CLIP改进工作串讲(上)
本文为 CLIP 改进工作串讲(上)【论文精读】 的学习笔记。
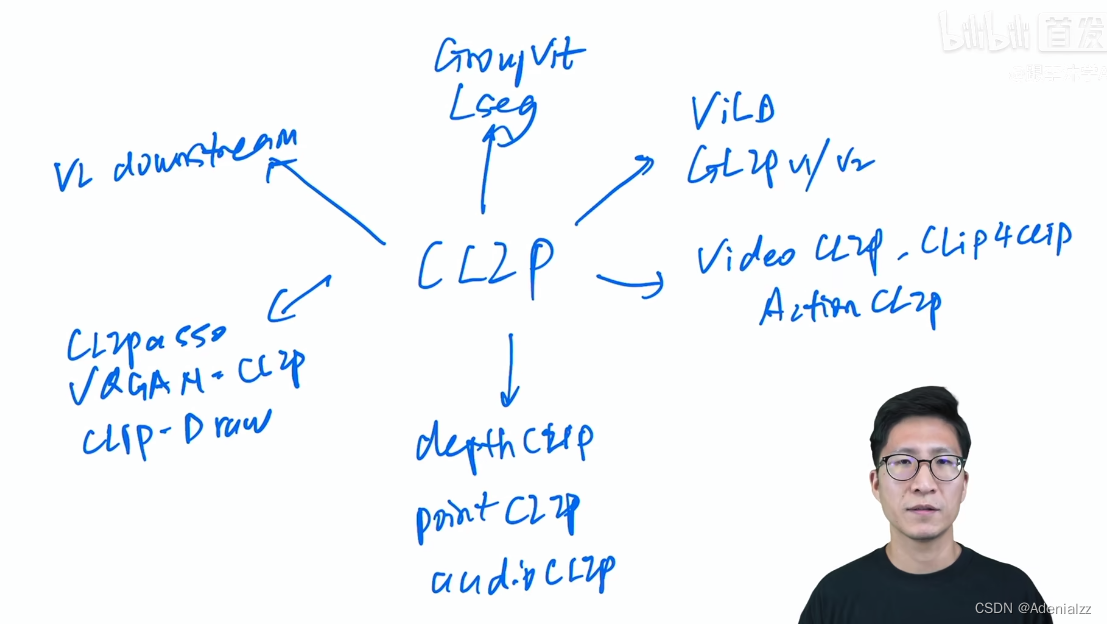
CLIP 改进方向
- 语义分割
- Lseg、GroupViT
- 目标检测
- ViLD、GLIP v1/v2
- 视频理解
- VideoCLIP、CLIP4clip、ActionCLIP
- 图像生成
- VQGAN-CLIP、CLIPasso、CLIP-Draw
- 多模态下游任务
- VL Downstream
- 其他
- depthCLIP、pointCLIP、audioCLIP
CLIP
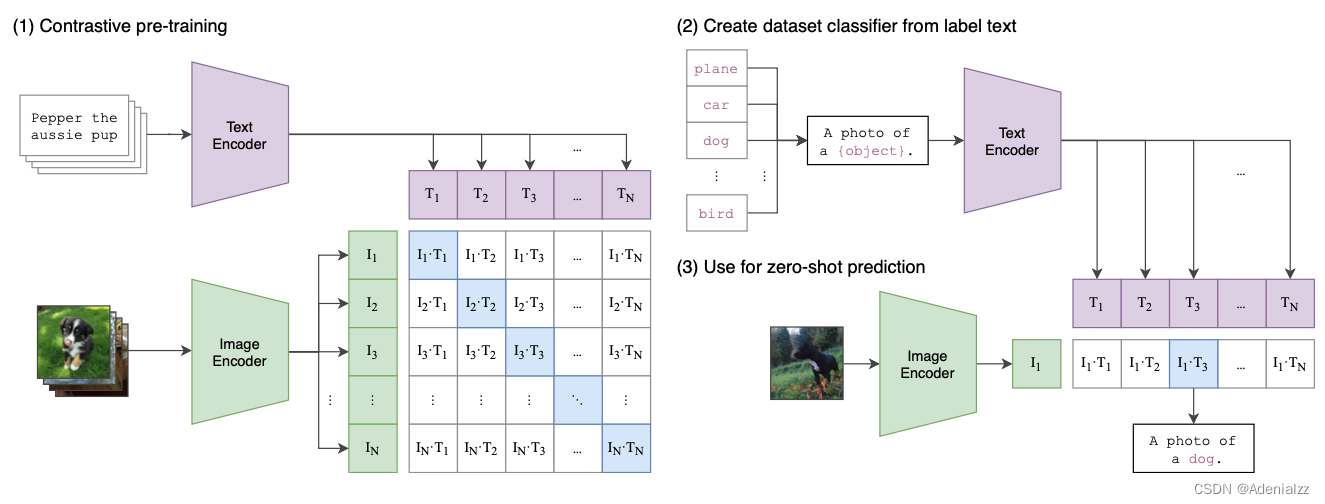
首先来简单回顾一下 CLIP 模型。CLIP 的做法其实非常简单,如图 2 所示,它在大量(400M)图片文本对上以对比学习的形式进行训练。来自同一个图文对的图片特征和文本特征是正样本对,应当有较高的相似度;来自不同图文对的则是负样本对,应当有较低的相似度。训练完成后,CLIP 模型文本编码器提取的文本特征和图片编码器提取的图片特征是在同一个特征空间,可以直接计算输入图片和文本的相似度。
有了这种图文相似度计算的能力之后,能做的事情就非常多了。其中论文强调的一个应用是 zero-shot 的分类,即不需看过数据集中的任何一个样本,就可以对数据集中的图片进行分类。听起来好像匪夷所思,但实际上,在文本 prompt 的帮助下,CLIP 确实能做到 zero-shot。如图 2 右侧所示,CLIP 模型进行 zero-shot 预测的方式是这样的:首先将数据集中的所有类别(如 ‘cat’、‘dog’ 等)通过句式生成文本 prompt(如 ‘A photo of a dog.’),然后将得到所有类别的文本 prompt 提取文本特征,并与测试图像计算图文相似度,相似度最高者即认为是模型的预测结果。形象点来说,就是对于一张测试图像,拿着所有该数据集内的类别信息来查询:这是一只狗吗?这是一只猫吗?这是一架飞机吗?…
因此,得益于巨大的训练数据量,CLIP 模型几乎能识别所有常见的文本和图片,提取它们各自的特征。并且,两种模态的特征是在同一个文本-图片联合特征空间中,可以直接计算跨模态的图文相似度。这也是 CLIP 模型本质上提供的能力:计算图文相似度。CLIP 最精髓的地方正如其题目所说,“Learning Transferable Visual Models From Natural Language Supervision” 是要用自然语言作为监督,来学习可迁移的视觉模型。
语义分割
LSeg
简介
语义分割可以看做是像素级的分类,因此分类的新技术、新思路,一般可以直接用过来。本文实现了 zero-shot 的语义分割,实现方式与 CLIP 实现 zero-shot 的方式类似,都是通过类别 prompt 作为文本输入,然后计算相似度。
结果展示
先看一些结果。图 3 展示了给定一张图片,然后通过文本 prompt 给任意的类别,从而实现对应的语义分割。可以看到,
- 给定了对应的类别 prompt,那么对于图中明确出现了的语义类别(如dog、tree)模型能够很清楚地分割出来;
- 对于图中没有的类别(如vehicle),模型也不会误召回;
- 对于图中有,但是类别 prompt 没给的(如tree、grass),也能正确分类为 other;
- 对于数据集中未曾出现过,但是相近的类(如pet),模型也能够通过语义识别出来
值得一提的是,由于 CLIP 类的模型实质上都是通过计算图文相似度来实现分类或分割的,因此 ‘other’ 类的类别 prompt 文本实际可以是任何无意义的文本,如 ‘me’,‘a’,‘an’ 等,只要与目标类别不要太接近即可。

模型框架与训练过程
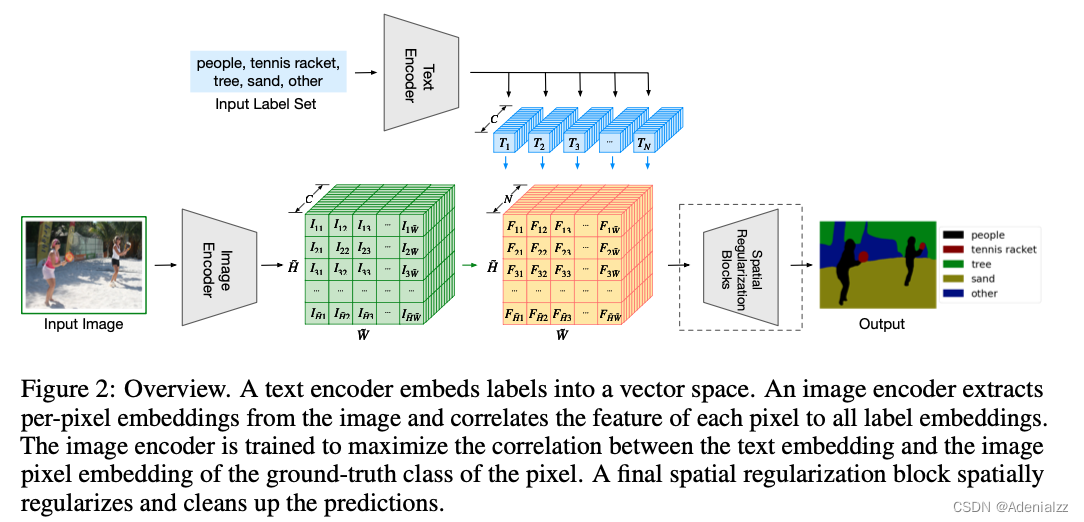
然后来看一下模型框架与训练过程。如图 4 所示,模型整体看来与 CLIP 模型非常相似,只是将单个的图像文本特征换成语义分割中逐像素的密集特征。文本编码器提取 N × C N\times C N×C 的文本特征,图像编码器提取 H ~ × W ~ × C \tilde{H}\times\tilde{W}\times C H~×W~×C 的密集图像特征,二者相乘得到 H ~ × W ~ × N \tilde{H}\times\tilde{W}\times N H~×W~×N 的特征,再经过 Spatial Regularization Blocks 上采样回原图尺寸,完成语义分割。其中 N , C , H ~ , W ~ N,C,\tilde{H},\tilde{W} N,C,H~,W~ 分别是类别 prompt 个数(可变)、通道数和特征图的高宽。除了上方的文本编码器提取的文本特征要与密集图像特征相乘来计算像素级的图文相似度之外,整个网络与传统的有监督网络完全一致。
在训练过程中,模型是以有监督的方式进行训练的,也就是说训练过程中是存在标注的分割图的,模型在 7 个分割数据集上进行训练。
在推理时,可以指定任意个数、任意内容的类别 prompt 来进行 zero-shot 的语义分割。
其他细节如下:
-
LSeg 整个文本编码器就是 CLIP 的文本编码器的模型和权重,并且训练、推理全程中都是冻结的;
-
LSeg 的图像编码器可以是任何网络(CNN/ViT),需要进行训练;
-
Spatial Regularization Blocks 是本文提出的一个模块,为了在计算完像素级图文相似度后有一些可学习的参数来理解计算结果,是由一些卷积和逐深度卷积组成;
定量实验结果
实验结果这里就只展示一个有代表性的定量实验对比。观察图 5 表格可知,LSeg 在 zero-shot 的语义分割上确实大幅领先之前方法,但是与 few-shot 哪怕是 one-shot 相比,还是有很大的距离。

GroupViT
简介
LSeg 虽然能够实现 zero-shot 的语义分割,但是训练方式并不是对比学习,没有将文本作为监督信号,因此还是需要有监督的分割图标注进行训练。而且由于语义分割的标注非常麻烦,因此分割领域的数据集都不大,LSeg 用的 7 个数据集加起来可能也就一二十万个样本。如何像 CLIP 一样,利用到文本来进行自监督训练呢?GroupViT 就是语义分割领域像 CLIP 一样使用文本来自监督训练的代表工作之一。GroupViT 通过文本自监督的对比学习来进行语义分割的训练,在推理阶段,可以实现 zero-shot 的推理,GroupViT 的问题概览如图 6 所示。
如标题所说,GroupViT 的核心思想是利用了深度学习之前无监督分割的 grouping 思想。当时的做法大概是在确定某个中心点之后,不断向外发散,将接近的点都分到一个 group 中,最终发散完毕,得到分割结果。在 GroupViT 中的 grouping 是将 ViT 中的图像块 token进行分配,分配到不同的语义类别 token 上。
模型框架与训练过程
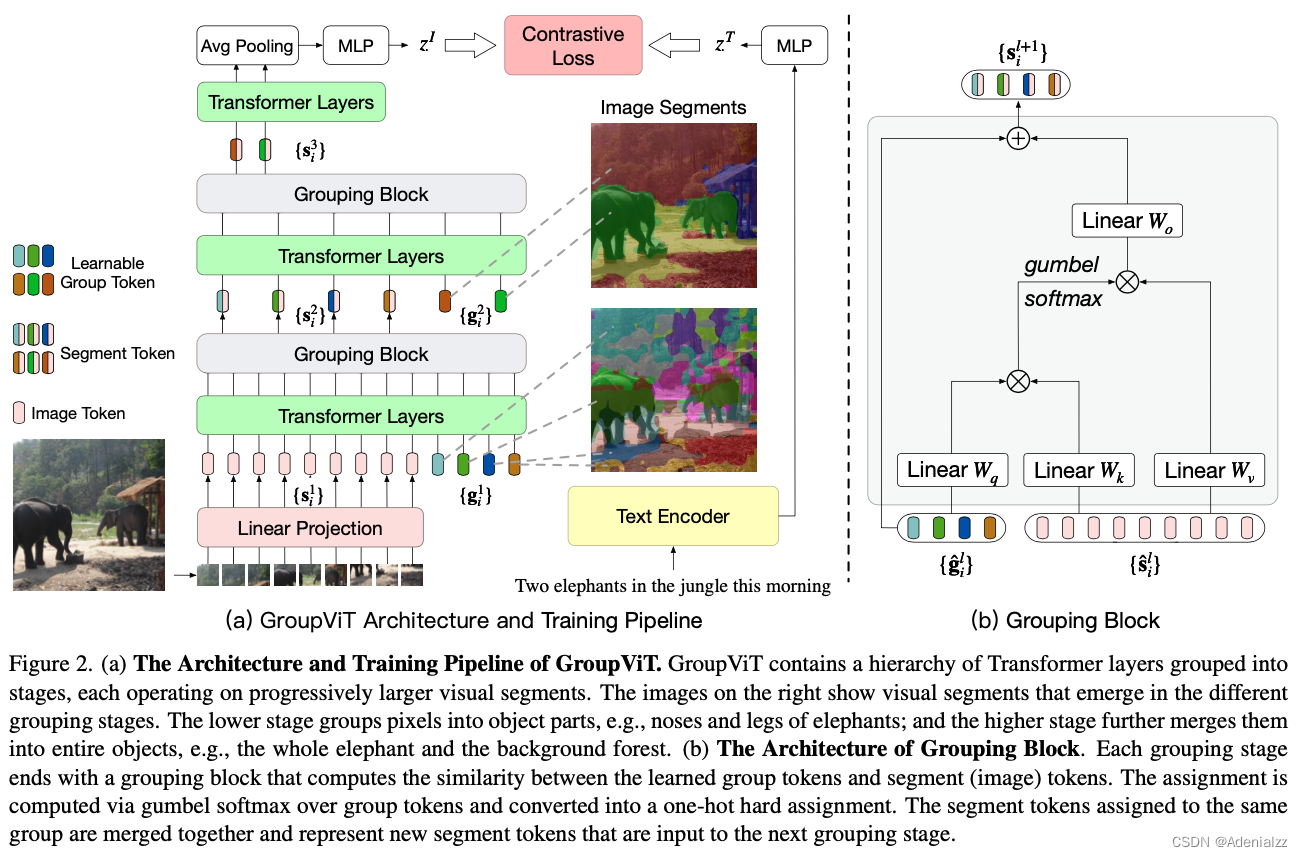
下面来看一下 GroupViT 具体是怎样进行训练的。模型框架和训练过程如图 7 所示。
- 送入 Transformer 的除了图像块 token s i 1 \mathbf{s}_i^1 si1 (尺寸 N × D N\times D N×D) ,还有可学习的 group token g i 1 \mathbf{g}_i^1 gi1 (尺寸 M 1 × D M_1\times D M1×D) 。这里的 group tokens 就相当于分类任务中的 cls token,由于分类任务一张图像只需要一个全图的特征,因此只用一个 token 即可,而语义分割中一张图需要多个特征,因此是多个 group tokens。
- 经过六层 Transformer Layers 的学习之后,通过 Grouping Block 来完成 grouping ,将图像块 token 分配到各个 group token 上,合并成为更大的、更具有高层语义信息的 group。Grouping token 的做法如图 7 右侧所示,与自注意力机制类似,就是计算图像块 token 与 grouping token 的相似度分配到最大的上面。这里为了克服 argmax 的不可导性,使用了 gumbel softmax。合并完成后得到 s i 2 \mathbf{s}_i^2 si2 (尺寸 M 1 × D M_1\times D M1×D) 。
- 然后再添加新的 Group tokens g i 2 \mathbf{g}_i^2 gi2 (尺寸为 M 2 × D M_2\times D M2×D),重复上述过程:经过 3 层 Transformer Layers 的学习之后,在经过再一次的 grouping block 分配之后,得到 s i 3 \mathbf{s}_i^3 si3 (尺寸 M 2 × D M_2\times D M2×D) 。
- 这里就要用语义编码器提取的语义特征来监督了,但是不同于分类任务只有一个图像特征,这里有 M 2 M_2 M2 个图像特征,怎么计算其与文本特征的相似度呢?这里作者用了最简单的办法,直接平均池化,得到一个 D D D 维的图像特征 z I \mathbf{z}^I zI ,与文本特征 z T \mathbf{z}^T zT 计算对比损失。
其他细节:
- 除了与图形配对的文本本身,还将文本中的名词提取出来,按照类似 CLIP 中的方法生成 prompt (如 “A photo of a {tree}.”),与某个图像特征计算对比损失,见原文 Figure 3;
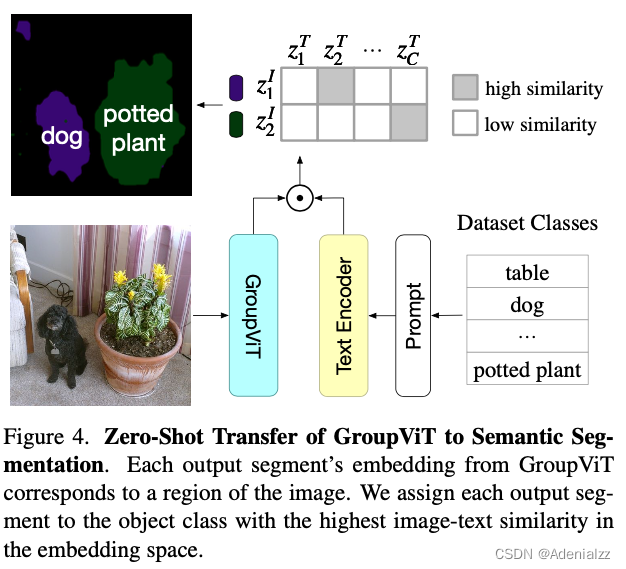
推理过程
然后来看一下 GroupViT 是如何进行 zero-shot 推理的。如图 8 所示,GroupViT 实现 zero-shot 推理的方式与 CLIP 十分相似,先通过图像编码器得到 M 2 M_2 M2 个图像特征,然后将它们分别与给定类别 prompt 提取的文本特征计算相似度,取最大值。但是这样实现 zero-shot 一个很明显的缺点是能检测到的图像中的类别个数最多只能是 M 2 M_2 M2 个。
其他细节:
- 对于语义分割中的背景类,GroupViT 在推理时是这样处理的:如果某个图像特征与所有文本特征的相似度都在某个阈值以下,就判断为背景类
可视化结果
GroupViT 中不同阶段不同 group token 对应的注意力区域可视化结果如图 9 所示。可以看到,在第一阶段,每个 token 都注意到一些语义明确的区域,如眼睛、四肢,并且,都是些相对较小的区域;在第二阶段,每个 token 注意到的语义区域则相对较大,如脸、身体。这正符合了作者想要的 group 分组合并的效果。

定量实验结果
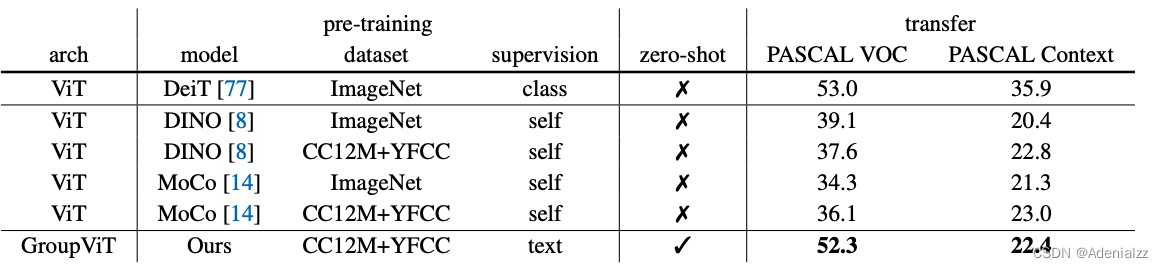
观察定量结果的表格(图 10)有以下结论:
- GroupViT 是第一个实现 zero-shot 语义分割的工作;
- GroupViT 相较于其他自监督语义分割方法提升显著
但是,PASCAL VOC 在有监督上的水准已经在 90+ 了,因此还是有很大的提升空间。
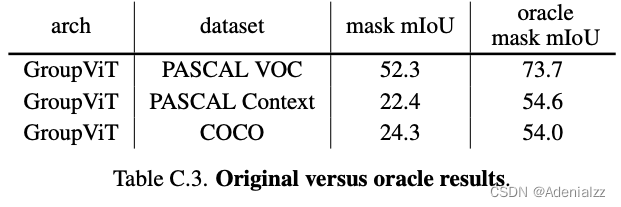
oracle对比
为了探究目前 GroupViT 的性能瓶颈到底在哪里,作者做了与 oracle 结果进行对比的实验。所谓 oracle mask mIoU,是指模型在完成分割之后,不用模型预测的类别结果,而是将每个 mask 与 GT mask 计算 IoU,直接取最大的类别标签作为类别结果。这相当于,模型只要分割的准就行了,语义类别的预测是肯定准的。结果如图 11 可以看到,oracle 结果相比于原结果有多达二三十个点的巨大提升,这说明,语义类别预测错误是 GroupViT 模型的一大瓶颈。这是由于对比学习的训练结果对于背景这种语义比较模糊类别很难识别。
目标检测
ViLD
简介
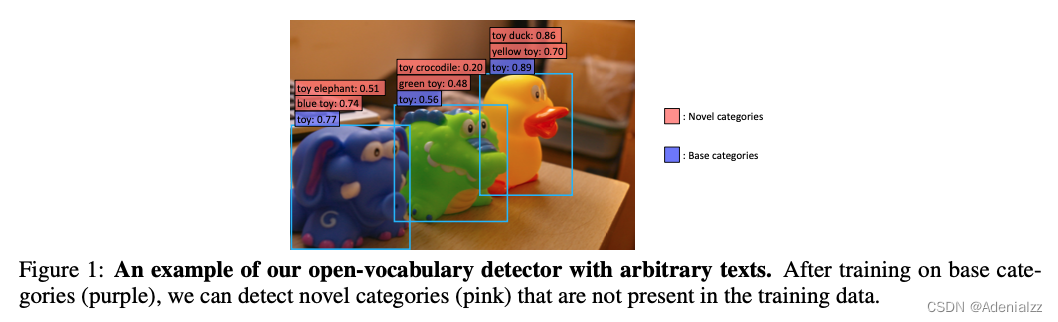
本文要做的开放词表目标检测的例子如图 12 所示。在图 12 中,紫色的是基础类(Base categories),粉色的是新类(Novel categories)。ViLD 想要做到的事情是:在训练时只需要训练基础类,然后通过知识蒸馏从 CLIP 模型中学习,从而在推理时能够检测新类。
模型结构与训练目标
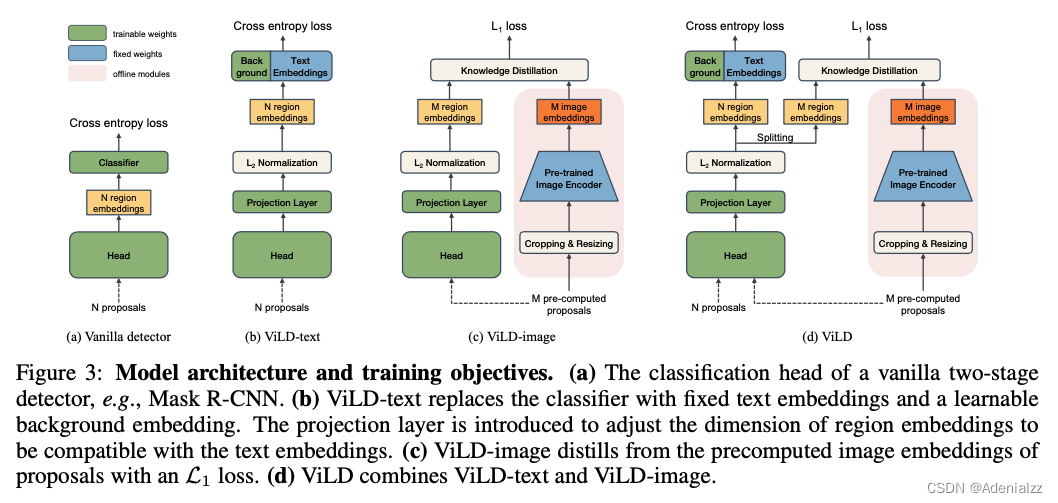
ViLD 的模型结构与训练目标如图 13 所示。ViLD 方法的研究重点在二阶段检测器的第二阶段,即得到提议框(proposal)之后的阶段。
-
(a) 是一个常规的二阶段检测器的分类头,直接计算交叉熵损失。
-
(b) 是 ViLD-text 模型,它将分类器替换为了固定的语义类别文本 embedding 和可学习的背景 embedding,再计算图像文本特征相似度,来计算交叉熵损失。文本 embedding 就是将根据数据集中基础类生成的 prompt 提取到的特征。需要添加一个单独的背景 embedding 的原因是,训练时只有基础类,而其他不在基础类的物体则需要全部归为背景类,用一个背景 embedding 表示,在训练时一起更新。Projection 层的引入是为了统一图像文本特征的尺寸。
在 ViLD-text 模型中,通过文本 embedding 将图像特征和文本特征联系到了一起,模型结构已经支持文本查询的 zero-shot 检测,但是由于模型还不了解基础类之外的其他语义内容,因此直接做 zero-shot 的效果不会很好。
-
© 是 ViLD-image,它将 CLIP 模型的图像编码器作为教师模型,使用知识蒸馏来让检测器学习 CLIP 提取的特征。为了加速模型训练,在训练 ViLD-image 时先用 CLIP 模型提取好图像区域特征,保存在硬盘中,在训练时直接从硬盘读取即可。
考虑到 CLIP 模型提取的图像特征与文本关联紧密,ViLD-image 模型通过知识蒸馏来学习预训练的图片编码器(CLIP)中的开放世界的图像特征提取能力。由于监督信号来自 CLIP,而非人工标注,因此 ViLD-image 不再受到特定类别的限制,而是对于任何的语义区域都可以由 CLIP 抽取图像特征,检测器来学习。因此模型的 open-vocabulary 能力得到增强。
-
(d) 是将 ViLD-text 和 ViLD-image 模型合并起来,得到完整 ViLD 模型,同时进行训练,训练目标已经在上面两点介绍过。
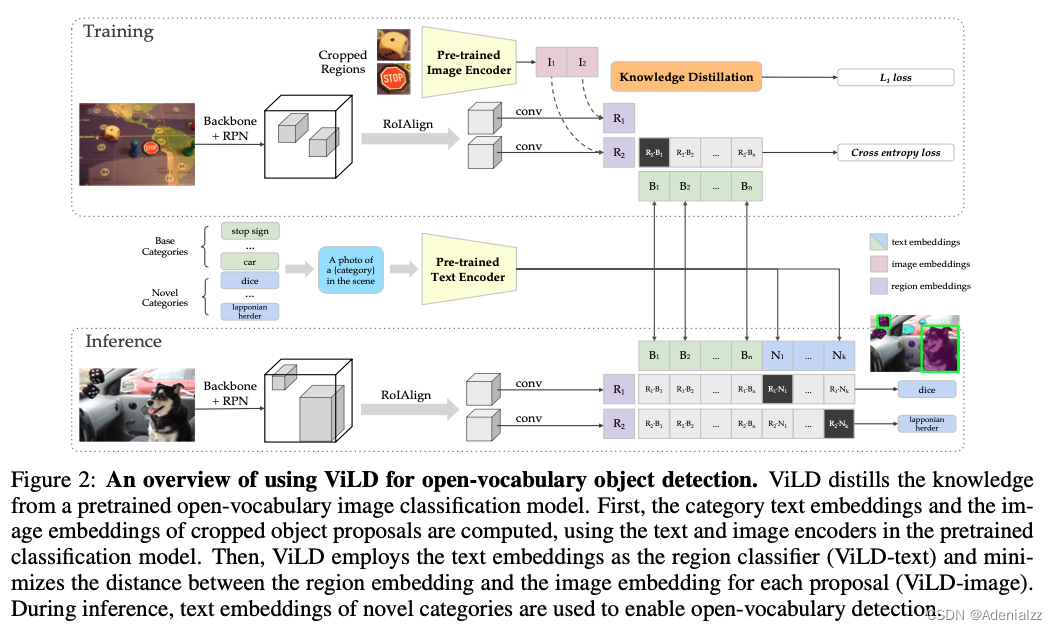
模型训练与推理完整框架
图 14 的上半部分是模型训练过程及目标函数,已经介绍过,不再赘述。图 14 的下半部分是 ViLD 进行 zero-shot 推理时的过程,将任意类别(基础类+新类)通过 prompt 生成文本并提取特征,与检测器提取的图像区域特征计算相似度,取最大值为该检测框的预测类别。
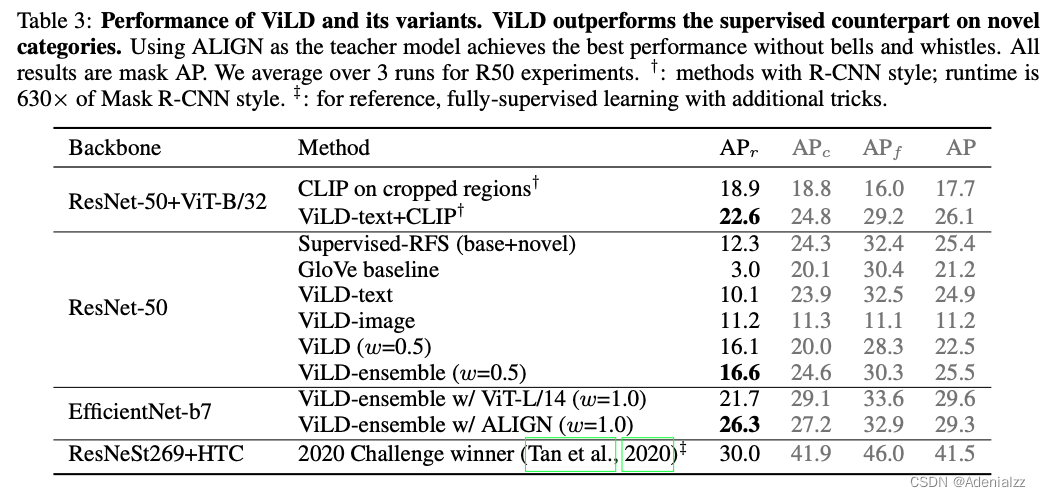
定量实验
ViLD 定量实验主要是在 LVis 数据集上进行,LVis 数据集是一个十分长尾的数据集,该数据集的图片就是 COCO 数据集中的图片,但是标注了多达 1203 类,所以在这么多类中,有大量的类别可能只有一两个标注。LVis 数据集将各个类别分为 fequent、common、rare,其中类内的数量递减。在本文的实验中,将 frequent 和 common 作为方法设定中的基础类(共 886 类),rare 作为新类(共 337 类)开展试验。结果如图 15 所示,可以看到 ViLD 模型在新类上的 AP 大幅领先基线模型。并且要注意,ViLD 在新类上的 AP 是 zero-shot 的方式测得的,基线模型则是有监督学习。zero-shot 的结果超越有监督训练的结果,仿佛难以置信。但实际上,这是可以理解的,原因就在于 LVis 数据集长尾的特点,这些 rare 的类可能只有一两个标注,即使使用了 RFS 采样策略来缓解长尾问题,也很难做好这些稀有类。在整个数据集所有类上进行有监督训练,这些稀有类甚至可能会越来越差。
GLIP
简介
定位任务与图像检测任务非常类似,都是去图中找目标物体的位置。GLIP 模型统一了目标检测(object detection)和定位(grounding)两个任务,构建了一个统一的训练框架,从而将两个任务的数据集都利用起来。再配合伪标签的技术来扩增数据,使得训练的数据量达到了前所未有的规模。在训练完成之后,直接以 zero-shot 的方式在 COCO 数据集上进行测试,达到了 49.8 AP。
GLIP 进行 zero-shot 测试的结果如图 16 所示,不管是给定几个类别(如 person、pistol、apple等)还是给定一段话(如 ‘there are some holes on the road’)作为文本编码器的输入,GLIP 模型都能从图像中找到对应物体的位置。

如何统一两个任务
detection 和 grouding 任务的目标函数都是由两部分损失组成,即分类损失和定位损失。定位损失不必多说,直接去计算与标注中的 GT 框的距离即可。而对于分类损失,则有所不同。
-
对于 detection 任务来说,分类的标签是一个类别单词,在计算分类损失时,每个区域框特征与分类头计算得到 logits,输出 logits 经过 nms 筛选之后,与 GT 计算交叉熵损失即可。
类似 ViLD 中的 (a) 常规目标检测器分类头
-
对于 grounding 任务来说,标签是一个句子,不是用分类头,而是通过文本编码器得到文本特征,计算文本特征与区域框特征的相似度,得到匹配分数。
类似 ViLD 中的 (b) ViLD-text
数据
既然统一了 detection 和 grounding 两个任务,最直接的一个利好就是两边的数据集都可以拿来训练这个统一的框架。即图 17 中所示的 O365 和 GoldG 两个数据集。这些数据集都是有标注的,规模还不够大。想要进一步获得更大量的数据,必须像 CLIP 那样借助无标注的图像文本对数据。但是,目标检测任务的训练必须要 GT 框,单独的图文对数据没法直接用。作者这里使用了 self-training 中伪标签的方式,使用 O365 和 GoldG 上训练好的 GLIP-T© 去在图文对数据 Cap4M/ Cap24M 上生成伪标签,直接当做 GT 框给 GLIP-T/L 进行训练。生成的伪标签肯定有错误,但是实验表明,经过扩充大量伪标签数据训练得到的 GLIP-L 模型仍然会有性能提高。

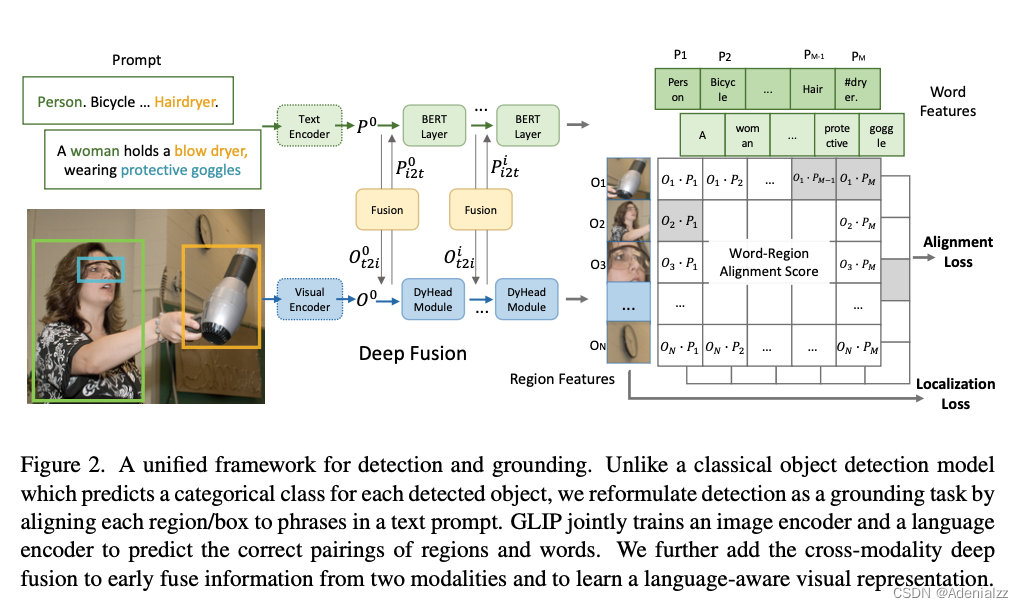
模型结构
GLIP 模型结构及训练目标如图 18 所示,模型是以有监督的方式进行训练,计算得到文本特征和图像特征的相似度之后,直接与 GT 计算对齐损失(alignment loss)即可,定位损失(Localization loss)也是直接与GT 框计算。
模型中间的融合层(fusion)是为了增加图像编码器和文本编码器之间的特征交互,使得最终的图像-文本联合特征空间训练得更好。
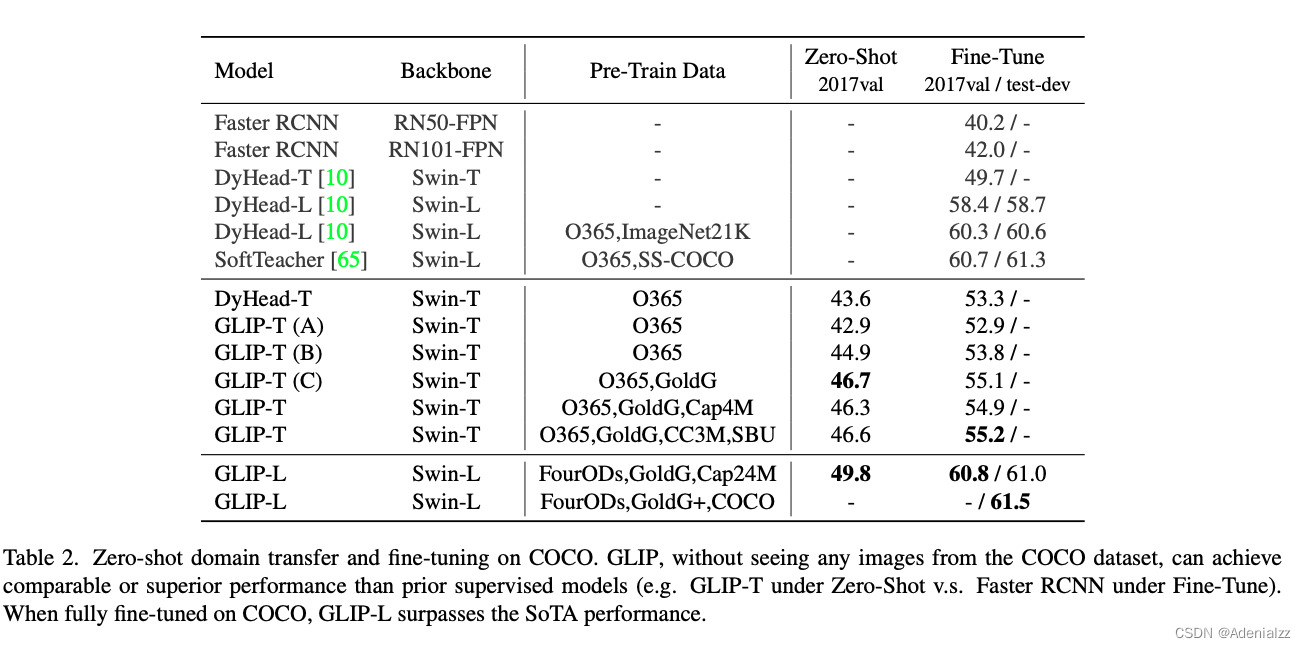
定量实验结果
GLIP 的定量实验结果如图 19 所示,GLIP 模型可以做 zero-shot 的目标检测,并且能够达到 49.8 AP。如果再在 COCO 上进行微调,GLIP 的 AP 能够超过当前最好的一些有监督方法。
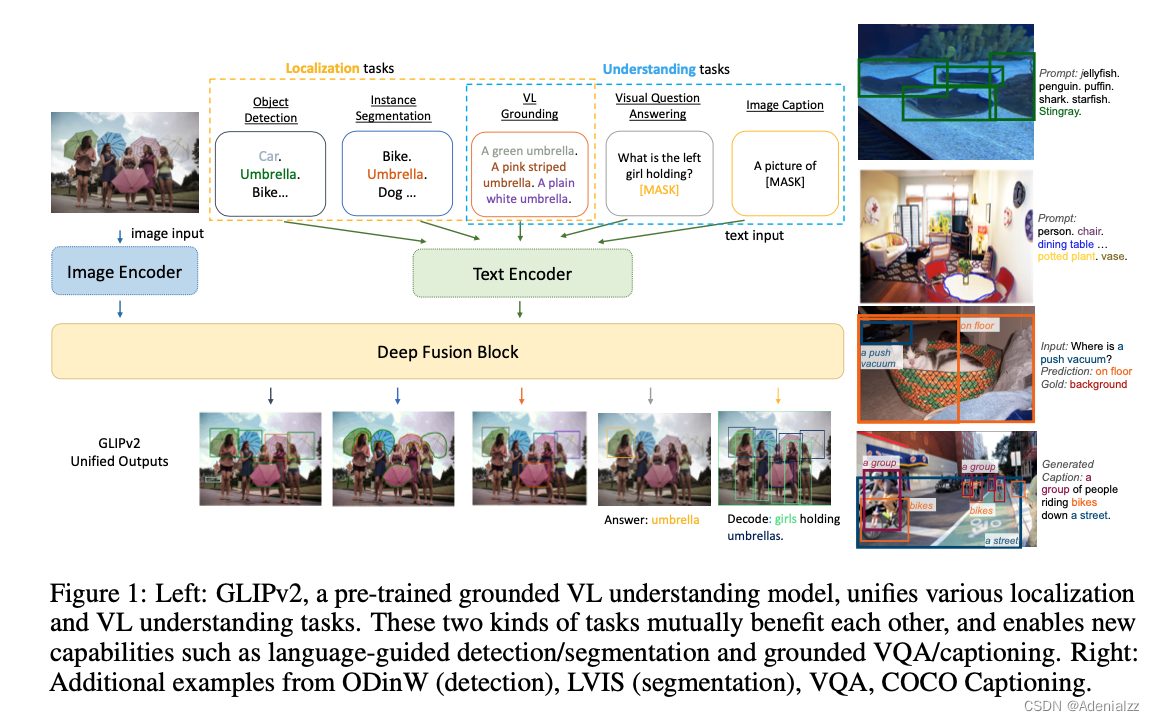
GLIPv2
GLIP 的进一步拓展工作 GLIPv2 融合了更多定位相关的任务(如检测、实例分割)和更多的多模态相关的任务(如问答、字幕生成)。