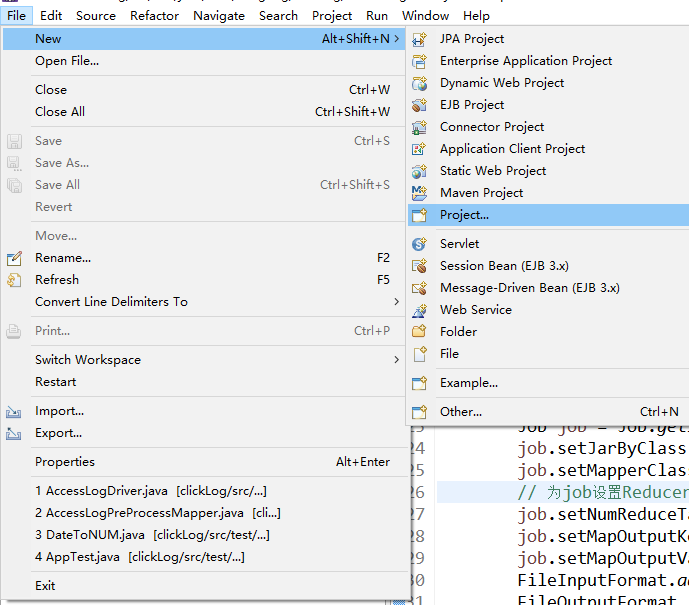
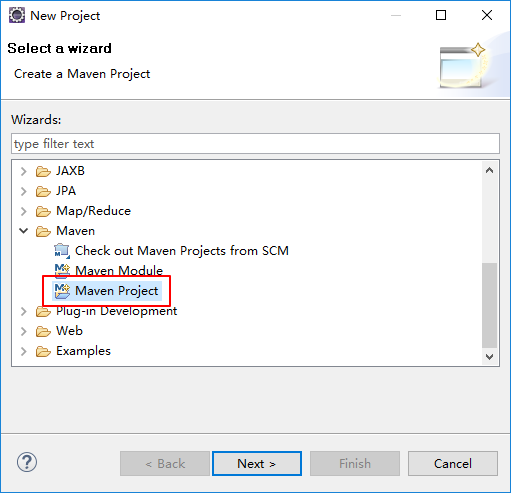
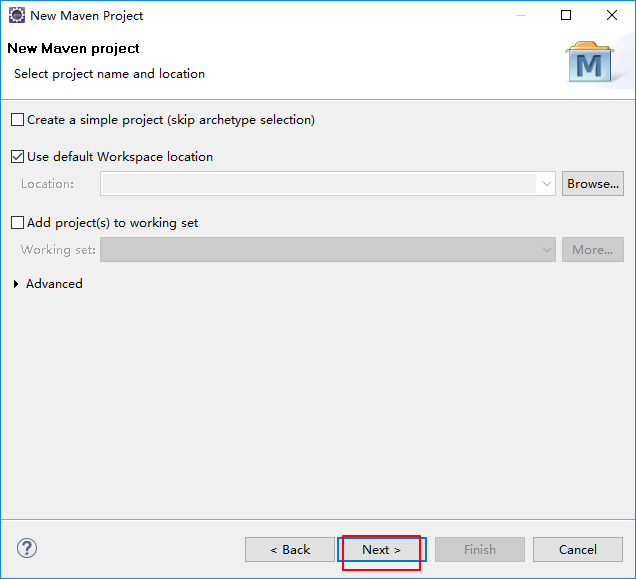
打开eclipse创建maven项目


pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.it19gong</groupId>
<artifactId>sparkproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>sparkproject</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-rdbms</artifactId>
<version>4.1.7</version>
</dependency>
<dependency>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-api-jdo</artifactId>
<version>3.2.6</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/main/test</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>true</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.it19gong.sparkproject.App</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
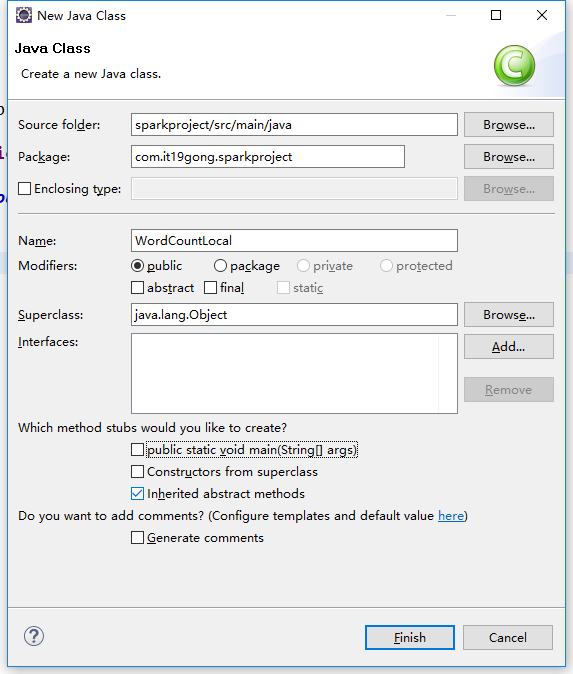
创建一个WordCountLocal.java文件
package com.it19gong.sparkproject;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCountLocal {
public static void main(String[] args) {
//1.设置本地开发
SparkConf conf = new SparkConf().setAppName("WordCountLocal").setMaster("local");
//2.创建spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
//3.读取文件
JavaRDD<String> lines = sc.textFile("E://Mycode//dianshixiangmu//sparkproject//data//spark.txt");
//4.开始进行计算
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
}
}
运行一下
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
19/11/10 14:12:18 INFO SparkContext: Running Spark version 1.5.1
19/11/10 14:12:18 INFO SecurityManager: Changing view acls to: Brave
19/11/10 14:12:18 INFO SecurityManager: Changing modify acls to: Brave
19/11/10 14:12:18 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Brave); users with modify permissions: Set(Brave)
19/11/10 14:12:19 INFO Slf4jLogger: Slf4jLogger started
19/11/10 14:12:19 INFO Remoting: Starting remoting
19/11/10 14:12:19 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@10.0.75.1:55718]
19/11/10 14:12:19 INFO Utils: Successfully started service 'sparkDriver' on port 55718.
19/11/10 14:12:19 INFO SparkEnv: Registering MapOutputTracker
19/11/10 14:12:19 INFO SparkEnv: Registering BlockManagerMaster
19/11/10 14:12:19 INFO DiskBlockManager: Created local directory at C:\Users\Brave\AppData\Local\Temp\blockmgr-58932928-9dcc-40bd-86b9-9056cb077e9e
19/11/10 14:12:19 INFO MemoryStore: MemoryStore started with capacity 2.9 GB
19/11/10 14:12:19 INFO HttpFileServer: HTTP File server directory is C:\Users\Brave\AppData\Local\Temp\spark-7e77199e-97b8-4ad1-850d-45a4b9dbb981\httpd-2e225558-a380-410a-83ab-6d4353461237
19/11/10 14:12:19 INFO HttpServer: Starting HTTP Server
19/11/10 14:12:19 INFO Utils: Successfully started service 'HTTP file server' on port 55719.
19/11/10 14:12:19 INFO SparkEnv: Registering OutputCommitCoordinator
19/11/10 14:12:19 INFO Utils: Successfully started service 'SparkUI' on port 4040.
19/11/10 14:12:19 INFO SparkUI: Started SparkUI at http://10.0.75.1:4040
19/11/10 14:12:19 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
19/11/10 14:12:19 INFO Executor: Starting executor ID driver on host localhost
19/11/10 14:12:19 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 55756.
19/11/10 14:12:19 INFO NettyBlockTransferService: Server created on 55756
19/11/10 14:12:19 INFO BlockManagerMaster: Trying to register BlockManager
19/11/10 14:12:19 INFO BlockManagerMasterEndpoint: Registering block manager localhost:55756 with 2.9 GB RAM, BlockManagerId(driver, localhost, 55756)
19/11/10 14:12:19 INFO BlockManagerMaster: Registered BlockManager
19/11/10 14:12:20 INFO MemoryStore: ensureFreeSpace(120136) called with curMem=0, maxMem=3086525399
19/11/10 14:12:20 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 117.3 KB, free 2.9 GB)
19/11/10 14:12:20 INFO MemoryStore: ensureFreeSpace(12681) called with curMem=120136, maxMem=3086525399
19/11/10 14:12:20 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 12.4 KB, free 2.9 GB)
19/11/10 14:12:20 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:55756 (size: 12.4 KB, free: 2.9 GB)
19/11/10 14:12:20 INFO SparkContext: Created broadcast 0 from textFile at WordCountLocal.java:25
19/11/10 14:12:22 WARN : Your hostname, DESKTOP-76BE8V4 resolves to a loopback/non-reachable address: fe80:0:0:0:597b:a8f9:8691:f5d2%eth10, but we couldn't find any external IP address!
19/11/10 14:12:23 INFO FileInputFormat: Total input paths to process : 1
19/11/10 14:12:23 INFO SparkContext: Starting job: foreach at WordCountLocal.java:62
19/11/10 14:12:23 INFO DAGScheduler: Registering RDD 3 (mapToPair at WordCountLocal.java:38)
19/11/10 14:12:23 INFO DAGScheduler: Got job 0 (foreach at WordCountLocal.java:62) with 1 output partitions
19/11/10 14:12:23 INFO DAGScheduler: Final stage: ResultStage 1(foreach at WordCountLocal.java:62)
19/11/10 14:12:23 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
19/11/10 14:12:23 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
19/11/10 14:12:23 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at WordCountLocal.java:38), which has no missing parents
19/11/10 14:12:23 INFO MemoryStore: ensureFreeSpace(4832) called with curMem=132817, maxMem=3086525399
19/11/10 14:12:23 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.7 KB, free 2.9 GB)
19/11/10 14:12:23 INFO MemoryStore: ensureFreeSpace(2688) called with curMem=137649, maxMem=3086525399
19/11/10 14:12:23 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.6 KB, free 2.9 GB)
19/11/10 14:12:23 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:55756 (size: 2.6 KB, free: 2.9 GB)
19/11/10 14:12:23 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:861
19/11/10 14:12:23 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at WordCountLocal.java:38)
19/11/10 14:12:23 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
19/11/10 14:12:23 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 2156 bytes)
19/11/10 14:12:23 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
19/11/10 14:12:23 INFO HadoopRDD: Input split: file:/E:/Mycode/dianshixiangmu/sparkproject/data/spark.txt:0+159
19/11/10 14:12:23 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
19/11/10 14:12:23 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
19/11/10 14:12:23 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
19/11/10 14:12:23 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
19/11/10 14:12:23 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
19/11/10 14:12:23 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver
19/11/10 14:12:23 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 83 ms on localhost (1/1)
19/11/10 14:12:23 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/11/10 14:12:23 INFO DAGScheduler: ShuffleMapStage 0 (mapToPair at WordCountLocal.java:38) finished in 0.094 s
19/11/10 14:12:23 INFO DAGScheduler: looking for newly runnable stages
19/11/10 14:12:23 INFO DAGScheduler: running: Set()
19/11/10 14:12:23 INFO DAGScheduler: waiting: Set(ResultStage 1)
19/11/10 14:12:23 INFO DAGScheduler: failed: Set()
19/11/10 14:12:23 INFO DAGScheduler: Missing parents for ResultStage 1: List()
19/11/10 14:12:23 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCountLocal.java:49), which is now runnable
19/11/10 14:12:23 INFO MemoryStore: ensureFreeSpace(2496) called with curMem=140337, maxMem=3086525399
19/11/10 14:12:23 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.4 KB, free 2.9 GB)
19/11/10 14:12:23 INFO MemoryStore: ensureFreeSpace(1509) called with curMem=142833, maxMem=3086525399
19/11/10 14:12:23 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1509.0 B, free 2.9 GB)
19/11/10 14:12:23 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:55756 (size: 1509.0 B, free: 2.9 GB)
19/11/10 14:12:23 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:861
19/11/10 14:12:23 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCountLocal.java:49)
19/11/10 14:12:23 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
19/11/10 14:12:23 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1901 bytes)
19/11/10 14:12:23 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
19/11/10 14:12:23 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/11/10 14:12:23 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 3 ms
jkjf appeared 1 times.
spark appeared 4 times.
hive appeared 3 times.
klsdjflk appeared 1 times.
hadoop appeared 3 times.
flume appeared 2 times.
appeared 6 times.
dshfjdslfjk appeared 1 times.
sdfjjk appeared 1 times.
djfk appeared 1 times.
hava appeared 1 times.
java appeared 3 times.
sdjfk appeared 1 times.
sdfjs appeared 1 times.
19/11/10 14:12:23 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
19/11/10 14:12:23 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 24 ms on localhost (1/1)
19/11/10 14:12:23 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/11/10 14:12:23 INFO DAGScheduler: ResultStage 1 (foreach at WordCountLocal.java:62) finished in 0.024 s
19/11/10 14:12:23 INFO DAGScheduler: Job 0 finished: foreach at WordCountLocal.java:62, took 0.189574 s
19/11/10 14:12:23 INFO SparkUI: Stopped Spark web UI at http://10.0.75.1:4040
19/11/10 14:12:23 INFO DAGScheduler: Stopping DAGScheduler
19/11/10 14:12:23 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
19/11/10 14:12:23 INFO MemoryStore: MemoryStore cleared
19/11/10 14:12:23 INFO BlockManager: BlockManager stopped
19/11/10 14:12:23 INFO BlockManagerMaster: BlockManagerMaster stopped
19/11/10 14:12:23 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
19/11/10 14:12:23 INFO SparkContext: Successfully stopped SparkContext
19/11/10 14:12:23 INFO ShutdownHookManager: Shutdown hook called
19/11/10 14:12:23 INFO ShutdownHookManager: Deleting directory C:\Users\Brave\AppData\Local\Temp\spark-7e77199e-97b8-4ad1-850d-45a4b9dbb981
集群执行wordcount程序
创建一个WordCountCluster.java文件
// 如果要在spark集群上运行,需要修改的,只有两个地方
// 第一,将SparkConf的setMaster()方法给删掉,默认它自己会去连接
// 第二,我们针对的不是本地文件了,修改为hadoop hdfs上的真正的存储大数据的文件
SparkConf conf = new SparkConf().setAppName("WordCountCluster");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://node1:9000/spark.txt");
package com.it19gong.sparkproject;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCountCluster {
public static void main(String[] args) {
//1.设置本地开发
SparkConf conf = new SparkConf().setAppName("WordCountCluster");
//2.创建spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
//3.读取文件
JavaRDD<String> lines = sc.textFile("hdfs://node1/spark.txt");
//4.开始进行计算
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
}
}
对工程进行打包
把spark.txt文件上传到集群

同时把文件上传到hdfs上

把刚刚打好的架包上传到集群
修改一下包的名字

现在我们编写一个脚本
Wordcount.sh
/opt/modules/spark-1.5.1-bin-hadoop2.6/bin/spark-submit --class com.it19gong.sparkproject.WordCountCluster --num-executors 3--driver-memory 100m --executor-memory 100m --executor-cores 3/home/hadoop/sparkproject.jar

启动spark
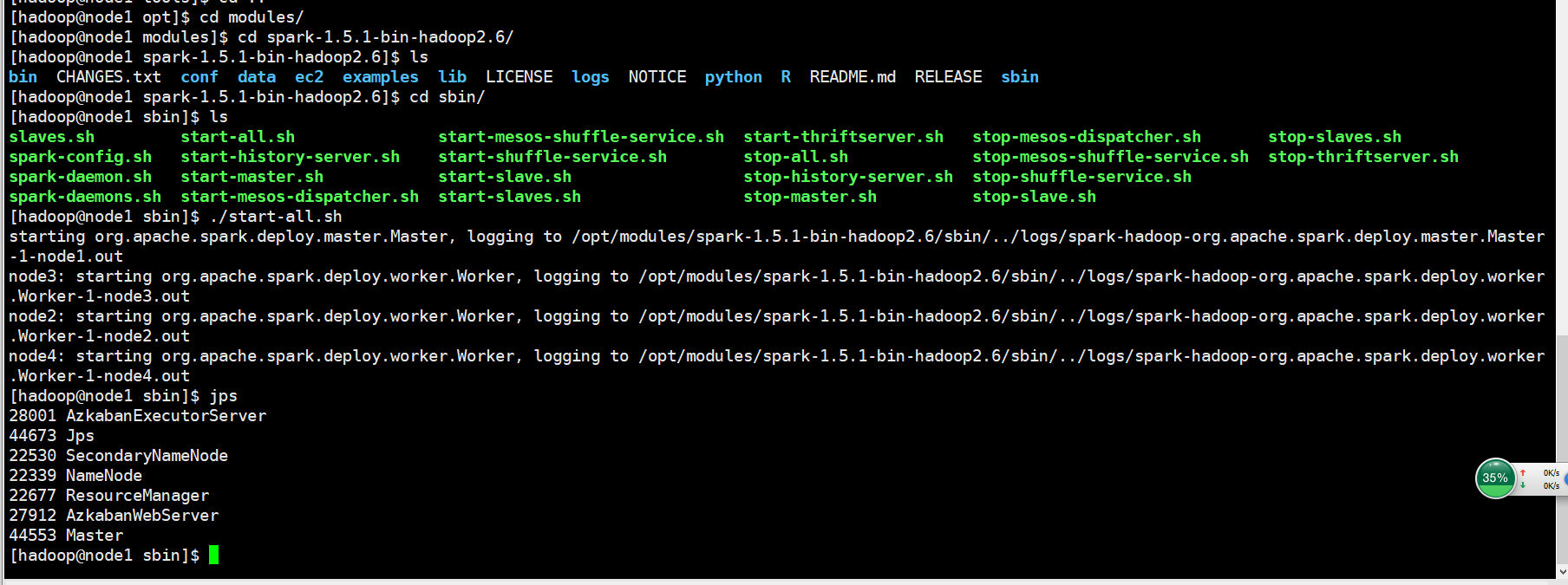
执行脚本
[hadoop@node1 ~]$ ./Wordcount.sh
19/11/10 15:33:40 INFO spark.SparkContext: Running Spark version 1.5.1
19/11/10 15:33:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/11/10 15:33:41 INFO spark.SecurityManager: Changing view acls to: hadoop
19/11/10 15:33:41 INFO spark.SecurityManager: Changing modify acls to: hadoop
19/11/10 15:33:41 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
19/11/10 15:33:42 INFO slf4j.Slf4jLogger: Slf4jLogger started
19/11/10 15:33:42 INFO Remoting: Starting remoting
19/11/10 15:33:42 INFO util.Utils: Successfully started service 'sparkDriver' on port 42358.
19/11/10 15:33:42 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.86.131:42358]
19/11/10 15:33:42 INFO spark.SparkEnv: Registering MapOutputTracker
19/11/10 15:33:42 INFO spark.SparkEnv: Registering BlockManagerMaster
19/11/10 15:33:42 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-2e4d079e-a368-4779-93e6-de99c948e0d2
19/11/10 15:33:42 INFO storage.MemoryStore: MemoryStore started with capacity 52.2 MB
19/11/10 15:33:42 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-b3327381-3897-4200-913a-0b09e354f0e1/httpd-1cd444b4-38c9-4cec-9e16-66d0d2c1117c
19/11/10 15:33:42 INFO spark.HttpServer: Starting HTTP Server
19/11/10 15:33:43 INFO server.Server: jetty-8.y.z-SNAPSHOT
19/11/10 15:33:43 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:40646
19/11/10 15:33:43 INFO util.Utils: Successfully started service 'HTTP file server' on port 40646.
19/11/10 15:33:43 INFO spark.SparkEnv: Registering OutputCommitCoordinator
19/11/10 15:33:43 INFO server.Server: jetty-8.y.z-SNAPSHOT
19/11/10 15:33:43 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
19/11/10 15:33:43 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
19/11/10 15:33:43 INFO ui.SparkUI: Started SparkUI at http://192.168.86.131:4040
19/11/10 15:33:44 INFO spark.SparkContext: Added JAR file:/home/hadoop/sparkproject.jar at http://192.168.86.131:40646/jars/sparkproject.jar with timestamp 1573371224734
19/11/10 15:33:45 WARN metrics.MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
19/11/10 15:33:45 INFO executor.Executor: Starting executor ID driver on host localhost
19/11/10 15:33:46 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 35773.
19/11/10 15:33:46 INFO netty.NettyBlockTransferService: Server created on 35773
19/11/10 15:33:46 INFO storage.BlockManagerMaster: Trying to register BlockManager
19/11/10 15:33:46 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:35773 with 52.2 MB RAM, BlockManagerId(driver, localhost, 35773)
19/11/10 15:33:46 INFO storage.BlockManagerMaster: Registered BlockManager
19/11/10 15:33:47 INFO storage.MemoryStore: ensureFreeSpace(130448) called with curMem=0, maxMem=54747463
19/11/10 15:33:47 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 127.4 KB, free 52.1 MB)
19/11/10 15:33:47 INFO storage.MemoryStore: ensureFreeSpace(14403) called with curMem=130448, maxMem=54747463
19/11/10 15:33:47 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 14.1 KB, free 52.1 MB)
19/11/10 15:33:47 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:35773 (size: 14.1 KB, free: 52.2 MB)
19/11/10 15:33:47 INFO spark.SparkContext: Created broadcast 0 from textFile at WordCountCluster.java:25
19/11/10 15:33:48 INFO mapred.FileInputFormat: Total input paths to process : 1
19/11/10 15:33:48 INFO spark.SparkContext: Starting job: foreach at WordCountCluster.java:62
19/11/10 15:33:48 INFO scheduler.DAGScheduler: Registering RDD 3 (mapToPair at WordCountCluster.java:38)
19/11/10 15:33:48 INFO scheduler.DAGScheduler: Got job 0 (foreach at WordCountCluster.java:62) with 1 output partitions
19/11/10 15:33:48 INFO scheduler.DAGScheduler: Final stage: ResultStage 1(foreach at WordCountCluster.java:62)
19/11/10 15:33:48 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
19/11/10 15:33:48 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0)
19/11/10 15:33:49 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at WordCountCluster.java:38), which has no missing parents
19/11/10 15:33:49 INFO storage.MemoryStore: ensureFreeSpace(4800) called with curMem=144851, maxMem=54747463
19/11/10 15:33:49 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.7 KB, free 52.1 MB)
19/11/10 15:33:49 INFO storage.MemoryStore: ensureFreeSpace(2665) called with curMem=149651, maxMem=54747463
19/11/10 15:33:49 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.6 KB, free 52.1 MB)
19/11/10 15:33:49 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:35773 (size: 2.6 KB, free: 52.2 MB)
19/11/10 15:33:49 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:861
19/11/10 15:33:49 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at WordCountCluster.java:38)
19/11/10 15:33:49 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
19/11/10 15:33:49 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 2179 bytes)
19/11/10 15:33:49 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
19/11/10 15:33:49 INFO executor.Executor: Fetching http://192.168.86.131:40646/jars/sparkproject.jar with timestamp 1573371224734
19/11/10 15:33:49 INFO util.Utils: Fetching http://192.168.86.131:40646/jars/sparkproject.jar to /tmp/spark-b3327381-3897-4200-913a-0b09e354f0e1/userFiles-5ed25560-5fd3-43ce-8f5f-d5017b6e5c4e/fetchFileTemp5320647246797663342.tmp
19/11/10 15:33:51 INFO executor.Executor: Adding file:/tmp/spark-b3327381-3897-4200-913a-0b09e354f0e1/userFiles-5ed25560-5fd3-43ce-8f5f-d5017b6e5c4e/sparkproject.jar to class loader
19/11/10 15:33:51 INFO rdd.HadoopRDD: Input split: hdfs://node1/spark.txt:0+159
19/11/10 15:33:51 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
19/11/10 15:33:51 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
19/11/10 15:33:51 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
19/11/10 15:33:51 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
19/11/10 15:33:51 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
19/11/10 15:33:52 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver
19/11/10 15:33:52 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (mapToPair at WordCountCluster.java:38) finished in 3.353 s
19/11/10 15:33:52 INFO scheduler.DAGScheduler: looking for newly runnable stages
19/11/10 15:33:52 INFO scheduler.DAGScheduler: running: Set()
19/11/10 15:33:52 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 1)
19/11/10 15:33:52 INFO scheduler.DAGScheduler: failed: Set()
19/11/10 15:33:52 INFO scheduler.DAGScheduler: Missing parents for ResultStage 1: List()
19/11/10 15:33:52 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 3337 ms on localhost (1/1)
19/11/10 15:33:52 INFO scheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCountCluster.java:49), which is now runnable
19/11/10 15:33:52 INFO storage.MemoryStore: ensureFreeSpace(2496) called with curMem=152316, maxMem=54747463
19/11/10 15:33:52 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.4 KB, free 52.1 MB)
19/11/10 15:33:52 INFO storage.MemoryStore: ensureFreeSpace(1511) called with curMem=154812, maxMem=54747463
19/11/10 15:33:52 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1511.0 B, free 52.1 MB)
19/11/10 15:33:52 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:35773 (size: 1511.0 B, free: 52.2 MB)
19/11/10 15:33:52 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:861
19/11/10 15:33:52 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCountCluster.java:49)
19/11/10 15:33:52 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
19/11/10 15:33:52 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/11/10 15:33:52 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1960 bytes)
19/11/10 15:33:52 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 1)
19/11/10 15:33:52 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/11/10 15:33:52 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 8 ms
jkjf appeared 1 times.
spark appeared 4 times.
hive appeared 3 times.
klsdjflk appeared 1 times.
hadoop appeared 3 times.
flume appeared 2 times.
appeared 6 times.
dshfjdslfjk appeared 1 times.
sdfjjk appeared 1 times.
djfk appeared 1 times.
hava appeared 1 times.
java appeared 3 times.
sdjfk appeared 1 times.
sdfjs appeared 1 times.
19/11/10 15:33:52 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
19/11/10 15:33:52 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 340 ms on localhost (1/1)
19/11/10 15:33:52 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/11/10 15:33:52 INFO scheduler.DAGScheduler: ResultStage 1 (foreach at WordCountCluster.java:62) finished in 0.340 s
19/11/10 15:33:52 INFO scheduler.DAGScheduler: Job 0 finished: foreach at WordCountCluster.java:62, took 4.028079 s
19/11/10 15:33:52 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
19/11/10 15:33:53 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
19/11/10 15:33:53 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.86.131:4040
19/11/10 15:33:53 INFO scheduler.DAGScheduler: Stopping DAGScheduler
19/11/10 15:33:53 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
19/11/10 15:33:53 INFO storage.MemoryStore: MemoryStore cleared
19/11/10 15:33:53 INFO storage.BlockManager: BlockManager stopped
19/11/10 15:33:53 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
19/11/10 15:33:53 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
19/11/10 15:33:53 INFO spark.SparkContext: Successfully stopped SparkContext
19/11/10 15:33:53 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
19/11/10 15:33:53 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
19/11/10 15:33:53 INFO util.ShutdownHookManager: Shutdown hook called
19/11/10 15:33:53 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-b3327381-3897-4200-913a-0b09e354f0e1
[hadoop@node1 ~]$ ls
创建RDD(集合,本地文件,HDFS文件)
进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD。该RDD中,通常就代表和包含了Spark应用程序的输入源数据。
然后在创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行转换,来获取其他的RDD。
Spark Core提供了三种创建RDD的方式,包括:使用程序中的集合创建RDD;使用本地文件创建RDD;使用HDFS文件创建RDD。
个人经验认为:
1、使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程。
2、使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件。
3、使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作。
并行化集合创建RDD
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用SparkContext的parallelize()方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,
也就是一个RDD。相当于是,集合中的部分数据会到一个节点上,而另一部分数据会到其他节点上。然后就可以用并行的方式来操作这个分布式数据集合,即RDD。










