文章目录
一、结构化查询语句
SQL是结构化查询语言,它是关系型数据库的通用语言。
SQL主要可以分为一下三种类型:
- DDL(Data Definition Languages)语句:数据定义语句,这些语句定义了不同的数据库、表、列、索引等对象。常用的语句关键字有create、drop、alter
- DML(Data Manipulation Languages)语句:数据操作语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字包括 insert、delete、update和select等
- DCL(Data Control Languages)语句:数据控制语句,用于控制不同的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别,常用的语句关键字包括grant、revoke
二、库操作
1. 查询数据库:
show databases;
2. 创建数据库
create database testdb;
3. 删除数据库
drop database testdb;
4. 选择数据库
use testdb;
三、表操作
因为业务层操作内存,MySQL操作磁盘,数据库永远是最先达到性能瓶颈,我们不能把过多的逻辑操作放在数据库上,逻辑操作应该在业务层做。
MySQL只做最核心的CRUD,触发器、存储函数、存储过程等都不会在MySQL上设置,统一迁移到业务层中的服务层做
1. 创建表:
create table stu(
id int unsigned primary key not null auto_increment,
name varchar(50) not null unique,
age tinyint not null,
sex enum("man","woman") not null
);
2. 查看表结构:
desc stu;
3. 删除表:
drop table stu;
4. 打印表创建的SQL:
show create table stu;
四、CRUD操作
1. 插入:
// id从1开始自增,上限和id的类型有关,到了上限就无法插入
insert into stu(name, age, sex) values("shen", 10, "man");
insert into stu(name, age, sex) values("zhang", 11, "woman");
insert into stu(name, age, sex) values("shen", 10, "man"),("zhang", 11, "woman");
2. 删除:
delete from stu;
3. 更新
update stu set age=age+1 where name="shen";
面试可能会问上述两种insert的区别:
批量导入数据的时候,常用的是一条SQL语句插入多条数据,而不是一条SQL插入一条数据。因为 每条SQL语句都需要C/S之间建立连接,最好是一条SQL插入更多的数据

五、查询操作
1. 去重:
select distinct age from stu;
2. union合并查询
select exp1, exp2, ..., expn
from tables [where conditions]
union [all|distinct] -- union默认去重,不用distinct修饰,all表示显示所有重复值
select exp1, exp2, ..., expn
from tables [where conditions]
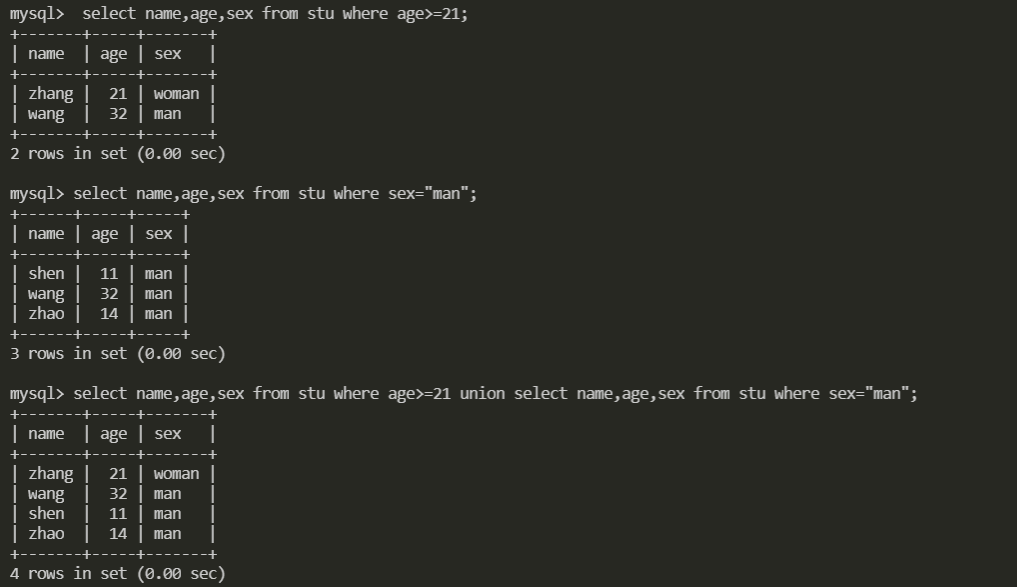
and用到索引,or被MySQL优化为union也用到了索引
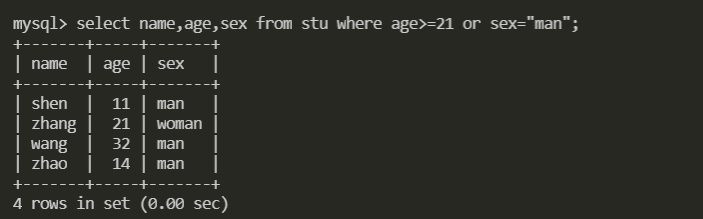
3. 带in子查询
select * from stu where age in (11, 22, 33);
select * from stu where age not in (11, 22, 33);
select * from stu where age between 11 and 22; -- [11, 22]
select name from stu where id in (select id from stu where age > 10);
4. 分页查询
-- 限制查询的数量,用法:limit count 或 limit start count
select * from stu limit 2; -- 偏移0条开始显示2条,limit 0, 2
select * from stu limit 1, 5; -- 偏移1条开始显示5条
select * from stu limit 5 offset 2; -- 偏移2条开始显示5条
select * from stu order by age desc limit 10,2; -- 先按照年龄降序排列,偏移10条显示2条
explain:查看SQL语句的执行计划,罗列SQL执行的一些关键信息,大致统计一些性能指标
创建表的时候关键字unique会创建索引
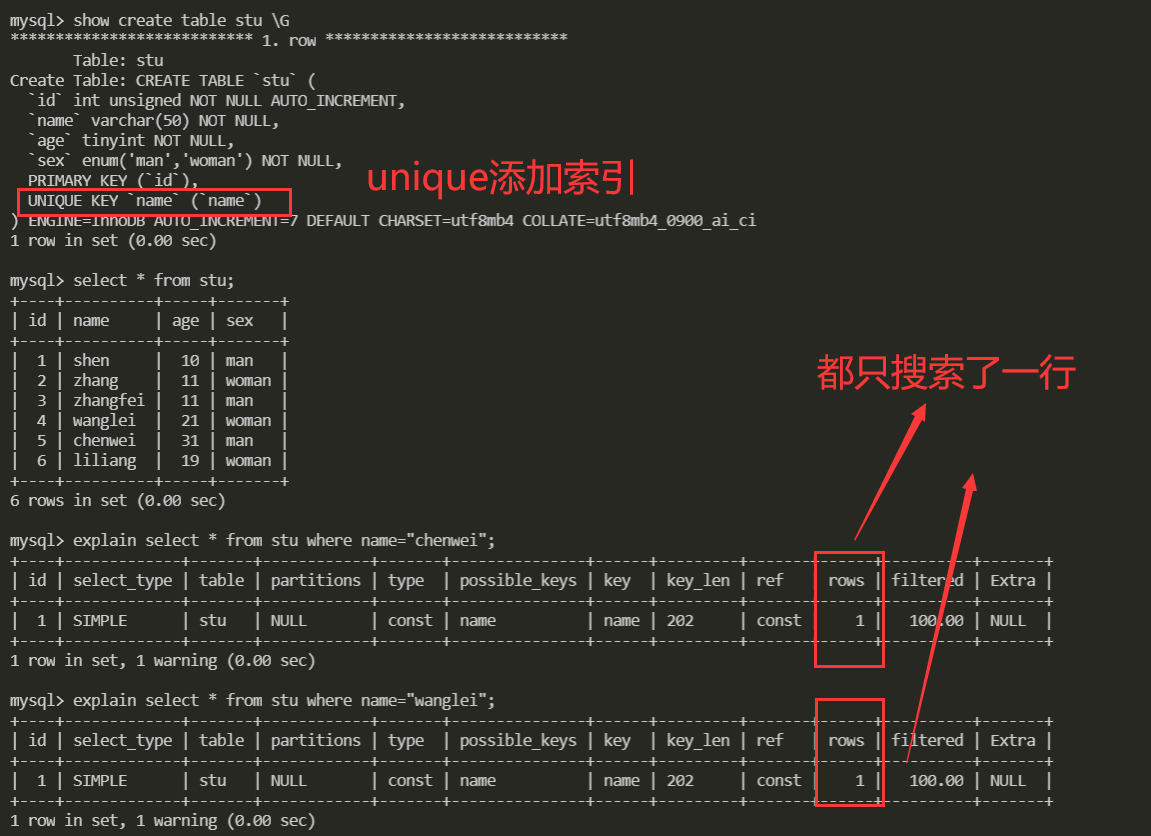
就比如我们注册QQ,登录的时候都会到数据库匹配信息,不可能是注册的早的人匹配信息快登录快,注册的晚的人匹配信息慢登录名。
查询一下age
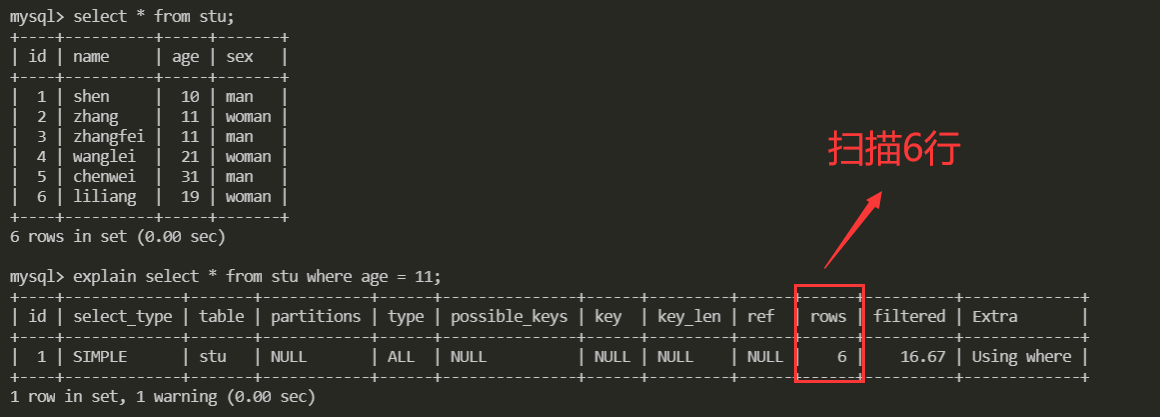
由于age没有添加索引,所以数据库引擎做的是整表搜索,效率很低
可以通过limit加快查找

使用大数据证实limit加快查找
建表、插入数据的过程见六

这里只使用了100000条数据,如果使用百万、千万级别数据,效果会更明显
扫描的数据一旦满足limit条件时,就会停止扫描,可以提高搜索效率
实际出现的效率问题:

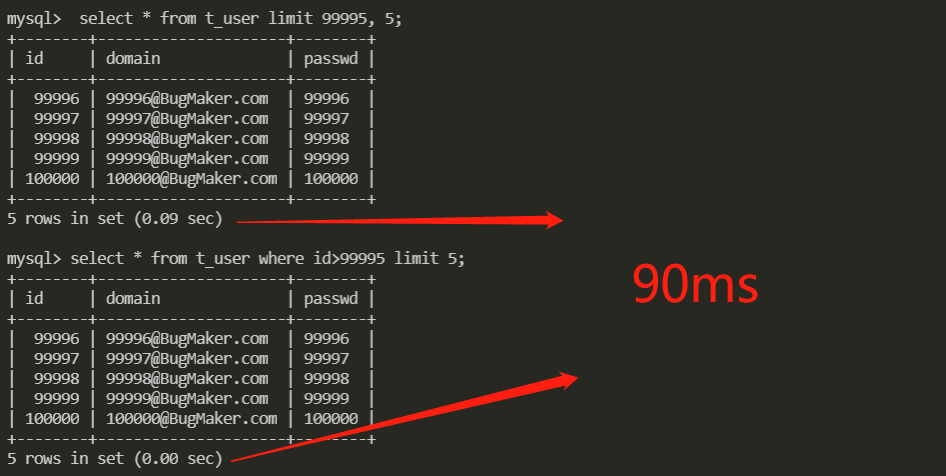
我们若使用如下SQL查询,就会有前几页查询快,后几页查询慢的问题
效率主要低在(page_num-1)*n偏移量,偏移需要花费时间
select * from t_user limit (page_num-1)*n, n;
我们可以使用id索引直接偏移
select * from t_user where id>(page_num-1)*n limit n;
六、创建存储过程procedure
create table t_user(
id bigint primary key not null auto_increment,
domain char(20) not null,
passwd char(20) not null
);
delimiter $ -- 修改MySQL的分隔符,避免和创建语句的分隔符冲突
create procedure add_t_user(in n int)
begin
declare i int;
set i = 0;
while i < n do
insert into t_user(domain, passwd) values(concat(i+1,"@BugMaker.com"), i+1);
set i = i + 1;
end while;
end$
delimiter ;
call add_t_user(100000);
其他常见的SQL语句可参考:MySQL笔记










