfer.so.7 /usr/lib
ubuntu@ubuntu:~$ sudo cp NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/targets/x86_64-linux-gnu/lib/libnvonnxparser.so.7 /usr/lib
ubuntu@ubuntu:~$ sudo cp NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/targets/x86_64-linux-gnu/lib/libnvparsers.so.7 /usr/lib
ubuntu@ubuntu:~$ sudo cp NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/targets/x86_64-linux-gnu/lib/libnvinfer_ /usr/lib
libnvinfer_plugin.so libnvinfer_plugin_static.a
libnvinfer_plugin.so.7 libnvinfer_static.a
libnvinfer_plugin.so.7.2.2
ubuntu@ubuntu:~$ sudo cp NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/targets/x86_64-linux-gnu/lib/libnvinfer_plugin.so.7 /usr/lib
ubuntu@ubuntu:~$ sudo cp NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/targets/x86_64-linux-gnu/lib/libmyelin.so.1 /usr/lib
(注意)代码有点小bug,如果使用不量化的模型话,图片画框有点小瑕疵
测试效果和平均识别时间3.18ms

(5)、Deepstream 测试一下yolov5s.pt模型 改一下gen_wts.py内容选
ubuntu@ubuntu:~$ git clone https://github.com/DanaHan/Yolov5-in-Deepstream-5.0.git
Cloning into 'Yolov5-in-Deepstream-5.0'...
remote: Enumerating objects: 93, done.
remote: Counting objects: 100% (93/93), done.
remote: Compressing objects: 100% (73/73), done.
remote: Total 93 (delta 26), reused 86 (delta 20), pack-reused 0
Unpacking objects: 100% (93/93), 125.54 KiB | 615.00 KiB/s, done.
ubuntu@ubuntu:~$ cd Yolov5-in-Deepstream-5.0/
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ ls
CMakeLists.txt gen_wts.py logging.h yololayer.cu yolov5_trt.py
common.hpp hardswish.cu README.md yololayer.h
'Deepstream 5.0' hardswish.h utils.h yolov5.cpp
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ mkdir build
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ cd build/
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ cmake .
生成模型
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ cp gen_wts.py ../yolov5
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ cd
ubuntu@ubuntu:~$ cd yolov5/
ubuntu@ubuntu:~/yolov5$ python3 gen_wts.py
YOLOv5 🚀 v6.0-88-g80cfaf4 torch 1.10.0+cu113 CPU
ubuntu@ubuntu:~/yolov5$ cp yolov5n.wts ../Yolov5-in-Deepstream-5.0/
然后拷贝头文件,进行编译文件
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ cp ../NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/include/* .
修改yolov5l.pt的经验 修改5s
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ make
[ 60%] Built target myplugins
[100%] Built target yolov5
修改 yolov5.cpp 文件,将 NET 宏改成自己对应的模型
#define NET x // s m l x
遇见错误
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ sudo ./yolov5 -s
Loading weights: ../yolov5s.wts
[11/18/2021-16:14:05] [E] [TRT] Parameter check failed at: ../builder/Network.cpp::addScale::494, condition: shift.count > 0 ? (shift.values != nullptr) : (shift.values == nullptr)
yolov5: /home/ubuntu/Yolov5-in-Deepstream-5.0/common.hpp:190: nvinfer1::IScaleLayer* addBatchNorm2d(nvinfer1::INetworkDefinition*, std::map<std::__cxx11::basic_string<char>, nvinfer1::Weights>&, nvinfer1::ITensor&, std::string, float): Assertion `scale_1' failed.
Aborted
在yolov5代码中添加summary.py文件
import torch
from torchsummaryX import summary
from models.experimental import attempt_load
model1_path = r'yolov5s.pt'
model = attempt_load(model1_path, map_location=torch.device('cpu'))
# model.to('cuda').eval()
# print(model)
summary(model, torch.rand((1, 3, 640, 640)))
比较一下tag6的yolov5.pt和tag3的yolov5s.pt的却不一样,以后再具体改c++代码,先使用
切换一下分支代码,然后在下载对应v3.0的yolov5.pt代码,重新生成一下.wts权重 https://github.com/ultralytics/yolov5/releases/download/v3.0/yolov5s.pt
ubuntu@ubuntu:~/yolov5$ git checkout -b v1.7.0
Switched to a new branch 'v1.7.0'
ubuntu@ubuntu:~/yolov5$ git branch -v
master 80cfaf4 AutoAnchor and AutoBatch `LOGGER` (#5635)
* v1.7.0 80cfaf4 AutoAnchor and AutoBatch `LOGGER` (#5635)
ubuntu@ubuntu:~/yolov5$ python3 gen_wts.py
YOLOv5 🚀 v6.0-88-g80cfaf4 torch 1.10.0+cu113 CPU
然后生成tengine就没有问题了
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ sudo ./yolov5 -s
Loading weights: ../yolov5s.wts
Building engine, please wait for a while...
[11/18/2021-20:17:50] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[11/18/2021-20:18:36] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
Build engine successfully!
测试一下识别速度
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ sudo ./yolov5 -d ~/tensorrt_inference/yolov5/samples/
[11/18/2021-20:27:00] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[11/18/2021-20:27:00] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
492ms
5ms
6ms
5ms
5ms
5ms
6ms
测试结果 5ms

复制库和生成权重文件到deepstream 5.0
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ cp yolov5s.engine ../Deepstream\ 5.0/
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/build$ cp libmyplugins.so ../Deepstream\ 5.0/
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0$ cd Deepstream\ 5.0/
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/Deepstream 5.0$ cd nvdsinfer_custom_impl_Yolo/
修改一下配置文件
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/Deepstream 5.0$ cat config_infer_primary_yoloV5.txt
.....
model-engine-file=yolov5s.engine
custom-lib-path=nvdsinfer_custom_impl_Yolo/libnvdsinfer_custom_impl_Yolo.so
.....
开始编译库中,遇到一个错误
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/Deepstream 5.0/nvdsinfer_custom_impl_Yolo$ make
g++ -c -o nvdsinfer_yolo_engine.o -Wall -std=c++11 -shared -fPIC -Wno-error=deprecated-declarations -I../includes -I/usr/local/cuda-11.3/include nvdsinfer_yolo_engine.cpp
In file included from nvdsinfer_yolo_engine.cpp:23:
../includes/nvdsinfer_custom_impl.h:126:10: fatal error: NvCaffeParser.h: No such file or directory
126 | #include "NvCaffeParser.h"
| ^~~~~~~~~~~~~~~~~
compilation terminated.
make: *** [Makefile:50: nvdsinfer_yolo_engine.o] Error 1
解决一下
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/Deepstream 5.0/nvdsinfer_custom_impl_Yolo$ cp ~/NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/include/* ../include
重新生成so 还是有问题
ubuntu@ubuntu:~/Yolov5-in-Deepstream-5.0/Deepstream 5.0/nvdsinfer_custom_impl_Yolo$ make
g++ -c -o yolo.o -Wall -std=c++11 -shared -fPIC -Wno-error=deprecated-declarations -I../includes -I/usr/local/cuda-11.1/include yolo.cpp
In file included from yolo.h:31,
from yolo.cpp:23:
yolo.cpp:72:12: error: ‘virtual nvinfer1::IBuilderConfig::~IBuilderConfig()’ is protected within this context
72 | delete config;
| ^~~~~~
In file included from yolo.h:31,
from yolo.cpp:23:
../includes/NvInfer.h:6756:13: note: declared protected here
6756 | virtual ~IBuilderConfig() {}
| ^
yolo.cpp: In member function ‘NvDsInferStatus Yolo::buildYoloNetwork(std::vector<float>&, nvinfer1::INetworkDefinition&)’:
yolo.cpp:178:81: error: invalid new-expression of abstract class type ‘YoloLayerV3’
178 | m_OutputTensors.at(outputTensorCount).gridSize);
| ^
make: *** [Makefile:50: yolo.o] Error 1
搜索无果 累
(6)、使用另一个大佬的代码,需要新生成一遍yolov5n.pt---yolov5n.wts 方法如下
ubuntu@ubuntu:~$ git clone https://github.com/wang-xinyu/tensorrtx.git
Cloning into 'tensorrtx'...
remote: Enumerating objects: 1827, done.
remote: Counting objects: 100% (184/184), done.
remote: Compressing objects: 100% (136/136), done.
remote: Total 1827 (delta 105), reused 87 (delta 48), pack-reused 1643
Receiving objects: 100% (1827/1827), 1.64 MiB | 2.96 MiB/s, done.
Resolving deltas: 100% (1162/1162), done.
ubuntu@ubuntu:~$ cd tensorrtx/
ubuntu@ubuntu:~/tensorrtx$ cd yolov
bash: cd: yolov: No such file or directory
ubuntu@ubuntu:~/tensorrtx$ cd yolov5
ubuntu@ubuntu:~/tensorrtx/yolov5/build$ make
[100%] Linking CXX executable yolov5
[100%] Built target yolov5
ubuntu@ubuntu:~/tensorrtx/yolov5/build$ ./yolov5
arguments not right!
./yolov5 -s [.wts] [.engine] [n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw] // serialize model to plan file
./yolov5 -d [.engine] ../samples // deserialize plan file and run inference
ubuntu@ubuntu:~/tensorrtx/yolov5/build$ sudo ./yolov5 -s ~/yolov5/yolov5n.
yolov5n.onnx yolov5n.torchscript.pt yolov5n.wts
yolov5n.pt yolov5n.trt
ubuntu@ubuntu:~/tensorrtx/yolov5/build$ sudo ./yolov5 -s ~/yolov5/yolov5n.
yolov5n.onnx yolov5n.torchscript.pt yolov5n.wts
yolov5n.pt yolov5n.trt
ubuntu@ubuntu:~/tensorrtx/yolov5/build$ sudo ./yolov5 -s ~/yolov5/yolov5n.wts yolov5n.engine n
Loading weights: /home/ubuntu/yolov5/yolov5n.wts
Building engine, please wait for a while...
[11/19/2021-18:16:52] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[11/19/2021-18:20:31] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
Build engine successfully!
ubuntu@ubuntu:~/tensorrtx/yolov5/build$
ubuntu@ubuntu:~/tensorrtx/yolov5/build$ sudo ./yolov5 -d yolov5n.engine ../samples
[11/19/2021-18:20:53] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[11/19/2021-18:20:53] [W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
inference time: 1ms
inference time: 1ms
但是使用GitHub - hlld/deepstream-yolov5: an implementation of yolov5 running on deepstream5 大佬生成so就没有问题,
ubuntu@ubuntu:~$ git clone https://github.com/hlld/deepstream-yolov5.git
Cloning into 'deepstream-yolov5'...
remote: Enumerating objects: 33, done.
remote: Counting objects: 100% (33/33), done.
remote: Compressing objects: 100% (24/24), done.
remote: Total 33 (delta 9), reused 32 (delta 8), pack-reused 0
Unpacking objects: 100% (33/33), 25.26 KiB | 253.00 KiB/s, done.
ubuntu@ubuntu:~$ cd deepstream-yolov5/
ubuntu@ubuntu:~/deepstream-yolov5$ ls
configs data LICENSE README.md source
ubuntu@ubuntu:~/deepstream-yolov5$ cd source/
ubuntu@ubuntu:~/deepstream-yolov5/source$ ls
common.h nvdsparsebbox_Yolo.cpp yolo.cpp yololayer.h
Makefile trt_utils.cpp yolo.h yolo_utils.h
nvdsinfer_yolo_engine.cpp trt_utils.h yololayer.cu yolov5.cpp
ubuntu@ubuntu:~/deepstream-yolov5/source$ sudo vim Makefile
ubuntu@ubuntu:~/deepstream-yolov5/source$ sudo gedit Makefile
(gedit:20487): Tepl-WARNING **: 18:25:12.660: GVfs metadata is not supported. Fallback to TeplMetadataManager. Either GVfs is not correctly installed or GVfs metadata are not supported on this platform. In the latter case, you should configure Tepl with --disable-gvfs-metadata.
ubuntu@ubuntu:~/deepstream-yolov5/source$ make
ugin -lnvinfer -lnvparsers -L/usr/local/cuda-11.1/lib64 -lcudart -lcublas -lstdc++fs -L/home/ubuntu/NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/lib -Wl,--end-group
ubuntu@ubuntu:~/deepstream-yolov5/source$ ls
common.h trt_utils.cpp yololayer.o
libnvdsinfer_custom_impl_yolov5.so trt_utils.h yolo.o
Makefile trt_utils.o yolo_utils.h
nvdsinfer_yolo_engine.cpp yolo.cpp yolov5.cpp
nvdsinfer_yolo_engine.o yolo.h yolov5.o
nvdsparsebbox_Yolo.cpp yololayer.cu
nvdsparsebbox_Yolo.o yololayer.h
然后我改名拷贝过来,执行有问题,查看配置文件发现需要调用
修改了这里
[sink0]
#enable=1
enable=0
[sink1]
#enable=0
enable=1
[primary-gie]
enable=1
gpu-id=0
#model-engine-file=../yolov5s_b1_gpu0_fp16.engine
model-engine-file=/home/ubuntu/ty/tensorrtx/yolov5/build/yolov5n.engine
[tracker]
enable=0
tracker-width=640
tracker-height=384
#ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_mot_klt.so
ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_mot_klt.so
[source0]
#enable=1
enable=2
#Type - 1=CameraV4L2 2=URI 3=MultiURI
然后就跑起来了
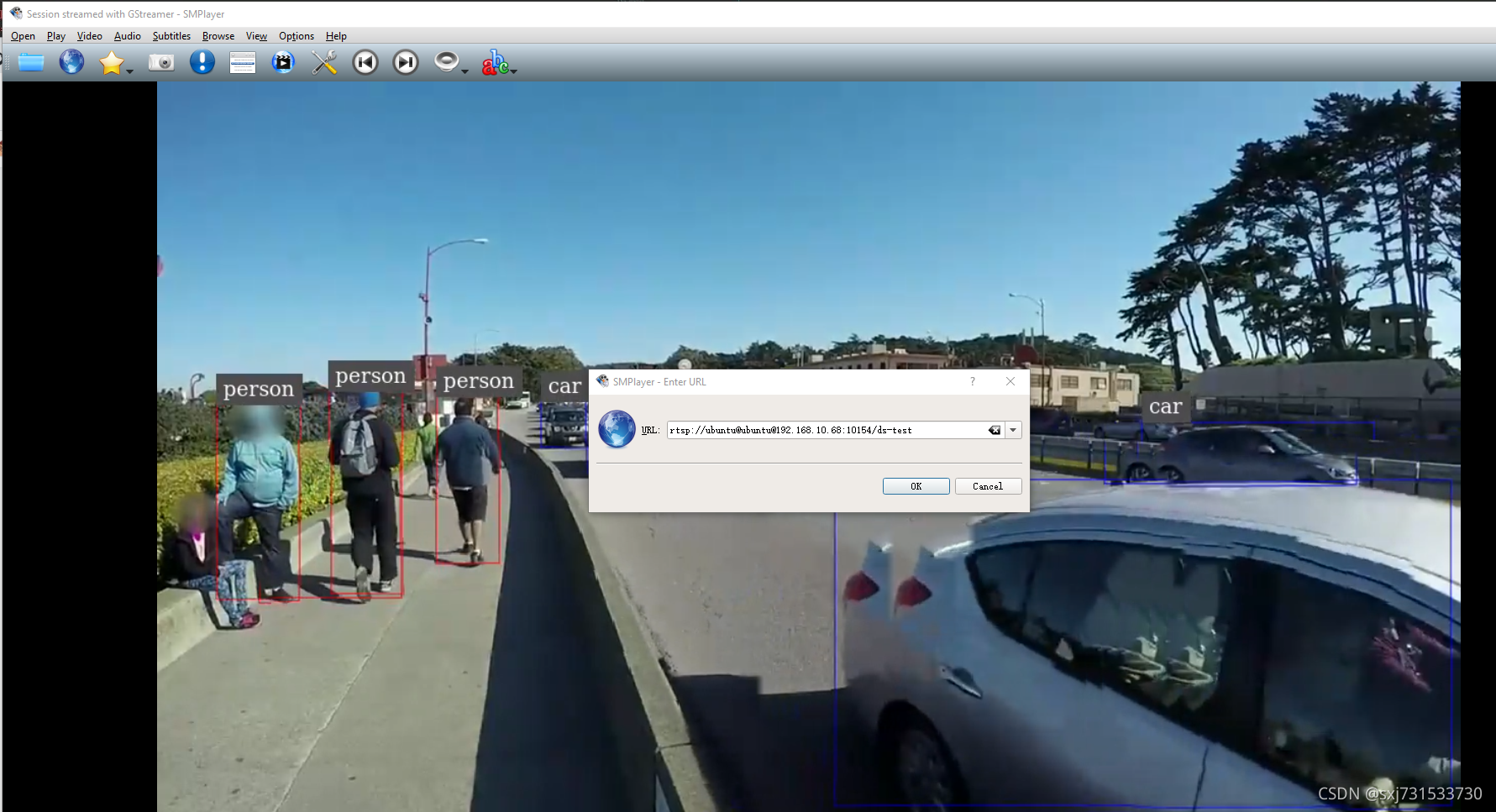
测试数据 出来了推理地址 rtsp://localhost:10154/ds-test ***
ubuntu@ubuntu:~/deepstream-yolov5$ sudo deepstream-app -c configs/deepstream_app_config_yolov5s.txt
*** DeepStream: Launched RTSP Streaming at rtsp://localhost:10154/ds-test ***
Unknown or legacy key specified 'is-classifier' for group [property]
Warn: 'threshold' parameter has been deprecated. Use 'pre-cluster-threshold' instead.
WARNING: ../nvdsinfer/nvdsinfer_func_utils.cpp:36 [TRT]: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
WARNING: ../nvdsinfer/nvdsinfer_func_utils.cpp:36 [TRT]: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
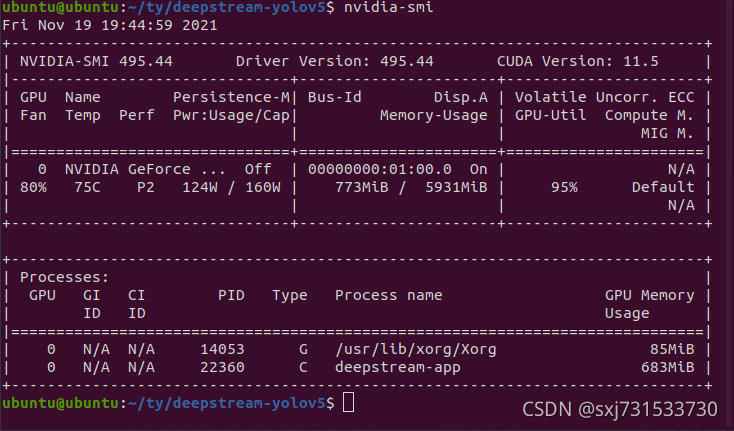
0:00:01.030647881 22360 0x55cfcb064090 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary_gie> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1702> [UID = 1]: deserialized trt engine from :/home/ubuntu/ty/tensorrtx/yolov5/build/yolov5n.engine
INFO: ../nvdsinfer/nvdsinfer_model_builder.cpp:685 [Implicit Engine Info]: layers num: 2
0 INPUT kFLOAT data 3x640x640
1 OUTPUT kFLOAT prob 6001x1x1
0:00:01.030690121 22360 0x55cfcb064090 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary_gie> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:1806> [UID = 1]: Use deserialized engine model: /home/ubuntu/ty/tensorrtx/yolov5/build/yolov5n.engine
0:00:01.031251094 22360 0x55cfcb064090 INFO nvinfer gstnvinfer_impl.cpp:313:notifyLoadModelStatus:<primary_gie> [UID 1]: Load new model:/home/ubuntu/ty/deepstream-yolov5/configs/./config_infer_primary_yolov5s.txt sucessfully
Runtime commands:
h: Print this help
q: Quit
p: Pause
r: Resume
NOTE: To expand a source in the 2D tiled display and view object details, left-click on the source.
To go back to the tiled display, right-click anywhere on the window.
** INFO: <bus_callback:181>: Pipeline ready
** INFO: <bus_callback:167>: Pipeline running
**PERF: FPS 0 (Avg)
**PERF: 460.51 (460.49)
**PERF: 462.28 (461.40)
**PERF: 462.21 (461.76)
**PERF: 461.70 (461.69)
**PERF: 464.78 (462.37)
**PERF: 463.54 (462.57)
**PERF: 461.85 (462.45)
**PERF: 460.58 (462.21)
**PERF: 460.26 (462.00)
**PERF: 460.67 (461.85)
**PERF: 464.37 (462.10)
**PERF: 465.33 (462.37)
**PERF: 466.88 (462.72)
**PERF: 464.26 (462.83)
**PERF: 465.44 (463.00)
**PERF: 465.30 (463.15)
**PERF: 465.44 (463.29)
**PERF: 451.70 (462.62)
**PERF: 451.87 (462.07)
**PERF: 463.94 (462.16)
**PERF: FPS 0 (Avg)
**PERF: 451.90 (461.66)
**PERF: 455.48 (461.38)
然后在 使用smplayer进行拉流就可以了 上图
一、下载yolov5(tag6)代码(开发板)
nvidia@nvidia-desktop:~$ git clone https://github.com/ultralytics/yolov5.git
使用了最快的模型yolo5n.pt
nvidia@nvidia-desktop:~/yolov5$ wget https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5n.pt
测试图片使用tensorrt_inference中的yolov5中example图片
git clone https://github.com/linghu8812/tensorrt_inference.git
需要配置一下环境 scipy 编译时间较长
nvidia@nvidia-desktop:~/yolov5 sudo apt-get install python3-matplotlib
nvidia@nvidia-desktop:~/yolov5$ sudo apt-get install python3-seaborn
nvidia@nvidia-desktop:~/yolov5$ sudo apt-get install libblas-dev checkinstall
nvidia@nvidia-desktop:~/yolov5$ sudo apt-get install liblapack-dev checkinstall
nvidia@nvidia-desktop:~/yolov5$ sudo apt-get install gfortran
nvidia@nvidia-desktop:~/yolov5$ pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple scipy
Collecting scipy
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/aa/d5/dd06fe0e274e579e1dff21aa021219c039df40e39709fabe559faed072a5/scipy-1.5.4.tar.gz
Building wheels for collected packages: scipy
Running setup.py bdist_wheel for scipy ...
done
Stored in directory: /home/nvidia/.cache/pip/wheels/74/91/ed/c853fd6d1f8f7f436e23b242427d9dacf967f3507e736f0637
Successfully built scipy
Installing collected packages: scipy
Successfully installed scipy-1.5.4
nvidia@nvidia-desktop:~/yolov5$ pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple Pillow-PIL
也可以使用tensorrtx里面insightface
ubuntu@ubuntu:~$ pip3 install mxnet-cu111 -i https://pypi.tuna.tsinghua.edu.cn/simple
参考:感谢一下几位大佬的博客和github
https://github.com/ycdhqzhiai/yolov5_tensorRT.git










