在开窗函数出现之前,存在着很多用 SQL 语句很难解决的问题,很多都要通过复杂的相关子查询或者存储过程来完成。为了解决这些问题,在2003年ISO SQL标准加入了开窗函数,开窗函数的使用使得这些经典的难题可以被轻松的解决。
下面通过一些简单的需求示例介绍主要的开窗函数。
本例的数据源:
select * from wx_tmp1;
需求1:要在源表中,增加两列,全国总的gmv和各城市的gmv占比。
select *,sum(gmv) over() as all_gmv,
gmv/sum(gmv) over() as gmv_pro
from wx_tmp1;
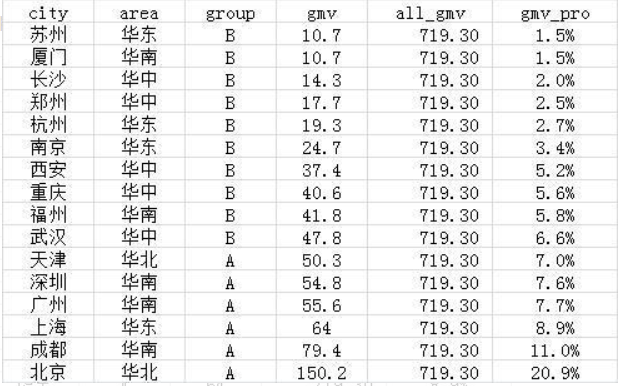
这就是开窗函数的妙处。SQL标准允许将所有聚合函数用做开窗函数,只需要在聚合函数后加over()即可。
over()可以传入对应的子句来达到不同的效果,下面一一介绍。
需求2:要在源表中,增加两列,各区域的gmv及各分组的gmv。
select *,
sum(gmv) over(partition by area) as area_gmv,
sum(gmv) over(partition by group) as group_gmv
from wx_tmp1;
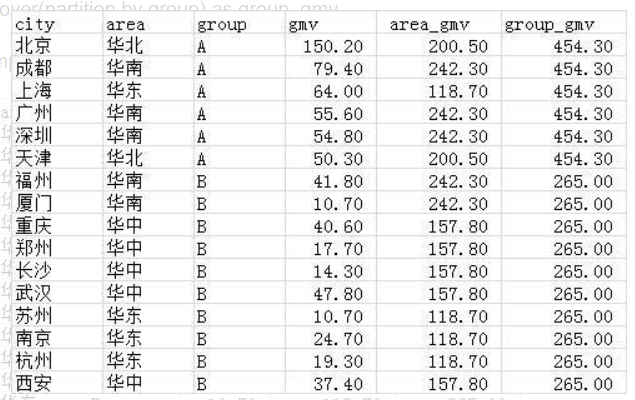
partition by对表进行分区然后聚合计算每个分区的数据,且同一个select语句中可以同时使用多个开窗函数,而且这些开窗函数并不会相互干扰。
需求3:在源表的基础上,增加一列,按gmv升序排列并计算累计gmv。
select *,
sum(gmv) over(order by gmv rows between unbounded preceding and current row) as leiji_gmv
from wx_tmp1;
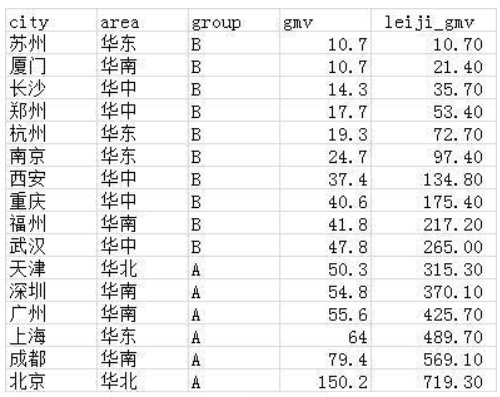
order by子句可以对结果集按照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算。
order by子句的语法为:order by 字段名 range|rows between 边界规则1 and 边界规则2。
range|rows between 边界规则1 and 边界规则2,这个子句又被称为定位框架。
range是按照值的范围进行范围的定义,rows是按照行的范围进行范围的定义,边界范围可取值:
current row:当前行
n preceding:前N行,比如 2 preceding
unbounded preceding:一直到第一条记录
n following:后N行
unbounded following:一直到最后一条记录
这个需求中,计算累计gmv,即计算第一条记录到当条记录的gmv之和。
rows between unbounded preceding and current row,是最常用的定位框架,可以省略。
因此可以简写为以下:
select *,
sum(gmv) over(order by gmv) as leiji_gmv
from wx_tmp1;
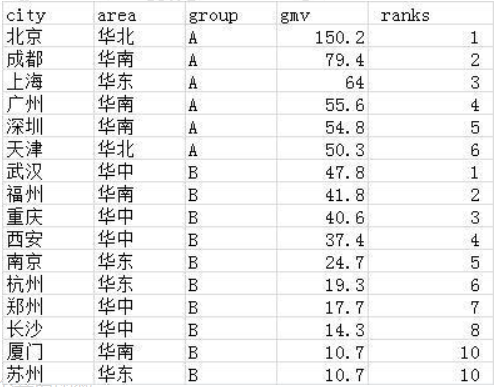
需求4:在源表中,增加一列,计算gmv的分组排名。
select *,
count(city) over(partition by group order by gmv desc) as ranks
from wx_tmp1;
分组排名有另外三个开窗函数:
select *,count(city) over(partition by group order by gmv desc) as ranks1,
rank() over(partition by group order by gmv desc) as ranks2,
dense_rank() over(partition by group order by gmv desc) as ranks3,
row_number() over(partition by group order by gmv desc) as ranks4
from wx_tmp1
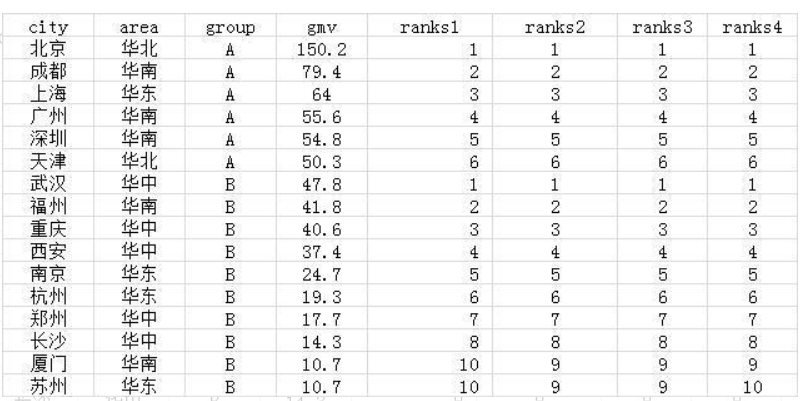
通过结果可以看出几种排序的差异。ranks2和ranks3的排序在本例中没有体现:
ranks2:如果下面还有一个城市的话,排名是11;ranks3:如果下面还有一个城市的话,排名是10。
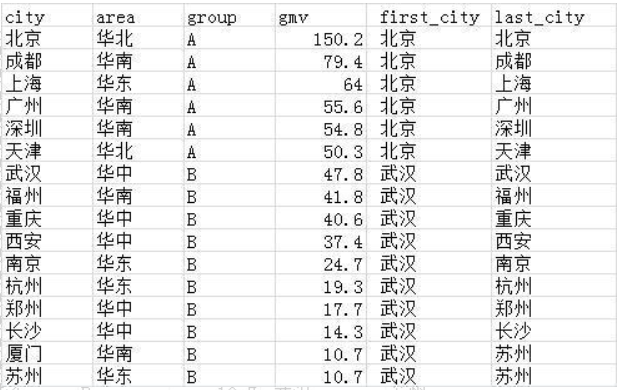
需求5:在源表中增加两列,取出每组gmv最大的城市,和最小的城市。
select *,first_value(city) over(partition by group order by gmv desc) as first_city,
first_value(city) over(partition by group order by gmv) last_city
from wx_tmp1
first_value:按分组排序后,取范围内第一个值。相应的还有last_value,按分组排序后,取范围内,最后一个值。
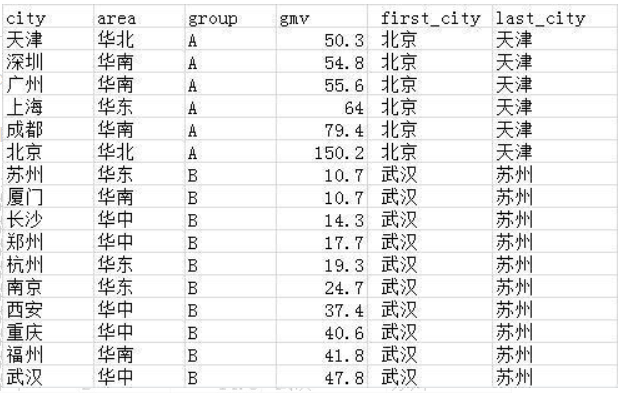
如果这个需求中,按以下写法的话:
select *,first_value(city) over(partition by group order by gmv desc) as first_city,
last_value(city) over(partition by group order by gmv desc) last_city
from wx_tmp1
会发现last_city的结果不是我们想要的。是因为使用了默认定义框架:第一行到当前行的最后一个值。
要纠正这个问题,需要使用定位框架,因为相对麻烦,建议用first_value()替代。
需求6:在源数据中增加两列,第一列取gmv分组排名在当前城市上面1位的城市,第二列取gmv分组排名在当前城市下面1位的城市。
select *,lag(city,1,null) over(partition by group order by gmv desc) as up_city,
lead(city,1,null) over(partition by group order by gmv desc) down_city
from wx_tmp1
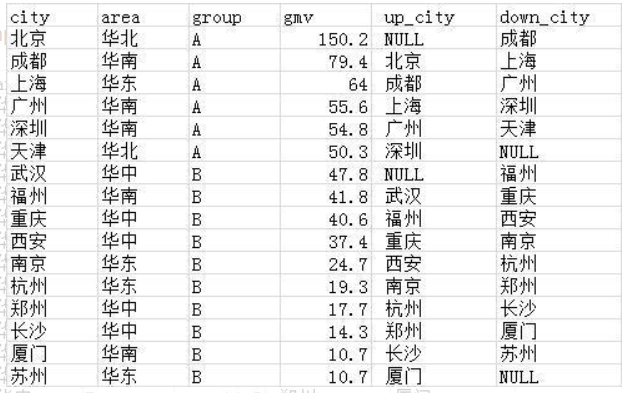
如果要取排名前/后两位的城市,调整lag和lead第二个参数即可。第三个参数为默认值,可以省略,省略的话,默认取不到时是NULL,如果不省略的话,取不到时则取指定默认值。
还有一个开窗函数,如下用法:
select *,ntile(2) over(partition by group order by gmv desc) rn from wx_tmp1
即将源表按group分组,并按gmv降序排列后,将每组平均分为2部分。
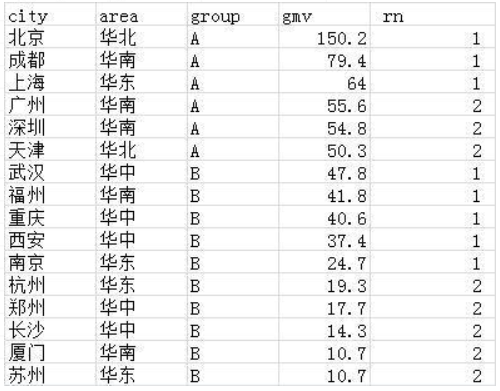
还有其他聚合函数用法跟sum()一致,就不一一介绍了。
转自:https://baijiahao.baidu.com/s?id=1592467638440407962&wfr=spider&for=pc
转载于:https://blog.51cto.com/yntmdr/2152991
相关资源:hive开窗函数知识点总结.txt_hive开窗函数,hive开窗函数详解-Hive…










