1. 性能功能特点
B站视频:DorisDB VS ClickHouse OLAP PK
1.1 DorisDB
场量:线上数据应用
访问官方网站
DorisDB企业版文档
DorisDB是鼎石科技由Apache Doris核心研发团队打造的新一代企业级MPP数据库。它继承了Apache Doris项目十多年研发成果,累积了线上数千台服务器稳定运行经验,并在此基础上,对传统MPP数据库进行了开创性的革新。DorisDB重新定义了MPP分布式架构,集群可扩展至数百节点,支持PB级数据规模,是当前唯一可以在大数据规模下进行在线弹性扩展的企业级分析型数据库。DorisDB还打造了全新的向量化执行引擎,单节点每秒可处理多达100亿行数据,查询速度比其他产品快10—100倍!
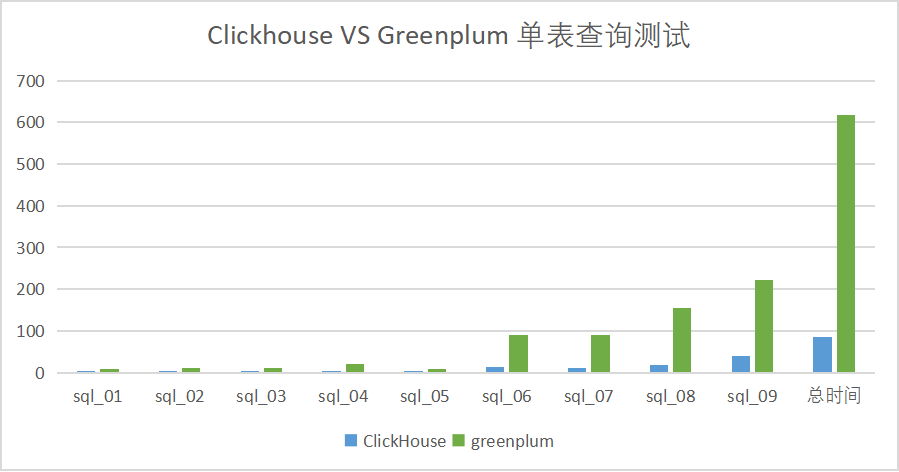
- 单表/多表查询,DorisDB总体时间最短
- 单表查询:DorisDB最快次数最多,ClickHouse次之
- 多表查询:DorisDB所有执行均最快
- DorisDB多表关联效率好
- 支持各种主流分布式Join,不仅支持大宽表模型,还支持星型模型和雪花模型
- 数据按列存储,第一列单独存放,查询时,只访问查询涉及的列,降低I/O
- Mysql协议兼容,支持标准的SQL语言,可直接对接主流的BI系统
- 与 R 语言可以实现无缝对接,用 R 语言可直接操作 Doris 数据库,进行数据分析、数据挖掘等工作
- 分片方式保存数据,小查询只需要用到部分机器资源,能极大提高并发查询量
- 可以实现多层聚合,能执行复杂的SQL查询,大表Join,高基数聚合查询
- 能有效利用多机资源保证查询性能,总体持有成本低,集群资源利用率高
- 数据导入有事务保证,可以很容易地实现不丢不重
- 支持实时数据的增量聚合计算
- 扩容时只需迁移部分数据分片,可线性扩展,副本自动均衡,系统自动完成,不影响线上服务
- 开箱即用,自适应,无须额外优化
- 高可用:无单点瓶颈(类Paxos一致性算法)
- 高度自治:无外部依赖,副本自修复,数据自均衡,一键扩容、缩容
- 极简运维:无外部依赖,整个系统只有两种进程,自动故障恢复(可视化运维管理平台需要企业版)
- 可视化管理 工具,生态完善,使用 Prometheus、Grafana 将监控项指标列出
- 支持云化部署
- 支持在线更改表模式(加减列,创建 Rollup),不影响当前服务,不阻塞读、写操作,异步执行不需要用户一直盯着
- 稳定可靠:完成SSB等测试集功能完备,每天千万条随机SQL验证,引入SQLite/Spark等外部DB 200万标准测试集通过
- 内部支持订阅 Kafka 数据流,实现直接对接 Kafka(可自动感知 Kafka 中 partition 变化,合理调度并发导入),支持对 Kafka 原始数据做二次处理(如转换,过滤等)
- 三层微批驱动(MPP+调度)
- DWD 明细层: 明细事实、维度表、明细宽表
- DWS 汇总层:公共汇总、通用视图、聚合宽度
- ADS 应用层:业务指标、汇总结果、物化视图
- 美团 VIPKID 等大厂用作数据分析平台,可服务高并发固定报表,
OLAP高维分析和Adhoc即席查询(可通过Mysql Binlog->Kafka->DorisDB同步数据) - 极速向量化引擎
【主要缺点】
- DorisDB 主要解决 PB 级别的数据量(如果高于 10 PB 级别,不推荐使用,可以考虑用
Hive等工具) - 不适合做大规模的批处理,当前版本由于是全内存计算,所以面对大规模数据的复杂ETL容易内存不足(短期内可能不能得到解决,官方称这是之后研发的一个方向)
- 目前不支持insert overwrite,可以用truncate+insert into代替
- 周边生态比较不完善
- 部分SQL语法不支持
【商业特性】
- 暂未开源,承诺可以免费永久使用
- 社区核心研发人员都是中国人,国内有商业化支持,服务更加本地化,支术支持无障碍
- 百度将 Doris 贡献给 Apache 社区之后,许多外部用户也成为了 Doris 的使用者,例如新浪微博,美团,小米等著名企业
- Apache Doris开源版可直接下载使用,DorisDB分标准版和企业版,需要申请使用
【部署环境】
- 准备
3台物理机: Linux(Centos 7+)、Java 1.8+ - CPU需要支持
AVX2指令集。cat /proc/cpuinfo |grep avx2有结果输出表明CPU支持,如果不支持建议找合适的机器进行部署测试,DorisDB使用向量化技术需要一定的指令集支持才能发挥效果。 - 将DorisDB的二进制产品包分发到目标主机的部署路径并解压,可以考虑使用新建的DorisDB用户来管理。
- BE推荐16核64GB以上(DorisDB的元数据都在内存中保存),FE推荐8核16GB以上
- 磁盘可以使用HDD或者SSD
- 网络需要万兆网卡和万兆交换机
- FE节点之间的时钟相差不能超过
5s,使用NTP协议校准时间。一台机器上只可以部署单个FE节点。所有FE节点的http_port需要相同。 - 一般至少部署3个BE实例,每个实例的添加步骤相同
【基本概念】
- FE:FrontEnd DorisDB的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。
- BE:BackEnd DorisDB的后端节点,负责数据存储,计算执行,以及compaction,副本管理等工作。
- Broker:DorisDB中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
- DorisManager:DorisDB 管理工具,提供DorisDB集群管理、在线查询、故障查询、监控报警的可视化工具。
- Tablet:DorisDB 表的逻辑分片,也是DorisDB中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个Tablet存储在不同BE节点上。
【资源下载】
Release Notes:
https://forum.dorisdb.com/t/topic/301
文档地址:
http://doc.dorisdb.com/
测试FAQ:
http://doc.dorisdb.com/2228586
1.2 ClickHouse
场景:日志分析、宽表分析
ClickHouse全称是Click Stream,Data Warehouse,简称ClickHouse就是基于页面的点击事件流,面向数据仓库进行OLAP分析。ClickHouse是一款开源的数据分析数据库,由战斗民族俄罗斯Yandex公司研发的,Yandex是做搜索引擎的,就类似与Google,百度等。
- 毫秒级响应,为了高效的使用CPU,数据不仅仅 按列存储,同时还按向量进行处理(区别与HBase,ClickHouse的是完全列式存储,HBase具体说是列族式存储)
- 数据压缩空间大,减少IO;处理单查询高吞吐量每台服务器每秒最多数十亿行
- 写入速度非常快,50-200M/s,对于大量的数据更新非常适用
- ClickHouse多表 查询需要更改SQL ,使类型一致才可以,且字段名、表名区分大小写
- ClickHouse单机性能强悍,性价比较高
- 不需要任何数据预处理
- 支持批量更新
- 支持高可用(多主结构,在后面的结构设计中会讲到)
- 不依赖Hadoop复杂生态(像ES一样,开箱即用)
【主要缺点】
- 不支持事务,不支持真正的删除/更新,ClickHouse的定位是 分析性数据库,而不是严格的关系型数据库
- 不支持标准的SQL语言,无法直接对接主流的BI系统(最新版已支持类似SQL的join,但性能不好)
- 几乎不支持分布式Join,在分析模型上仅支持大宽表模式
- 不支持高并发,Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数
- 难以实现高并发查询,且无法通过扩容提高并发能力
- MergeTree合并不完全
- 聚合操作依赖单点完成,操作数据量大时存在明显性能瓶颈
- 对高基数列进行精确去重操作(如计算APP的DAU)时,受限于单点聚合的处理方式,性能瓶颈明显
- 受限于单机的物理内存,一旦query的mem消耗过大,将被kill
- 不擅长根据主键按行粒度查询(但是支持这种操作)
- 不擅长按行删除数据(但是支持这种操作)
- 没有强类型校验,数据可能被内部机制进行截取,造成数据不一致
【商业特性】
- 不盈利
- 俄罗斯的‘百度’叫做
Yandex,战斗民族开源神器
【部署环境】
- ClickHouse 可以在任何具有 x86_64、AArch64 或 PowerPC64LE CPU 架构的 Linux、FreeBSD 或 Mac OS X 上运行
- 官方预构建二进制文件通常针对 x86_64 进行编译并利用 SSE 4.2 指令集
【其他】
- MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,有多少CPU,吃多少资源,所以飞快
1.3 TiDB
场景:OLTP 同时兼顾OLAP
- 支持更新/删除
- 兼顾了OLTP的需求
- 支持Flink ExactlyOnce语意,支持幂等
【主要缺点】
- 无列式存储 (新版本有了)
- 无预计算手段
- 无向量化执行
- 无预聚合功能
- OLAP 性能相对 ClickHouse 或 DorisDB 较弱
2. 名词简介
MPP
MPP ( Massively Parallel Processing ),即大规模并行处理,海量数据并发查询。
在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。简单来说,MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。
OLAP
数据分析的目标则是探索并挖掘数据价值,作为企业高层进行决策的参考,通常被称为OLAP(On-Line Analytical Processing,联机分析处理)。
业务数据积累时所产生的价值信息则被OLAP不断呈现,企业高层通过参考这些信息会不断调整经营方针,也会促进基础业务的不断优化。
OLAP不应该对OLTP产生任何影响,(理想情况下)OLTP应该完全感觉不到OLAP的存在。
OLTP
业务类系统主要供基层人员使用,进行一线业务操作,通常被称为OLTP(On-Line Transaction Processing,联机事务处理)。从功能角度来看,OLTP负责基本业务的正常运转。
物化视图
物化视图是提取某些维度的组合建立对用户透明的却有真实数据的视图表格。类似于MSSQL Server中的snapshot,静态快照。