安装包下载地址zookeeper 3.4.9+kafka 2.12_2.6.1
链接:https://pan.baidu.com/s/1aqBQVMxMNa7RrMfxmg65cw
提取码:s3ms
链接:https://pan.baidu.com/s/1Hr2pcqXUsQMrdxyLkuWZUA
提取码:9cwl部署zookeeper集群
(网络需要打通3个端口 2181对外提供服务端口(kafka用),2888 leader和follower通信端口,3888 leader选举的端口)
三台节点部署zookeeper集群
解压文件
tar -xzf zookeeper-3.4.9.tar.gz -C /usr/local切换目录
cd /usr/local/zookeeper-3.4.9修改配置
- 1,zookeeper-3.4.9/conf目录下的zoo_sample.cfg文件拷贝一份,命名为“zoo.cfg”,使用以下命令
cp zoo_sample.cfg zoo.cfg2,创建两个文件夹
进入cd zookeeper-3.4.9 目录创建两个文件夹zkdata和zklog,命令如下:
mkdir zkdata
mkdir zklog3, 编辑zookeeper的配置文件
vim zookeeper3.4.9/conf/zoo.cfg增加如下内容:
其中dataDir为上一步创建的zkdata的绝对路径;dataLogDir为zklog的绝对路径;截图仅供参考
dataDir=/usr/local/zookeeper-3.4.9/zkdata
dataLogDir=/usr/local/zookeeper-3.4.9/zklog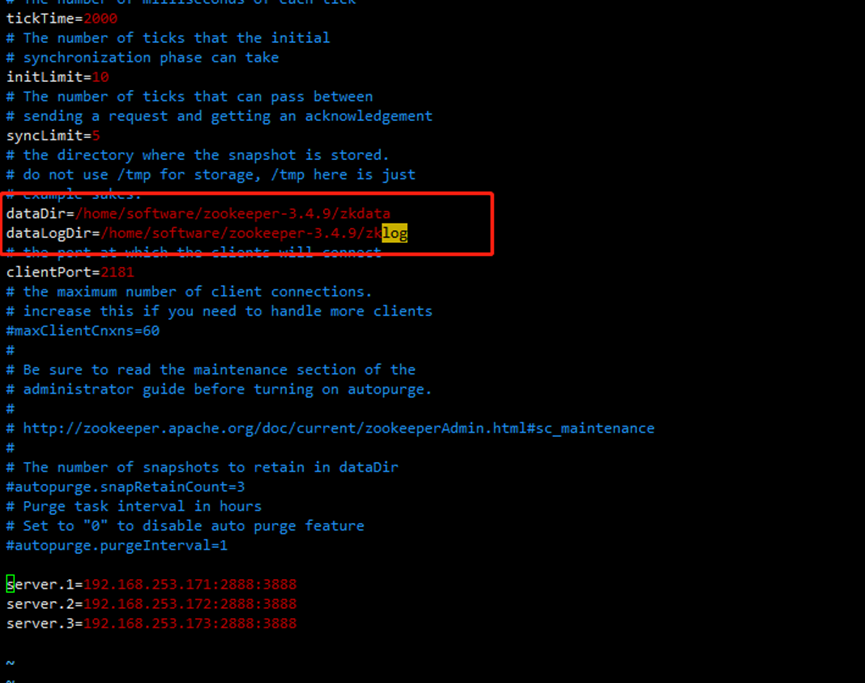
文件末尾添加如下内容,注server.1中的1为myid中的对应的数字标识,node01为节点的ip地址,第一个端口2888为master和slave之间的通信端口,默认是2888;第二个端口3888是leader选举的端口,默认是3888,截图仅供参考
server.1=node01(节点ip地址):2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888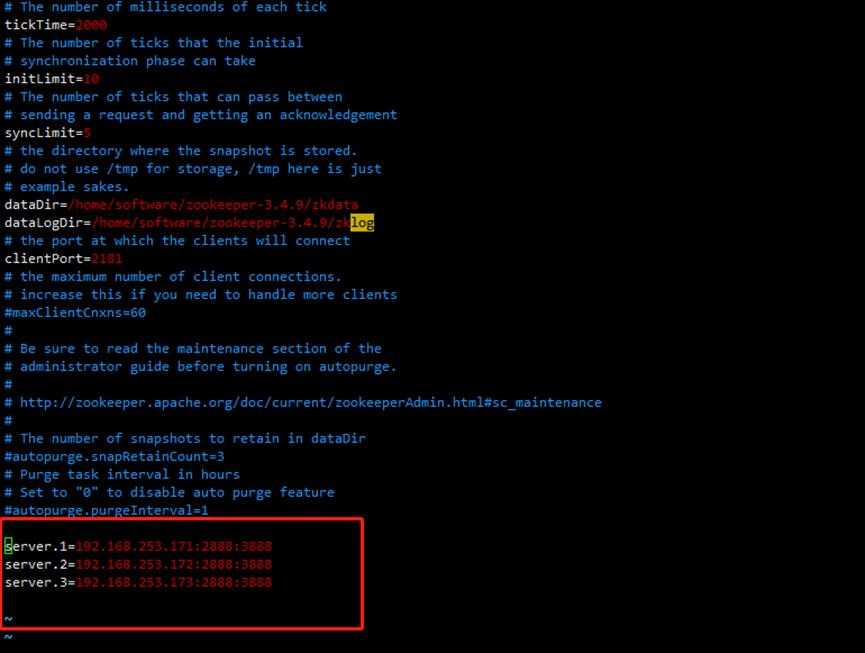
4,切换到zkdata目录,
cd zkdata然后创建文件myid文件,依次写入节点名称1(注意不同节点myid文件里的数字是不一样的,依次为 1 2 3)
echo 1 > myid
启动
1,依次启动zookeeper节点
切换到 zookeeper3.4.9/bin目录下,使用命令,启动命令如下:
cd zookeeper3.4.9/bin
./zkServer.sh start
2,查看服务状态
./zkServer.sh status
部署kafka集群(kafka集群依赖jdk 1.8)
上传文件
上传压缩包kafka_2.12-2.6.1.tgz
解压安装包,切换解压目录
tar -xzvf kafka_2.12-2.6.1.tgz -C /usr/local
cd /usr/local/kafka_2.12-2.6.1修改kafka配置文件
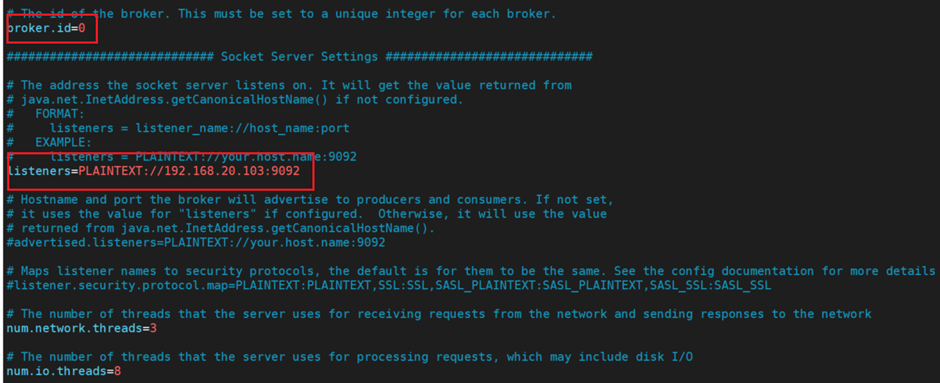
vim config/server.properties1,修改属性broker.id=0,不同节点该值不一样,依次递增(0 1 2);
2,修改kafka监听地址,端口可以使用默认值9092;
listeners=PLAINTEXT://192.168.20.93:9092如下图所示:
3,修改kafka持久化路径,建议修改为容量大的磁盘路径(该路径用于持久化数据),建议创建多个日志目录(多个目录用逗号分隔),截图仅供参考,如下所示
log.dirs=/tmp/kafka-logs,/opt/kafka-logs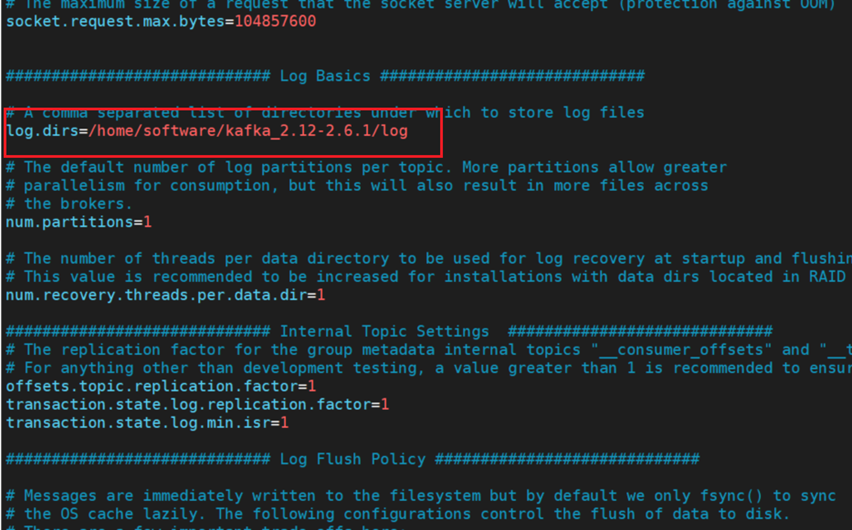
4,修改zookeeper的监听地址,集群地址用逗号隔开(根据自己实际情况填写服务器地址)
zookeeper.connect=192.168.xx.xxx:2181,192.168.xx.xxx:2181,192.168.xx.xxx:21815,配置不允许程序创建主题,(防止主题名称不规范,主题列表建议工程维护)
在配置文件末位添加如下:
auto.create.topics.enable=false6,修改位移主题副本数,建议为3,该参数决定位移主题的高可用
offsets.topic.replication.factor=3
启动
依次在三台机器上部署kafka
1,启动kafka命令,切换到目录 kafka_2.12-2.6.1,使用命令
nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &2,使用如下命令,查看服务启动日志
tailf logs/server.log3,使用如下命令,查看服务状态
ps -ef |grep kafka
kafka常用命令(在安装目录下执行)
1,查看主题列表(其中localhost为zookeeper的地址和端口)
bin/kafka-topics.sh --zookeeper localhost:2181 --list2,创建主题 partition 分区数(负载均衡用,一般分区数越大,吞吐量越大,如果3节点的kafka集群建议为3-6个分区数), replication-factor 副本数(应小于等于启动的集群服务器个数,如果3节点的集群集群建议为3副本)
(其中localhost为zookeeper的地址和端口)
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test-perf --partitions 6 --replication-factor 33,消费者消费消息测试脚本,其中bootstrap-server为kafka的地址和端口
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-perf --from-beginning4,生产消息测试脚本,其中bootstrap-server为kafka的地址和端口
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test-perf(注:可在两台服务器上分别模拟生产者与消费者,进行kafka消费的场景的演示)










