1、背景与需求:
随着业务规模的不断增大,系统的复杂度也越来越高,我们的软件架构也进入了分布式的阶段,服务按照不同的维度进行拆分,那么一次请求可能横跨多个服务模块、项目,依赖的中间件也越来越多,其中任何一个节点出现异常,都可能导致业务出现波动或者异常。而传统的日志监控等方式无法很好满足调用链路跟踪,排查问题等需求,这就导致定位/诊断服务异常变得异常复杂。
因此面对复杂的调用链路,我们需要一款全链路追踪工具,帮助我们实现如下功能,提高我们对业务的掌控度:
(1)功能性需求:
- ① 请求链路追踪,快速定位故障,缩短故障的排除时间 以及 判断故障影响范围
- ② 可视化链路各阶段的耗时,进行性能分析,排除业务瓶颈
- ③ 梳理服务依赖关系以及优化依赖的合理性
- ④ 系统指标监控,吞吐量(TPS)、响应时间及错误记录等。
(2)非功能性需求:
- 探针的性能消耗:服务调用埋点本身会带来性能损耗,这就需要组件对业务系统的性能影响小
- 代码的侵入性:对业务系统尽可能少入侵或者无入侵其他,对于使用方透明,减少开发人员的负担。
2、Skywalking 简介:
skywalking 是一个优秀的国产开源APM组件,是一个对 Java 分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。2015年由个人吴晟开源 , 2017年加入Apache孵化器。短短两年就被Apache收入麾下,实力可见一斑。
skywalking 支持 SpringBoot、SpringCloud、dubbo 集成,代码无侵入,通信方式采用 GRPC,性能较好,实现方式是 Java 探针,支持告警,支持JVM监控,支持全局调用统计等等,功能较完善。
3、Skywalking 使用说明:
3.1、仪表盘:
仪表盘是Skywalking的首页,它提供多个指示板来可视化指标,例如:服务(APM)、数据库(Database)等等。

3.1.1、APM(服务):
APM面板总体分为四个维度:Global(全局)、Service(服务)、Instance(实例)、Endpoint(API),提供筛选功能,每块都包含一些指标。
(1)Global(全局)指标:
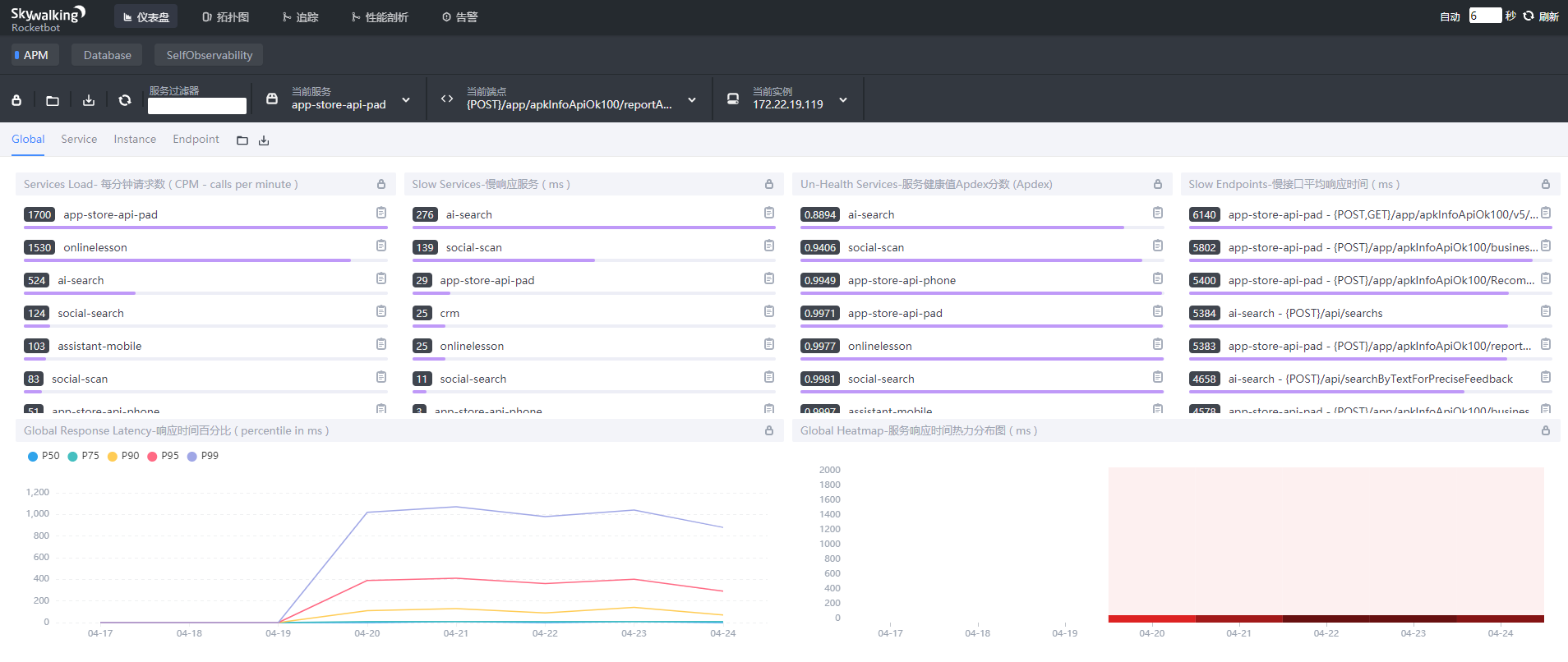
- Services Load:服务每分钟请求数
- Slow Services:慢响应服务,按响应时间排序topN,单位ms
- Un-Health Services (Apdex):Apdex性能指标,即服务的不健康值,1为满分,Apdex是根据设定的阈值和响应时间综合考虑的衡量标准,是满意响应时间和不满意响应时间相对于总响应时间的比率,衡量的是用户对服务的满意程度,因为传统的指标(如平均响应时间)可能很快就会容易形成偏差。
- Slow Endpoints:慢接口平均响应耗时排序,单位ms
- Global Response Latency:响应时间百分比,不同百分比的延时时间,单位ms。percentile 标签含义,例如 p99 为 3500ms,意味着 99% 的请求应该比 3500ms 更快
- Global Heatmap:服务响应时间热力分布图,根据时间段内不同响应时间的数量显示颜色深度, 颜色越深,请求越多。
(2)Service(服务)维度:
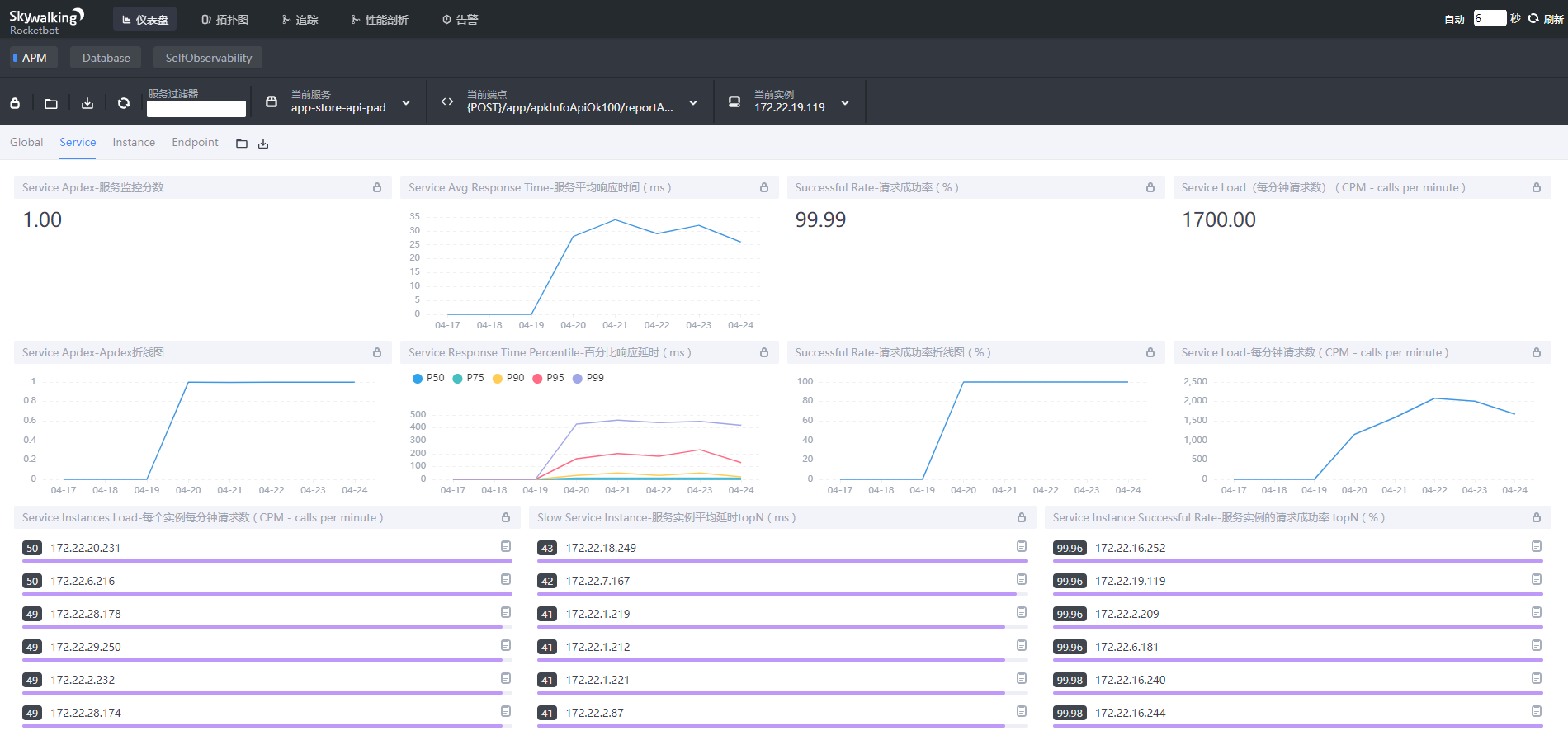
- Service Apdex 数字:Apdex性能指标
- Service Apdex 折线图:一段时间的Apdex分数
- Service Avg Response Time:服务平均响应时间
- Service Response Time Percentile:百分比响应延时
- Successful Rate(%)数字:请求成功率
- Successful Rate(%)折线图:一段时间的请求成功率
- Service Load(CPM - calls per minute):每分钟调用数
- Service Load(CPM - calls per minute):一段时间的每分钟调用数
- Service Instances Load(CPM - calls per minute):每个实例每分钟请求数
- Slow Service Instance:每个服务实例平均延时topN
- Service Instance Successful Rate:服务实例的请求成功率 topN
(3)Instance(实例)维度:

- Service Instance Load:实例每分钟调用数
- Service Instance Successful Rate:实例调用成功比率
- Service Instance Latency:实例响应延时
- JVM CPU(Java Service):JVM 占用 CPU 百分比
- JVM Memory (Java Service):JVM内存占用大小,包含四个指标 instance_jvm_memory_heap(堆内存使用)、instance_jvm_memory_heap_max(最大堆内存)、instance_jvm_memory_noheap(直接内存当前使用)、instance_jvm_memory_noheap_max(最大直接内存)
- JVM GC Time:JVM垃圾回收时间,包含 young gc 和 old gc
- JVM GC Count:JVM垃圾回收次数,包含 young gc count 和 old gc count
(4)Endpoint(API)维度:
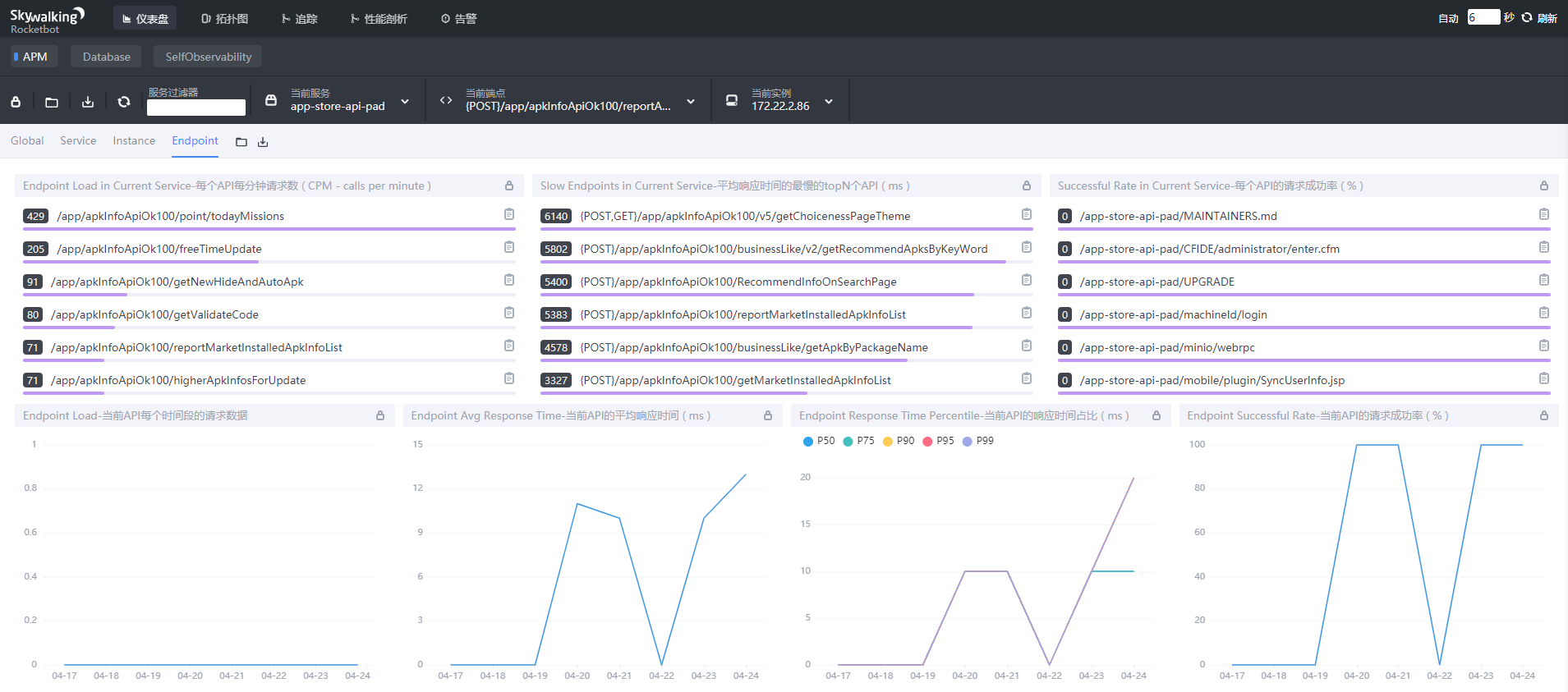
- Endpoint Load in Current Service:每个API每分钟请求数
- Slow Endpoints in Current Service:平均响应时间的最慢的topN个API
- Successful Rate in Current Service:每个API的请求成功率
- Endpoint Load:当前API每个时间段的请求数据
- Endpoint Avg Response Time:当前API每个时间段的平均响应时间
- Endpoint Response Time Percentile:当前API每个时间段的响应时间占
- Endpoint Successful Rate:当前API每个时间段的请求成功率
3.1.2、Database(数据库):

- Database Avg Response Time:当前数据库平均响应时间
- Database Access Successful Rate:当前数据库访问成功率
- Database Traffic:当前数据库每分钟请求数
- Database Access Latency Percentile:数据库不同响应时间占比
- Slow Statements:当前数据库慢查询TopN
- All Database Loads:所有数据库中请求量排序
- Un-Health Databases:所有数据库不健康排名,请求成功率排名,失败最多的请求在最上。
3.2、拓扑图:
拓扑图可以很直观地展示服务与服务之间的依赖关系,这对于我们进行服务梳理是非常有帮助的,并且支持自定义分组,如下图所示,就将 ai-search、social-search、social-scan 三个服务自定义一个分组,并通过拓扑图很直观地展示出三者间的依赖关系:
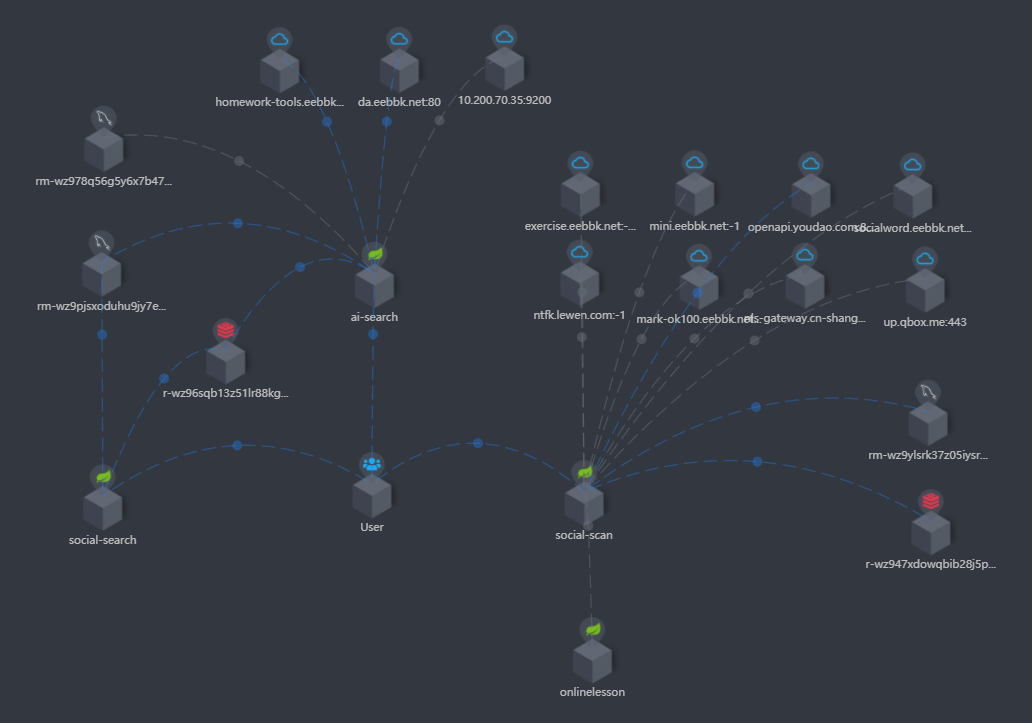
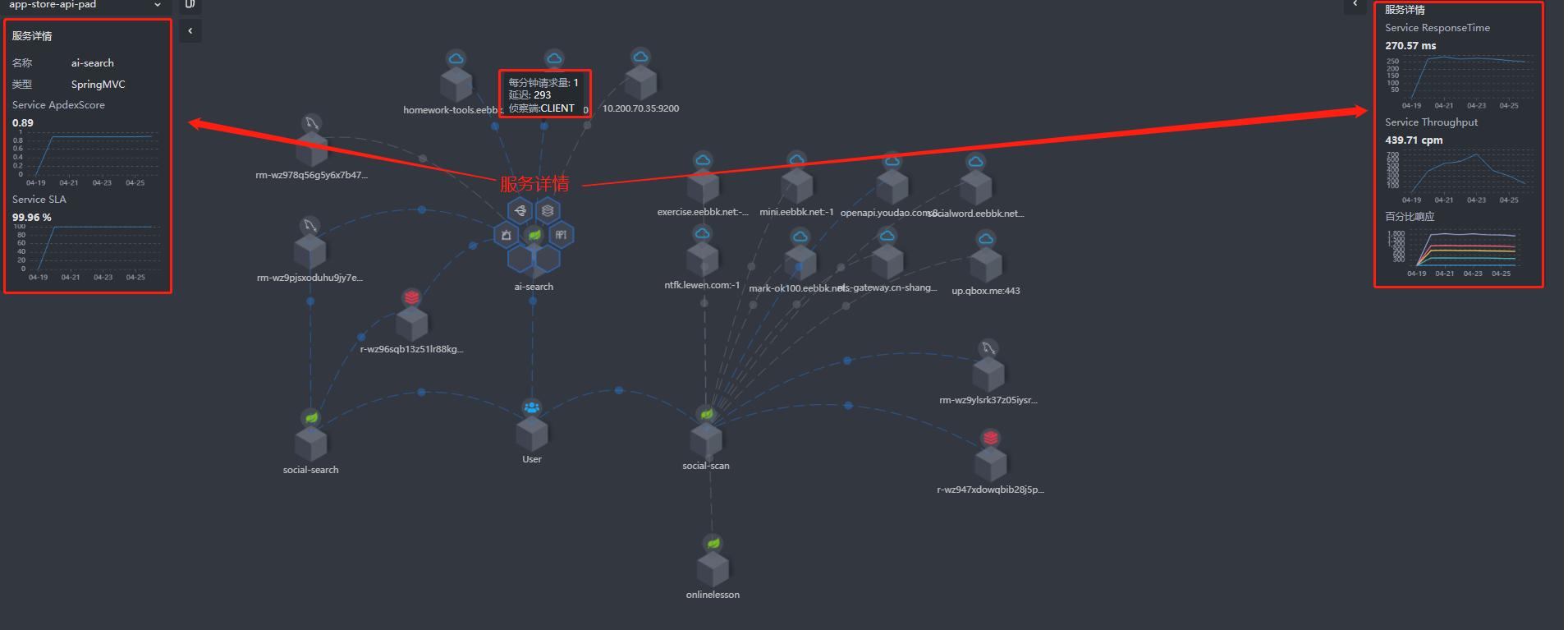
除此之外,拓扑图还能查看服务运行信息进行度量,包括开发框架类型、服务平均响应时间、吞吐量、百分比响应、Apdex分值、SLA值等
3.3、链路追踪:
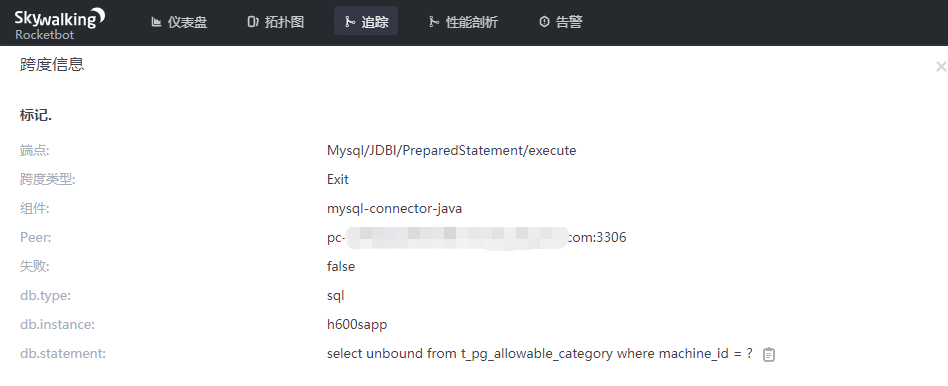
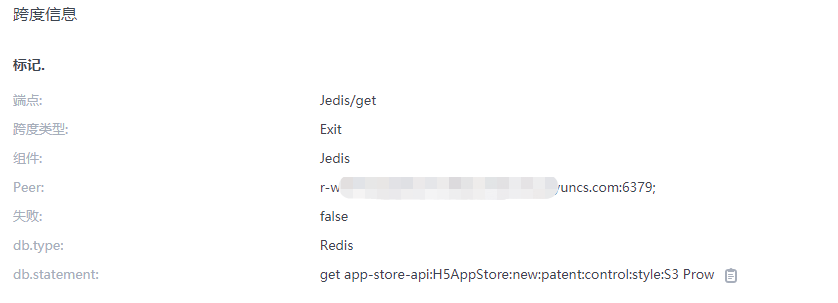
链路追踪可以查看每个接口的调用链,每个链路耗时、状态,如果为失败,还会展示错误信息,如果是数据库也会展示查询语句,如果是Redis还会展示操作指令,另外可以根据追踪id(trace id)进行筛选查询:

查看数据库操作详情:
查看Redis缓存操作详情:
3.4、性能剖析:
Skywalking 在性能剖析方面非常强大,提供到基于堆栈的分析结果,能够让开发人员一看看出调用过程中各个步骤所消耗的时间,以便进行有针对性的进行优化。
性能剖析通过新建任务,对不同端点进行采样,提供更详细的报告,比如比链路追踪多了线程栈的信息、慢方法提示等等内容。接下来我们就介绍下怎么进行性能剖析:
(1)新建任务:
在 性能剖析模块 -> 新建任务 -> 选择服务、填写端点、监控时间,操作如下图:

(2)执行请求:
多次访问 "/api/searchByWholeOcr" 接口,然后选择这个任务将会出现监控到的数据,如下图:
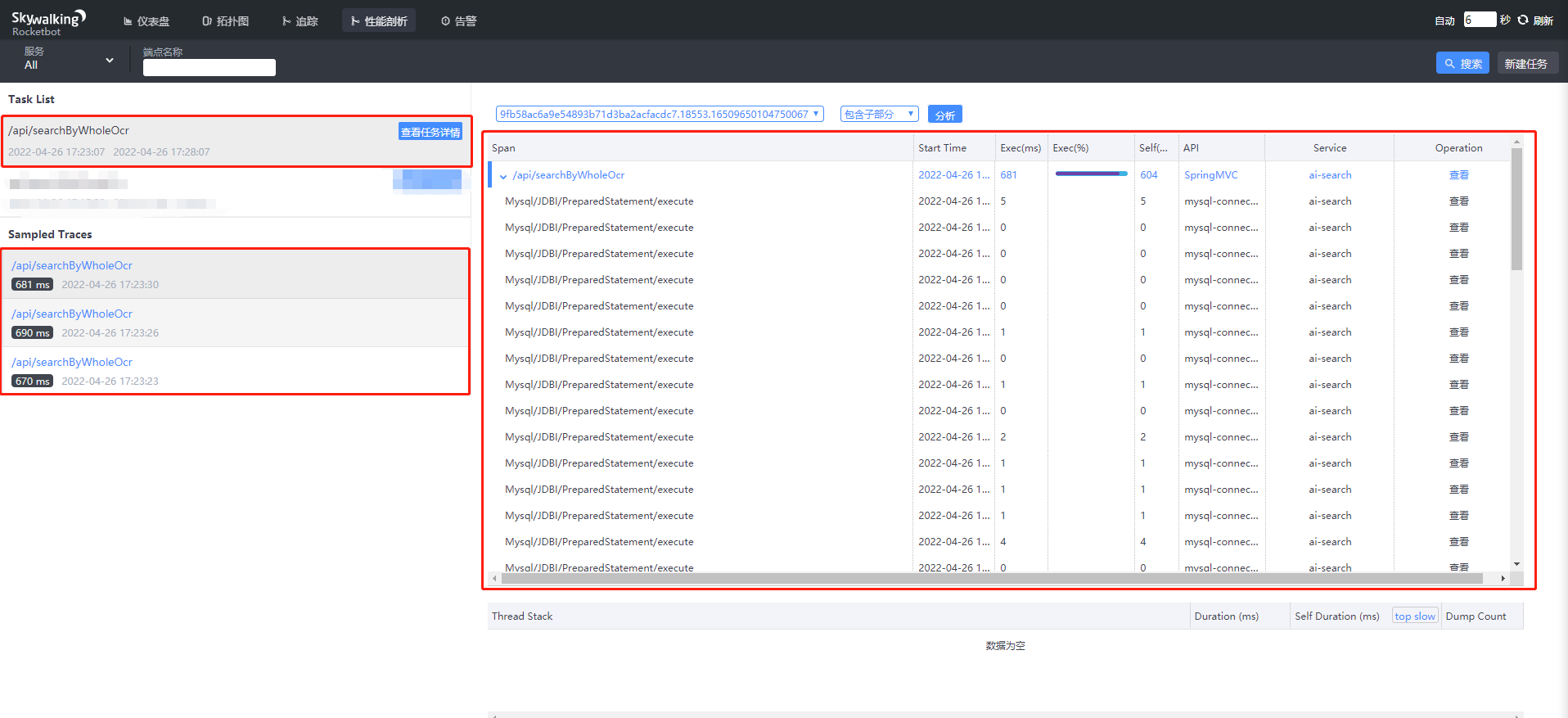
(3)性能剖析:
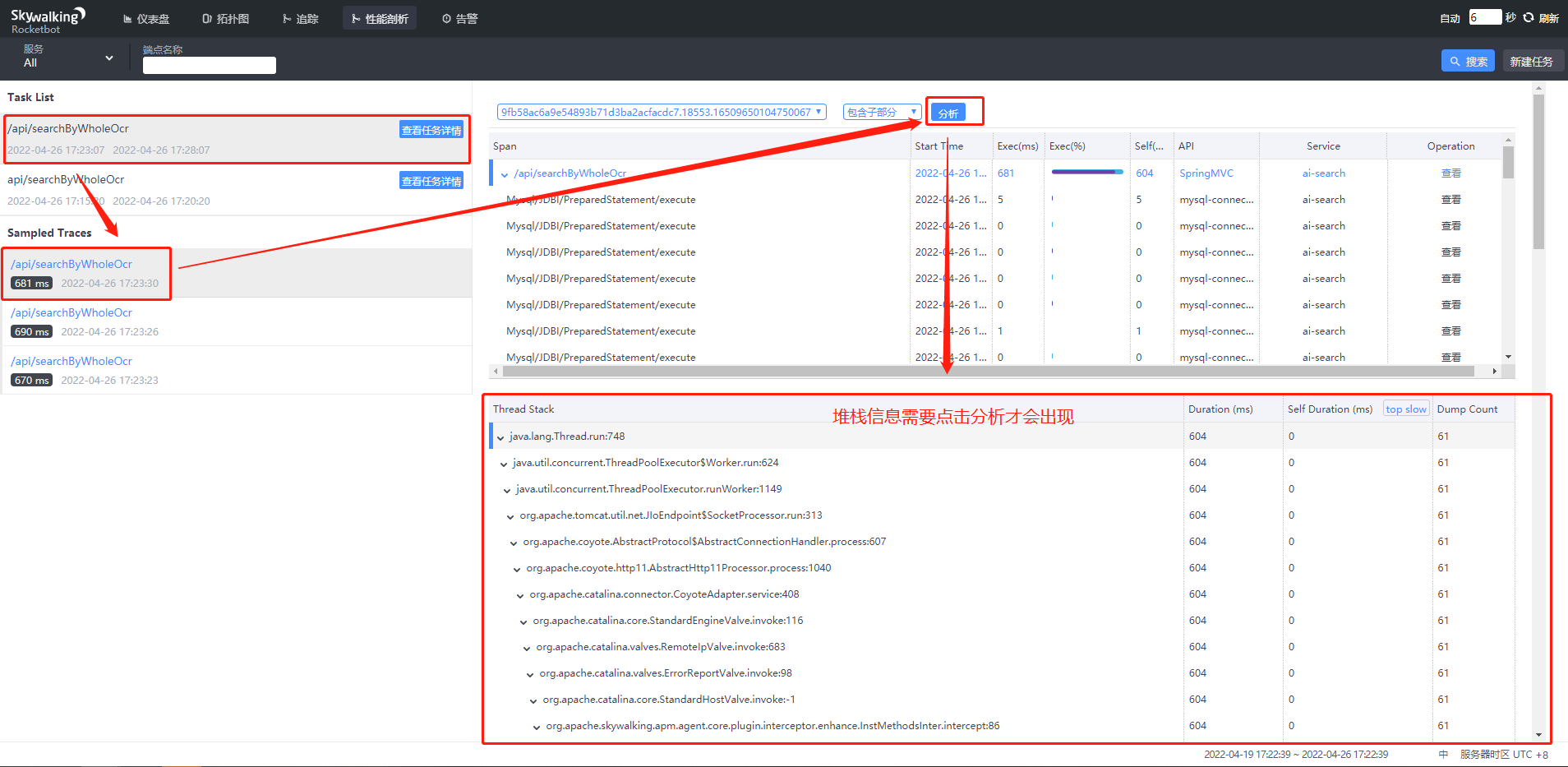
上图可以看出,”/api/searchByWholeOcr“ 接口耗费了681ms,通过分析详细堆栈信息,我们可以看到耗时最多的操作就是SearchServiceImpl 类的 executeSearchRequest()方法,耗费了563ms,主要是调用 ES 做了全文搜索,如下图所示:











