研究生语音识别课程作业记录(三) 非特定人孤立词识别
前言
研究生期间的语音识别课程作业记录,研一暑假的主要工作,也是自己正式入门语音识别的启程之路,虽然是采用传统方法进行语音识别的工程仿真,但对于一个新手菜鸟来说,这样的训练必不可少,借此机会记录一下,希望可以对刚入门语音识别的小白提供一点开拓的思路。
一. 任务要求
提供声音文件: 0-9的数字孤立词读音文件库,共28人录音样本,每人10次, 手工分割存档。
任务完成建议和要求:
1.数据是16KHz采样的, 一般需要降采样到8KHz后使用。(Matlab中有相应的命令), 如果直接使用16KHz的数据,应用MFCC时的子带数需要调整, 不能用缺省。
2.可以考虑选择12维MFCC+12维其差分共24维作为提取的特征。
3.可以考虑其他的特征, 例如LPC、LPCC、LSP等等,自己研究后决定。
4.训练及识别(一半的数据用于训练(训练集), 一半的数据用于识别(测试集)), 分别给出训练集和测试集的识别率. 特别提醒,任务的目标是非特定人的孤立词识别,因此,建议自己查一下中国期刊网, 研究一下中文期刊的文章,其他学者对非特定人的特征选择是如何优化的,可以借用别人的思路进行特征提取选择。
5.必须用VQ+DTW方法和自己任选一种识别方法(BP/RBF/GMM/DHMM/SVM/ADABOOST)实现识别任务。
6.用doc文档 描述所进行的一切步骤细节,包括预滤波,分帧加窗(海明窗),特征选择和识别机的参数选择过程(必须给出所有的相关细节参数), 给出实验结果(包括研究的中间过程结果即调整参数前后的实验结果,所有的实验结果需要贴图到doc文档中,不要贴程序),给出结论。 还有必须对实验结果及过程中出现的问题和给出的解决方案进行描述和讨论。
7.提交程序要求: 能够读出和所提供数据库完全一样格式的数据,并给出识别结果显示,包括每一个数字的识别率和最终的平均识别率。
8.将来用于评测所提交作业的数据库独立于目前提供的数据库。
二. 识别方法
SVM
三. 语音数据库
1,一个命名为0-9 digital C的文件夹里面digital文件中存有0-9九个子文件夹,分别存放0到9的数字的录音文件,其中每个子文件夹内有28个人x10个音=280个语音。总计280*10个数字=2800个语音。
2,所有语音统一为16K采样率,16位,单声道,coolEditor软件录制生成, 手工分割。每个人每个数字录取10段语音, 数据命名说明:ij.wav表示第i个人的第j个样本。
3,在本次试验中,取每个数字每个人的取五段语音(共1400段)作为训练集,另五段语音(共1400段)作为测试集,不同的识别方法对不同的训练集和测试集有着不一样的识别率,所以应根据识别率来给每种识别方法调整测试与训练的样本。
4,分别通过不同的识别方法对不同的函数中的参数进行调整,然后进行训练,测试,最终得出训练及测试的最佳识别率。
四. 特征参数提取
1,本文提取12维MFCC+12维其差分共24维作为提取的特征,首先让每段语音信号通过双门限端点检测函数(edgedetection)获得有效语音段,再通过分帧函数(enframe)得到语音帧数。
2,并对每一帧进行预加重,加窗(海明窗),fft,计算幅度谱的平方通过mel滤波器组每一个滤波器的加权输出和,取对数,再经DCT变换,得到12维的MFCC,然后计算12维其差分MFCC,合并组成24维MFCC。
3,本文未采取LPCC系数作为特征提取是因为:LPCC系数主要是模拟人的发声模型,不如MFCC,它未考虑人耳的听觉特性,进行平均分段, 它对元音有较好的描述能力,对辅音描述能力及抗噪性能比较差,其优点是计算量小,易于实现。
4,本文选择两种样本选择方法,两种分类方法分别适应不同的方法的最佳识别率:
a:训练集:每个数字每人的前五段语音;测试集:每个数字每人的后五段语音。
b: 训练集:每个数字每人的五段偶数序语音;测试集:每个数字每人的五段奇数序语音。
五. 识别过程及分析
SVM方法是通过一个非线性映射,把样本空间从低维映射到一个高维乃至无穷维的特征空间中(Hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题。
1,分别创建训练和测试索引文件名目录TrainIndexs和TestIndexs,按索引依次读入语音,通过双门限端点检测函数,加窗(海明窗)分帧函数,提取每段语音的MFCC参数矩阵train_m和test_m(10x140),再通过规整函数(transform)将所有语音特征规整到Nx24维MFCC,保存为trainmfcc和testmfcc(1x10)。
2,载入规整后的特征参数矩阵,通过SVM调用svmtrain和svmclassify函数识别训练集和测试集。最佳识别结果如下:(本实验采用b训练集(偶五奇五),因为a训练集测试的最高识别率为97.64%)

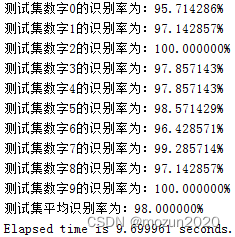
b: 训练集:每个数字每人的五段偶数序语音 测试集:每个数字每人的五段奇数序语音
3,参数调整:规整帧数N,SVM核函数种类,高斯核函数缩放因子sigma
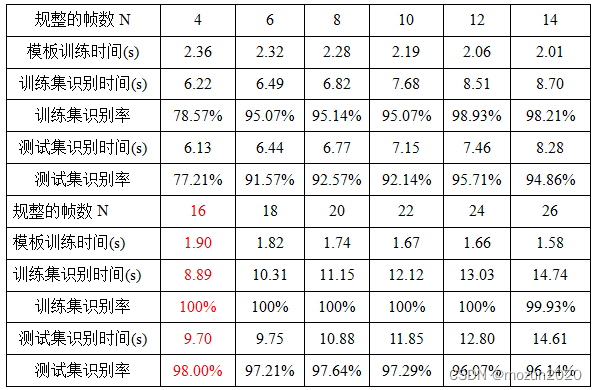
表一:不同规整帧数的识别率
由上表分析,规整帧数越大,模板训练时间越少,但是识别时间相应增加;而训练集识别率在N=16-24之间能达到100%,测试集的识别率呈抛物线变化,在N=16时达到最大98%;因此,通过本实验验证可知SVM方法的最佳规整帧参数取值为N=16。
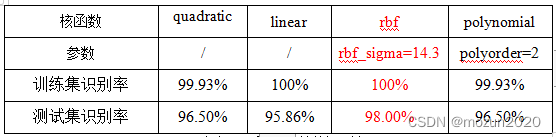
表二:不同核函数的识别率
由上表可知,SVM的选取的核函数不同,对应的识别率也会有所不同。经过调整核函数的参数值,可以看出不同的核函数训练的结果还是有将近一两个百分点的差距,因此本次实验选用的核函数为rbf径向基核函数。Rbf核函数的参数rbf_sigma缩放因子调整过程如下:
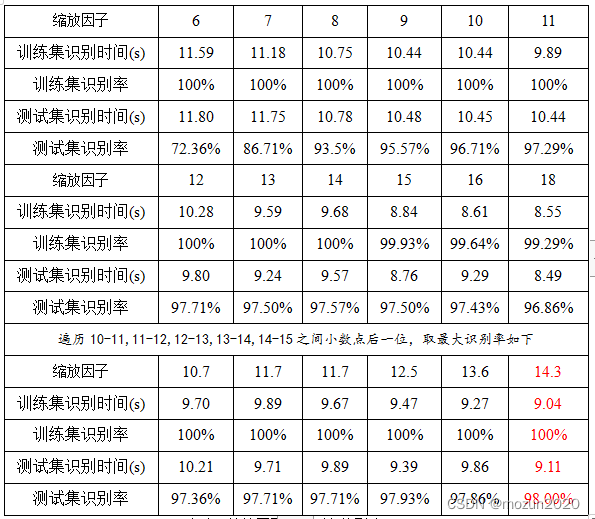
表三:缩放因子对识别率的影响
由实验数据分析,径向基核函数又称高斯核函数,其参数缩放因子与方差有关,sigma越小,函数分布越尖锐;sigma越大,函数分布越平缓。在本次实验中当sigma参数取11-15中的整数时识别率都能超过97%,因此再精确一步,遍历到小数点后一位,得到最高识别率98%,因此缩放因子的最佳取值为:sigma=14.3,此时测试集最佳识别率达到98%。
六. 实验总结
将上述五种方法的最佳识别率综合如下表所示:
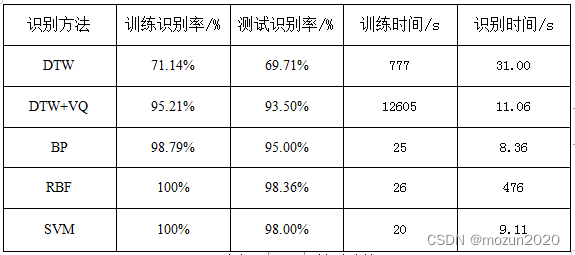
表四:不同识别方法比较
分析:
通过上述表格中的比较,我们可以发现识别率最高的是RBF,其次是SVM,但是RBF的训练时间和识别时间明显高于SVM,因此如果对时间要求严格的话RBF的性能稍弱于SVM的;依次往后,由表九的实验数据中可知,BP优于DTW+VQ,而DTW+VQ则优于单独DTW。综上,如果对识别率和实时性综合要求,则性能排名优劣如下:SVM、RBF、BP、DTW+VQ、DTW。
上文实验数据是在本语音数据库下的实测识别率,通过作者不断地实验和调整参数,发现语音识别仍有很大的提高空间,得出以下三点心得体会:
一,在语音数据库相同的情况下,针对不同的识别方法,需要适当的调整训练的样本;不同的识别方法对不同的样本提取到的特征识别效果不一,因为在特征分类时,针对特征的微小误差就会造成识别率几个百分点的差别。因此选取合适的训练集是非常关键的,它应该是能最大限度地满足在该识别方法的最佳识别率的代表样本。
二,在本实验中没有遍历所有参数的所有可能,精分度依然不够。例如针对不同的帧数及其他识别方法中的某些参数,如果能再进一步进行精确实验,识别结果依然可以得到一些提高,鉴于实验中训练模板及样本的时间问题,本次实验只是遍历了一部分具有代表性的参数值,再根据所得结果体现的规律忽略掉了许多未知的实验数据,因此本实验仍有很大的提高空间。
三,在语音识别的实际运用中,本文中后四种方法均可以作为研究的方向之一,可以通过对底层函数(加窗分帧预加重等)的进一步改进,使之进一步地精确对特征进行分类。在不同的应用场景中应该采用不同的识别方法,如普通民用中的相对精确度要求较松,可以适当进行实用,因为在实践中可以根据具体情况分析解决实际问题,实验结果更具可靠性。
七. 小结
研一的课程作业好多思路都还比较简单稚嫩,但也确实是付出了时间心血,希望未来自己在接下里的日子里,继续努力,继续学习,在语音信号处理方向不断精进!








