[翻译] TensorFlow 分布式之论文篇 “TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems”
文章目录
- [翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
本系列我们开始分析 TensorFlow 的分布式。之前在机器学习分布式这一系列分析之中,我们大多是以 PyTorch 为例,结合其他框架/库来穿插完成。但是缺少了 TensorFlow 就会觉得整个世界(系列)都是不完美的,不单单因为 TensorFlow 本身的影响力,更因为 TensorFlow 分布式有自己的鲜明特色,对于技术爱好者来说是一个巨大宝藏。
读论文有一种原则是:本领域最经典的论文,近5年最热的论文,近1年最新的论文。按照这个原则,本文主要介绍一篇 TensorFlow 经典论文[ TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems](http://download.TensorFlow .org/paper/whitepaper2015.pdf)。大家如果读了下面论文就会发现 TensorFlow分布式的博大精深。
本文图来自原始论文。
1. 原文摘要
基于我们在 DistBelief 方面的经验,以及对期望的系统特性和训练/使用神经网络需求的更全面的理解,我们构建了 TensorFlow ,这是我们的第二代系统,用于实现和部署大规模机器学习模型。 TensorFlow 采用类似数据流的模型来描述计算,并将其映射到各种不同的硬件平台上,从在 Android 和 iOS 等移动设备平台上运行推理,到使用包含一个或多个 GPU 卡的单机的中等规模训练和推理系统,再到在数百台具有数千个 GPU 的专用主机上运行的大规模训练系统。
拥有一个能够跨越如此广泛的平台的单一系统可以显著简化机器学习系统的实际使用,因为我们发现,如果大规模训练和小规模部署都分别有自己的独立系统,则会导致巨大的维护负担和漏洞。 TensorFlow 计算被表示为有状态数据流图,我们致力于使系统具有足够的灵活性,以便用户可以快速试验新模型,系统同时也具有足够高的性能和鲁棒性,可以被用于机器学习模型的训练和部署。
为了将神经网络训练扩展到更大规模的部署, TensorFlow 允许客户机通过复制和并行执行核心模型数据流图来轻松表达各种并行性,这样可以使用许多不同的计算设备来更新一组共享参数或其他共享状态。对计算描述的适度更改允许用户实现多种不同的并行方法。
TensorFlow 允许在参数更新的一致性方面具有一定的灵活性,这些宽松的同步要求允许我们可以在一些较大的部署中更加轻松。与 DistBelief 相比, TensorFlow 的编程模型更加灵活,性能显著提高,支持在更广泛的异构硬件平台上训练和使用更广泛的模型。
2. 编程模型和基本概念
TensorFlow 计算由一组节点组成的有向图来描述。该图表示一个数据流计算,也允许让某些类型的节点来维护和更新持久状态,并以类似于 Naiad 的方式在图中实现分支和循环控制结构。客户端通常使用一种前端语言(C++或Python)构建计算图。下图显示了使用 Python 前端构建并执行 TensorFlow 计算图的示例片段。

图 1. TensorFlow 计算图示例片段
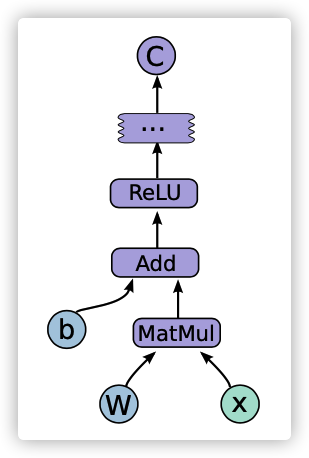
图 2,计算图
在 TensorFlow 图中,每个节点表示操作的实例,其具有零个或多个输入和零个或多个输出。在计算图中沿普通边流动的值(从输出到输入)被称为张量。张量是任意维数组,其基本元素类型在计算图构造时被指定或推断出来。特殊的边(被称为控制依赖关系)也可以存在于图中:这些边上没有数据流,但它们表明控制依赖关系的源节点必须在控制依赖关系的目标节点开始执行之前完成执行。因为我们的模型包含可变状态,因此客户可以直接使用控制依赖关系来强制执行。我们的实现有时也会在内部插入控制依赖项,以强制某些独立操作之间的顺序,例如,可以控制峰值内存使用。
2.1 算子(Operations)与核(Kernels)
算子(Operation)表示一个抽象计算(例如,“矩阵乘法"或"加法”)。一个算子可以拥有属性,但是所有属性必须在计算图构造时被提供或推断出来,这样才能实例化一个执行该算子的节点。属性的一个常见用途是使算子在不同的张量元素类型上具有多态性(例如,加法算子即支持两个类型为 float 的 tensors 相加,也支持两个类型为 int32的张量相加)。
核(Kernel)是可以在特定类型的设备(例如CPU或GPU)上运行的算子的具体实现。 TensorFlow 通过注册机制定义了一系列算子和核,这样意味着用户可以通过链接其他算子和/或内核来进行扩展。下图显示了 TensorFlow 库中内置的一些算子。

表 1. 算子
2.2 会话(Sessions)
客户端程序通过创建会话与 TensorFlow 系统交互。会话先构建一个空计算图,为了创建计算图,会话接口支持Extend 方法,该方法可以让客户端附加节点和边来扩充这个空图,然后进行计算。
2.3 变量(Variables)
在大多数计算中,一个图会被执行多次,而大多数张量在图的单次执行之后都不会存在。然而,有一些张量是在计算图的执行过程之中始终存在的,位置也是固定的,其不能正常流动但是可以更新,比如模型的参数,这就引出了变量这个概念。
变量是一种特殊的操作,它返回持久可变张量的句柄,这些句柄可以被传递给少量特殊的操作,例如 Assign 和AssignAdd(相当于+=),通过这些操作就可以改变这些变量引用的张量。
3. 实现
TensorFlow 系统中的主要组件是客户端,它使用会话接口与主机以及一个或多个工作进程进行通信。每个工作进程负责协调对一个或多个计算设备(如 CPU 内核或 GPU 卡)的访问以及按照主设备的指示在这些设备上执行计算图节点。 TensorFlow 接口有本地和分布式实现两种。
- 当客户端、master 和 worker 都在单个机器上单个进程的上下文之中运行时(如果机器安装了多个 GPU 卡,则可能使用多个设备),将使用本地实现。
- 分布式实现与本地实现共享大部分代码,但支持通过一个环境对其进行扩展,在该环境中,客户端、master和 worker 都可以在不同机器上不同的进程中。在我们的分布式环境中,这些不同的任务是 job 之中的一些容器,这些 job 由集群调度系统来管理。这两种不同的模式如下图所示。
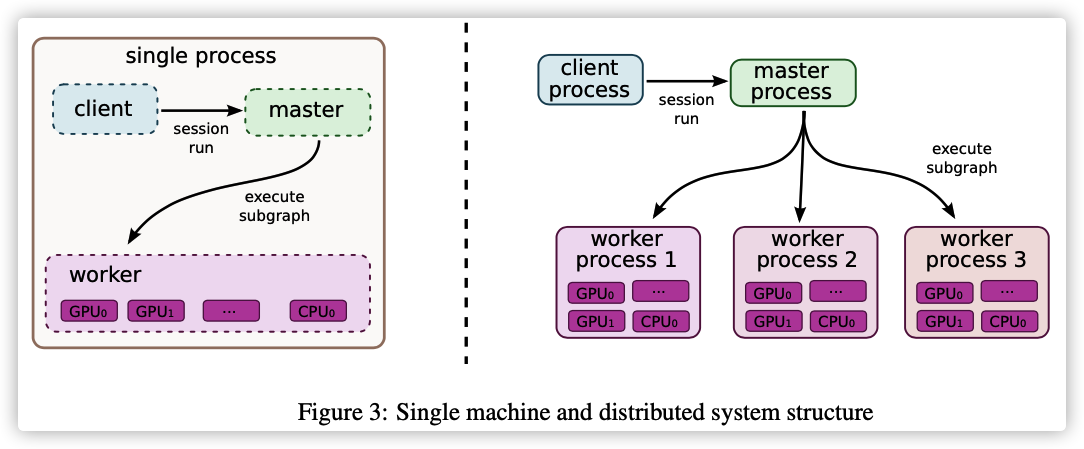
图 3. 调度模式
3.1 设备(Devices)
设备是 TensorFlow 的计算核心。每个工作者负责一个或多个设备,每个设备都有一个设备类型和名称。设备名称由以下几部分组成:
- 设备类型。
- 设备在工作者中的索引。
- 分布式设置中对于工作者所在作业和任务的标识(如果设备是进程本地的,则为 localhost)。
示例设备名称的样例如下:
- “/job:localhost/device:cpu:0”。
- “/job:worker/task:17/device:gpu:3”。
PyTorch 有针对 CPU 和 GPU 的设备接口的实现,其他设备类型可以通过注册机制提供新设备实现。每个设备对象负责管理设备内存的分配和释放,以及执行 TensorFlow 下发的核方法。
3.2 张量
在我们的实现中,张量是一个类型化的多维数组。我们支持多种张量元素类型,包括大小从 8 位到 64 位的有符号和无符号整数、IEEE 浮点和双精度类型、复数类型和字符串类型(arbitrary byte array)。张量所在设备的分配器负责管理张量的存储区,张量存储缓冲区是引用计数的,在没有引用保留时会进行释放。
3.3 单设备执行
让我们首先考虑最简单的执行场景:一个拥有单个设备的工作者进程。计算图中的节点按照节点之间依赖关系的顺序来执行。我们将跟踪每个节点尚未执行的依赖项数量的计数。一旦此计数降至零,该节点就有资格执行,并被添加到就绪队列中。就绪队列以某种未指定的顺序进行处理,其将节点的核方法执行委托给设备对象。当节点完成执行时,依赖于此已完成节点的所有节点的计数都将减少。
3.4 多设备执行
一旦一个系统有多个设备,就有两个主要的复杂问题:如何决定将每个节点的计算放在哪个设备上,如何管理这些放置(Placement )所带来的跨设备数据通信。本小节讨论这两个问题。
3.4.1 决定设备(Node Placement)
给定计算图之后, TensorFlow 实现的主要职责之一是将计算映射到可用设备集。本文给出了该算法的一个简化版本。
布局(placement)算法的一个输入是成本模型(cost model),该模型包含每个计算图节点的输入和输出张量的大小(字节)估计,以及每个节点在获得输入张量之后所需的计算时间估计。该成本模型要么基于与不同操作类型相关的启发式静态估计,要么基于计算图早期执行的实际布局决策集进行测量/决定。
布局算法首先运行计算图的模拟执行,然后使用贪婪启发式为图中的每个节点选择一个设备。此模拟生成的"节点到设备放置关系"最终也用作实际执行的放置。布局算法从计算图的源开始,并在前进过程中模拟系统中每个设备上的活动,在此遍历中:
- 当到达了一个节点,就考虑此节点的可使用设备集(如果设备不提供用户希望的实现特定操作的内核,则设备就不使用)。
- 对于具有多个可用设备的节点,布局算法使用贪婪启发式算法,看看将节点放置在每个可能设备上对节点完成时间会造成怎样的影响。该启发式方法不仅考虑了在成本模型中,该类设备上操作的估计或测量执行时间,还包括为了将输入从其他设备传输到该节点而引入的通信成本。然后选择最快完成节点操作的设备作为该操作的设备,
- 布局(placement)过程继续进行,以便为图中的其他节点(包括现在准备好模拟执行的下游节点)做出放置决策。
3.4.2 跨设备通信(Cross-Device Communication)
一旦决定了节点如何放置到设备之上(node placement),图就被划分成一组子图,每个设备一个子图。任何跨设备的从 x 到 y 的边将被删除,并替换为两条新边:
- 一条边是在 x 子图中,从 x 到新的 Send 节点。
- 一条边是在 y 的子图之中,从对应的 Receive 节点到 y。
请参见下图。
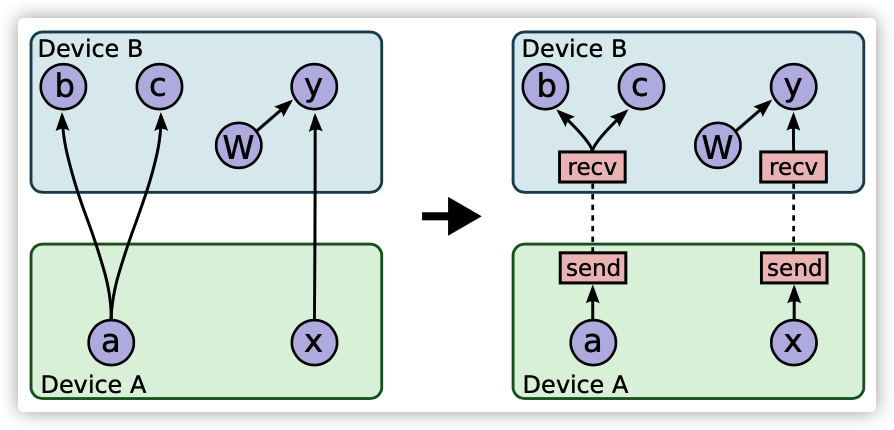
图 4 插入发送/接收节点之前和之后
在运行时,发送和接收节点将会彼此协调如何在设备之间传输数据。这使我们能够把发送和接收的所有通信隔离出来,从而简化运行时(runtime)的其余部分。
当我们插入发送和接收节点时,我们规范如下:特定设备上特定张量的所有用户都使用同一个接收节点,而不是特定设备上的每个下游用户都拥有一个自己的接收节点。这确保了所需张量的数据在"源设备→ 目标设备对"之间只传输一次,并且目标设备上张量的内存只分配一次,而不是多次(例如,参见上图中的节点 b 和 c)。
通过以这种方式处理通信,我们还允许将不同设备上的图的各个节点的调度分散到工作者之中:发送和接收节点在不同的工作者和设备之间传递必要的同步,这样就把主节点从调度任务之中解放出来。主节点只需要向每个具有计算图的任何节点的工作者发出单个 Run 请求(每次计算图执行),而不需要参与每个节点或每个跨设备通信的调度。这使得系统更具可伸缩性可扩展性,并且和主节点强制执行调度相比,可以执行更细粒度的节点执行策略。
3.5 分布式执行
计算图的分布式执行与多设备执行非常相似。在决定设备如何放置之后,将为每个设备创建一个子图。发送/接收节点对在跨工作进程通信时候使用远程通信机制(如 TCP 或 RDMA)来跨机器边界移动数据。
3.5.1 容错(Fault Tolerance)
我们可以在许多地方检测到分布式执行中的故障,目前主要依靠如下两种方式:
- 检测到发送和接收节点对之间的通信错误。
- 从主进程到每个工作进程的定期健康检查。
当检测到故障时,整个计算图执行将中止并从头开始。因为变量(Variable)节点指的是在图的执行过程中持续存在的张量,所以我们支持设置一致性检查点,以此来在重新启动时恢复这些状态。具体来说,每个变量节点都连接到一个 Save 节点。这些保存节点定期执行,例如每 N 次迭代执行一次,或每 N 秒执行一次。当它们执行时,变量的内容被写入持久存储,例如分布式文件系统。类似地,每个变量也都连接到一个恢复节点,该节点仅在重新启动后的第一次迭代中启用。
4. 扩展(Extensions)
在本节中,我们将介绍基本编程模型的几个更高级的特性。
4.1 计算梯度
许多优化算法,包括常见的机器学习训练算法(如随机梯度下降),会使用一组输入来计算一个成本函数(cost function)的梯度。因为这是一种常见的需求,所以 TensorFlow 内置了对自动梯度计算的支持。如果一个 TensorFlow 计算图中的张量 C 可能通过一个复杂的操作子图依赖于一组张量{ X k X_k Xk},那么一个内置函数将返回张量集{ d C / d X k dC/dX_k dC/dXk}。梯度张量和其他张量一样,通过使用以下步骤扩展 TensorFlow 图来计算。
张量 C 依赖于张量 I,当 TensorFlow 需要计算张量 C 相对于张量I的梯度时,它首先在计算图中找到从 I 到 C 的路径。然后它从 C 回溯到 I,对于反向路径上的每个操作,它会向 TensorFlow 图添加一个节点,使用链式规则沿向后路径合成偏导数。
新添加的节点为前向路径中的相应操作计算"梯度函数"。梯度函数可以通过任何操作注册。该函数不仅将沿反向路径计算的部分梯度作为输入,还可以选择正向操作的输入和输出。下图显示了根据图2示例计算的成本梯度。灰色箭头显示梯度函数的潜在输入,该函数不用于所示的特定操作。
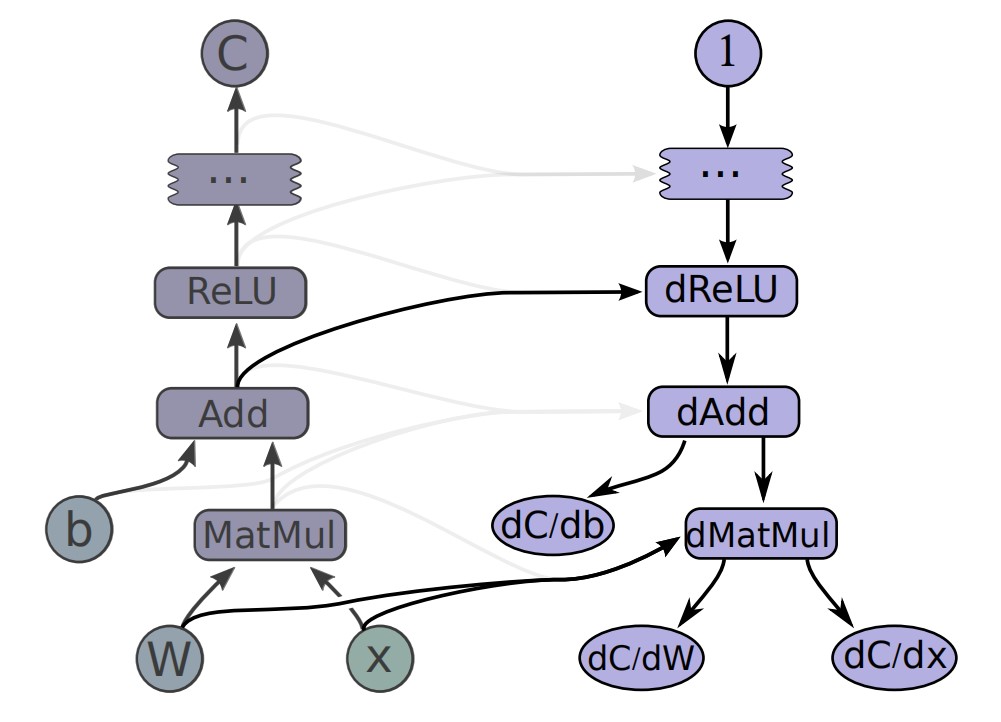
图 5 计算这些梯度所需的附加值为:
[
d
b
,
d
W
,
d
x
]
=
t
f
.
g
r
a
d
i
e
n
t
s
(
C
,
[
b
,
W
,
x
]
)
[db,dW,dx] = tf.gradients(C,[b,W,x])
[db,dW,dx]=tf.gradients(C,[b,W,x])
自动梯度计算会使优化更加复杂化,尤其是内存使用。当执行前向计算子图(即用户显式构造的子图)时,启发式优化算法可以通过观察计算图的构造顺序来决定下一步执行哪个节点,这通常意味着临时输出在构建后很快就会被占用,因此它们的内存可以很快被重用。
当启发式无效时,用户可以通过更改计算图构造的顺序,或添加控制依赖项来优化内存使用。但是,当梯度节点自动添加到计算图中时,用户的控制能力会降低,启发式算法可能会崩溃。特别是,因为梯度反转了正向计算顺序,因此在计算图执行中,早期使用的张量在梯度计算的末尾经常再次需要。这种张量会占用大量稀缺的 GPU 内存,从而不必要地限制计算量。我们正在积极改进内存管理,以便更好地处理此类情况。选项包括使用更复杂的启发算法来确定计算图执行的顺序,重新计算张量而不是将其保留在内存中,以及将长期张量从 GPU 内存交换到更大的主机 CPU 内存。
4.2 局部执行(Partial Execution)
客户机通常只想执行整个执行图的一个子图。为了支持这一点,一旦客户机在会话中设置了计算图,我们的 Run 方法允许客户机执行整个图的任意子图,并沿图中的任意边输入任意数据,以及沿图中任意边获取数据。
图中的每个节点都有一个名称,节点的每个输出由源节点名称和节点的输出端口标识,从 0 开始编号(例如,“bar:0” 表示"bar"节点的第一个输出,而"bar:1"表示第二个输出)。
Run 调用的两个参数有助于定义将要执行的计算图的确切子图。首先,Run 调用接受类型为 name:port 名称到"fed"张量值的映射作为输入。其次,Run 调用接受 output names,这是一个输出 name[:port] 列表,其指定了应执行哪些节点。如果名称中存在端口部分,则如果 Run 调用成功完成,应将节点的特定输出张量值返回给客户端。
计算图可以基于输入和输出的值进行转换。输入中每个 node:port 都替换为一个 feed 节点,该节点将从用于 Run 调用的 Rendezvous 对象中获取输入张量。类似地,每个带有端口的输出名称都连接到一个特殊的 fetch 节点,该节点被用来保存输出张量,并在运行调用完成时将其返回给客户端。最后,一旦通过插入这些特殊的 feed 和 fetch 节点重写了计算图,要执行的节点集可以通过以下方式确定:从每个由输出指定的节点开始,使用图依赖关系在图中进行后向传播,以确定为了计算输出而必须在重写图中执行的完整节点集。下图在左侧显示了一个原始图,以及在使用 inputs == {b} 和 outputs == {f:0} 调用 Run 时生成的转换图。因为我们只需要计算节点f的输出,所以我们不会执行节点 d 和 e,因为它们与 f 的输出没有任何关系。
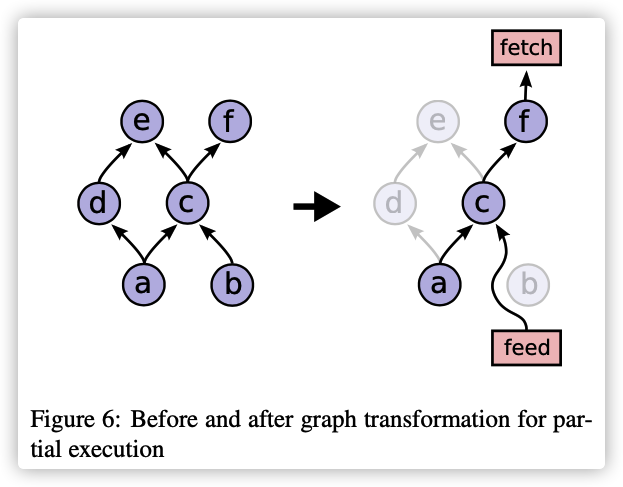
图 6 局部执行前后
4.3 设备约束(Device Constraints)
TensorFlow 客户端可以通过为节点提供部分约束来控制节点在设备上的位置,这些约束与节点可以在哪些设备上执行有关。例如,“仅将此节点放置在 GPU 类型的设备上”,或*"此节点可以放置在*/job:worker/task:17*"中的任何设备上,或*“将此节点与名为variable13"的节点合并”。在这些约束条件的约束范围内,布局算法(placement algorithm)负责完成节点到设备的分配,以提供快速的计算执行,并满足设备自身施加的各种约束,例如,限制设备上执行其计算图节点子集所需的内存总量。
支持此类约束要求更改前面描述的布局算法。我们首先计算每个节点的可行设备集,然后在共定位约束图(graph of colocation constraints)上使用 union find 来计算出必须放置在一起的图组件。对于每个这样的组件,我们计算可行设备集的交集。
4.4 控制流
虽然没有任何显式控制流的数据流图也非常有表达能力,但我们发现,在很多情况下,如果支持条件和循环,则可以用更简洁和有效来表示机器学习算法。
与 Arvind 描述的数据流机(dataflow-machine)方法一样,我们在 TensorFlow 中引入了一小部分控制流原语操作符,并将 TensorFlow 推广到可以处理循环数据流图。Switch 和 Merge 运算符允许我们根据布尔张量的值来跳过整个子图的执行。Enter,Leave 和 NextIteration 运算符允许我们表示迭代。高层级的编程结构,如 if-conditionals 和 while-loops 则可以使用这些控制流操作符来轻松地编译成数据流计算图。
TensorFlow 运行时实现了标签(tags)和帧(frames)的概念,其在概念上类似于 MIT 标记令牌机(MIT Tagged-Token machine)。循环的每个迭代都由一个 tag 唯一标识,其执行状态由一个 frame 表示。只要输入准备好,它就可以进入迭代,因此可以同时执行多个迭代。
如何为分布式系统处理循环控制的状态? TensorFlow 使用分布式协调机制来执行带有控制流的图。通常,循环可以包含分配给许多不同设备的节点。因此,管理循环的状态成为分布式终止检测问题。TensorFlow 的解决方案是基于图重写。在图分区过程中,我们自动向每个分区添加控制节点。这些节点实现了一个小型状态机,它协调每个迭代的开始和结束,并决定最终循环的结束。对于每个迭代,拥有循环终止断言(predicate)的设备向每个参与的设备发送一条控制消息。
如上所述,我们通常通过梯度下降来训练机器学习模型,并将梯度计算表示为数据流图的一部分。当模型包含控制流操作时,我们必须在相应的梯度计算中考虑它们。例如,对于具有 if-conditional 的模型,梯度计算需要知道采用了条件的哪个分支,然后将梯度逻辑应用于该分支。类似地,带有 while-loop 的模型的梯度计算需要知道进行了多少次迭代,并且还将依赖于在这些迭代期间计算的中间值。目前依然采用重写计算图技术来记录梯度计算所需的值。
4.5 输入操作
虽然可以通过 feed 节点把输入数据提供给计算调用,但用于训练大规模机器学习模型的另一种常见机制是在图中部署有特定的输入操作节点,这种节点通常配置成一组文件名,该节点每次执行时产生一个张量,该张量包含存储在该组文件中的数据的一个或多个样本。这样就允许将数据直接从底层存储系统读取到计算机内存中,然后计算机内存将对数据执行后续处理。在客户端进程与工作进程分开的配置中,如果数据被馈送,则通常需要额外的网络跃点 hop(从存储系统到客户端,然后从客户端到工作进程,而不是使用输入节点时直接从存储系统传输到工作进程)。
4.6 队列
队列是我们添加到 TensorFlow 中的一个有用特性。它们允许计算图的不同部分进行异步操作,并通过入队(Enqueue)和出队(Dequeue)操作传递数据。入队操作可以阻塞,直到队列中有可用的空间,而出队操作也可以阻塞,直到队列中有所需的最少数量的元素可用。队列的一种用途是,当机器学习模型的计算部分仍在处理前一批数据时,模型可以从磁盘文件中预取输入数据。它们也可用于其他类型的分组操作,包括累积多个梯度,这样可以把小 batch 组合成为一个大 batch,以便在大的批次上计算更复杂的梯度组合,或将循环语言模型的不同输入句子分组到大致相同长度的句子箱(bin)中,然后可以更有效地处理这些问题。
除了普通的 FIFO 队列之外,我们还实现了一个 shuffling 队列,它在一个大的内存缓冲区内随机 shuffle 其元素。例如,对于希望用随机顺序来处理样本的机器学习算法来说,这种洗牌功能非常有用。
4.7 容器
容器是 TensorFlow 中用于管理长期可变状态的机制。默认容器将会一直持续到进程终止,但我们也允许使用其他的命名容器。容器存储变量的备份,可以通过完全清除容器中的内容来重置容器。通过使用容器可以在不同会话的完全不相交的计算图之间共享状态。
5 优化
在本节中,我们将介绍 TensorFlow 实现中的一些优化,这些优化可以提高系统的性能或资源利用率。
5.1 消除公共子表达式
由于计算图的构造通常由客户机代码中的许多不同层的抽象来完成,因此计算图很容易存在重复计算。为了处理这个问题,我们实现了类似于Click(原始论文参考文献12)描述的算法,该算法在计算图上运行,并将具有相同输入和操作类型的多个操作副本缩减到其中的一个节点,并会把相应的边进行重定向。
5.2 控制数据传输和内存使用
仔细安排 TensorFlow 操作可以提高系统的性能,特别是在数据传输和内存使用方面。具体而言,调度可以减少中间结果保存在内存中的时间,从而减少内存消耗峰值。这种减少对于内存不足的 GPU 设备尤为重要。此外,重新安排设备间的数据通信可以减少对网络资源的争夺。
虽然有很多机会可以安排优化,但这里我们重点关注一个我们认为特别必要和有效的机会。它涉及接收节点读取远程值的计划。如果不采取预防措施,这些节点可能会比必要时启动得更快,可能在执行开始时一次启动。通过执行运筹学中常见的尽快/尽可能晚(ASAP/ALAP)计算,我们分析图的关键路径以估计何时启动接收节点。然后,我们插入控制边,目的是在需要这些节点的结果之前取消这些节点的起始位置。
5.3 异步核
除了正常同步内核之外,我们的框架还支持非阻塞内核。这样的非阻塞内核使用一个稍有不同的接口,通过该接口,一个 continuation 被传递给计算方法,该 continuation 应该在内核执行完成时调用。这是一种针对具有多个活动线程环境的优化。在这些环境中,内存使用或其他资源相对昂贵,因此我们应该避免在等待 I/O 或其他事件发生时长期占用执行线程。异步内核的示例包括接收内核、排队内核和出列内核(如果队列空间不可用或没有可读取的数据,则可能需要分别进行阻塞)。
5.4 优化函数库
目前有很多高度优化的函数库,比如 BLAS 和 cuBLAS,另外,cuda convnet 和 cuDNN 可以在 GPU 之上处理卷积核。因此我们利用这些函数库实现了系统的很多内核。
5.5 有损压缩(Lossy Compression)
一些机器学习算法(比如通常用于训练神经网络的算法)具有抗噪声和降低算法精度的能力。在设备之间发送数据时(有时在同一台机器内的设备之间),我们通常使用高精度的有损压缩,这一方式类似于分布式系统。例如,我们通常插入特殊的转换节点,将 32 位浮点表示转换为 16 位浮点表示(不是 IEEE 16 位浮点标准,而是 32 位 IEEE 794 浮点格式,但尾数中的精度降低了 16 位),然后在通信信道的另一端转换回 32 位表示(只需为尾数的丢失部分填入零,因为这样在 32→ 16→ 32 位转换时计算花费更少)。
6. 编程技巧
上面讲的都是一些系统级别的优化,下面我们讲述一些机器学习算法所用到的技巧。这里假定用户都用 SGD 来求解机器学习算法。TensorFlow 的基本数据流图模型可以以多种方式用于机器学习应用。我们关心的一个领域是如何加速计算密集型神经网络模型在大型数据集上的训练。本节描述了我们和其他人为了实现这一点而开发的几种技术,并说明了如何使用 TensorFlow 实现这些不同的方法。
本小节中的方法假设使用随机梯度下降法(SGD)对模型进行训练,使用的小批次包括 100~1000 个样本。
6.1 数据并行训练
可以通过数据并行的方式来提升 SGD 的效率,比如,假如每次 SGD 的 mini-batch 是 1000 个样本,我们可以把模型复制成 10 份放到 10 个 GPU 之上,mini-batch 也被切成 10 份,每份就是 100 个样本。这个 10 个模型副本并行计算自己 100 个样本的梯度,然后把这些梯度进行同步规约,最后用于模型参数更新。这就像我们使用 1000个元素的批量大小运行顺序 SGD 算法一样。在这种情况下, TensorFlow 图拥有原计算图中执行大多数计算部分的多个副本,由单个客户端线程驱动这个大型图的整个训练循环。下图顶部对此进行了说明。
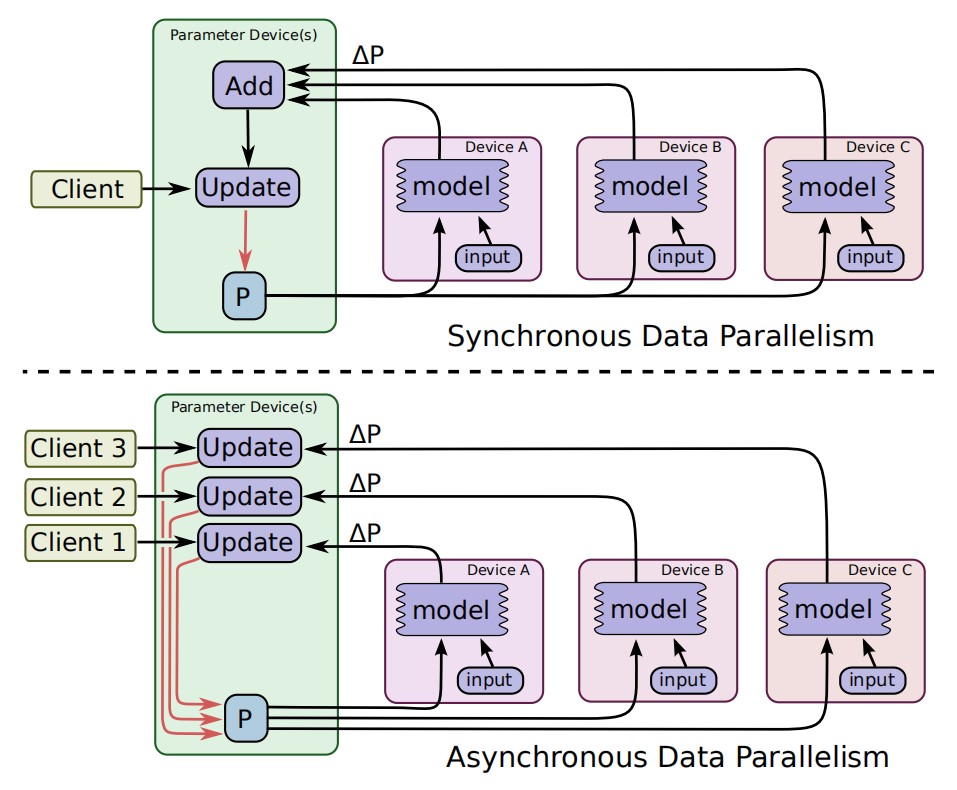
图 7 数据并行
这种方法也可以是异步的,每一个模型副本异步地将梯度更新应用于模型参数,不需要彼此等待。在此配置中,每个图副本都有一个客户端线程。上图下半部分对此进行了说明。
7. Model Parallel Training
模型并行训练也很容易用 TensorFlow 表示,这样对于同一批样本,模型不同部分可以在不同的计算设备上同时计算。下图显示了 LSTM 模型的示例,该模型在三个不同的设备上并行。
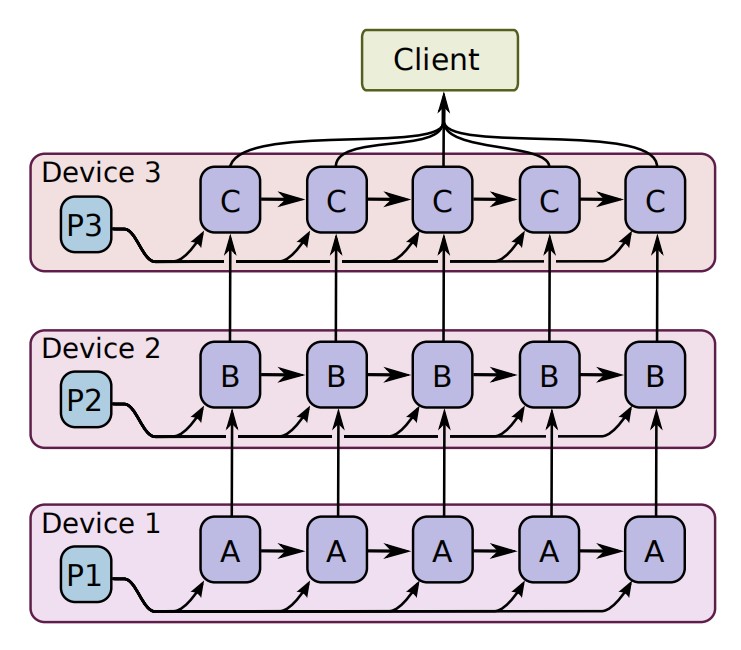
0x08 Concurrent Steps for Model Computation PipeLine
在同一设备中对模型计算进行流水线处理也是一个常用的提高利用率的方法,这是通过在同一组设备中运行少量的并发步骤来完成的。它有点类似于异步数据并行,只是流水线并行发生在同一设备内,而不是在不同设备上复制计算图。在一个单一的步骤中,在所有设备上的计算可能无法在任何时候完全利用全部设备的并行性,而流水线并行允许 “填补间隙”,这可以充分利用空闲的设备资源。
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。

0xFF 参考
TensorFlow 架构
[ TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems](http://download. TensorFlow .org/paper/whitepaper2015.pdf)
TensorFlow : a system for large-scale machine learning
TensorFlow 分布式采坑记










