ASCII编码
将0000 0000 ~ 0111 1111编码成英文与一些控制字符,比如97对应的是小写字母’a’,但是中文是编码不过来的。或者说如果文件采用的是ASCII编码,那么文件中不能出现中文,否则就会乱码。
UTF-8编码
由于ASCII编码表示的字符太少了,所以各个国家都有一套自己的编码标准,比如中国的GB2312、GBK编码等。但是如果每个国家都用自己的标准,那么交流起来就很复杂,所以ISO组织就发明了UNICODE编码,UTF-8(每次传输8位)是UNICODE的一种,向下可兼容ASCII编码,其格式如下:
00 - 7F:0xxxxxxx
80 - 7FF:110xxxxx 10xxxxx
800 - FFFF:1110xxxx 10xxxxxx 10xxxxxx
10000 - 10FFFF:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
# 序列0开头表示兼容ASCII编码
# 序列110开头表示是两个字节编码的
# 序列1110开头表示是三个字节编码的
# 序列11110开头表示是四个字节编码的
# 序列10开头表示是编码字节的组成部分
1.求出“段”的UTF-8编码
段:6bb5 #中文"段"的Unicode编码是6bb5
6bb5: 0110 1011 1011 0101
================================
0110 101110 110101
UTF-8:11100110 10101110 10110101
================================
# 故段的UTF-8编码为:E6AEB5
print("段".encode('utf-8'))
>>> b'\xe6\xae\xb5'
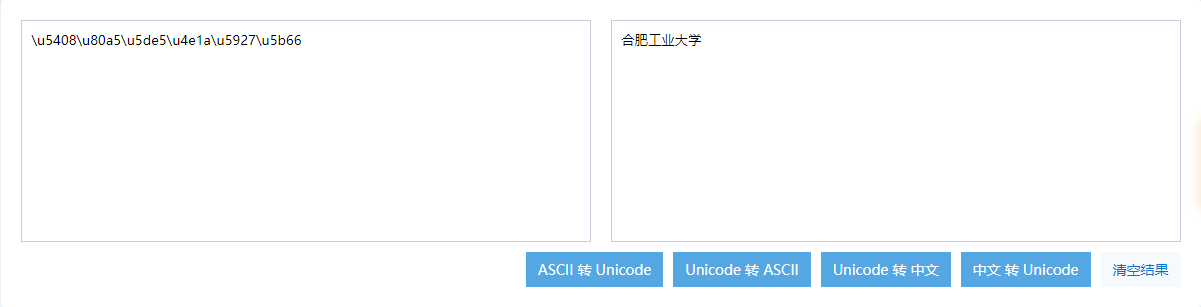
2.已知一串UTF-8编码的二进制序列,求出他对应的中文
# 字节序列如下,我们一行放五个字节
11100101 10010000 10001000 11101000 10000010
10100101 11100101 10110111 10100101 11100100
10111000 10011010 11100101 10100100 10100111
11100101 10101101 10100110
# 由于开头都是1110组成,所以都是由三个字节编码的
# 每三个字节一组,去掉固定的字段,提取信息后如下:
0101 010000 001000
1000 000010 100101
0101 110111 100101
0100 111000 011010
0101 100100 100111
0101 101101 100110
# 重新排列并转换成十进制
0101 0100 0000 1000 -> 0x5408
1000 0000 1010 0101 -> 0x80a5
0101 1101 1110 0101 -> 0x5de5
0100 1110 0001 1010 -> 0x4e1a
0101 1001 0010 0111 -> 0x5927
0101 1011 0110 0110 -> 0x5b66