FM
我们用向量的内积来计算得到了就交叉特征的系数,所以我们引入的参数矩阵V可以看成是对W矩阵做了一个因子分解,这也是FM得名的由来。
这里V是N*K的二维矩阵,当然在实际的应用场景当中,我们并不需要设置非常大的K,因为特征矩阵往往非常稀疏,我们可能没有足够多的样本来训练这么大量的参数,并且限制K也可以一定程度上提升FM模型的泛化能力。
FM的优点
FM模型的种种好处,比如和SVM对比,它能够在稀疏的特征当中仍然拥有很好的表现,并且FM的效率非常高,可以在线性时间内获得结果。并且不像非线性的SVM(核函数),FM并不需要将特征转换成对偶形式,并且模型的参数可以直接训练,也不用借助支持向量或者是其他的方法。
总结,FM模型的优点有如下几点:
1.FM模型的参数支持非常稀疏的特征,而SVM等模型不行
2.FM的时间复杂度为O(N),并且可以直接优化原问题的参数,而不需要依靠支持向量或者是转化成对偶问题解决
3.FM是通用的模型,可以适用于任何实数特征的场景,其他的模型不行
FM为人称道的也正是这一点,既引入了特征交叉,又解决了复杂度以及模型参数的问题
此外这样做还有一个好处就是有利于模型训练,因为对于有些稀疏的特征组合来说,我们所有的样本当中可能都是空的。比如在刚才的例子当中用户A和电影B的组合,可能用户A在电影B上就没有过任何行为,那么这个数据就是空的,我们也不可能训练出任何参数来。但是引入了V之后,虽然这两项缺失,但是我们仍然可以得到一个参数。因为我们针对用户A和电影B训练出了一个向量参数,我们用这两个向量参数点乘,就得到了这个交叉特征的系数。也就解决了特征高度稀疏的问题


协同过滤算法如何实现,用户特征向量用哪些用户属性表示,如何挖掘更多的用户信息?

说出计算用户之间相似度的三种方式?
Jaccard相似度
杰卡德相似度(Jaccard similarity coefficient),也称为杰卡德指数(Jaccard similarity),是用来衡量两个集合相似度的一种指标。Jaccard相似指数被定义为两个集合交集的元素个数除以并集的元素个数。

余弦相似度
将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并求得夹角之间的余弦值,此余弦值就可以用来表征,这两个向量之间的相似性。夹角越小,余弦值越接近于1,则越相似。
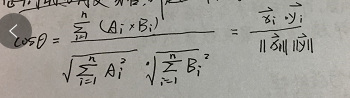
Pearson系数(皮尔森系数)
皮尔逊系数也称为积差相关(或积矩相关),是英国统计学家皮尔逊提出的一种计算直线相关的方法。取值范围[-1.1]。比如求两个用户之间的相似度,他是用协方差除以两个变量的标准差得到的,等于1时表示完全正相关。
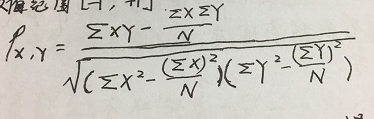
说出你的推荐算法的效果,如何提升推荐准确率,如何知道推荐结果是否正确?

推荐算法:
协同过滤(基于物品和基于用户)的原理,ItemCF、UserCF、SVD矩阵分解
原理与实现:给一个场景,给出解决方案
首先选择基于物品或者用户的协同过滤,用户行为如果比较少,需要细化特征,得到相似性
项目需要弄明白的东西:
项目来源
数据量,7天10个TB
做了多长时间,项目排期
用的算法和模型的原理
不同模型的区别,如何选择
模型参数的调试
结果如何评估,
可以改进的地方
项目突出的内容
推荐实时性很重要,两个小时的,一个是实时预测,一个是凌晨全量迭代
简历中项目要突出自己的工作量,实验结果,比如提升了多少auc
DSSM
广告场景中的DSSM双塔模型模型整体结构如下图所示,也分成三层:输入层、表示层和匹配层。
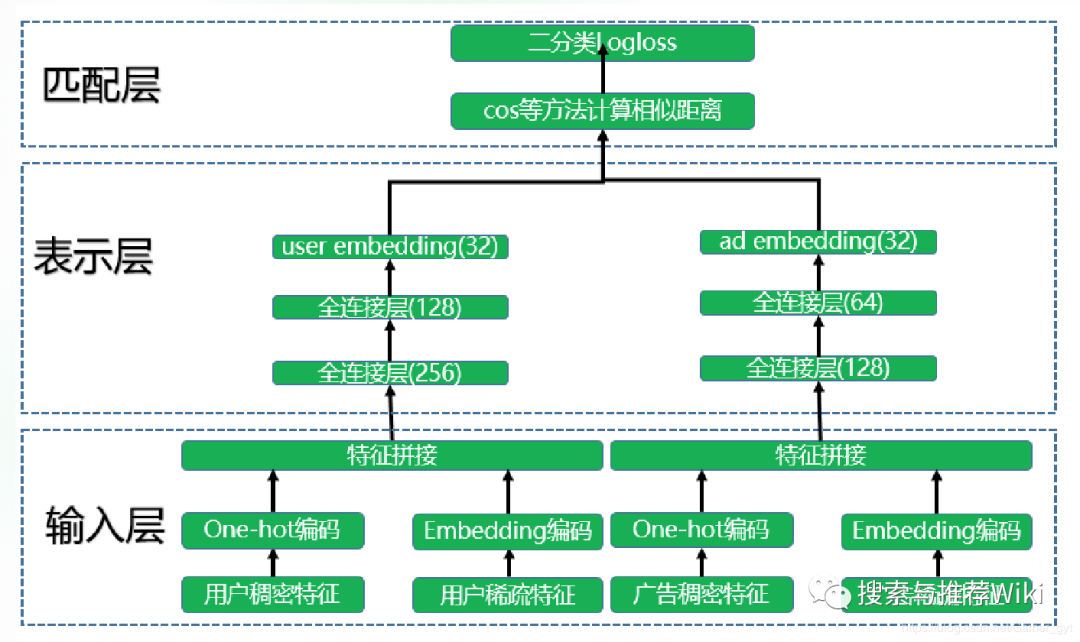
输入层
模型训练分成两座不同的“塔”分别进行,就是两个不同的神经网络。一座塔是用于生成user embedding。处理数据获取各种用户特征(用户基本信息、行为过的Item序列等)embedding然后拼接起来。item侧也类似(比如视频推荐的Video特征(视频ID、频道ID)转化为Embedding,对于同一个ID的embedding在双塔模型的左侧和右侧是共享的。对于一些多值特征(比如视频的主题)采用Embedding加权平均)。
表示层
得到拼接好的特征之后会提供给各自的dnn模型。用户特征和item特征经过各自的全连接层后得到了维度相同的user embedding和ad embedding(两个塔的网络模型可以不同但是输出的维度必须是一样的,这样才能在匹配层进行运算)。一般user embedding和ad embedding 维度是32,64。
匹配层
之后将输出的user embedding和ad embedding存到内存数据库。要给某个item推荐用户,则将该item的 embedding分别和所有人群的user embedding算cos相似度选topN进行推荐。(用cos相当于做了两个向量模长归一化,只保留方向,不考虑长度)
训练时将cos距离过一个sigmoid函数归一化到[0,1]再用真实标签算logloss。模型评估主要使用auc指标。用训练出的user embedding和每个item embedding计算cos相似度,这个相似度过sigmoid函数归一化到[0~1],再和数据的标签计算log loss 也就是交叉熵(logloss就是二分类时的交叉熵)也就让用户和正例Item在Embedding空间更接近,和负例Item在Embedding空间距离拉远。
DSSM的优点(特点)
1。两个塔相对独立。它们各自接受用户或者Item的特征输入,能够独立打出准确的User Embedding或者Item Embedding。
2.比如对于大量候选item粗筛的时候,可以通过Item侧塔,离线将所有Item转化成Embedding,配合ANN向量化检索,他的速度特别快,效果也很好。
3.用户的User Embedding,一般要求实时更新,体现用户最新的兴趣。当然可以通过在线模型实时更新双塔的参数来达到效果;但是毕竟在线模型实施成本高,所以可以固定用户侧的塔模型参数,在输入端,将用户最新行为过的Item做为用户侧塔的输入,然后通过User侧塔打出User Embedding。这样可以实时地体现用户即时兴趣的变化,做起来相对简单。
DSSM的缺点
1.还是因为双塔的结构,导致用户特征和Item特征分离,但是有些时候会需要一些User侧特征和Item侧特征的组合特征,但是这种特征在双塔模型里没办法用,因为这种特征即不能放在user侧塔也不能放在item侧。
2.双塔模型只有在User Embedding和Item Embedding计算cos距离,算内积的时候,两者才发生交互,但这个时候User Embedding和Item Embedding已经经过多次神经网络的非线性变换,整合出的一个表征用户或者Item的整体Embedding,细粒度的特征这时候已经很难体现了,就是两侧特征交互的时机太晚了。相比在网络的浅层就进行特征交互,就会有一些效果上的损失。
DSSM和FM的比较
相对FM模型,双塔DNN模型的优点是引入了非线性,但是因为这种非线性是在User侧特征之间,或者Item侧特征之间做的,所以可能发挥的作用就没有那么大,因为User侧和Item侧之间的特征交互会更有效一些。单侧特征的多层非线性操作,可能反而会带来上两侧特征交互太晚,细节信息丢失的问题。
FM模型,感觉特性和DNN双塔正好相反,它在User侧和Item侧交互方面比较有优势,因为没有深层,也没有非线性对单侧特征的深度融合,只在两侧特征Embedding层级发生交互作用,所以在特征Embedding层级能够更好地表达User侧和Item侧特征之间的交叉作用,当然,缺点是缺乏非线性。








