本文创新点:
点对特征是一种广泛应用的检测点云中三维物体的方法,但在存在传感器噪声和背景杂波的情况下,它们很容易失效。本文引入了新的采样和投票方案,可以很好地降低杂波和传感器噪声的影响。我们的实验表明,随着我们的改进,ppfs变得比最先进的方法更有竞争力,因为它在几个具有挑战性的基准上优于它们,成本很低。
相关工作:
1. 基于特征稀疏的方法:虽然几年前在彩色或强度图像中流行于三维物体检测,但这些方法现在不太流行,因为实际的机器人应用程序经常考虑由于缺乏纹理而不显示许多稳定特征点的物体。
2. 基于模板的方法:此方法对于模板捕获对象在不同视点下有着不同的外观。当模板与图像匹配时,会检测到一个对象,其三维姿态由模板给出,其中使用三维物体模型的合成渲染来生成覆盖全视半球的大量模板。它采用了一种基于边缘的距离度量,它很好地用于无纹理的对象,并使用ICP来实现精确的6d姿态。这种基于模板的方法在实践中可以准确和快速地工作。然而,它们显示出典型的问题,如对杂乱和遮挡的鲁棒性不是很好。
3. 基于局部补丁的方法:当前者对象坐标回归并进行随后的基于能量的姿态估计时,后者将用其投票基于尺度不变的贴片表示,并同时返回位置和姿态。其中还使用随机森林来推断物体和姿态,但通过滑动窗口来表示深度体积。
4. 基于点云的方法:点云数据中3D对象的检测有着非常悠久的历史。物体姿态估计的标准方法之一是ICP,但它需要一个初始估计,不适合于物体检测。基于三维特征的方法更合适,通常采用ICP进行姿态调整。这些方法包括点对、自旋图像和点对直方图,该方法通常在计算上是昂贵的,并且在具有严重杂波的场景中具有相当大的困难。然而,我们在本文中表明,这些缺点是可以避免的。
本文方法介绍:
1. 三维模型和输入场景的预处理
在预处理阶段,Drost-ppf对目标对象的三维点和输入场景进行了子样本,这加快了进一步的计算,并且避免了那些模棱两可的点对,彼此接近的点往往有相似的法线,并产生许多非歧视的ppfs。因此,Drost-ppf对点进行了子采样,使得两个三维点之间至少有一个选定的最小距离。然而,这可能导致失去有用的信息时,法线是交流-实际上是不同的。因此,我们保持点对,即使距离小于最小距离,如果法线之间的角度大于30度,因为这些点对很可能是歧视性的,然后像在Drost-ppf中那样进行次采样,但是有了这个额外的约束。
2. 点对的智能采样
在次采样后,在Drost-ppf中,每个场景点在运行时与每个其他场景点配对,因此,在三维场景中的点数中,复杂度是二次的。为了减少计算时间,建议只使用每5个场景点作为第一个点,虽然这改善了运行时间,但复杂性仍然是二次的,因为我们从已经采样的场景点云中删除了信息。因此我们提出了一种更好的方法来加快计算,而不丢弃场景点,给定一个来自场景的点,它应该只与其他可以属于同一对象的场景点配对。例如,如果两个点之间的距离大于对象的大小,我们知道这两个点不可能属于同一个对象,因此不应该配对。实验表明,这导致了一种可以更有效地实现的方法。这样做的一个保守方法是忽略离点对的第一点比dobj更远的任何点,其中dobj是目标物体的包围球的直径,它是一个投票球。然而,对于一些对象来说,球面区域可能有一个非常糟糕的近似,特别是对于窄长的物体,半径为dobj的球体中采样将在背景杂波上产生许多点,如果在平行于其最长尺寸的观察方向上观察到该物体,如下图所示,在这些情况下,我们希望使用一个较小的采样体积,其中与所有其他场景点相比,位于物体上的场景点的比率更大。这样我们就没有任何关于物体姿态的先验信息,并且点对的第一个场景点可以位于物体上的任何地方。在一定的对象配置下,如果不丢弃一对场景点,那么就不可能去一个比半径dobj球小的单一体积,而这些场景点都位于目标对象上。
因此,我们选择连续使用两个具有不同辐射的投票球:一个半径为的小投票球,其中dmin是对象包围盒的最小维数,dmed是其三维的中值,而最大的是半径为Rmax=dobj的投票球。可以很容易地看出,Rmin是对象的最小可观测扩展。我们将说,如果第一个点位于球的中心,并且它到第二点的距离小于球的半径,则点对被投票球接受。我们首先用小球接受的点对选票来填充累加器,从累加器中提取峰值,每个峰值对应于对象的三维姿态和模型与场景点之间的对应关系的假设,如Drost-ppf。然后,我们继续填充累加器与选票从点对接受的大球,但被拒绝的小球。我们像以前一样,提取峰值来产生姿态和点对应假设。这样,在姿态下,如下图所示,我们可以得到在第一个通道中受背景杂波污染较小的峰值,在第二通道中仍能得到其他构型的峰值。
3. 投票时传感器噪声的核算
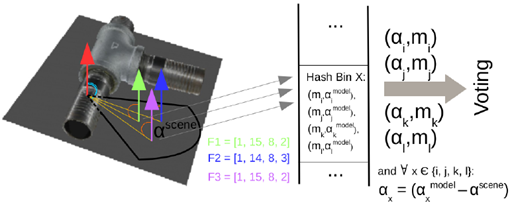
为了快速访问,对ppfs进行了离散化,然而,传感器噪声可以改变离散化,防止一些ppfs被正确匹配。我们通过在模型的预处理过程中传播查找哈希表的内容来克服这个问题。而不是只将第一个模型点和旋转角存储在离散PPF向量索引的bin中,我们还将它们存储在由相邻离散PPF索引的(80)邻域中,在运行时,我们面临一个类似的问题,在投票的量化旋转角度围绕点法线。为了克服这一问题,我们使用了与上述相同的策略,不仅对原始的量化旋转角进行投票,而且对其相邻域也进行投票。然而,如下图所示,扩展也有一个缺点,由于特征旋转空间的离散化和扩展,由近景点组成的点对很可能具有相同的量化旋转角度,并映射到相同的查找表中,因此,他们将在累加器空间中投票给同一个bin,从而在投票中引入偏见。为了避免多票,我们可以选择一种直接方法是对每个场景点使用3D二进制数组,如果分别以第i个模型点、第j个模型点为第一个点和第2点进行投票,并且已经在法线周围施加了第k个量化的旋转角,并防止对此组合进行额外的投票。
4. 生成对象位姿和后处理
为了从累加器中提取对象姿态,Drost-ppf使用了一种贪婪的聚类方法,它们从累加器中提取峰值,每个峰值对应于对象3D姿态上的假设以及模型和场景点之间的对应关系,并以与其票数相同的顺序处理它们,如果它们足够接近,则将它们分配给最近的集群,或者以其他方式创建另一个集群。我们发现,这种方法并不总是可靠的,特别是在噪声传感器和背景杂波的情况下。这些结果导致虚假投票,而累加器空间中的票数不一定是假设质量的可靠指标。因此,我们提出了一种考虑到我们投票策略的不同集群策略。我们对在投票过程中产生的姿态假设进行自下而上的聚类,我们允许假设加入几个集群,只要它们的姿态与集群中心的姿态相似。我们还跟踪与每个假设相关的模型点,并且只允许假设投票给一个集群,如果以前没有其他具有相同模型点的假设投票给这个集群。因此,我们避免了模糊和重复的几何结构,如平面表面引入偏差。对于具有最大权重的少数簇中的每一个,我们使用投影ICP来估计姿态。在实践中,我们考虑了两个投票球中每一个的四个的第一组。
为了拒绝不实际对应于对象的簇,我们根据相应的3D姿态对对象进行渲染,并计算有多少像素有一个接近渲染的深度,有多少像素离摄像机更远|并且可能被遮挡,有多少像素更接近,因此与渲染不一致。如果与像素总数相比,更接近的像素数太大,则拒绝集群。在实践中,这个阈值设置为10%。我们还丢弃了太多被遮挡的物体。作为最后一次检查,我们计算场景中有符号深度或正常变化的区域,并将它们与投影对象的轮廓进行比较:如果轮廓被深度或正常变化覆盖得不够,我们就放弃匹配。在实践中,我们使用与遮挡检查相同的阈值。我们根据它们对场景点的处理程度对所有剩余的集群进行排序,并只返回最佳集群的姿态,或者在多实例检测的情况下,从所有剩余集群中返回整个姿态列表。
5. 实验结果
我们将我们的方法与Drost-ppf、Linemod、DTTS、Birdal、Bachmann、Krull等人的方法进行了比较。对于我们的方法,我们对所有的实验和对象使用相同的参数,除了处理后的阈值来解释遮挡数据集。
(1)识别率对不同方法的评价度量。我们对13个对象中的8个执行得最好,而其他的除了深度外,还使用颜色数据,我们只使用深度数据。
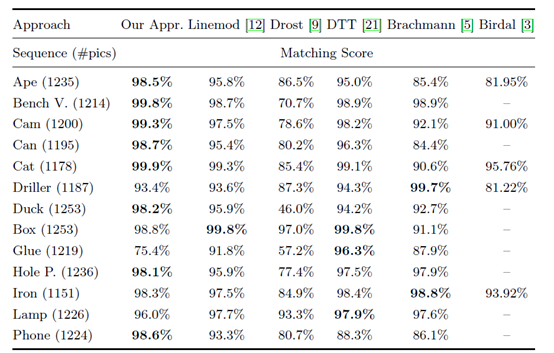
(2)我们的方法对八个中的五个对象表现得更好,平均而言,我们的表现比Krull好3.3%,而Krull在训练过程中除了深度和地面外,还使用颜色数据。我们只使用深度数据。
参考文献
[1] Drost, B., Ulrich, M.,Navab, N., Ilic, S.: Model Globally, Match Locally: Efficient and Robust 3DObject Recognition. In: Conference on Computer Vision and Pattern Recognition(2010)
[2]Wohlhart, P., Lepetit, V.: Learning Descriptors for Object Recognition and 3D PoseEstimation. In: Conference on Computer Vision and Pattern Recognition(2015)
本文仅做学术分享,如有侵权,请联系删文。











