一、FlinkTableAPI与FlinkSQL背景介绍
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是我们熟知的 Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。
Flink SQL 是面向用户的 API 层,在我们传统的流式计算领域,比如 Storm、Spark Streaming 都会提供一些 Function 或者 Datastream API,用户通过 Java 或 Scala 写业务逻辑,这种方式虽然灵活,但有一些不足,比如具备一定门槛且调优较难,随着版本的不断更新,API 也出现了很多不兼容的地方。
Flink本身是批流统一的处理框架,所以Table API和SQL,就是批流统一的上层处理API。
Table API是一套内嵌在Java和Scala语言中的查询API,它允许我们以非常直观的方式,组合来自一些关系运算符的查询(比如select、filter和join)。而对于Flink SQL,就是直接可以在代码中写SQL,来实现一些查询(Query)操作。Flink的SQL支持,基于实现了SQL标准的Apache Calcite(Apache开源SQL解析工具)。
无论输入是批输入还是流式输入,在这两套API中,指定的查询都具有相同的语义,得到相同的结果。
二、在Oracle VM VirtualBox下搭建开发环境
https://www.apache.org/dyn/closer.lua/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.12.tgz
root@zwg:/home/zwg/flink-1.14.4/bin# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host zwg.
Starting taskexecutor daemon on host zwg.

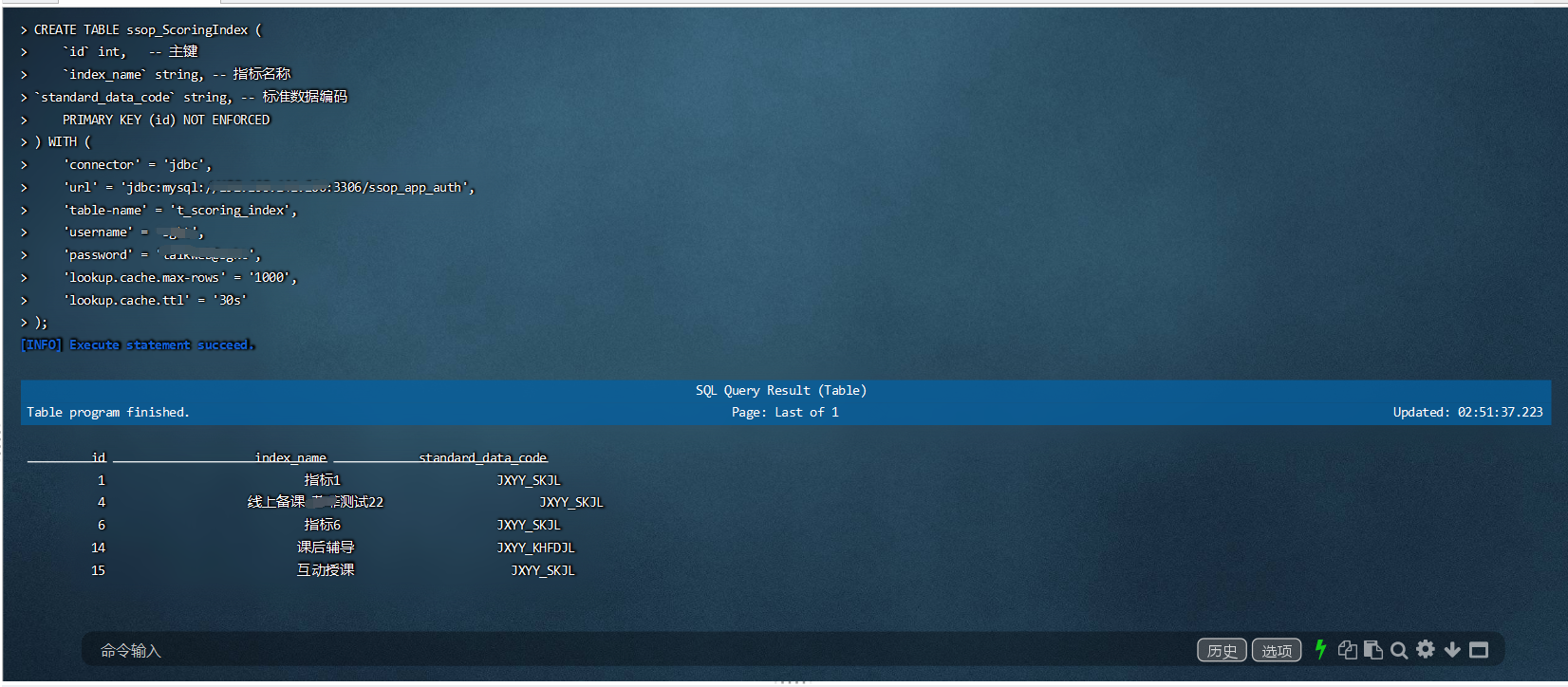
三、IDEA、maven搭建Flink Table API的开发环境
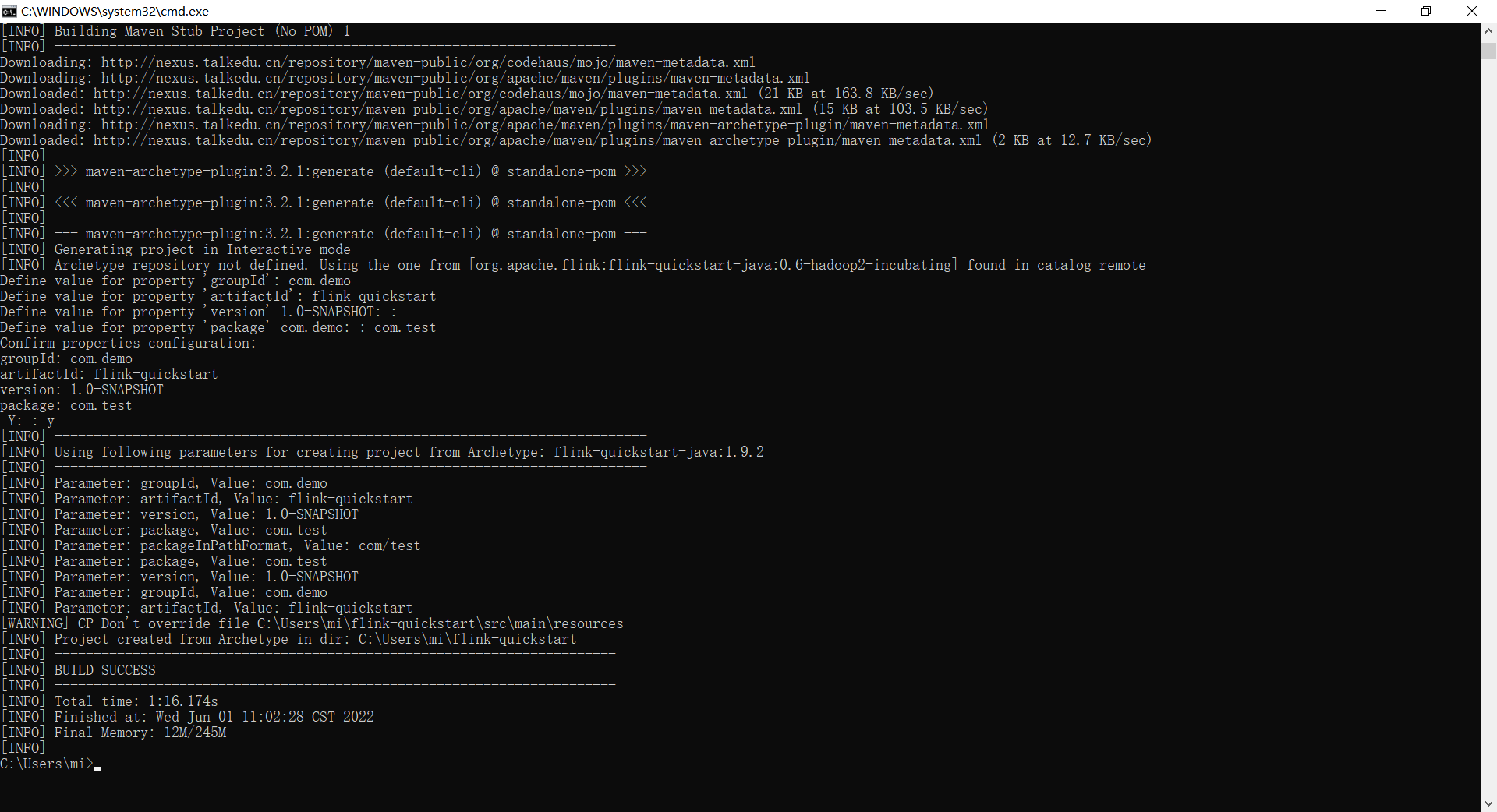
两种方式:1、命令行方式:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.9.2
2、在IDEA中直接建maven工程:
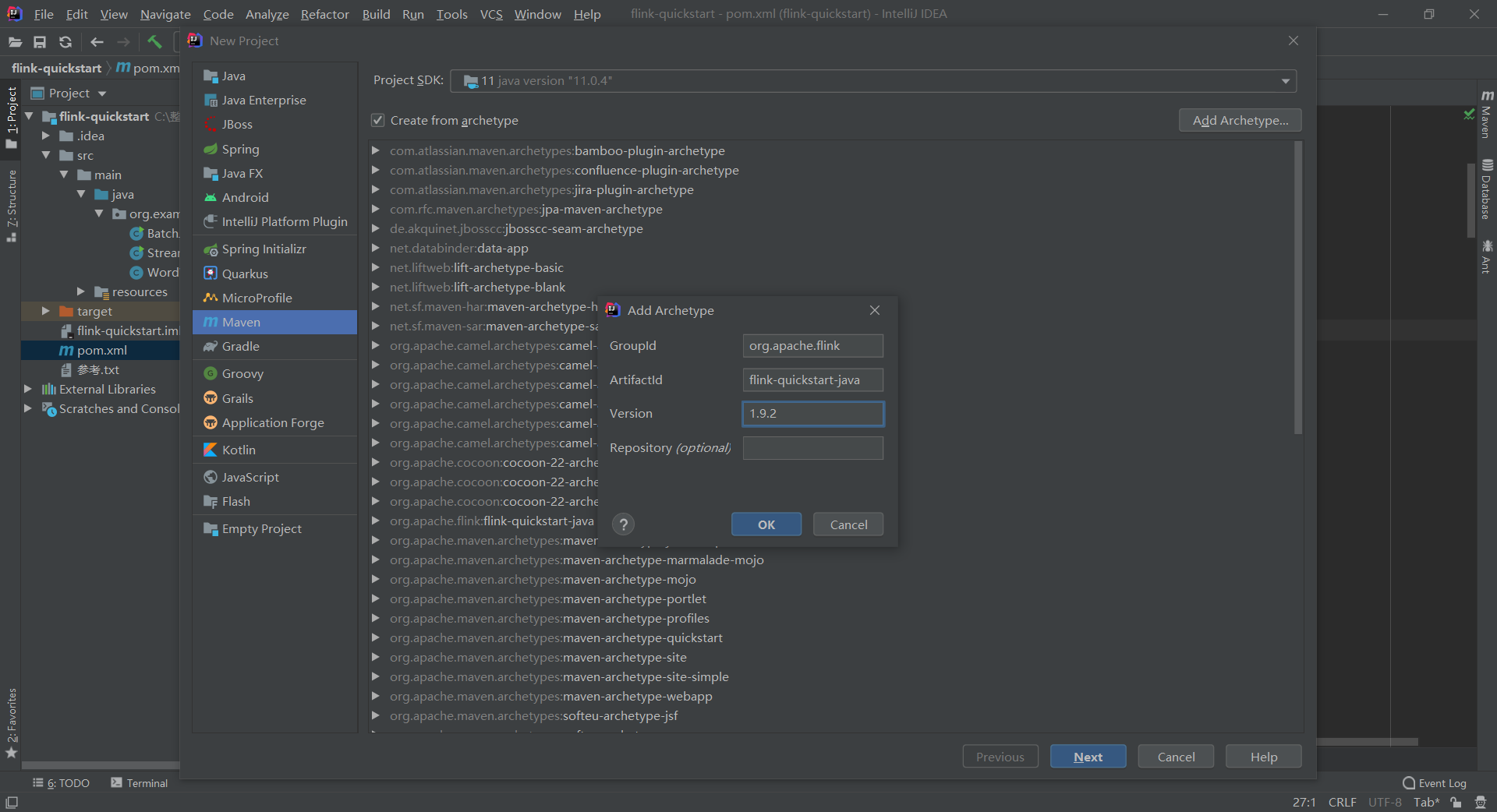
然后一步步往下走,直到结束。
一个简单的统计示例:
StreamingJob.java
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.example;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class StreamingJob {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", 18081, "\n");
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
String[] splits = value.split("\\s");
for (String word:splits) {
out.collect(new WordWithCount(word,1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count");
windowCount.print().setParallelism(1);
env.execute("Flink Streaming Java API Skeleton");
}
public static class WordWithCount{
public String word;
public long count;
public WordWithCount(){}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
WordWithCount.java
package org.example;
public class WordWithCount {
public String word;
public long count;
public WordWithCount(){}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
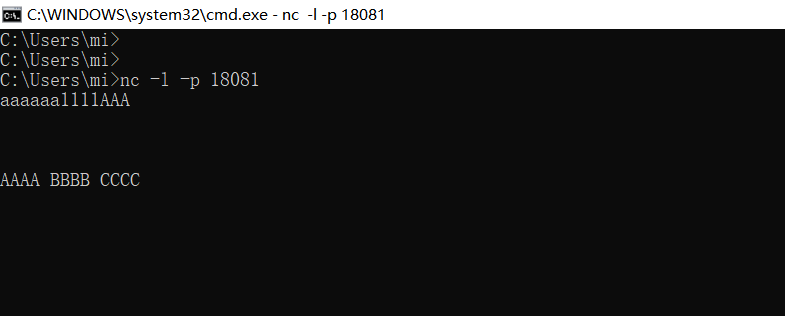
zai 在本机监听 18081端口:
nc -l -p 18081
运行 StreamingJob 类,并在命令行输入一些字符:
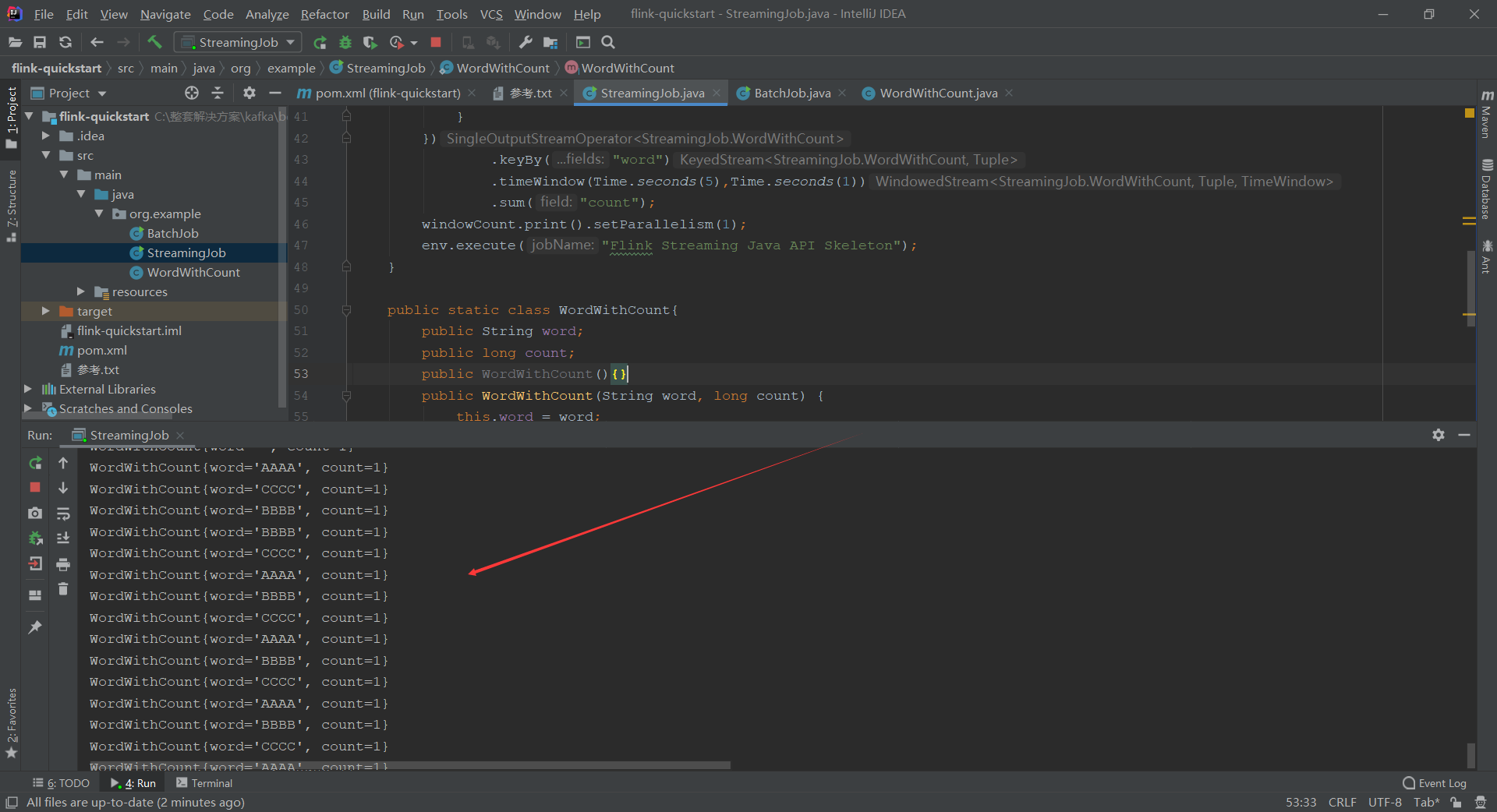
统计程序响应:
四、小结与梳理










