
本期 AI Drive以SSAT: A Symmetric Semantic-Aware Transformer Network for Makeup Transfer and Removal(AAAI2022)为汇报内容,讲述妆容迁移的研究目标与背景知识,阐明语义对应作为本文创新点在妆容迁移领域的主要贡献,对比现有最先进工作说明本文方法的优越性,最后还公开了训练好的模型与测试代码,为其他感兴趣的研究者提供研究基础。
主讲人为孙朝阳,本硕博均就读于武汉理工大学计算机与人工智能学院,目前博一。从19年研二开始接触深度学习,目前主要研究方向为妆容迁移和语义分割,已发表CCFA1篇(AAAI一作),CCFC1篇(ACCV一作)。

本文将按照如下五个方向进行讲解(本文ppt,“数据实战派”按后台菜单指示即可获得下载地址,关注视频号“AI Drive”可获得回放):
一、妆容迁移的研究背景。
二、妆容迁移的相关工作及本文想法的产生。
三、想法的代码实现。
四、实验结果分析。
五、科研研究心得。
一、妆容迁移的研究背景
妆容迁移是一个比较小的领域,本节会介绍什么是妆容迁移以及妆容迁移的主要任务是什么。

妆容迁移的任务中,它的输入是一张未化妆的目标图像,和一张任意妆容的参考图像,目标是合成一张新的图像,该图像具有参考图像的妆容风格,同时又保留目标图像的人物身份、表情、姿态、背景等内容信息。
那么,美图秀秀以及各种美颜相机,它不是已经有了这种妆容迁移的功能了吗?
这里需要解释的是,我们做的是一种参考图像的任意妆容迁移。比如给出任意一张图像,它含有一些妆容,需要把这些妆容迁移过去。而美图秀秀及各种美颜相机,它只有特定的几款指定的妆容可以迁移,这是我们所做的与一些现有APP的差异。

它主要有哪些应用方面?如果大家有女朋友或者自己是个女孩子,对化妆品应该不是很陌生,从古代的时候的胭脂水粉到现在的口红眼影以及各种粉底,化妆品一直备受女性用户的广泛喜爱。
据国家统计局的一些数据报告,从2015年到2019年,我国化妆品零售业一直在飞速的增长,即使在疫情期间零售业一直保持快速增长。
妆容迁移的应用方面是很广泛的,比方说电商的试装,在淘宝或者京东去买口红的时候,是想跟买衣服一样试穿一下衣服的效果是怎么样的。买口红也是一样的,想试一下这种口红的色号,在自己的脸上是不是合适。
第二个应用方向是妆容搭配,通过妆容迁移的技术,每天化妆,口红需要选什么色号,适合什么样的眼妆,需要打什么样的高光,打什么样的粉底,可以做一些妆容的搭配。
还有美化图片,比如现在直播或者通过微信、QQ聊天,需要在直播过程中,把自己的图像进行美化一下,上一些妆容之类的。
二、妆容迁移的相关工作及本文想法的产生
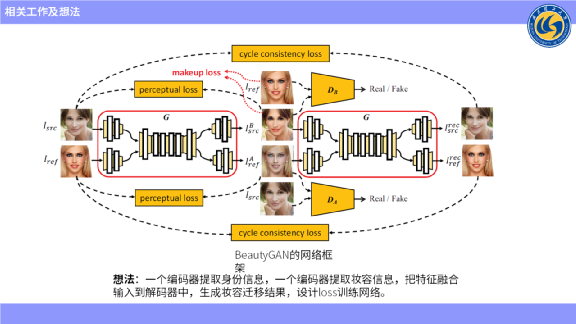
首先,介绍一个非常经典的、也比较简单的,发表在A类会议上的一篇论文——BeautyGAN。
它的想法是,一个编码器提取人物的身份信息,另一个编码器提取人物的妆容信息,把这两个信息进行融合,然后输入到解码器中生成妆容迁移结果。
上图左上角是没有化妆的图像,右上角是化妆图像,经过编码器之后用来提取身份特征和妆容特征,然后输出两张图像,一张是产生妆容迁移的结果,另一张是妆容移除的结果。
然后把这两张生成的图像再次输入到网络中,按理说妆容图像再次交换之后,应该可以复原到原始的结果,这里边设计了一个cycle loss,希望能还原回去。
第二个是妆容迁移过程中需要保护人物的身份不变,所以又设计了一个感知loss,需要妆容迁移的结果在迁移的过程中保持不变。
第三个是希望迁移参考图像的妆容,因此设计了一个妆容loss,经过直方图匹配来生成一个实例的图像,从而约束图像的生成。
第四个loss是用GAN做的,用判别器来判别生成的妆容迁移的结果是属于妆容域的,这个想法是很简单的,把两个条件作为输入,输入到一个双输入网络,产生妆容迁移的结果。相当于内部网络自主地进行一些妆容的交换,再输入到里边生成结果。这些网络,不管是解码器还是中间层,用的都是最普通的卷积。
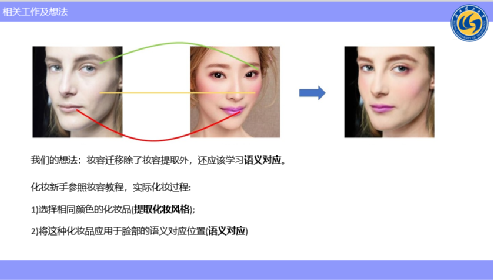
当时我们在考虑一个问题,当模拟实际化妆的一些场景时,妆容迁移除了妆容提取外,还应该去学习语义对应。
新手化妆的时候,通常会参考化妆教程来进行化妆,比方说想画口红,她首先要看到口红的色号,去选择这个色号,再把口红涂到自己的嘴唇上;比方说腮红,她首先也要取一个那种腮红的色号,再涂到自己的脸上;在眼影这些位置,他会找一些眼影、眉笔来进行勾画。
所以我们发现,化妆其实是分为两个步骤的,第一个步骤是选择相同颜色的化妆品,这一步我们就可以定义为“提取妆容风格”,提取了妆容风格之后,需要把这个化妆品应用到脸部的“语义对应位置”,这是beauty GAN没有进行建模的,beauty GAN并没有学习语义对应。
所以,我们就考虑能不能在妆容迁移里加上语义对应,用语义对应来提升妆容迁移的效果。既然有了这个想法,就看看如何实现语义对应的建模。
三、想法的代码实现
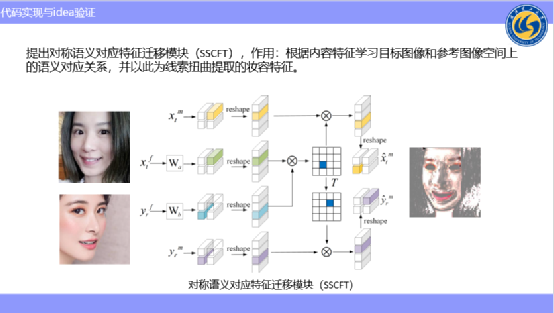
其实语义建模也比较简单,大家如果对 Self-Attention比较了解的话,它是做的每个位置和所有的位置的相似度的建模,所以我们这里也是参考Attention来设计了一个语义对应特征迁移模块。
不同的是,Self-Attention的输入是同一个,我们输入的是原图像没有带妆的特征和参考图带妆的特征,这里想学习到原图像和参考图像之间的空间位置的语义对应关系,通过这种对应关系去扭曲提取的参考图像的特征,使扭曲的参考图像的特征与原图像达到语义对齐的目的。
大家可以详细看一下,这里的xtf就是原图像的提取特征,yrf是参考图像提取特征。这些都是Attention里边的一些模块,reshape之后,进行矩阵乘法,来计算每个空间位置上两个图像之间的相关性,再用这种相关性去乘以提取到的参考图像的妆容特征来进行空间上的重新分布,最终得到扭曲的特征。
大家可以看右边这张图,用相关性矩阵乘以左下角这个图像,得到右边的图像。可以看到乘以了之后的图像是与原图像进行语义对齐了的,这一步已经实现了我们想要达到的语义对齐的步骤,我们刚才想模拟的就是眼妆、腮红等每个空间位置上的映射,达到了语义对齐的目的。
同时我们发现,语义对应是一对一的对应,比方说A对应B,同时B又对应A,那能不能利用这种对称性来做一些文章呢?我们发现妆容迁移有个反任务——妆容移除,所以我们就把语义对应的对称性进行转制,转制之后乘以原图像的妆容特征来进行妆容移除。
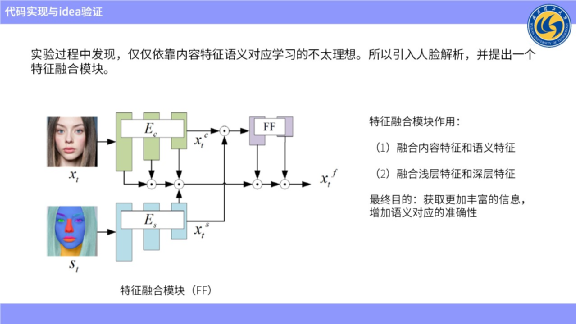
有了这个想法之后,我们就去实验,并在实验过程中发现,仅仅设计这样一个模块,很难达到较好的语义对应效果。为了提升模块的语义对应效果,引入人脸解析,以便往模块里注入空间信息。
人脸解析对应上图左下角的人脸解析模块,它的工作原理是解析这个图像并标记出哪里是嘴唇、鼻子、眼睛、眉毛、脸、头发。
引入人脸解析模块是为了提供尽可能多的空间信息,来达到更好的语义对应效果。
为了进一步赋能人脸解析模块,我们又设计了一个特征融合模块。融合模块的具体作用是把不同的编码器提取特征后进行融合,输入到一个特征里面。在这个特征上进行采样,并完成通道维度的拼接,以便进行最后的特征匹配。
特征融合模块有两个基本作用。一个是融合提取到的内容特征和语义特征,另一个是融合浅层特征和深层特征。而进行拼接操作,就是为了融合浅层特征和深层特征。
我们的想法主要是受到了金字塔的启发,比如他们发现浅层特征偏向于纹理特征,深层特征偏向于语义特征。因为不管是纹理特征,还是语义特征,对于语义对应都是有帮助的。所以我们想尽可能融合丰富的特征,来获得更加准确的语义对应。换而言之,最终目的是获取丰富的信息,来增加语义对应的准确性。
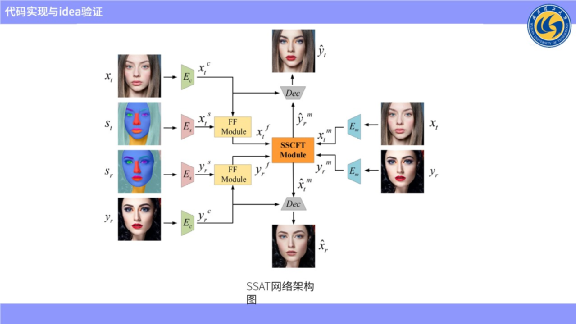
最终网络是如上图所示的设计。左部和右部是输入的图像,上部和下部是输出的图像。
Ec代表内容编码器,用来提取除妆容之外的所有信息,现在提取到的内容是Xtc,但同时要提取它的语义信息是Xtf。将这两个信息输入到特征融合模块,输出一个融合信息Xtf。Xtf就是融合特征,进行特征匹配。同样的我们提取参考妆容的内容,提取参考图像的语义来进行融合模块,来获取它的Yrf融合特征,并把这两个特征用来进行语义匹配。
Em代表妆容编码器,用来提取原图像以及参考图像的妆容信息。由上图可见,SSCFT模块,输入的是Xtf、Xtm、Yrf、Yrm 4个参数,刚好对应上文图中的4个参数。这4个参数的作用是扭曲提取到的妆容特征,把参考图像的状况特征扭曲成与原图像语义对应的妆容特征。把从未化妆图像中提取到的妆容进行扭曲,并与参考图像进行语义上的对齐。最后把语义已经对齐的妆容,和它的内容特征进行拼接并输入到解码器中,这就是整个网络结构。
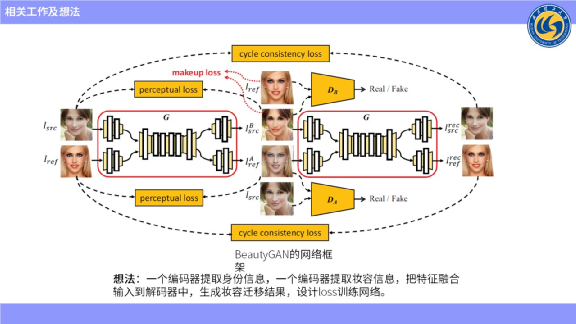
通过与上图比对可知,我们与BeautyGAN网络框架的主要差异在输入到解码器之前进行了语义对应,来使妆容特征与原图像语义对齐。而最终目的就是希望通过语义对齐模块来提升妆容迁移的效果。
所以我们设计了上图所示语义对应模块,并发现只用内容特征来进行匹配,语义对应效果不是很理想之后,又引入了人脸解析,并设计了融合模块来获取更加丰富的特征,来增加语义对应的准确性。
上图就是最终把语义对齐妆容与内容特征进行融合,输入到解码器中生成的最终结果。

以上就是网络部分。
接下来讲一下Loss。因为Loss对于网络的训练是至关重要的。现在基本上都是生成伪成对数据来指导妆容迁移。主流的伪成对生成方法有两种,一种是直方图匹配,一种是特征点扭曲。
我们融合了这两种数据生成方法。因为人脸特征点只分脸部部分,所以对脸部部分进行了特征点扭曲。但对于耳朵,还有脖子这种特征点检测不到的部位,进行了直方图匹配,生成了一个伪成对数据来进行妆容迁移的指导。最终大概是生成了18万对这种数据。
我们采用的是SPL损失函数来指导妆容迁移。这个函数的主要作用有两点。第一点是约束生成的伪成对数据与生成的数据在颜色域上要尽可能的保持一致。又同时约束生成的图像和原图像在梯度信息上尽可能的保持一致。
为什么需要这么约束呢?
上文介绍妆容迁移的时候,我们就提到,妆容迁移有两个目标。一个是保持原图像的人物身份不变,因为我们发现,约束梯度信息很大程度上是可以保持人物身份的,所以这里进行梯度信息的约束,就是为了保持人物身份的不变。另一个,因为保持人物身份之后还要含有参考妆容的妆容信息,所以又约束了生成的结果和伪成对的匹配对在颜色域上尽可能保持一致。
以上就是用SPL的原因,它比较契合妆容迁移的两个目标。同时因为我们设计了语义对应,考虑到语义对应是没有有效的监督信号的,就又设计了一个比较弱的监督信号。
监督信号是什么意思?拿语义解析图讲,要求在相同的类别在进行映射,比如鼻子映射到鼻子区域,嘴巴映射到嘴巴区域,不能映射到其他类别区域。所以设计了这个语义loss,要求映射要在相同语域区域内进行映射,同时因为采用了GAN,生成图像模式同样用GAN,所以设计了一个对抗loss,同时受到BeatyGan的启发,引入了一个Cycle loss。就和BeatyGan一样,把生成的妆容迁移结果和妆容移除结果,输入到网络中进行妆容的再次交换之后,应该去生成原始的结果。
同时我们也引入了一个就是自建损失,这个是表示什么?把提出了原图像的身份信息,和提取了原图像的妆容性信息,把这两个直接输入到解码器中,希望它能复原出原始的图像。
这里运用的是特征解耦思想,解耦之后把两项合并之后再输入到解码器中应该是生成原始的图像。我们设置了4个loss,第一个是语义loss,但是没有很好的监督信号,只提供一些比较弱的监督信号来进行监督。
第二个是妆容loss,其比较契合妆容迁移的两个目标,一个是约束身份不变,另一个有参考同样的妆容,并且参考的 Spl loss还是比较好的做到这一点。
这里还运用了解耦的思想,妆容从图像中进行信息解耦,出来之后进行交换一下,两次交换之后就应该能重建出原始的图像,如果没有交换的话,就应该自建出自身的图像。同时为了增加图像的真实感,又引入了GAN网络来进行一些对抗训练。
这就是我们的想法,怎么再用代码去实现想法。
可以大致梳理下,最开始就想学习一个语义对应,就想学习加入语义对应。之后受到attention的启发,因为attention是计算空间语义相关性,只不过输入是不一样的。所以最终网络是这样设计的,我们跟beauty GAN相比,就是在输入到解码器之前,进行了语义对应,把提取的重要特征进行了语义对齐。

最终的实验结果,如正面的测量,左侧是没有妆容的目标图像,最上方图像这是一些参考妆容。第二行就是学习到的语音对应,可以简单理解为把最上面图像一点一点移到与它对应的空间上,比如眼妆、口红等,说明这种语义对应已经捕获到了目标。
下面就是最终生成结果,是先进行语义对应再输入到解码器中得到的结果。可以看到在这种有pose姿态变化扭动的状态下,也可以生成比较好的结果。

并且我们与最先进的方法进行了一些对比,我们选取了18年的Beaty GAN, 20年的CVPR PS GAN ,21年的CVPR SC GAN ,在正脸的情况下进行对比,可以看到对于比较精致细小的眼妆,我们的效果是明显好于前三个的,同时对于大面积的腮红,也可以达到比较好的效果。同时比方说PS GAN和 SC GAN 的腮红迁移的不是很好。而我们为什么能迁移腮红,可以看到腮红基本上与我们最终的结果是相互拟合的,比方说眼妆的颜色与颜色之间是有对应关系的。

同时因为我们学习到语义对应,所以可以处理一些姿态表情鲁棒的,因为不管姿态差异性,在学习语义对应之后,都是与目标图像进行语义对齐的,所以可以很好的处理姿态表情各种变动的情况。
即使在比较大的的姿态变化下,对于细小眼妆的迁移效果也是比较好的。之前的这三个方法几乎是看不到眼妆迁移的效果。如此对照看过之后,就可以理解我们效果会更好一些。

同时因为此设计的语义对应的要求,是在相同的语义区域内去做对应,所以比如有头发遮挡或者眼镜遮挡,这种情况是学习不到语义对应的,网络自适应会不去学习它的对应关系而把这部分屏蔽过去,只学习面部区域之间的语义对应。所以,我们的方法对物体遮挡也是具有鲁棒性的,例如戴上眼镜的效果,同时我们也做了消融实验。
四、实验结果分析
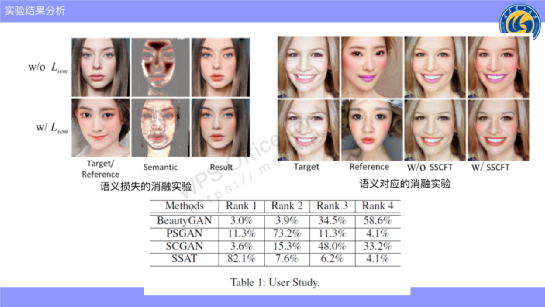
我们提出了一个语义损失函数来监督语义对应关系,上图显示了没有使用语义对应的和使用了语义对应的结果,可以看到,我们的语义对应至少与与目标图像是保持基本上一致的。
因为没有学习到很好的语义对应,可以看到,腮红遍布整个脸,而我们的方法中,腮红与参考图像的语义是对应的,比方说额头部分就没有,因此,良好的语义对应是对妆容提升有帮助的。
同时,我们也做了一些就是不去设计语义对应的模块,它效果是怎么样的?如上图所示,不加语义对应的唇色偏暗,比方说嘴唇比较紫的。
所以,加上语音对应的话,妆容的相似度视觉上是明显提升的。
同时我们也进行了一些用户研究,也就是把4个不同的方法,生成4种不同结果,然后打乱顺序,形成问卷来去交给志愿者去打分,最后,我们方法最好的效果是明显优于其他结果的。

因为我们把妆容特征从图像中抽离了,除了上面提到妆容迁移之外,只要对提取的妆容特征进行一些差值,还可以达到妆容调控的目的。
在妆容迁移应用范围,我们想达到妆容搭配,可以搭配不同的口红色号,就能在保持其他妆容不变的条件下单独调配色号,比方想要一个粉一点、些紫一点的嘴唇,就可以通过局部装饰迁移操作来进行局部搭配的效果。
同时,我们也介绍到了我们利用云对称性来进行妆容移除,可以看到,我们可以生成多模态、多种的妆容艺术结果。不过,我们研究重点是妆容迁移,妆容移除我们只是想实现这个效果。
妆容移除的方向主要为增强人脸的识别性,但是不属于我们的研究范围,我们只是想实现妆容迁移效果。我们的做了一个相应的视频,给大家呈现一个更加直观的效果。

可以看到,我们的眼妆是比较好的,结果比较平滑,大面积的腮红迁移的也是比较好的。
上述链接也提供了训练好的模型,大家可以稍微玩一下,非常简单就能实现装迁移的效果。
五、科研心得与体会

最后介绍一下我自己做研究的心得体会。
我是从2019年研二才开始学习深度学习,之前是做传统方法的,后来因为数学方面考虑转到了深度学习。
我将从四个方面给大家分享一下我的研究心得:
第一方面是论文阅读,因为我做妆容迁移,总共论文数量大概30多篇,当时把这30多篇都看完之后我发现是不够的。如果想做创新,要尽可能的读一些相关领域的研究,不要太泛,太泛的话,会找创新点的方向,比方说想做语义对应,就去看了相对应的五篇论文,觉得attention可以做。
接下来看一些用attention做语义对应的论文,如果有代码,就将代码下载下来,同步看能不能实现同样效果。
第二点是博士最少每天要大概精读一篇论文,因为论读多了才会有创新。
第三点是论文读完之后有不懂的地方一定要看代码,我发现有些同学论文是读懂了,但是他不懂这个网络是怎样实现的。
所以,怎样才叫读懂一篇论文呢?就是读完之后,自己能将其网络框架写出来,Loss也能写出来,这样就算读懂了一篇论文。
第二方面是学术研究的心得。
我做这些研究是如果有了想法,就立马做一个很小的实验小模型尽快实现这个想法,只要有一点效果,就说明这想法是可行的,我再去一步一步的完善。
第二是每个想法不一定都行得通,如果发现这个想法行不通就去想别的想法。
第三是要有耐心,硕士毕业是也有论文要求,我看的那些大佬们中A我当时也很着急,但也没办法,只能一步一步来。
第三方面是投稿的心得。
首先投稿最好先确定选择投什么会议,然后用这个会议的deadline去倒逼自己出结果。第二是写论文,好多人反映不会写论文,我当时也经历过同样的问题,也问过一些老师要如何做,答案是要多写,写多自然就会。第三是论文是否被选中,中论文有些运气的成分,不中也不要气馁,相对于中与不中,投论文会更重要一些。我目前是七投二中。
第四方面是读博的心得。如果对方向不感兴趣的话,是不推荐读博的,硕士相对毕业并不是很难,但是博士毕业是有硬性条件,而且读博很苦。有反馈说读博老师指导较少,但我觉得读博主要靠自学,老师给你提供好实验的环境和算力资源就已经完全可以了。如果有一些科研想法可以和老师交流,老师给到指导,还是要靠自己去学习。
最后一点是读博很累,大家要考虑清楚。
论文链接:https://arxiv.org/abs/2112.03631










