上一篇 lambda表达式的分析及使用
上一篇文章讲解了lambda表达式的使用,但是在日常开发中,对数据的操作大多使用stream流的方式,此篇文章来详细介绍一下stream流。
文章目录
流的基本介绍
流的起源
集合是java最常用的api,但是在没有java8之前,对集合的操作非常麻烦,比如我要查询一个集合中年龄小于18岁人的姓名,并不能像SQL一样 : select name from t_person where age <18。而是需要比较繁琐的操作才能找出age小于18的name。再比如说,如果数据量非常的庞大,需要进行多线程的操作,这写起来也比较复杂。所以,为了避免以上问题,可以让我们更加愉悦的开发,在java8中,以上问题都是可以通过stream流的方式来解决,不将就才是前进的原动力!
流的概念
流是java API的新成员,它是用声明式的方式来处理数据,要做什么就直接声明什么。对于流的解释,就像汽车的流水线一样:A组加工完之后,B组在A组加工的基础上进行进一步的加工,然后也可以再将加工后的产品给C组,这样形成一条流水线,流注重的是计算的过程。当然,流也是支持并行操作的,下面也会介绍。
集合和流之间的关系
集合和流之间的差异在于什么时候进行计算。集合是一个内存中数据结构,集合中的元素只能先计算出来之后再添加到集合中,集合中的元素是放在内存中的,元素必须先计算出来才能成为集合的一部分。
流是概念上固定的数据结构(我们不能对其进行添加和删除元素),而其元素是按需计算的,这与集合不同,也就是用户只需要从流中提取需要的值,而这些值,会在用户看不到的地方按需生成。
举一个例子来来说明集合和流的区别:
光盘里面的电影就是一个集合,它包含了整个数据结构,是先完全放进去的,才能播放;而我们如果在互联网上看同样的电影,可以一边看,一边加载,这就是流的形式,它只需要下载用户看的那几帧就可以了。
流的特点
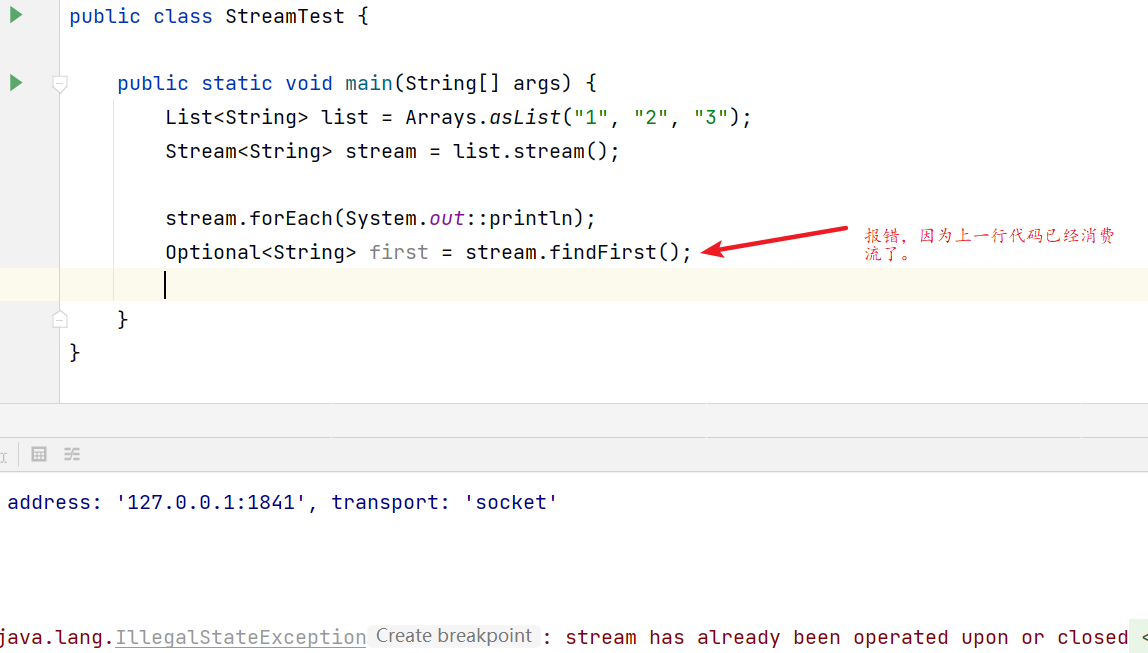
1、流只能被消费一次
对流的操作只能有一个终端操作,流只能被消费一次,举例以下代码会报错:
2、内部迭代
使用Collection接口进行的操作(比如foreach)属于外部迭代,Streams库使用的是内部迭代
(提示:该menu 会在下面多次使用,请留意)
外部迭代的方式:
public class StreamTest {
public static void main(String[] args) {
List<Dish> menu = Arrays.asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("fruit", true, 550, Dish.Type.MEAT),
new Dish("fish", false, 450, Dish.Type.FISH));
List<String> names = new ArrayList<>();
//显示的顺序迭代菜单列表,foreach是语法糖,背后使用的是Iterator
for (Dish dish : menu) {
names.add(dish.getName());
}
}
}
内部迭代的方式:
//使用getName方法获取菜名;collect操作执行流水线,没有迭代操作
List<String> collect = menu.stream().map(Dish::getName).collect(Collectors.toList());
总结:外部迭代需要显示的取出每一个项目再加以处理,而内部迭代,stream流会自己选择更优的方式来进行处理,同时也更加美观。
流的使用(中间链操作)
流的使用包括三个部分,这三部分缺一不可:
1、一个数据源(如集合)来执行一个查询。
2、一个中间操作链,来形成一个流水线,比如filter、map、limit、sorted、distinct。
3、一个终端操作,它来执行流水线,并能生成结果,比如foreach、count、collect。
下面来说明一下流的使用方式
筛选和切片
filter
使用filter来筛选指定条件的元素,如下,来筛选所有偶数,并确保没有重复
List<Integer> integers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
integers.stream()
.filter(i->i%2==0)
.distinct()
.forEach(System.out::println);
limit
使用limit来截取指定前n个元素,如下,选出热量超过300卡路里的头三道菜
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.limit(3)
.collect(Collectors.toList());
skip
使用skip来跳过指定前n个元素,它和limit是互补的,如下,跳过热量超过300卡路里的头三道菜
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.skip(3)
.collect(Collectors.toList());
映射
map
map方法,它会对每个元素都进行操作,使其映射为一个新的元素,注意的是,它不会修改原来元素的内容,只会创建一个新的元素。如下,通过map来获取菜单的名字
List<String> dishes = menu.stream()
.map(item -> item.getName())
.collect(Collectors.toList());
//直接通过引用的方式来完成
List<String> dishes = menu.stream()
.map(Dish::getName)
.collect(Collectors.toList());
大部分情况下,我们还会有其他的操作,比如,获取每个菜单名字的长度,可以使用显示的声明方式(return和花括号可以省略)
List<Integer> dishes = menu.stream()
.map(item -> {
return item.getName().length();
})
.collect(Collectors.toList());
flatMap
flatMap方法,它用来将集合中所有的元素最终都转成同一个流,flat就是扁平化的意思嘛,顾名思义,就是把所有元素都装在一个篮子里面。举个例子,给定一个单词列表[“hello”,:“world”],想要返回列表 [“h”,“e”,“l”,“o”,“w”,“r”,“d”],应该怎么做,如果使用map的话,split返回的是一个String类型的数组,最终只能转成一个流的列表。
List<Stream<String>> collect = list.stream().map(item -> item.split("")).map(Arrays::stream).distinct().collect(Collectors.toList());
用flatMap可以解决以上问题,它的作用是:各个元素并不是分别映射成一个流,而是统一变成一个流!!使用如下:
List<String> collect = list.stream()
//使用map()转换成数组类型的流(因为split()方法返回的是一个String类型的数组)
.map(item -> item.split(""))
//再使用flatMap()方法将map()产生的所有流都统一转换成一个流
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
打印效果:

查找和匹配
anyMatch
使用anyMatch可以查看流中是否有匹配的元素,它返回的是一个boolean,因此是一个终端操作。比如,可以用它来查看菜单中是否存在素食的食物:
if (menu.stream().anyMatch(Dish::isVegetarian)){
//do something
}
allMatch
allMatch的使用和anyMatch差不多,它会查看流中的元素是都匹配给定的条件。比如,可以用它来查看菜品中的事务是否全都低于1000卡路里:
if (menu.stream().allMatch(item->item.getCalories()<1000)){
//do something
}
noneMatch
noneMatch和allMatch是相对的,它用来确保流中没有任何元素与指定的条件相匹配,这里就不太赘述了。
findAny
findAny方法会返回当前流中的任意元素,它可以和其他流操作结合使用。比如,想找到任意一个素菜:
Optional<Dish> any = menu.stream().filter(Dish::isVegetarian).findAny();
Optional类是一个容器类,如果没有找到合适的元素,Optional就是一个空的容器,它可以避免空指针,不在这里详细阐述。
findFirst
findFirst是找到符合条件的第一个元素,和findAny同理。
归约(reduce)
规约是将流中的所有元素反复结合起来,得到一个值(将流规约成一个值),下面不使用规约和使用规约来进行求和计算
//使用for循环来实现元素求和
int sum = 0;
for (Integer integer : integers) {
sum += integer;
}
//使用归约进行求和
Integer reduce = integers.stream().reduce(0, (a, b) -> a + b);
第一个参数为初始值
第二个参数是一个函数式接口BinaryOperator类型的,它将两个元素结合起来产生一个新的元素,然后新的元素再和下一个元素继续结合。也可以用来求最大值(Integer::max)和最小值(Integer::min)
BinaryOperator源码如下:
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
/**
* Returns a {@link BinaryOperator} which returns the lesser of two elements
* according to the specified {@code Comparator}.
*
* @param <T> the type of the input arguments of the comparator
* @param comparator a {@code Comparator} for comparing the two values
* @return a {@code BinaryOperator} which returns the lesser of its operands,
* according to the supplied {@code Comparator}
* @throws NullPointerException if the argument is null
*/
public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
/**
* Returns a {@link BinaryOperator} which returns the greater of two elements
* according to the specified {@code Comparator}.
*
* @param <T> the type of the input arguments of the comparator
* @param comparator a {@code Comparator} for comparing the two values
* @return a {@code BinaryOperator} which returns the greater of its operands,
* according to the supplied {@code Comparator}
* @throws NullPointerException if the argument is null
*/
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
}
数值流
为了避免装箱的操作,java8引入了三个原始类型的特化流接口来解决该问题:IntStream、DoubleStream、LongStream,可以分别将流中的元素转为int、long、double,比如随机生成指定范围(1到100)的数字,可以进行如下操作:
long count = IntStream.rangeClosed(1, 100).filter(n -> n % 2 == 0).count();
流的使用(终端操作)
流支持两种类型的操作,中间操作(filter、map等)和终端操作(count、findfist等),这里主要讲的终端操作是collect,它也是一个归约的操作,接收各种参数来返回一个汇总的结果。
collect方法是一个终端操作,它来消费map、filter等方法产生的流,它里面的参数是一个Collector,而这个Collector大多数都是通过Collectors工具类来生成,所以下面的很多内容都会涉及到Collectors。collect方法源码如下:

比如,查找一个菜单中热量最多的菜,可以使用maxBy方法:
maxBy
Optional<Dish> collect1 = menu.stream().collect(Collectors.maxBy(Comparator.comparing(Dish::getCalories)));
joining
将字符串进行拼接,可以使用joining方法
String collect2 = menu.stream().map(Dish::getName).collect(Collectors.joining(","));
reducing
使用reduing来计算菜单中所有菜的热量之和
Integer collect3 = menu.stream().map(Dish::getCalories).collect(Collectors.reducing(0, (a, b) -> a + b));
groupingBy—基本分组
使用groupingBy方法可以实现分组的操作,比如我想根据食物的类型进行对食物进行分类,可以操作如下
Map<Dish.Type, List<Dish>> dishMap = menu.stream().collect(Collectors.groupingBy(Dish::getType));
groupingBy方法的参数是一个函数式接口Function,可以使用引用的方式来声明。最终产生的结果是一个map,key是分组的条件,value是一个list,里面放的是符合该条件的对象。
但是有的时候操作场景比较复杂,不只简单的根据对象中的属性就可以进行分组,比如想将食物的热量根据不同的范围进行分组,也可以使用Function接口,用lambda表达式实现显示的声明:
Map<Dish.Type, List<Dish>> collect = menu.stream().collect(Collectors.groupingBy(item -> {
if (item.getCalories() <= 100) return Dish.Type.MEAT;
else if (item.getCalories() <= 400) return Dish.Type.FISH;
else return Dish.Type.OTHER;
}));
groupingBy—多级分组
多级分组,如果想在map里面的value(也就是list)再次进行分组的话,groupingBy也是支持多级分组的,在第二个参数继续使用groupingBy方法即可。可以把groupingBy看成“桶”,第一个groupingBy给每一个键建立了一个桶,然后再用下游的收集器去收集每个桶中的元素,依次来得到n级分组。
final Map<Dish.Type, Map<Dish.Type, List<Dish>>> collect = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.groupingBy(item -> {
if (item.getCalories() <= 100) return Dish.Type.MEAT;
else if (item.getCalories() <= 400) return Dish.Type.FISH;
else return Dish.Type.OTHER;
})));
groupingBy—重载方法
groupingBy有一个重载的方法,可以传入两个参数,第二个参数是一个Collector,它可以进一步的来筛选我们想要的元素,因此我们想要找出该食物类型中热量最高的食物是哪一个,可以使用groupingBy的重载方法:
Map<Dish.Type, Optional<Dish>> collect = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))));
groupingBy—结合collectingAndThen
但是上面value是用Optional来修饰的,如果想要把它去掉的话,可以使用Collectors.collectingAndThen方法来实现。该方法有两个参数,第一个参数是需要被转换的收集器,第二个参数是转换的函数(实际上是一个Function接口),该函数的作用是将第一个参数的值进行操作。collectingAndThen在groupingBy里面执行,意思是当groupingBy分完组之后,会产生几个流,然后collectingAndThen再对groupingBy产生的流分别进行操作。如下就是按照菜单的类型分完组之后(作为map的key),再找出不同类型下热量最高的食物,最后的函数是将Optionl的值用get方法将值取出来。
Map<Dish.Type, Dish> collect1 = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get)));
groupingBy—结合mappping
但是经常和groupingBy联合使用的另外一个收集器是mapping方法生成的,它和map方法非常的相似,也是进行映射,该方法有两个参数,一个对流中的元素做变换,另一个则将变换返回的结果收集起来,这样可以指定元素的类型,比如,下面可以将最终的结果转化成一个set。该含义是找出不同类型的食物,并按照热量的高低来划分级别。
Map<Dish.Type, Set<String>> collect2 = menu.stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.mapping(item -> {
if (item.getCalories() <= 100) return "low";
else if (item.getCalories() <= 400) return "middle";
else return "high";
}, Collectors.toSet())));
partitioningBy(分区)
分区函数partitioningBy得到的map是以布尔值进行分类的,最终将元素分为两组,一组是true,一组是false,使用分区,我们可以把菜单中的食物按照素菜和肉菜进行区分:
Map<Boolean, List<Dish>> collect3 = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian));
另外,partitioningBy也支持方法的重载,第二个参数可以再放一个收集器,比如想找到素菜和肉菜各自热量最高的食物,可以再次使用collectingAndThen()方法:
Map<Boolean, Dish> collect4 = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian,
Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)), Optional::get)));
打印collect4结果如下:

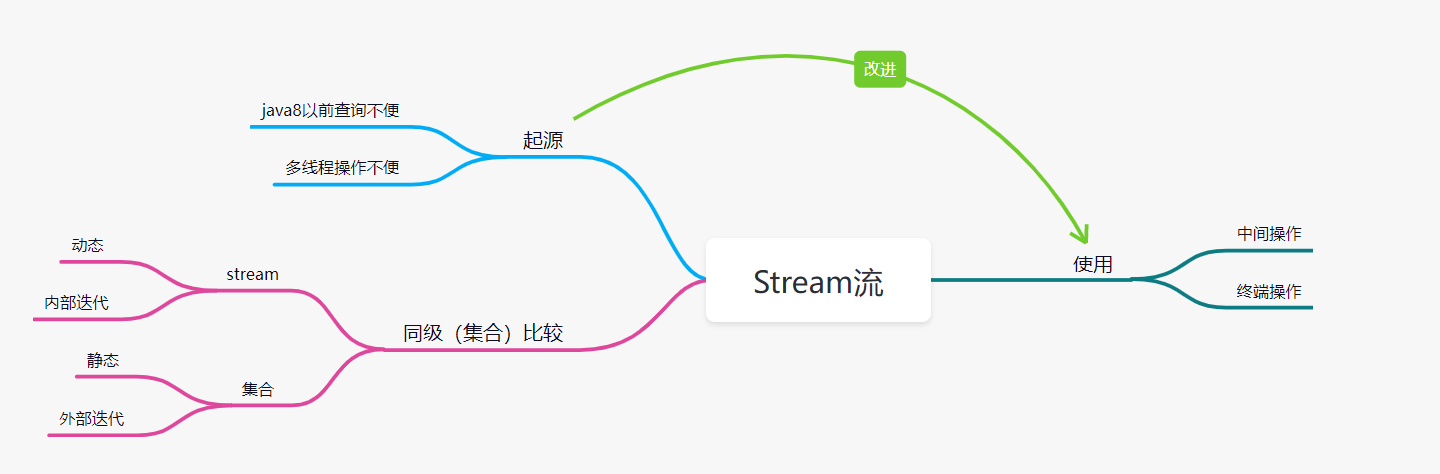
思维导图小总结
参考资料 《java8实战》
