Oracle 优化器RBO, CBO
RBO 基于规则的优化器 oracle 10g开始,已经丢弃RBO
CBO 基于成本的优化器 oracle 8中开始引入的
Oracle 解析器按照从右到左的顺序处理FROM 字句中的表名,FROM 中写在最后的表(基础表, drving table)将先被处理,在FROM 子句中包含多个表的情况下,你必须选择记录条数最小的表作为基础表, 如果有3个以上的表连接查,选择交叉表(Insertection table)作为基础表,交叉表指的是被其他表锁引用的表
性能优化
SELECT语句务必指明字段名称
SELECT *增加很多不必要的消耗(cpu、io、内存、网络带宽);增加了使用覆盖索引的可能性;当表结构发生改变时,也需要更新。所以要求直接在select后面接上字段名。
SQL语句中IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。再例如:select id from table_name where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了;再或者使用连接来替换。
尽量用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
区分in和exists, not in和not exists
select * from 表A
where id in (select id from 表B)等价于
select * from 表A
where exists(select * from 表B where 表B.id=表A.id)区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。如何高效的写出一个替代not exists的sql语句?
栗子
select colname … from A表
where a.id not in (select b.id from B表)优化
select colname … from A表 Left join B表 on
where a.id = b.id where b.id is null 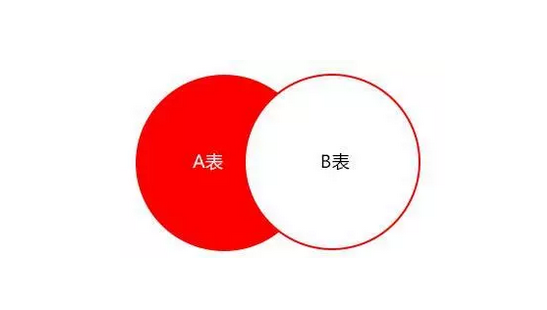
不建议使用%前缀模糊查询
例如LIKE “%name”或者LIKE “%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE “name%”。
那如何查询%name%?
如下图所示,虽然给secret字段添加了索引,但在explain结果并没有使用
避免隐式类型转换
where 子句中出现 column 字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定where中的参数类型
对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段id,name,school,可以直接用id字段,也可以id,name这样的顺序,但是name;school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询字段放在最前面











