我已经有两年 ML 经历,这系列课主要用来查缺补漏,会记录一些细节的、自己不知道的东西。
已经有人记了笔记(很用心,强烈推荐):
https://github.com/Sakura-gh/ML-notes
本节对应笔记:
- https://sakura-gh.github.io/ML-notes/ML-notes-html/13_Tips-for-Deep-Learning.html
- https://github.com/Sakura-gh/ML-notes/blob/master/keras-tips.md
本节内容综述
- 本次内容讲顺带解决CNN的中两个问题:
1是max pooling中无法为max微分,梯度下降时该怎么办;2是正则化L1如何解释。 - 深度学习中有两个问题:如何解决在
training data或testing data上效果不同的问题?对于前者,是否是设计的不够好?可以考虑从new activation function、adaptive learning rate入手;对于后者,本节课将从early stopping、regularization、dropout入手讲解。 - 对于前者,可以更换激活函数,引出了
ReLU 与ReLU - variant ,又详细讲了Maxout 。 - Maxout的训练回答了
1. 中提出的 max pooling 的问题。 - 接着,开始讲解
Adaptive learning rate 的内容。介绍了 RMSProp 、 Momentum 与 Adam ,具体可以见【李宏毅2020 ML/DL】P8-9。 - 接着开始介绍关于
Early Stopping的现象,见[小细节](#Early Stopping); - 接着,开始介绍关于正则的内容,包括
L2正则,L1正则,二者对比,weight decay等,见小细节 - 对于 Dropout,先讲了是什么怎么做,再讲为何做。见小细节
小细节
梯度消失 - 考虑更换激活函数
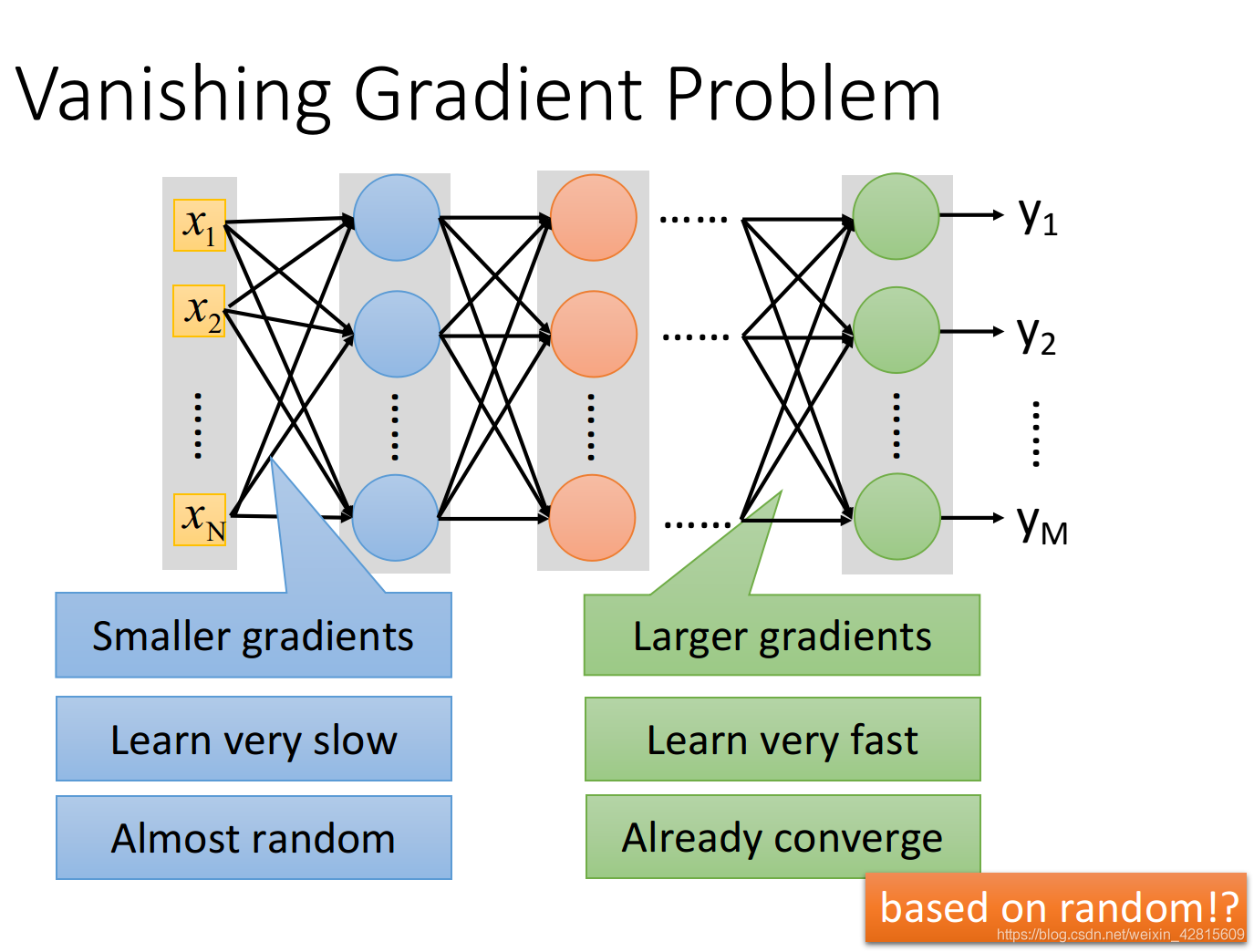
如上,在前面的层与后面的存在梯度“不对等”的问题,不在同一数量级。
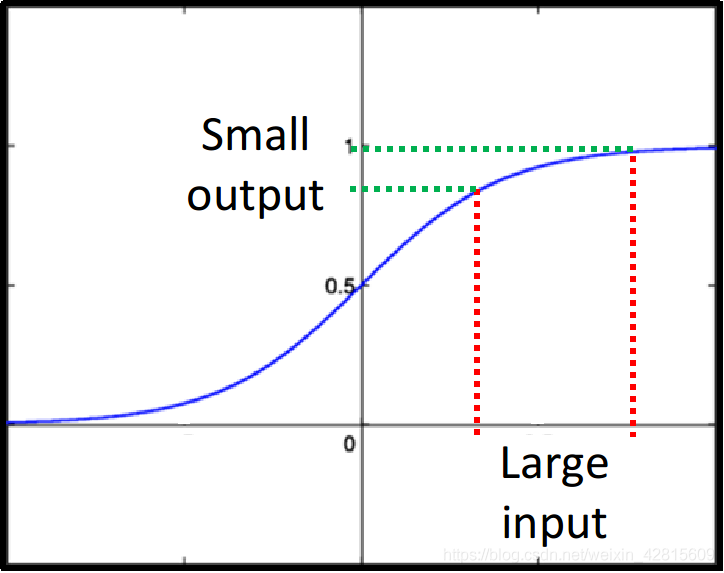
对于 sigmoid 函数,1到正无穷时,其值都是接近1的,变化不大。
这就造成第1层,或者说比较前面的层,其参数即便改变很大,到后面的影响也很小了。
因此,更改激活函数是一个好的解决方案。
ReLU
选择 ReLU 的理由如下:
- 跟 sigmoid function 比起来, ReLU 的运算快很多
- 结合了生物上的观察
- 无穷多 bias 不同的 sigmoid function 叠加的结果会变成 ReLU
- ReLU 可以处理 Vanishing gradient 的问题
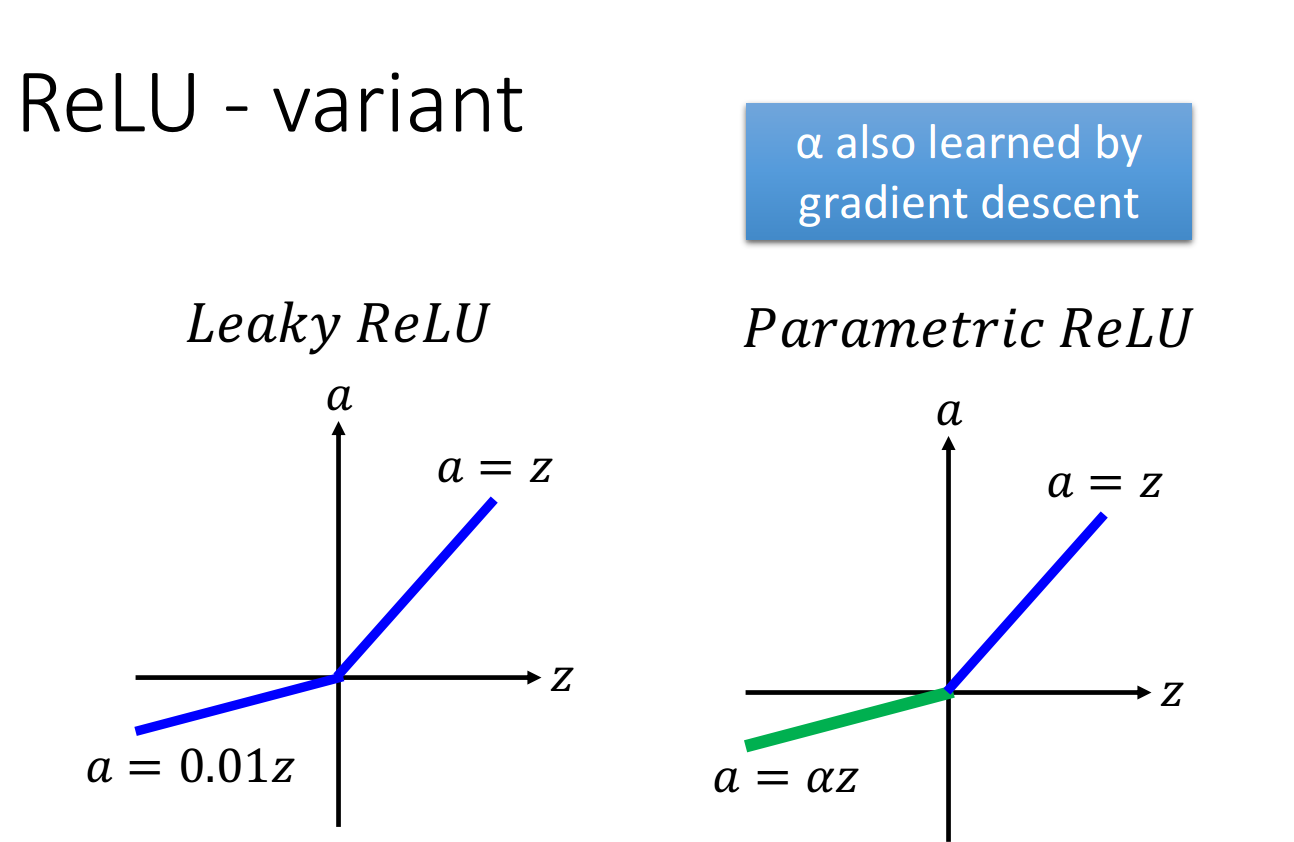
ReLU - variant
Maxout
Maxout network 是一种 Learnable activation function(lan J. 2013)
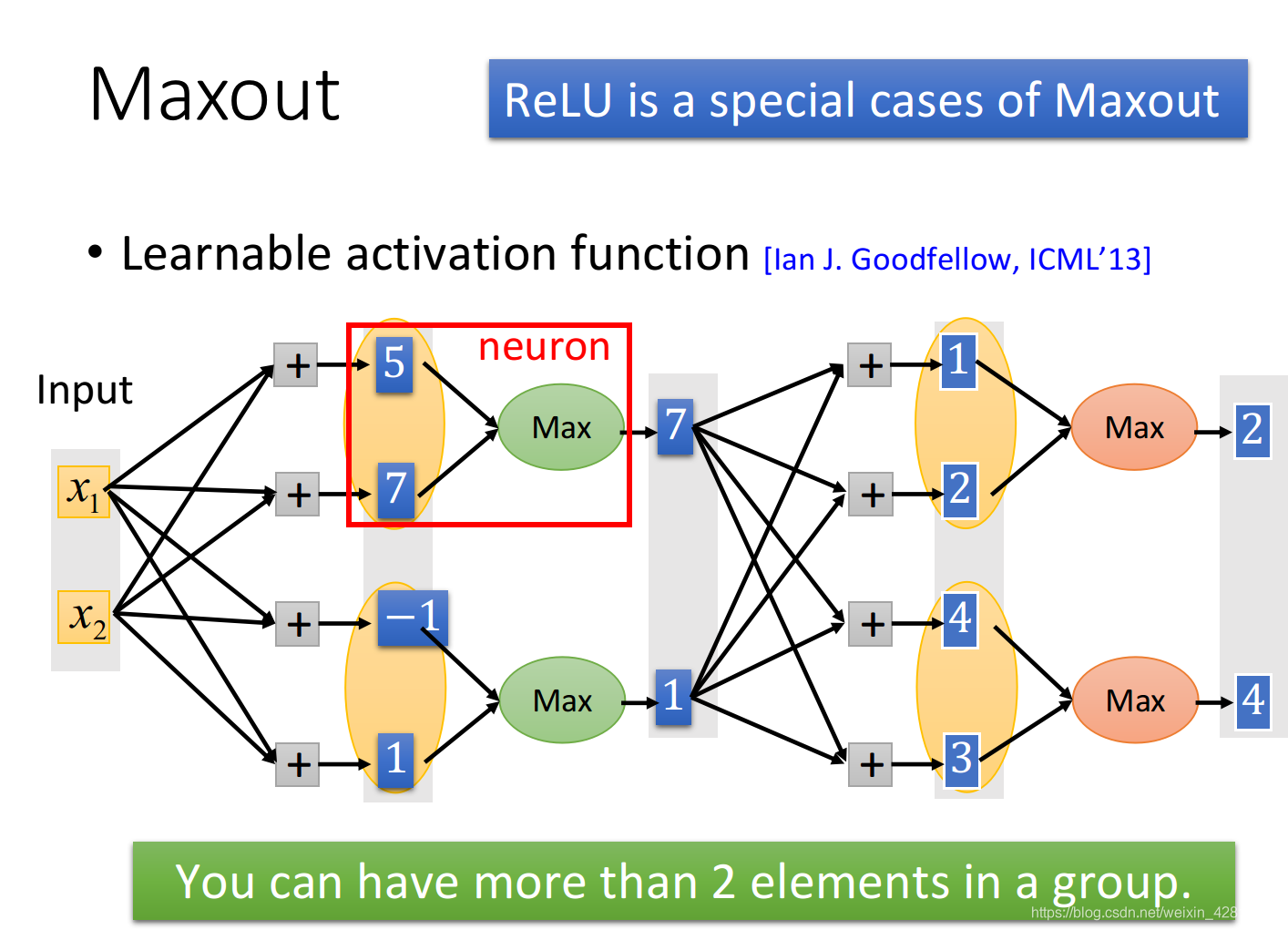
Maxout 有办法做到与 ReLU同样效果。如下图。
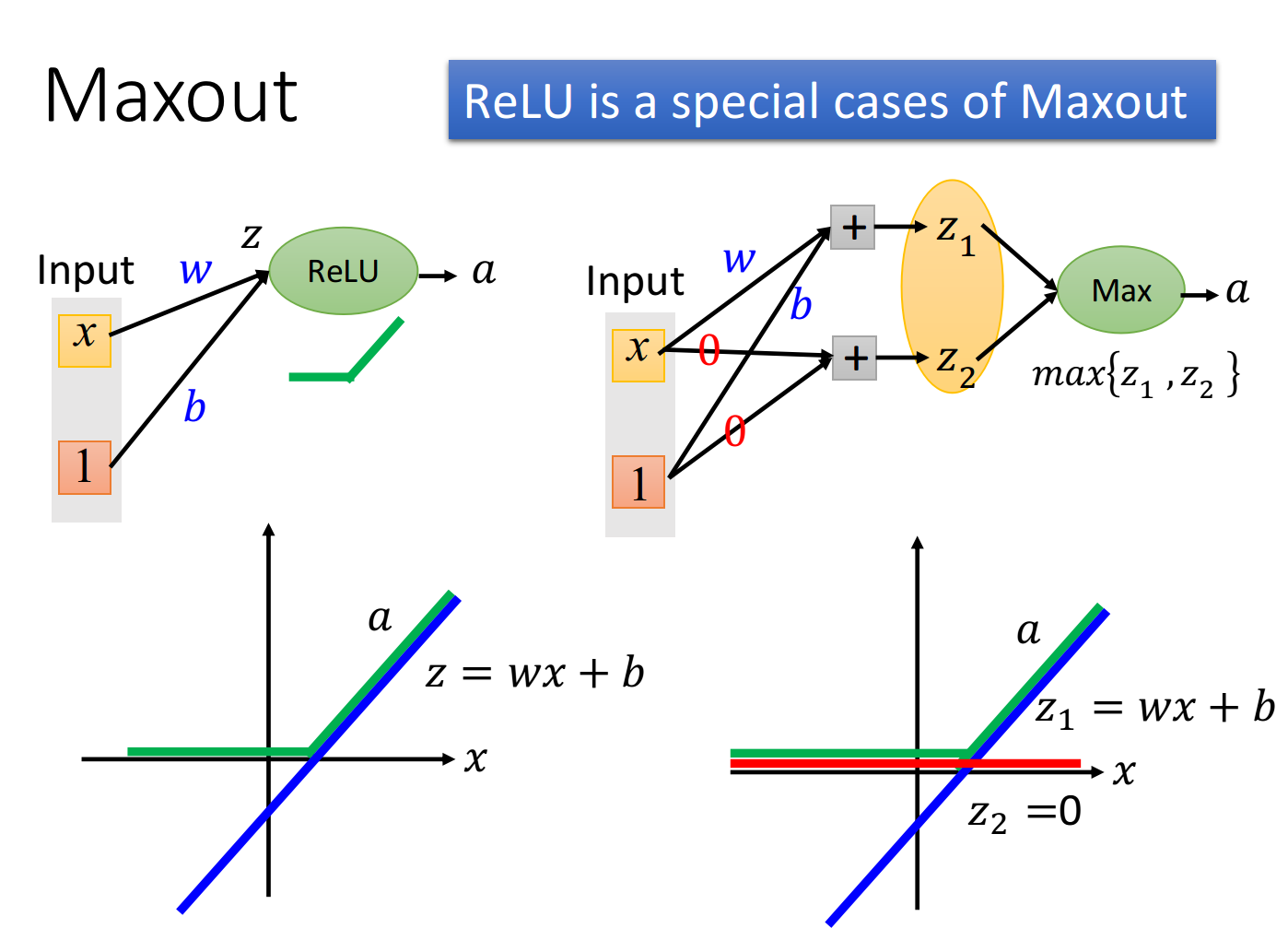
因此,可以说:ReLU是Maxout的特殊形式。
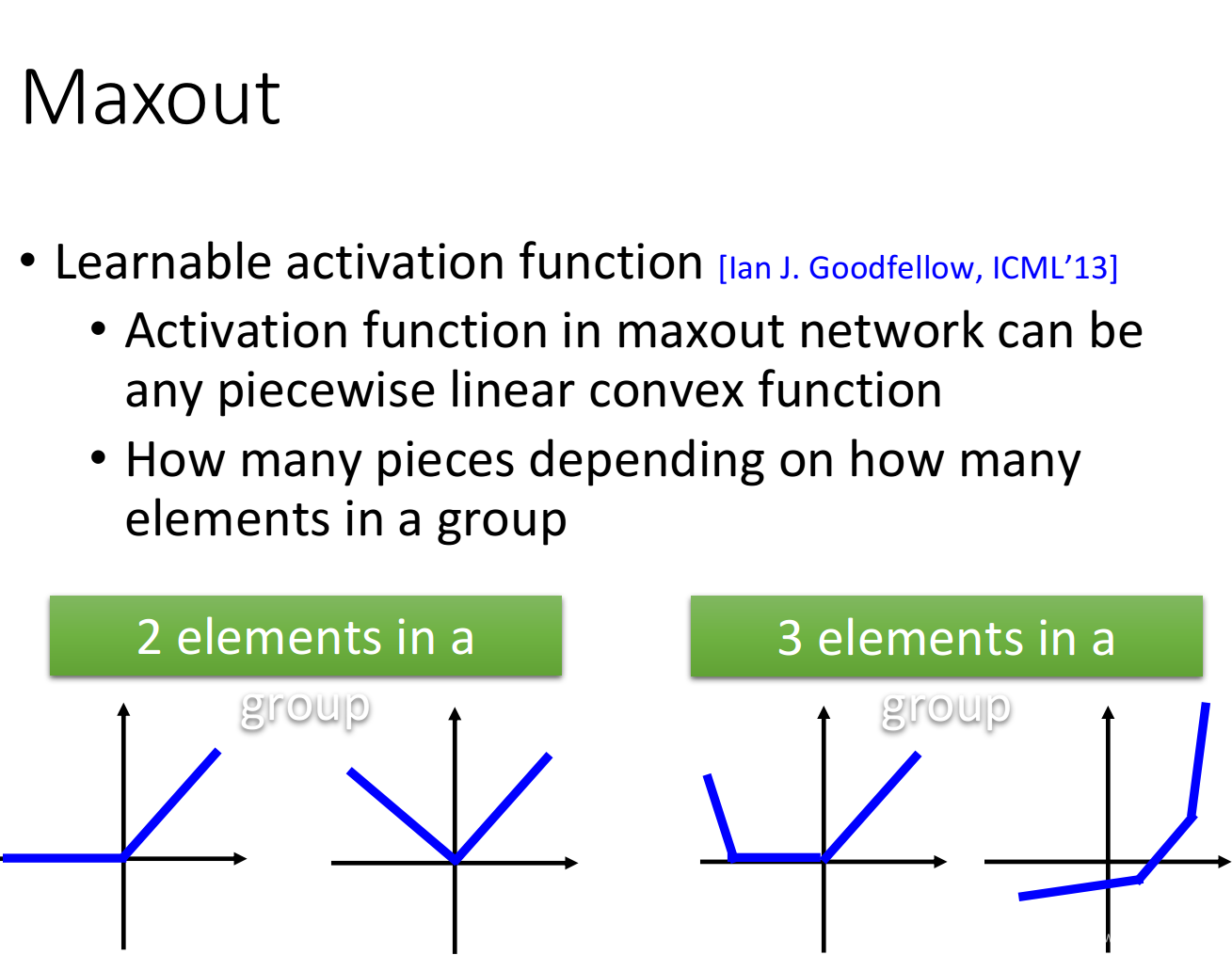
Maxout 的性质?
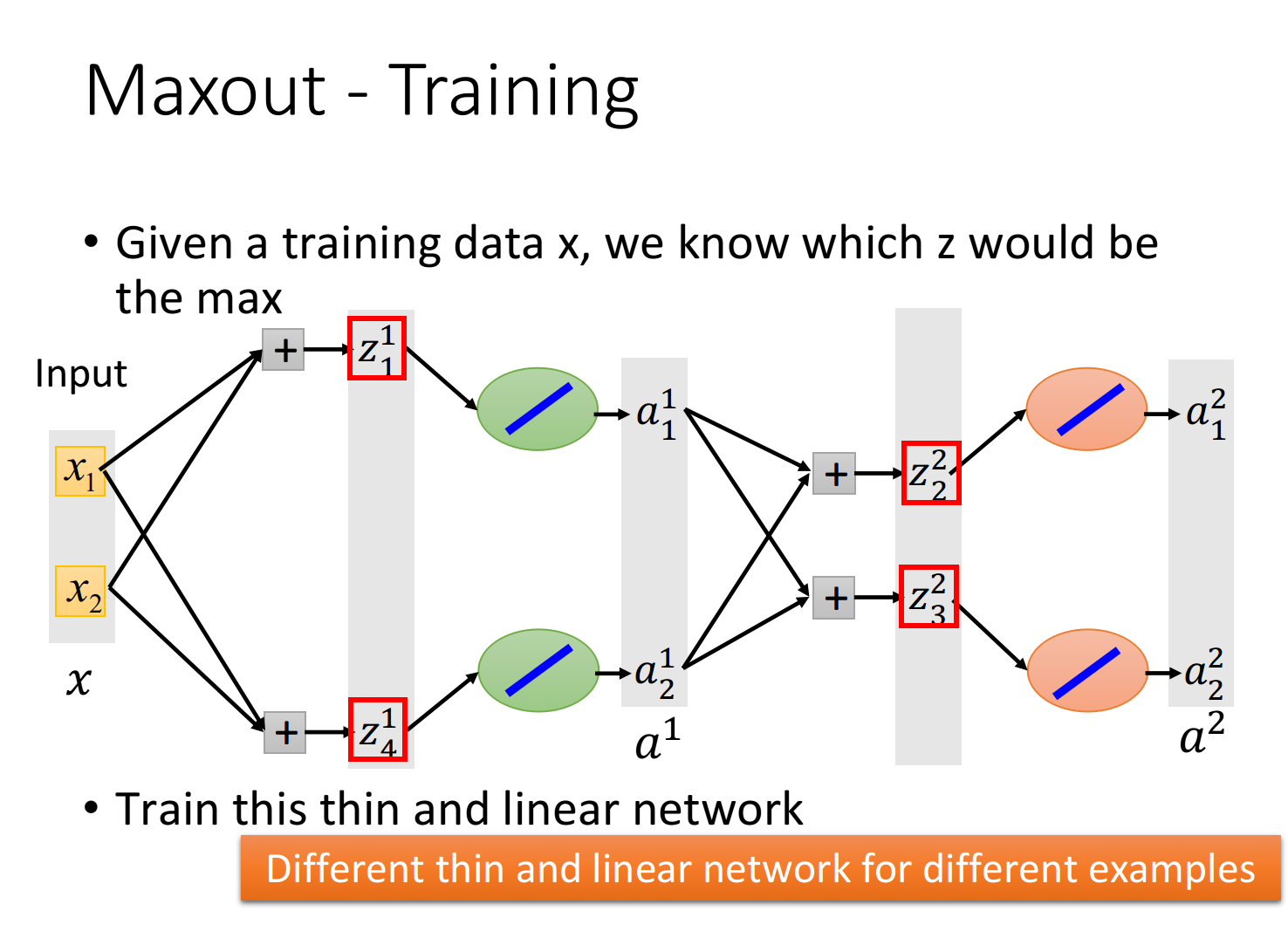
Maxout 如何训练?
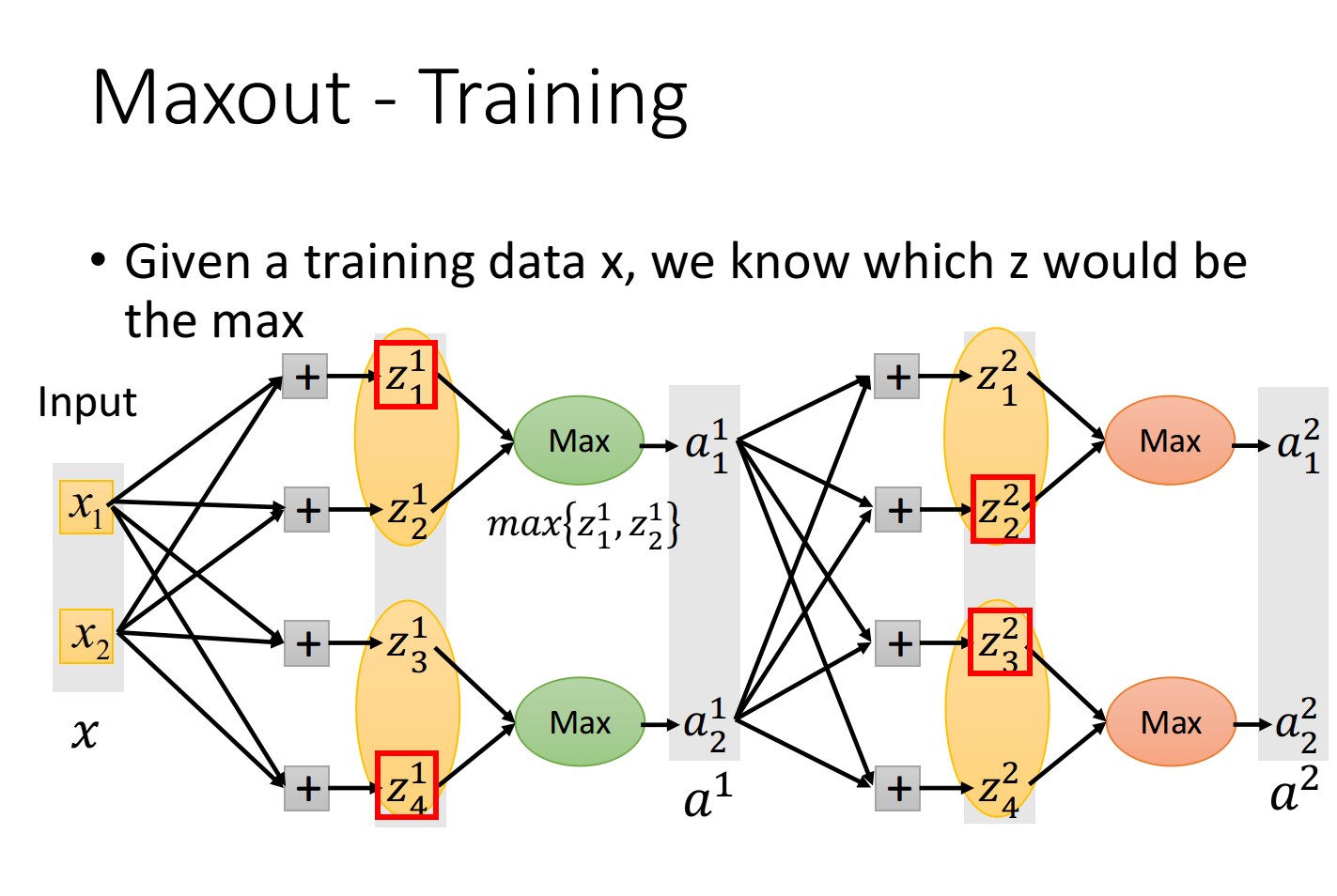
如上,再一次传播中,我们已经得到 Maxout 网络中选择哪个神经元。
接着,我们就把本次不参与计算的部分拿掉,如下。max函数无法微分,但是在具体实践中,我们可以根据数据把max函数转换成某个具体函数,再对这个转化后的 thinner linear network 进行微分。
Early Stopping
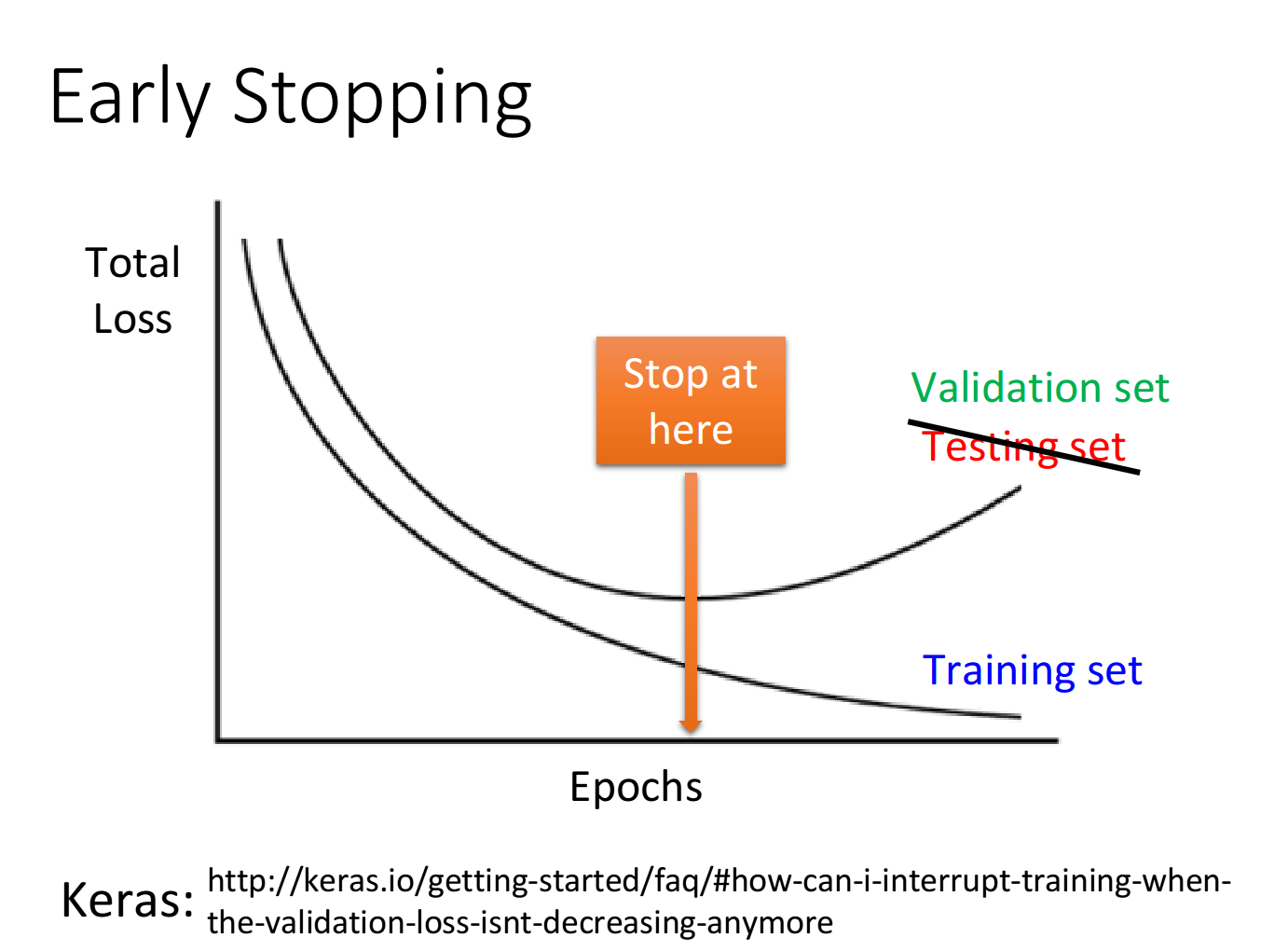
如上图,很有可能当 train loss 逐渐减小时,test loss 不降反升了。
Regularization
考虑到bias与平滑几乎没有关系,因此正则只是对w的处理。
L2 regularization
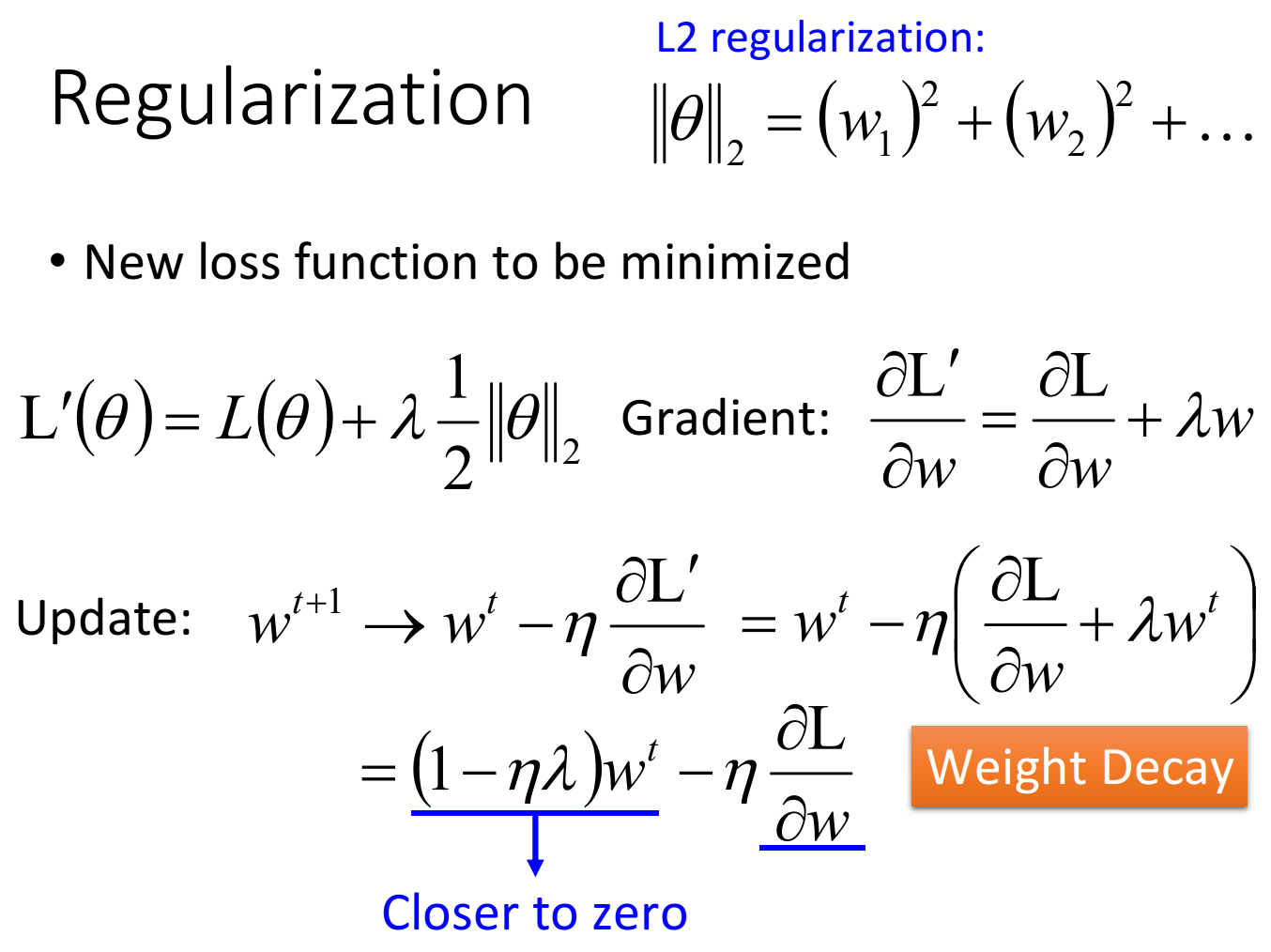
对于 L2 ,其效果有一种 Weight Decay 的效果。
L1 regularization
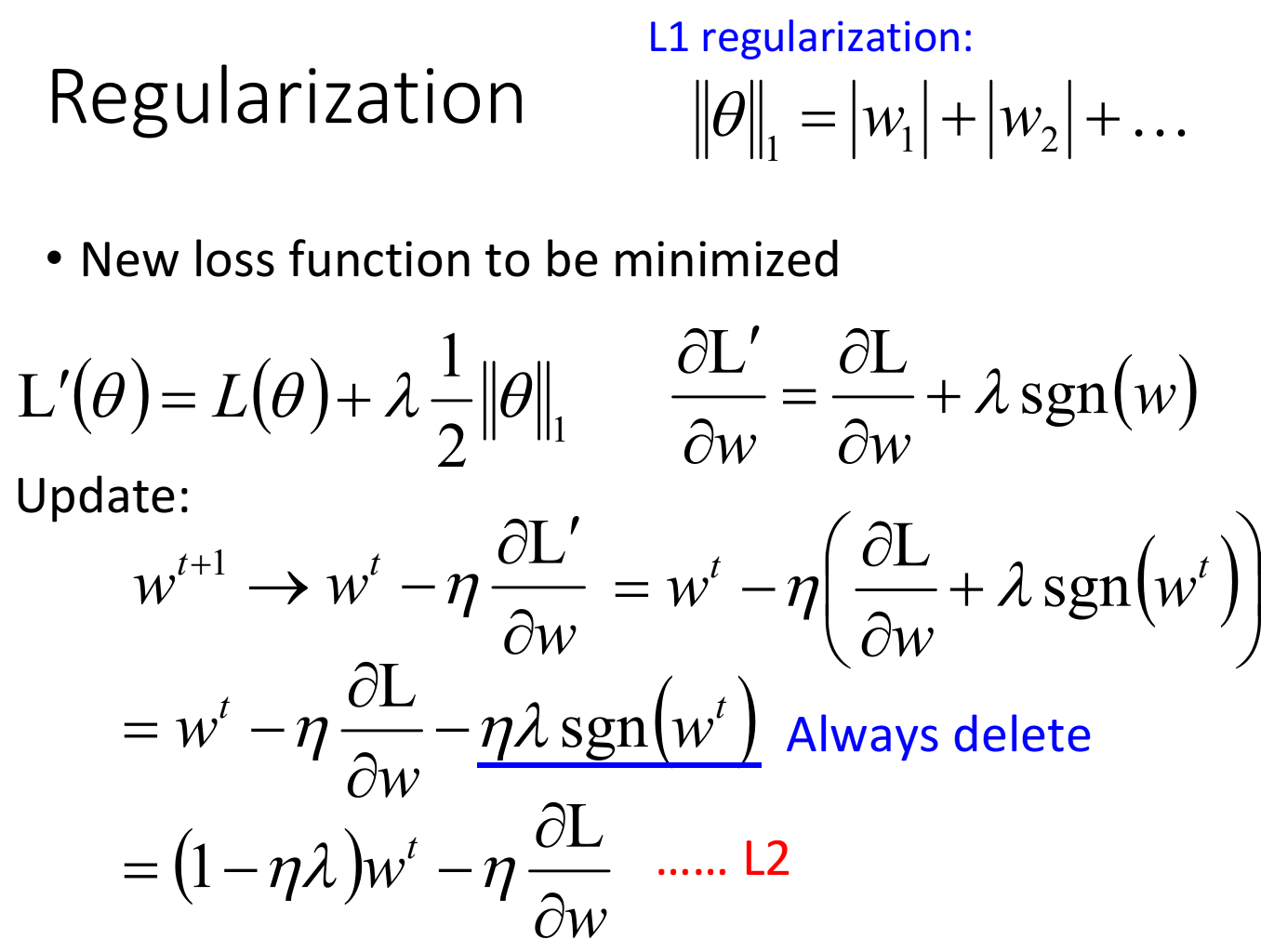
绝对值如何微分?使用sgn这个函数来近似。
对于 L1 ,其减去了一个固定值
η
γ
sgn
(
w
t
)
\eta \gamma \text{sgn}(w^t)
ηγsgn(wt) ,其值与
w
t
w^t
wt 大小无关。因此,用 L1 训练完,还可能出现比较大的参数,而且其在每次下降是是一个固定的值。这就造成L1的结果中,其参数比较sparse,有些比较大,很多事接近于0的。在CNN的任务中,使用L1比较合适。
Weight Decay

如上图,一些权重,如果不去更新,那么其每次都会越来越小,接近0。这与人脑的运作可能相同。
Dropout

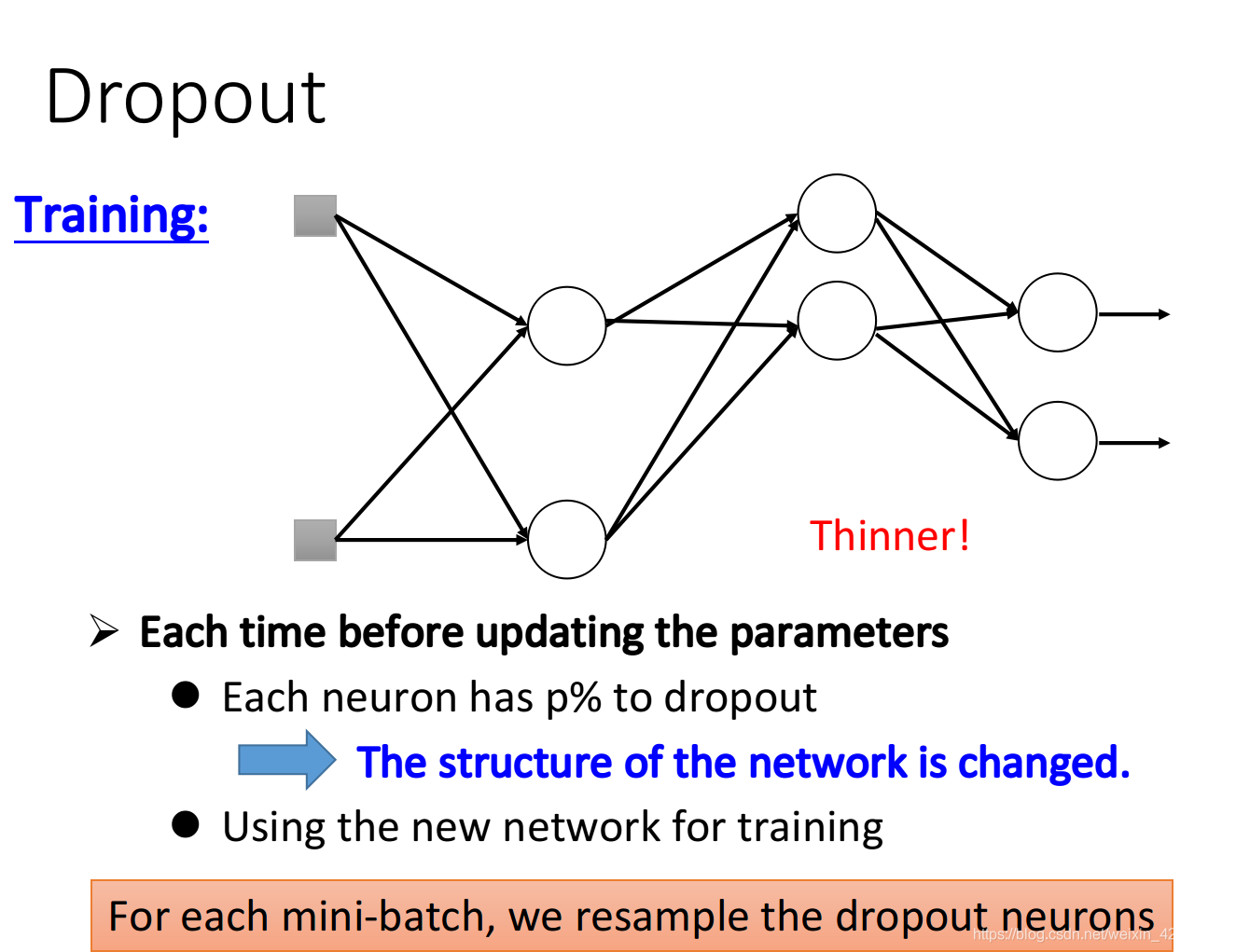
如上图,对于训练,每次更新参数前,我们用一定概率扔掉一些神经元。
注意:dropout 很有可能让 training 的效果变得更差,但有可能让 testing 的效果变得更好。是用来解决 testing 的问题的。
而对于训练时,dropout 的使用如下。

Dropout - Intuitive Reason

一个简单的类比是:
- 在训练时,“刻苦”一些,扔掉一些神经元;
- 在战斗时就会变强。
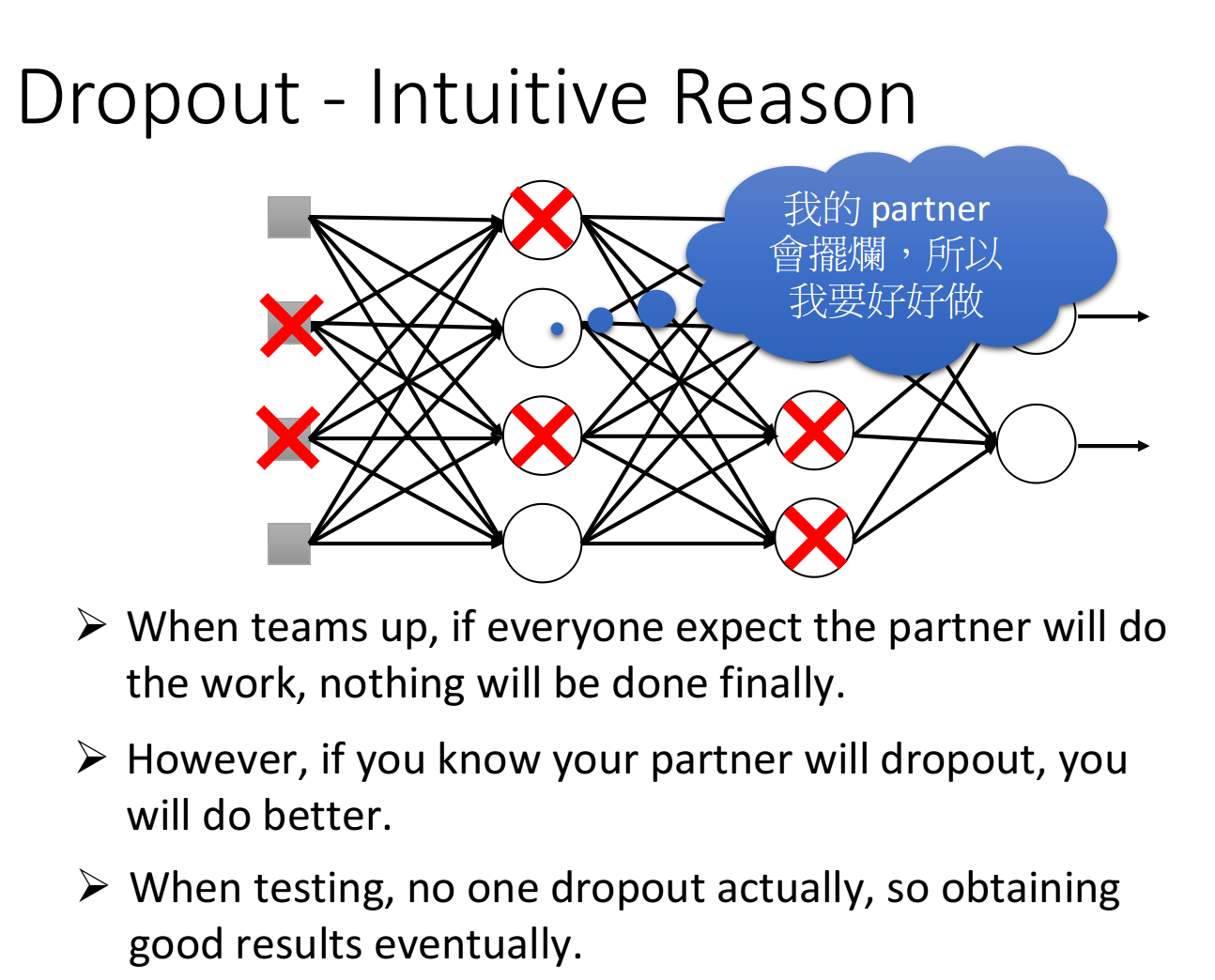
此外,也可以从集体的角度来理解,如上:
- 日常中(training),你认为你的队友会偷懒,因此自己加倍努力;
- 但真正做起事(testing),你的队友也不偷懒了。
为什么测试时权重要乘上(1-p)%?
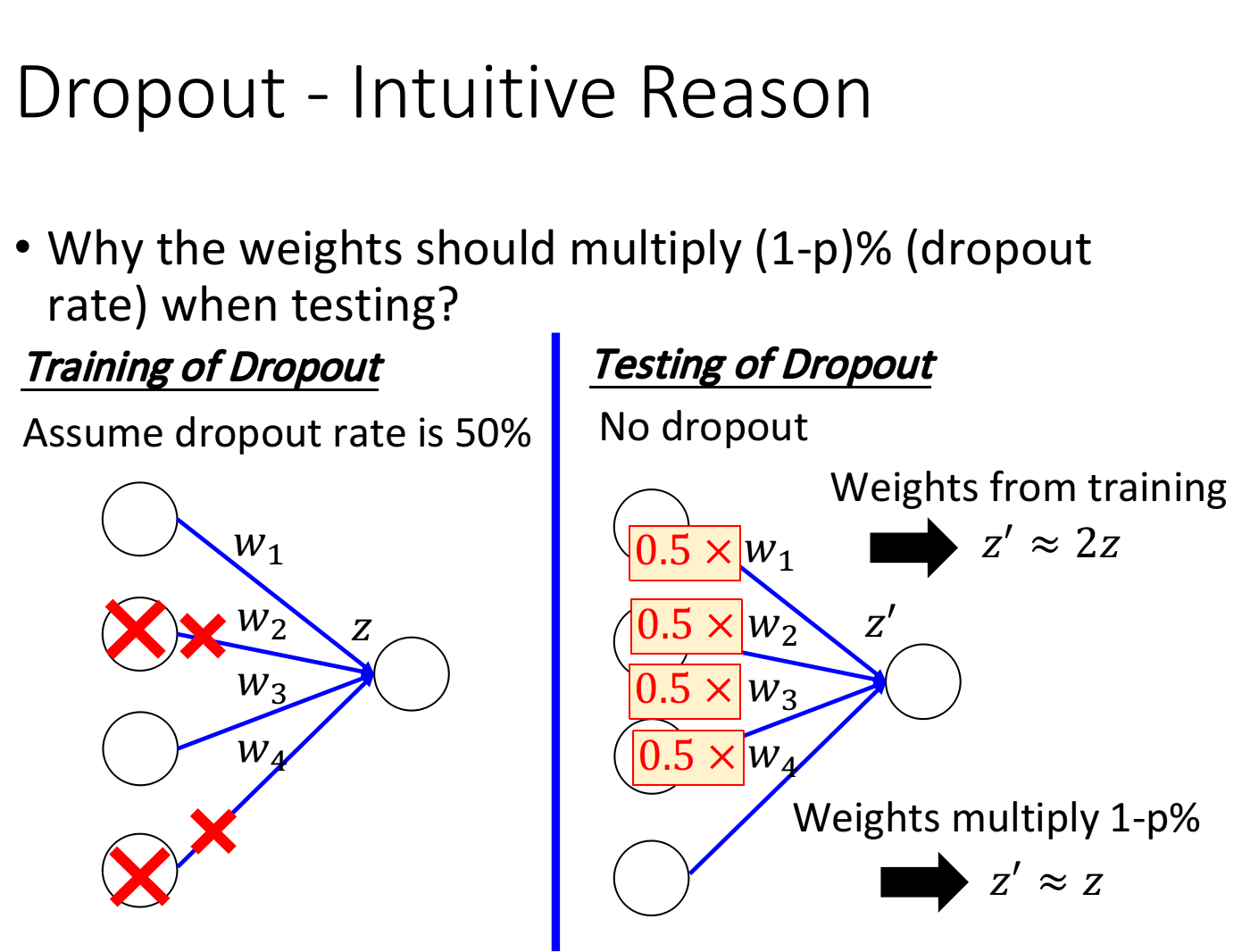
假设训练时,p=50%;则测试时,权重就乘上1-p=50%。这样防止得到的值成倍数增长。
Dropout is a kind of ensemble
对于集成学习 Ensemble ,其训练了多个模型,在使用(测试)时,则加权投票使用。
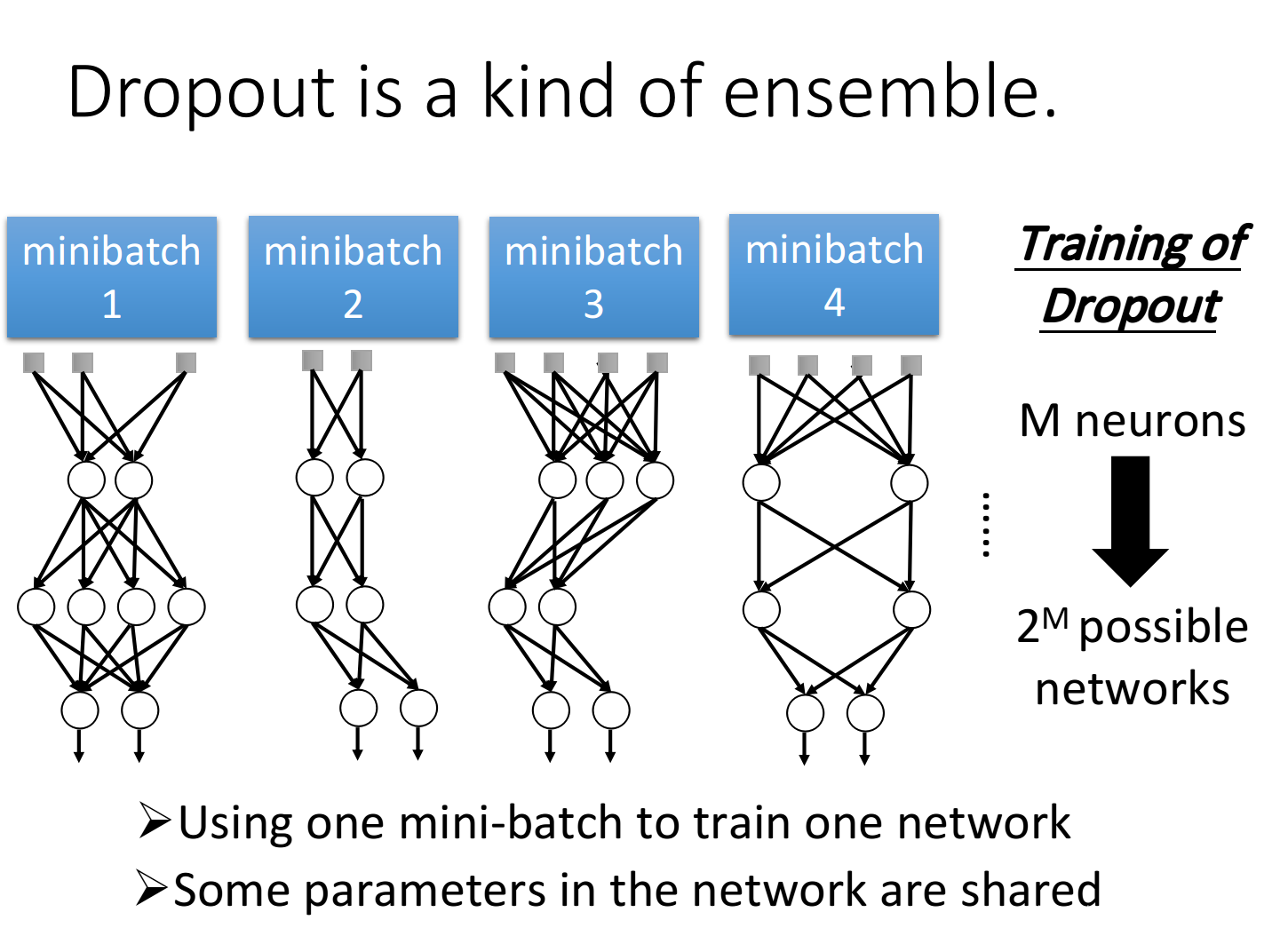
而 Dropout 则是一种“终极Ensemble”,其训练了 2 M 2^M 2M种可能的模型。
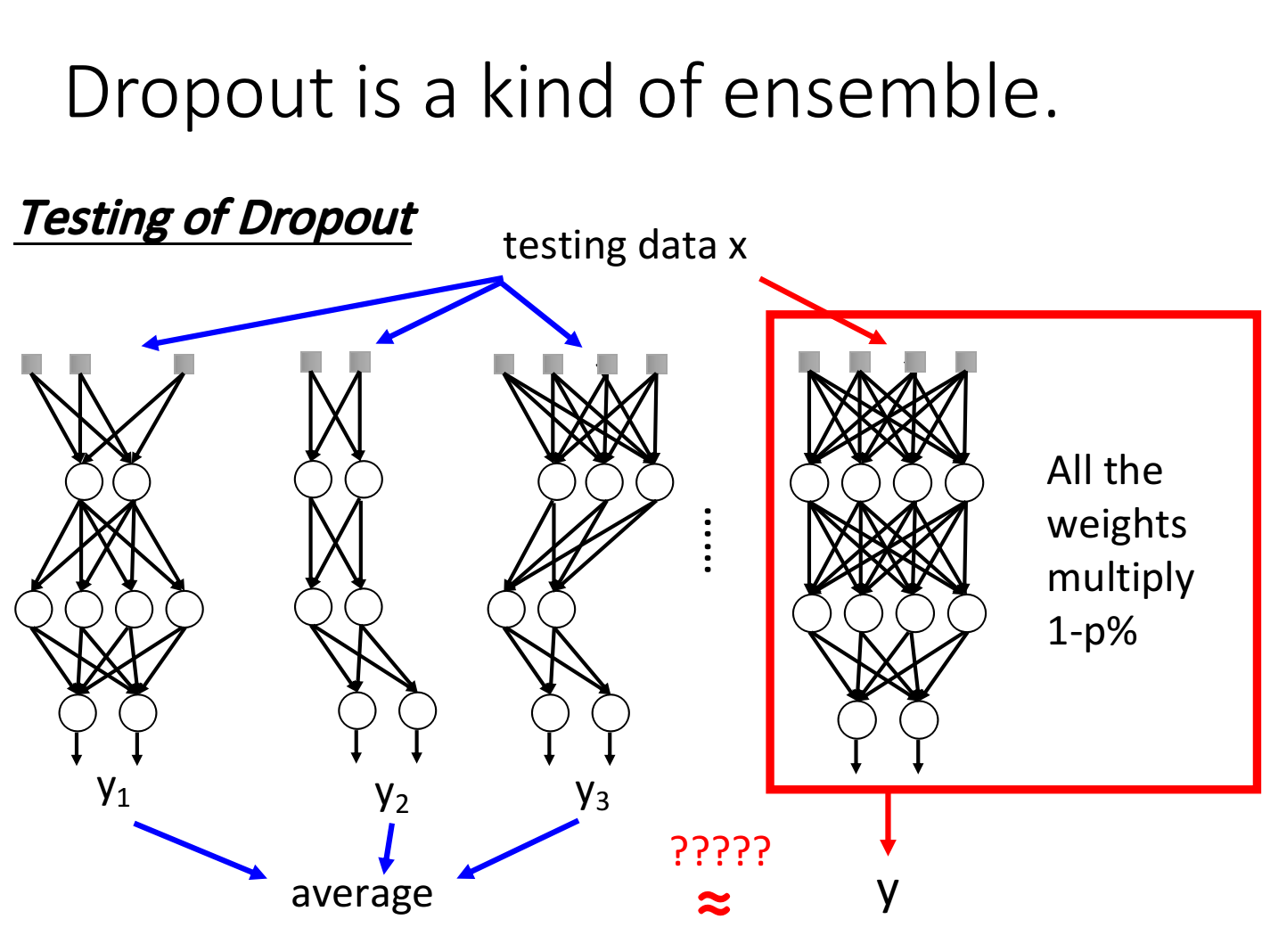
并且,Dropout在测试时,所使用的 ( 1 − p ) % (1-p)\% (1−p)%这个策略,与多个模型求平均效果时相同的。原因如下例。
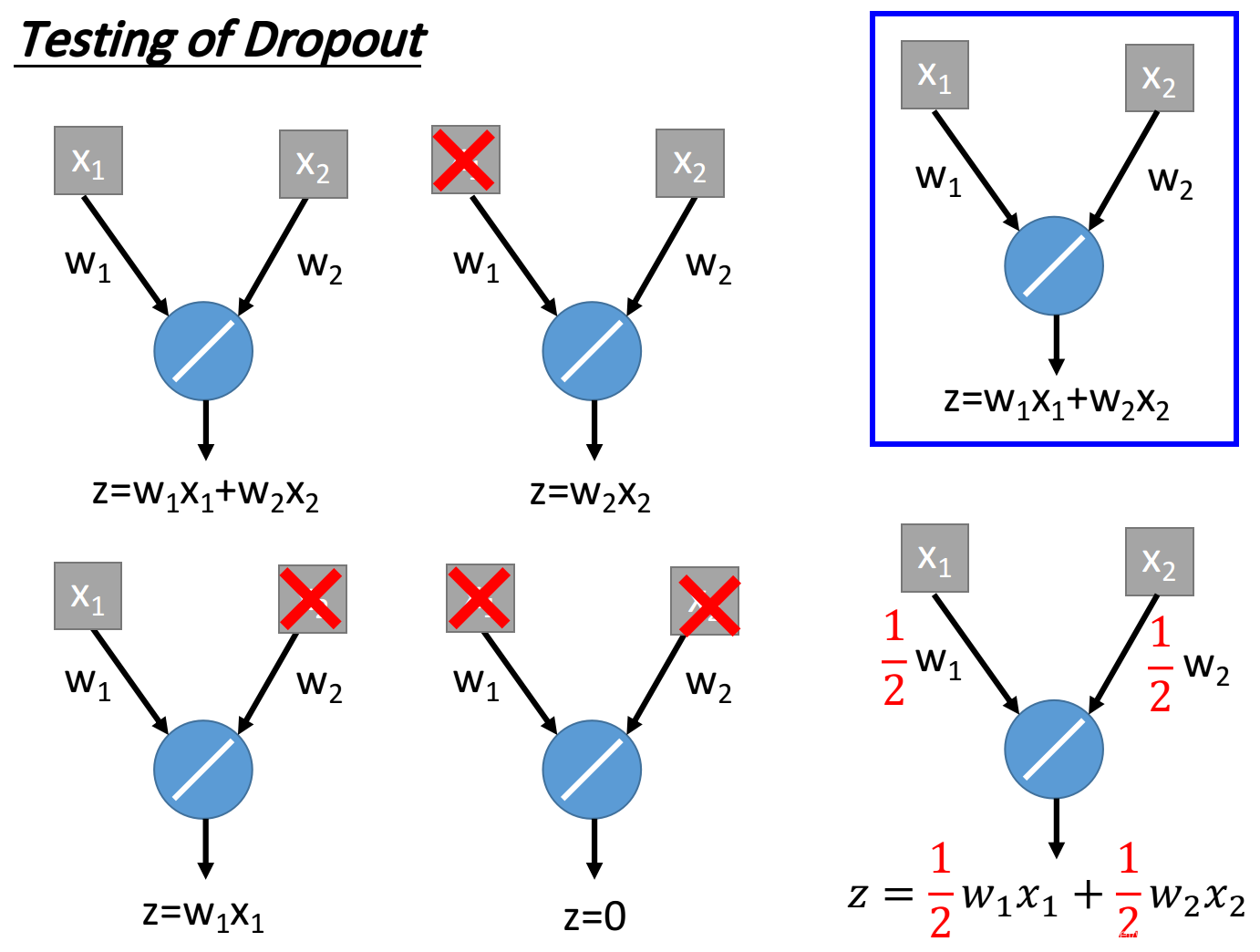
可见,在最简单的例子中,平均结果与 ( 1 − p ) % (1-p)\% (1−p)%效果相同。










