在前面两节我们已经可以通过一个简单的多层神经网络来实现一些二分类的问题,但是当在某些情况下,我们的样本可能不止需要被分为不止一类,那么怎么样找到当前样本在这样多的分类种最有可能的情况就是我们需要解决的问题。
一个很简单的思路就是按照之前Sigmoid的方法计算之后,计算每个分类的值后,再计算每个分类值占总和的百分比,这样根据这个比例,我们就可以在多种的分类种类种找到最有可能的分类结果。这也就是激活函数Softmax的原理。而Softmax最重要的意义是将多分类的输出值转化为[0,1]之间和为1的概率分布。其函数表达如下所示:
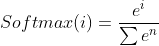
其中i代表第i个样品,n为待分类的种类数。
Softmax的matlab实现如下:
function y = Softmax(x)
ex = exp(x);
y = ex/sum(ex);
end接下来,我们就可以利用Softmax的激活方法来作为输出层的处理方法,进行多分类问题的求解了。下面我们继续之前的思路进行训练,训练的函数代码如下:
function [W1,W2] = MultiClass(W1,W2,X,D)
alpha = 0.9;%学习因子
N = 5;%输出分类数
for k = 1:N
x = reshape(X(:,:,k),25,1);%将图片5*5矩阵转化为25*1的向量,便于训练
d = D(k,:)';
v1 = W1*x;
y1 = Sigmoid(v1);%隐藏层输出结果,即输出层输入
v = W2*y1;
y = Softmax(v);%多分类问题采用softmax函数得到概率最大的分类结果
e = d-y;
delta = e;%采用交叉熵的学习规则,也可以不使用,则改为y.*(1-y).*e
e1 = W2'*delta;
delta1 = y1.*(1-y1).*e1;%反向传播算法,逆推隐藏层误差
%更新权重,训练一轮
dW1 = alpha*delta1*x';
W1 = W1+dW1;
dW2 = alpha*delta*y1';
W2 = W2+dW2;
end
end
为了检验我们这个模型的分类效果,接下来让我们用简单的5*5的数字矩阵作为训练集来训练我们的网络,之后,再对数字矩阵的个别元素进行替换,作为检验集来检验我们模型的效果。


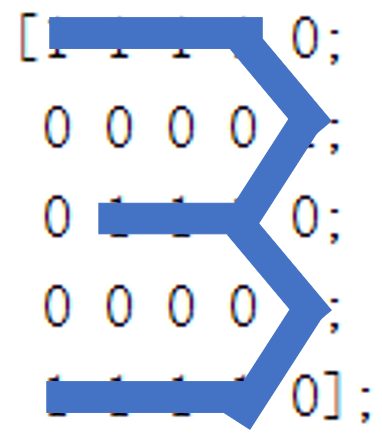
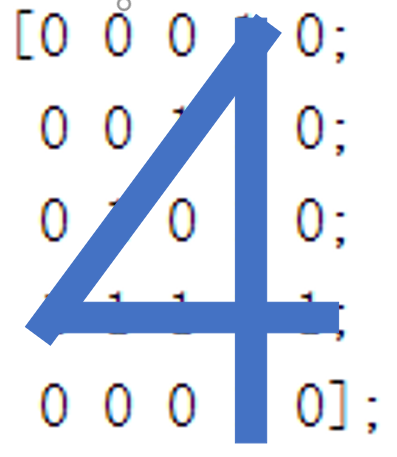
下面是利用训练集进行训练的代码,得到的对训练集的分类效果为D(初始化的标签矩阵)。
clc;clear all
X = zeros(5,5,5);%5页矩阵存储5种数值
X(:,:,1) = [0 1 1 0 0; %数字1
0 0 1 0 0;
0 0 1 0 0;
0 0 1 0 0;
0 1 1 1 1];
X(:,:,2) = [1 1 1 1 0; %数字2
0 0 0 0 1;
0 1 1 1 0;
1 0 0 0 0;
1 1 1 1 1];
X(:,:,3) = [1 1 1 1 0; %数字3
0 0 0 0 1;
0 1 1 1 0;
0 0 0 0 1;
1 1 1 1 0];
X(:,:,4) = [0 0 0 1 0; %数字4
0 0 1 1 0;
0 1 0 1 0;
1 1 1 1 1;
0 0 0 1 0];
X(:,:,5) = [1 1 1 1 1; %数字5
1 0 0 0 0;
1 1 1 1 0;
0 0 0 0 1;
1 1 1 1 0];
D = [1 0 0 0 0; %标签
0 1 0 0 0;
0 0 1 0 0;
0 0 0 1 0;
0 0 0 0 1];
%随机初始化权重
W1 = 2*rand(50,25)-1;
W2 = 2*rand(5,50)-1;
%训练
for epoch = 1:100000
[W1,W2] = MultiClass(W1,W2,X,D);
end
%训练集规模
N = 5;
%检验训练集的分类情况
for k = 1:N
x = reshape(X(:,:,k),25,1);
v1 = W1*x;
y1 = Sigmoid(v1);
v = W2*y1;
y = Softmax(v)
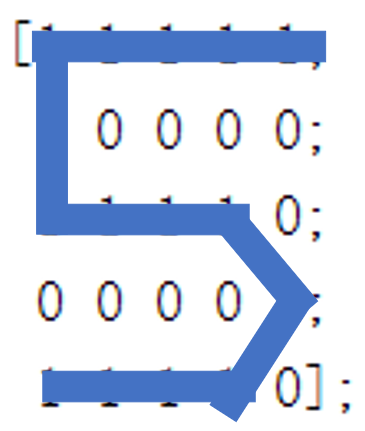
end为了检验我们的模型的分类效果,我们对之前的数字矩阵进行适当变换,而后重新进行分类检验,数字矩阵变化如下图所示:
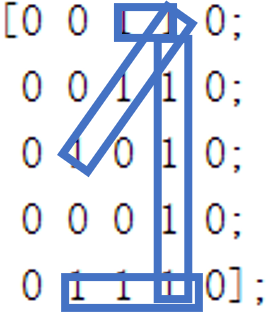

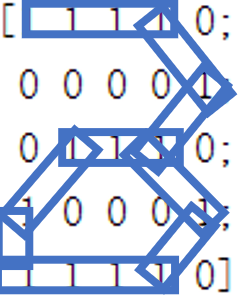
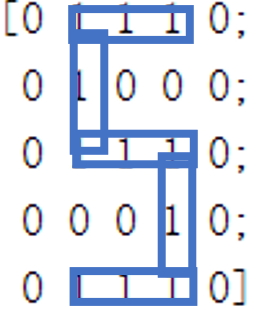
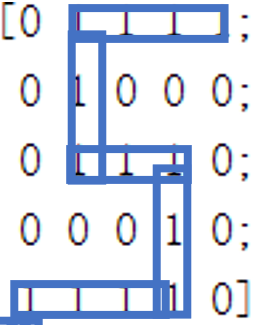
而对这样的数字矩阵进行分类只需训练后初始化矩阵,然后将五个图片输入模型中即可。
%% 训练
TestMultiClass;
%% 初始化5副图片
%略
%% 检验
N = 5;
for k = 1:N
x = reshape(X(:,:,k),25,1);
v1 = W1*x;
y1 = Sigmoid(v1);
v = W2*y1;
y = Softmax(v)
end而最终得到的结果为:
y1 =
0.0362
0.0035
0.0001
0.9600
0.0002
y2 =
0.0000
0.9984
0.0015
0.0000
0.0000
y3 =
0.0000
0.0197
0.9798
0.0000
0.0004
y4 =
0.4006
0.0453
0.4961
0.0111
0.0468
y5 =
0.0034
0.0248
0.0077
0.0010
0.9631可以发现对于图片2、3、5来说都可以做到准确的分类,这与我们的视觉直观感受是相似的,得到相同的结果。
而对图片1的检验结果为数字4,我们可能会直观的认为该图片与1更像,但是对于计算机来说,他并不知道这些形状的内容含义,只能简单粗暴的通过计算矩阵相似度的手段来进行分类,所以我们其实对矩阵元素进行分析也可以发现1图与数字4的矩阵元素排列更为相似。
同理,对于图4,上面的结论更为直观,明显的数字5形状却被分类为1或3,显然与结果并不相符。
而对这种情况的解决办法就是,增大我们的训练集,避免出现上述的过拟合情况的发生。其实真正的神经网络的训练过程都是需要成千上万起步的训练样本的,所以我们上面进行的训练其实是不科学和不严谨的,样本过少非常容易出现过拟合的状况。而在初步练习的过程中,我只是简单的进行了这样不科学的训练,但这样的错误也能够让我们实际的体会到神经网络的建立与训练检验的全过程,并得到一些预期的结果,更能让我们在发现问题后去寻找原因,最终解决问题。
因此,我们实际进行模型的训练时,需要去搜集相关的数据,只有大量的样本训练得到的模型才能达到我们预期的效果。










