- 参考:
- 李宏毅2021/2022春机器学习课程
- 王树森 RNN & Transformer 教程
- Transformer 详解
0. 背景:序列数据及相关任务
序列数据是由一组相互关联的样本组成的数据,其中任意样本对应的标记是由其自身和其他样本共同决定的;序列数据任务是输入或输出为序列数据的机器学习任务,用传统机器学习模型处理他们是困难的,比如 序列模型(1)—— 难处理的序列数据 中第 3 节的例子- 传统方法的局限性在于其问题建模,这些模型不是针对可变长度的输入输出设计的,无法体现序列数据的特点,具体而言
- 传统的 MLP、CNN 这类模型都是
one-to-one模型,即一个输入一个输出。这种模型会把序列数据作为一个整体来考虑,其输入输出的尺寸必须是固定的,比如输入一张固定尺寸的图像输出其类别,或者输入一段固定长度的句子预测下一个词Note:借助一些手段,可以强行用传统模型处理变长的输入输出问题,如 各种监督学习范式(强监督、半监督、多标记、偏标记、多示例、多示例多标记、标记分布...) 中的多示例多标记问题,但是这些模型本质上还是要将输入输出处理成固定的长度(比如用固定长度的 0/1 向量选出不同数量的样本作为输入输出)。至于样本间的关系,虽然可以通过网络自己学出来,但由于缺乏考虑这种关系的显式结构,所以很难学得好(可以参考 从模型容量的视角看监督学习)
- 一个良好的序列模型应该是
many-to-many模型,即支持可变长度的输入输出,并且最好能对序列样本间的关系进行显式建模,注意这样的模型也可以直接用来处理one-to-many,many-to-one甚至one-to-one问题。语音识别、本文情感分析、序列预测等等序列任务都能被这种模型更好地处理RNN 就是一种良好的序列模型,下图给出了各类输入输出情况下的 RNN 结构
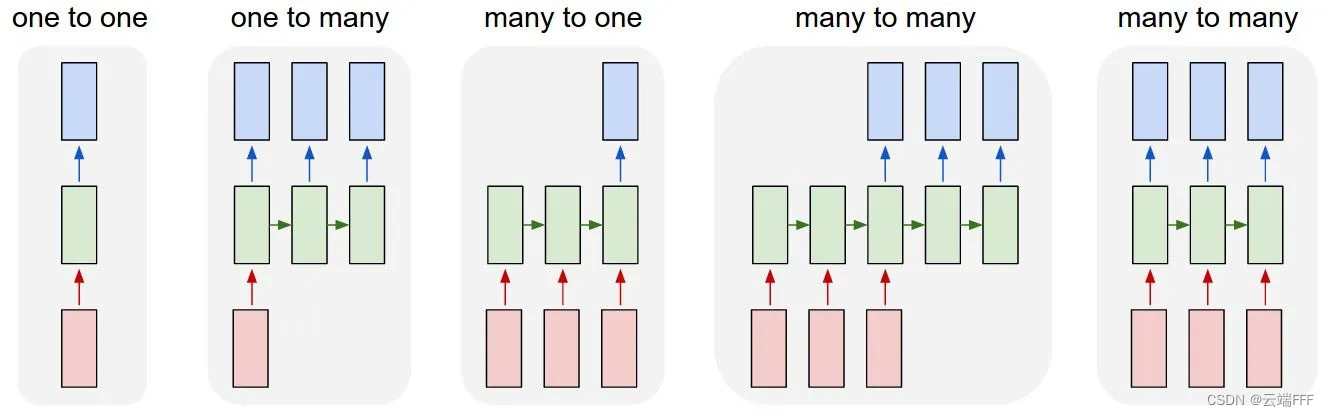
- 传统的 MLP、CNN 这类模型都是
1. 早期序列模型
- RNN 和 LSTM 等早期序列模型模仿人类处理序列数据的过程,人类阅读文本时每次看一个词,逐渐在大脑中积累文本信息,这些模型也是如此,其内部有一个隐状态代表目前积累的信息,每次读入一个序列样本就将其更新,如下图所示
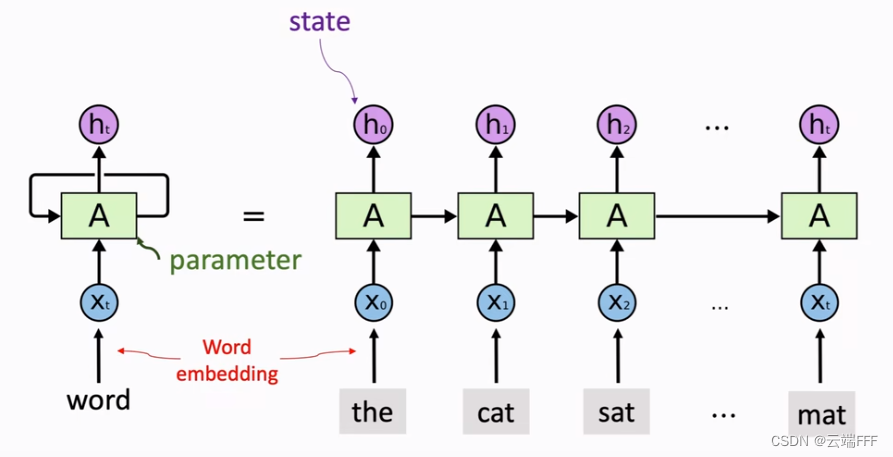 注意这里的每一列都是不同时刻下的同一个模型,可见,模型的每个隐状态都表示 “当前位置之前的 '已见序列片段' 的特征”,具体应用时
注意这里的每一列都是不同时刻下的同一个模型,可见,模型的每个隐状态都表示 “当前位置之前的 '已见序列片段' 的特征”,具体应用时
- 对于 “文本情感分析” 这类
传统监督学习任务(many-to-one),常将序列模型作为 “特征提取器”,只使用最后一个隐状态 $\pmb{h}_t$ 作为整个序列的特征向量,用它接一个分类头或回归头作为整个模型的输出。在训练时,只要像图像分类等普通监督学习任务一样训练即可 - 对于 “文本生成” 这类
标准语言模型任务(one-to-many),即不断根据之前序列样本预测下一个样本值的任务,通常会如下图所示做 Autoregress,这时我们会增加一个分类头或回归头将隐状态 $\pmb{h}$ 变换为输出 $\pmb{x}$,推断时不断地将上一步模型输出合并到下一步模型的输入中。在训练时,会构造很多以连续的 n 个样本作为输入,紧接着第 n+1 个样本作为标签的自监督样例,详见下文 1.4.1 节 - 对于 “文本翻译” 这类
Seq2Seq 任务(many-to-many),通常使用 Encoder-Decoder 结构。这时 Encoder 就是类似 1 中的 many-to-one 序列特征提取器,Decoder 就是类似 2 中的 one-to-many 序列生成器,Encoder 提取的特征作为 Decoder 的初始 seed,二者结合就能做 many-to-many 了。训练时通常用 teacher-forcing 形式,详见下文 1.4.2 节
- 对于 “文本情感分析” 这类
1.1 循环神经网络 RNN
- RNN 是实现第 1 节中 “信息积累” 概念的最简单模型,其结构图如下所示
 具体而言,设隐藏层激活函数为 $\phi$,$t$ 时刻输入批量大小为 $n$ 样本维度为 $d$ 的小批量样本 $\pmb{X}t\in \mathbb{R}^{n\times d}$,设隐藏变量维度为 $h$,前一个时刻的小批量隐层变量为 $\pmb{H}{t-1}\in\mathbb{R}^{n\times h}$。引入模型的权重参数 $\pmb{W}{xh}\in \mathbb{R}^{d\times h}, \pmb{W}{hh}\in \mathbb{R}^{h\times h}$ 和偏置参数 $\pmb{b}h\in \mathbb{R}^{1\times h}$,则该步的隐藏变量 $\pmb{H}t\in\mathbb{R}^{n\times h}$ 可以如下计算
$$
\begin{aligned}
\pmb{H}t
&= \phi(\pmb{X}t\pmb{W}{xh}+\pmb{H}{t-1}\pmb{W}{hh}+\pmb{b}h) \
&= \phi\left({\left[ \begin{array}{ccc}
\pmb{X}t & \pmb{H}{t-1}
\end{array}
\right ]}
{\left[ \begin{array}{ccc}
\pmb{W}{xh}\
\pmb{W}{hh}
\end{array}
\right ]}+\pmb{b}h\right) \
\end{aligned}
$$ 再设输出维度为 $m$,用于输出的 FC 层参数为 $\pmb{W}{hm}\in\mathbb{R}^{h\times m}, \pmb{b}_m\in\mathbb{R}^{1\times m}$,该步的输出变量 $\pmb{O}_t\in\mathbb{R}^{n\times m}$ 可以如下计算
$$
\pmb{O}_t = \pmb{H}t \pmb{W}{hm} + \pmb{b}_m
$$ 注意在不同的时间步使用的都是相同的模型参数 $\pmb{W},\pmb{b}$,因此 RNN 的参数开销不会随着时间步的增加而增加
具体而言,设隐藏层激活函数为 $\phi$,$t$ 时刻输入批量大小为 $n$ 样本维度为 $d$ 的小批量样本 $\pmb{X}t\in \mathbb{R}^{n\times d}$,设隐藏变量维度为 $h$,前一个时刻的小批量隐层变量为 $\pmb{H}{t-1}\in\mathbb{R}^{n\times h}$。引入模型的权重参数 $\pmb{W}{xh}\in \mathbb{R}^{d\times h}, \pmb{W}{hh}\in \mathbb{R}^{h\times h}$ 和偏置参数 $\pmb{b}h\in \mathbb{R}^{1\times h}$,则该步的隐藏变量 $\pmb{H}t\in\mathbb{R}^{n\times h}$ 可以如下计算
$$
\begin{aligned}
\pmb{H}t
&= \phi(\pmb{X}t\pmb{W}{xh}+\pmb{H}{t-1}\pmb{W}{hh}+\pmb{b}h) \
&= \phi\left({\left[ \begin{array}{ccc}
\pmb{X}t & \pmb{H}{t-1}
\end{array}
\right ]}
{\left[ \begin{array}{ccc}
\pmb{W}{xh}\
\pmb{W}{hh}
\end{array}
\right ]}+\pmb{b}h\right) \
\end{aligned}
$$ 再设输出维度为 $m$,用于输出的 FC 层参数为 $\pmb{W}{hm}\in\mathbb{R}^{h\times m}, \pmb{b}_m\in\mathbb{R}^{1\times m}$,该步的输出变量 $\pmb{O}_t\in\mathbb{R}^{n\times m}$ 可以如下计算
$$
\pmb{O}_t = \pmb{H}t \pmb{W}{hm} + \pmb{b}_m
$$ 注意在不同的时间步使用的都是相同的模型参数 $\pmb{W},\pmb{b}$,因此 RNN 的参数开销不会随着时间步的增加而增加
1.2 长短期记忆网络 LSTM
-
LSTM 是对 RNN 模型的改进,可以有效缓解 RNN 的梯度消失(见下文 1.3.2 节)问题,其结构如下所示
 这个结构看上去很复杂,不过我们可以从先从宏观角度来理解:相比 RNN,LSTM 针对序列数据性质增加了对数据处理过程的限制,从而减少了模型的弹性/容量,使它能在使得相同样本量下更好地提取序列信息,这和 CNN 比 MLP 能更好地处理图像数据是一个道理
这个结构看上去很复杂,不过我们可以从先从宏观角度来理解:相比 RNN,LSTM 针对序列数据性质增加了对数据处理过程的限制,从而减少了模型的弹性/容量,使它能在使得相同样本量下更好地提取序列信息,这和 CNN 比 MLP 能更好地处理图像数据是一个道理 -
现在来仔细看一下这个结构,LSTM 的设计灵感来自于计算机的逻辑门,它的输出和 RNN 一样仍然是隐状态 $\mathbf{H}$,只是生成过程更复杂。相比 RNN,LSTM 引入了
记忆单元cell$\mathbf{C}$,它和隐状态 $\mathbf{H}$ 具有相同的形状,用于记录附加的信息并产生输出 $\mathbf{H}$,其他的所有门都是为了控制这个记忆单元服务的。具体而言,设隐藏层维度为 $h$,batch size 为 $n$,样本维度为 $d$,则批量输入为 $\mathbf{X}t \in \mathbb{R}^{n \times d}$,前一时刻隐状态为 $\mathbf{H}{t-1} \in \mathbb{R}^{n \times h}$- 候选记忆 $\pmb{\tilde{C}}$ 和 RNN 中的隐状态 $\mathbf{H}$ 完全一致,只是指定了使用激活函数 $\phi=\tanh$,将值压倒 $(-1,1)$
- 遗忘门 $\mathbf{F}_t \in \mathbb{R}^{n \times h}$ 用来控制要保留记忆单元 $\mathbf{C}$ 中的过去信息的程度/比例,用 sigmoid 激活的 FC 层压倒 (0,1)
- 输入门 $\mathbf{I}_t \in \mathbb{R}^{n \times h}$ 用来控制候选记忆 $\mathbf{\tilde{C}}$ 被合并到记忆单元的程度/比例,用 sigmoid 激活的 FC 层压倒 (0,1)
- 输出门 $\mathbf{O}_t \in \mathbb{R}^{n \times h}$ 用来控制记忆单元 $\mathbf{C}$ 中作为输出 $\pmb{H}$ 的程度/比例,用 sigmoid 激活的 FC 层压倒 (0,1)
列一下公式,有 $$ \begin{aligned} \tilde{\mathbf{C}}t &= \text{tanh}(\mathbf{X}t \mathbf{W}{xc} + \mathbf{H}{t-1} \mathbf{W}_{hc} + \mathbf{b}c), \ \mathbf{I}t &= \sigma(\mathbf{X}t \mathbf{W}{xi} + \mathbf{H}{t-1} \mathbf{W}{hi} + \mathbf{b}i),\ \mathbf{F}t &= \sigma(\mathbf{X}t \mathbf{W}{xf} + \mathbf{H}{t-1} \mathbf{W}{hf} + \mathbf{b}f),\ \mathbf{O}t &= \sigma(\mathbf{X}t \mathbf{W}{xo} + \mathbf{H}{t-1} \mathbf{W}{ho} + \mathbf{b}o), \end{aligned} $$ 这里的 $\pmb{W},\pmb{b}$ 都是要学习的参数,相比 RNN 多了三组。另外,所有信息选取都是通过对应位置乘以 (0,1) 间小数的方式进行的,如图可见有 “遗忘门 $\mathbf{F}$ 去除部分老记忆 $\mathbf{C}{t-1}$”、“输入门 $\mathbf{I}$ 合并部分候选记忆 $\mathbf{\tilde{C}}$” 和 “输出门 $\mathbf{O}_t$ 保留部分新记忆 $\mathbf{C}_t$” 三处,公式表示为 $$ \begin{aligned} \mathbf{C}_t &= \mathbf{F}t \odot \mathbf{C}{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t\ \mathbf{H}_t &= \mathbf{O}_t \odot \tanh(\mathbf{C}_t). \end{aligned} $$
-
直观地看这个结构,其实就是每次 batch 输入先产生和 RNN 中 $\mathbf{H}$ 完全一样的 $\mathbf{\tilde{C}}t$ 作为 “当前步记忆”,然后用遗忘和输入门控制它和 “历史序列记忆” $\mathbf{C}{t-1}$ 混合得到 “最新序列记忆” $\mathbf{C}{t}$,最后使用输出门将 $\mathbf{C}{t}$ 衰减后输出为 $\mathbf{H}_t$
- 如果遗忘门始终为 1 且输入门始终为 0, 则过去的记忆元 $\mathbf{C}_{t-1}$ 将随时间被保存并传递到当前时间步,缓解梯度消失问题,更好地捕获序列中的长距离依赖关系。这有点类似残差网络通过残差连接避免梯度消失的思想
- 只要输出门接近 1,我们就能够有效地将所有记忆信息传递给预测部分, 而对于输出门接近 0,我们只保留记忆元内的所有信息,而不需要更新隐状态
-
最后再回到宏观来看,LTSM 通过学习四组系数 & 偏置参数,要求模型按照上述逻辑构造记忆并从中提取输出,相比 RNN 直接一个 FC 加激活函数,它通过模型结构引导其做出更符合序列性质的行为,从而缓解了 RNN 的梯度消失和梯度爆炸问题,大幅提升了 RNN 的性能
1.3 改善 RNN/LSTM 的三个技巧
1.3.1 通过堆叠扩展为深度模型
- 如果模型只有一层,其容量是有限的,无法表示太复杂的映射。但是注意到第 1 节这种序列模型对每一个输入都可以有一个输出代表对当前时刻之前的序列内容的聚合,而所有这些输出可以组合成一个新的序列,这样一来我们其实可以再把这个新序列输入参数相同的模型,这样每个输出将会是对当前时刻之前的序列内容的进一步聚合,如此反复堆叠就得到了
Stacked RNN/Stacked LSTM,其容量更大,能表示的映射关系也更加复杂,如下图所示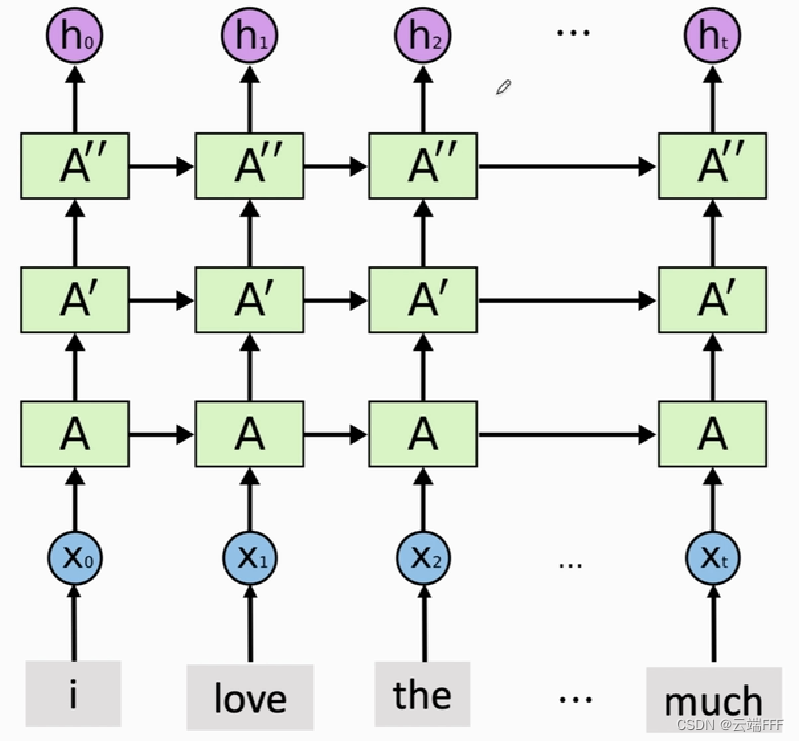 需要注意的是,对于更大容量的模型,需要提供更多的训练样本以避免过拟合
需要注意的是,对于更大容量的模型,需要提供更多的训练样本以避免过拟合
1.3.2 使用双向模型避免遗忘
-
无论 RNN 还是 LSTM,模型都只能利用隐藏状态间接地获取之前序列的信息,由于隐藏状态的维度一定远远小于之前的变长序列所有样本的连接维度,这种做法无可避免地会损失一些信息,体现在微观层面上就是两个经典问题
梯度消失:参数更新梯度被近期样本主导(和 MLP 里的梯度消失不太一样)梯度爆炸:参数更新梯度梯度趋近 $\infin$
在 RNN 中这两个问题尤其严重(可以参考 RNN梯度消失和爆炸的原因),以梯度消失为例,近期的序列样本主导了优化方向,这会导致模型快速忘记相隔时间比较久的早期序列输入,比如下例
这个 RNN 的任务是根据先前序列预测下一个单词,在 $x_1$ 处输入了 “China”,但由于梯度消失这个信息几乎没法被记住,模型难以在相隔较远的 $h_{t+1}$ 处给出 “Chinese” 的预测
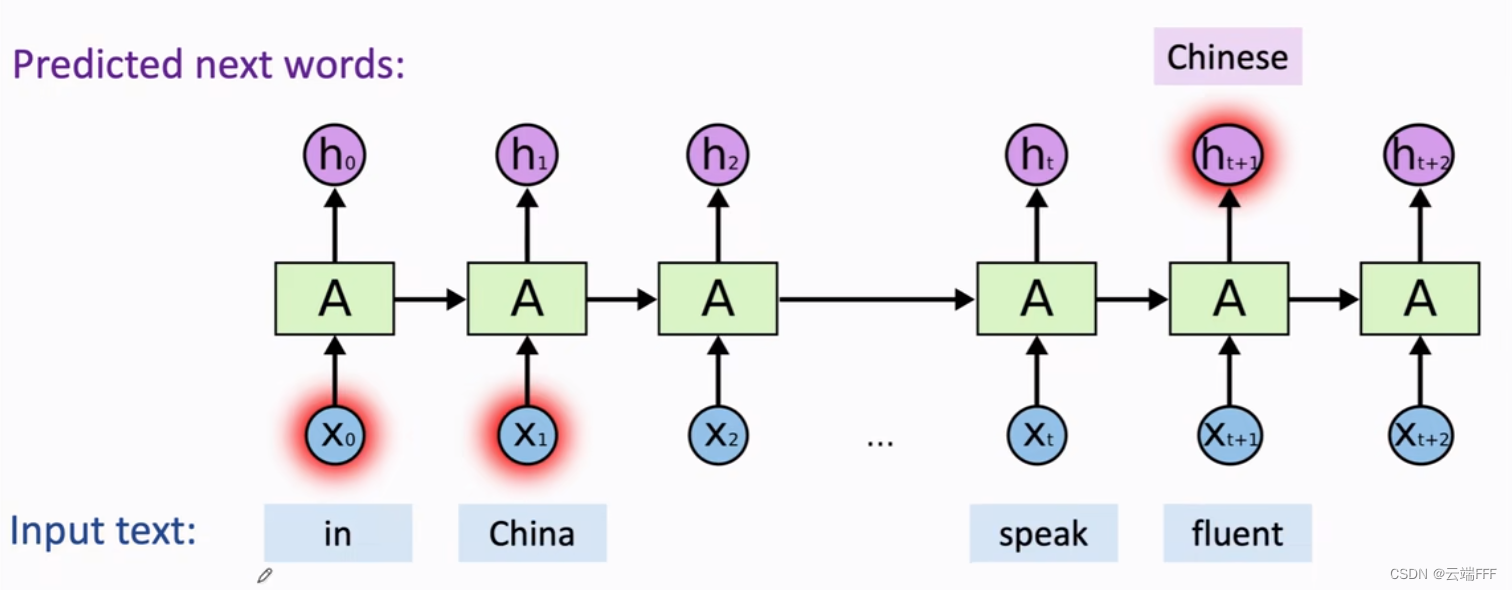 这里模型大概能学到应该输出一个语言,但是具体是什么语言会被近期序列的倾向所主导
这里模型大概能学到应该输出一个语言,但是具体是什么语言会被近期序列的倾向所主导LSTM 通过引入 “记忆单元” 缓解了这些问题,但依然无法完全解决。一个简单粗暴的优化方案是直接同时从两个方向训练 RNN 或 LSTM,这样得到的
Bidirectional RNN/Bidirectional LSTM结构如下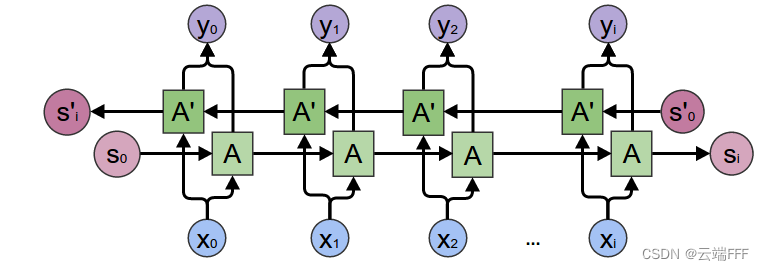 这样一来,一个方向的早期样本就成了另一个方向的近期样本,可以缓解 RNN/LSTM 的遗忘问题。另外这里输出的 $y$ 是两个模型输出的向量拼接,它也可以像上面那样进行 stack 从而扩展容量
这样一来,一个方向的早期样本就成了另一个方向的近期样本,可以缓解 RNN/LSTM 的遗忘问题。另外这里输出的 $y$ 是两个模型输出的向量拼接,它也可以像上面那样进行 stack 从而扩展容量
1.3.3 使用预训练模型
-
处理序列数据时往往要做一步 embedding,使得序列样本变得可以处理。比如常见的文本模型,你没法直接向网络输入一个单词,这时有几个做法
- 直接给每个单词编一个数字,但是这种简单做法存在问题,比如 “car” 编码为 1,“cat” 编码为 2,“red” 编码为 3,那么你会发现 “car” + “cat” = “red”,这是不合理的
- 更合理一点的做法是把单词编码成 one-hot 向量,但是这样一来如果单词数量多的话,输入的维度就会特别大,导致处理困难
- 目前通常的做法是先编码成 one-hot,然后接一个 FC 层把它降维,而且我们希望降维之后的词向量能够体现语义上的远近关系,比如 “汽车” 和 “跑车” 应该在嵌入空间接近;“汽车” 和 “苹果” 应该在嵌入空间远离
-
一个问题是,FC 嵌入层往往很大,有时甚至比模型参数还多不少,如果直接把它接在 RNN 或 LSTM 的输入之前一起训练,很容易导致嵌入层过拟合,影响模型性能。这时我们可以先用一个别的任务专门训练这个 FC 嵌入层,这就是所谓的
预训练pre-train过程,几个注意点是- 预训练任务必须要有对相同对象做嵌入的嵌入层,而且最好有大数据集
- 预训练任务可以是不同的任务,但是和目标任务越相关越好,因为学到的词向量会受到任务性质影响,越相关的任务,后期的调优过程越好做
- 预训练任务可以使用不同的模型,只要有 FC 嵌入层就行
完成预训练后,直接用预训练模型得到的 FC 嵌入层参数初始化目标模型的 FC 嵌入层,然后在目标任务训练过程中有时将其固定住只训练模型的其他部分,有时也带着这个 FC 层一起训练,这称为
微调fine-turn过程 -
所有涉及预处理的部分都可以用类似思路进行预训练,可以有效提高模型性能
1.4 传统序列模型任务
- 虽然 RNN 和 LSTM 都能对每个输入给出一个输出,但通常还是会用最后一个样本对应的输出作为整个序列的特征用于具体任务,因此这些传统模型自身是倾向
many-to-one形式的,但是通过巧妙的应用,其能处理的问题涵盖了one-to-many,many-to-one和one-to-one所有情况,下面简单举两个例子进行说明
1.4.1 自动文本生成(Autoregress 结构)
- 这个任务只需要一大段文本作为材料,就能生成出类似风格的句子
- 训练阶段,使用自监督方式构造样本,每个样本都是以一段固定长度文本作为输入序列,其后的词或字符作为预测标记,直接做多分类监督学习即可。样本的具体构造方式可以是随机截取,也可以是用一个滑动窗口以一定的偏移量扫过输入文本材料。注意到这样的输入输出符合
many-to-one的形式,另外由于输入长度必须固定,某种程度上也能看做one-to-one形式换个角度看,此模型也可理解为先用序列模型提取前驱序列的特征(RNN/LSTM 视角下就是隐变量),再用这个特征做多分类来选择生成下一个 token,直接把这两件事放在一起进行 end-to-end 的训练
- 预测阶段,使用 Autoregress 的方式反复生成单词或字符,如下图所示
 随便给定一个种子向量代表前驱序列特征,再给一个起始 token,模型就能输出后继 token 和新的隐状态,再将后继 token 作为输入就能继续生成,不断重复下去就能生成无限制长度的序列,这就是所谓的 “Autoregress”。总体上看属于
随便给定一个种子向量代表前驱序列特征,再给一个起始 token,模型就能输出后继 token 和新的隐状态,再将后继 token 作为输入就能继续生成,不断重复下去就能生成无限制长度的序列,这就是所谓的 “Autoregress”。总体上看属于 one-to-many形式
- 训练阶段,使用自监督方式构造样本,每个样本都是以一段固定长度文本作为输入序列,其后的词或字符作为预测标记,直接做多分类监督学习即可。样本的具体构造方式可以是随机截取,也可以是用一个滑动窗口以一定的偏移量扫过输入文本材料。注意到这样的输入输出符合
- 自动文本生成任务的意义在于,通过特定的结构安排,可以让只会做
to-one任务的模型完成to-many任务。监督学习模型基本都是 to-one 的,所以借助这个结构,我们甚至可以用 MLP 等八竿子打不着的模型来做文本生成,但由于这些网络缺乏对于序列任务的归纳偏置,提取序列特征的能力差,效果通常很差。可以参考 序列模型(1)—— 难处理的序列数据
1.4.2 机器翻译(Encoder-Decoder 结构)
-
机器翻译的输入和输出都是变长度序列,是典型的
many-to-many问题,机器学习中也称这种任务为 “Seq2Seq” 任务。为了让 RNN/LSTM 有能力处理这类问题,模型要设计成特殊的 “编码器-解码器架构”。正如其名,这种架构含有两个组件编码器Encoder:接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态,即从输入序列中提取一个特征向量。原始的 RNN/LSTM 可以完成这种many-to-one的任务,但特征向量中不可避免地会损失长跨度样本的信息,这也是后面出现注意力机制的重要原因解码器Decoder:将固定形状的编码状态映射到长度可变的序列。这恰好是上面 1.4.1 节那种one-to-many任务,所以 Decoder 也可以看做使用 Encoder 编码特征作为初始种子特征向量的自动文本生成任务。为了能自动控制输出长度,通常要增加 “起始” 和 “终止” 两个特殊 token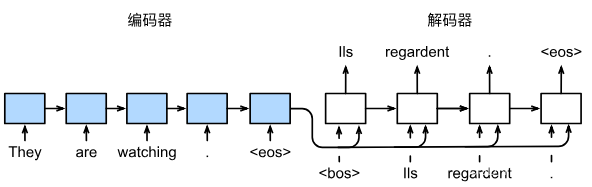
-
机器翻译模型设计得很巧妙,通过连接
many-to-one和one-to-many的两个组件真正实现了many-to-many任务-
训练阶段,Encoder 和 Decoder 连在一起作为一个 many-to-many 模型训练。以文本翻译任务为例,对于数据库中一个形如 $(样本序列, 标签序列)$ 的样本,如下操作
- Encoder 输入完整的样本序列,将 “起始” token 输入 Decoder,预测目标序列第1个 token $\pmb{p}_1$,它和标签序列第1个真实 token $\pmb{y}_1$ 计算损失
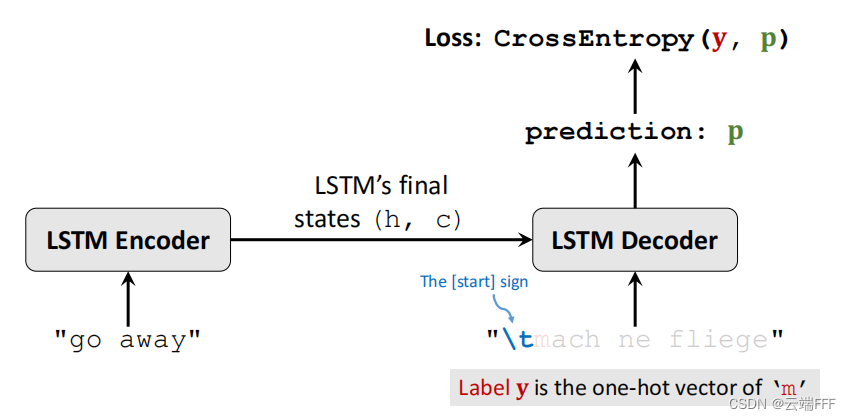
- Encoder 输入完整的样本序列,将 “起始” token 和标签序列第1个 token 输入 Decoder,预测目标序列第2个 token $\pmb{p}_2$,它和标签序列第2个真实 token $\pmb{y}_2$ 计算损失
- 重复直到标签序列最后一个 token
每次计算的损失梯度会从 Decoder 一直回传到 Encoder,同时更新两个组件的参数
- Encoder 输入完整的样本序列,将 “起始” token 输入 Decoder,预测目标序列第1个 token $\pmb{p}_1$,它和标签序列第1个真实 token $\pmb{y}_1$ 计算损失
-
测试阶段,Encoder 输入待翻译的句子,Decoder 输入 “起始” token,让它如 1.4.1 节一样自回归地生成序列,直到输出 “结束” token 未知
-
-
本节介绍的 “编码器-解码器结构” 是序列学习领域的一个重要模型,后面的 transformer 其实也是基于这个架构设计的
2. 注意力机制
2.1 注意力机制 (Attention)
-
正如上文 1.3.2 节的讨论,RNN 和 LSTM 这种传统序列模型对长跨度序列样本的特征提取能力有限,很容易出现梯度消失等问题,这个问题即使用双向模型也无法完全解决。Attention 是针对这个遗忘问题设计的,以机器翻译任务为例
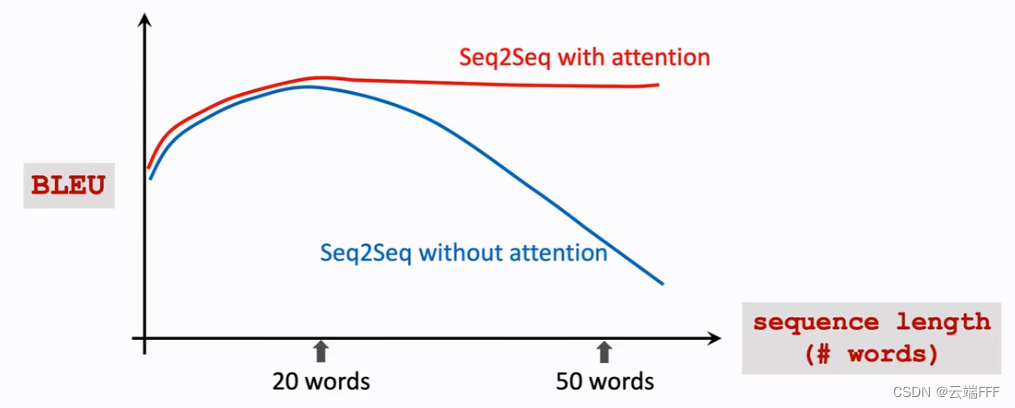 可见当句子长度超过 20 词时,传统序列模型翻译的 BLEU 评分会迅速下降,增加 attention 机制后问题解决
可见当句子长度超过 20 词时,传统序列模型翻译的 BLEU 评分会迅速下降,增加 attention 机制后问题解决 -
Attention 机制最早提出于 ICLR 2015 的文章 Neural machine translation by jointly learning to align and translate,这篇文章基于 Encoder-Decoder 结构做机器翻译任务,它的思想很简单,Decoder 输出每个词时不要再只依赖一个隐状态特征向量 $\pmb{s}$,而是去看完整地看一遍要翻译的原句,从原句的所有样本中提取信息汇聚成上下文向量 $\pmb{c}$ 作为 Decoder 的附加输入,而所谓 attention,本质就是汇聚上下文向量时的权重
Note:$\pmb{c}$ 可以作为附加信息和 $\pmb{s}$ 一起作为解码器输入;也可以完全不用 $\pmb{s}$ 只依靠 $\pmb{c}$ 和输入 token $\pmb{x}'$ 进行解码,因为 $\pmb{c}$ 中已经包含了从来自原始序列所有样本的特征
将这样的 attention 机制加入 RNN/LSTM Encoder-Decoder 结构,如下
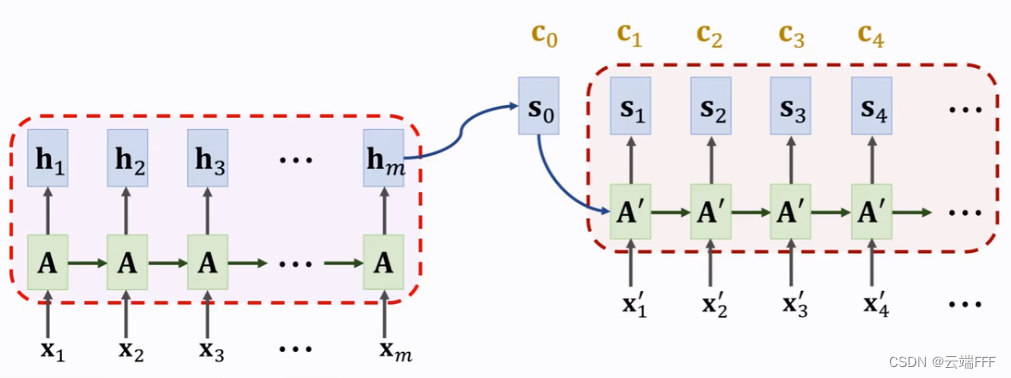 相比原始 RNN/LSTM Encoder-Decoder,差别仅在于多了一个上下文向量 $\pmb{c}_i$ 作为解码的附加信息(下图显示了注意力汇聚过程和附加输入结构,忽略了注意力计算过程)
相比原始 RNN/LSTM Encoder-Decoder,差别仅在于多了一个上下文向量 $\pmb{c}_i$ 作为解码的附加信息(下图显示了注意力汇聚过程和附加输入结构,忽略了注意力计算过程)
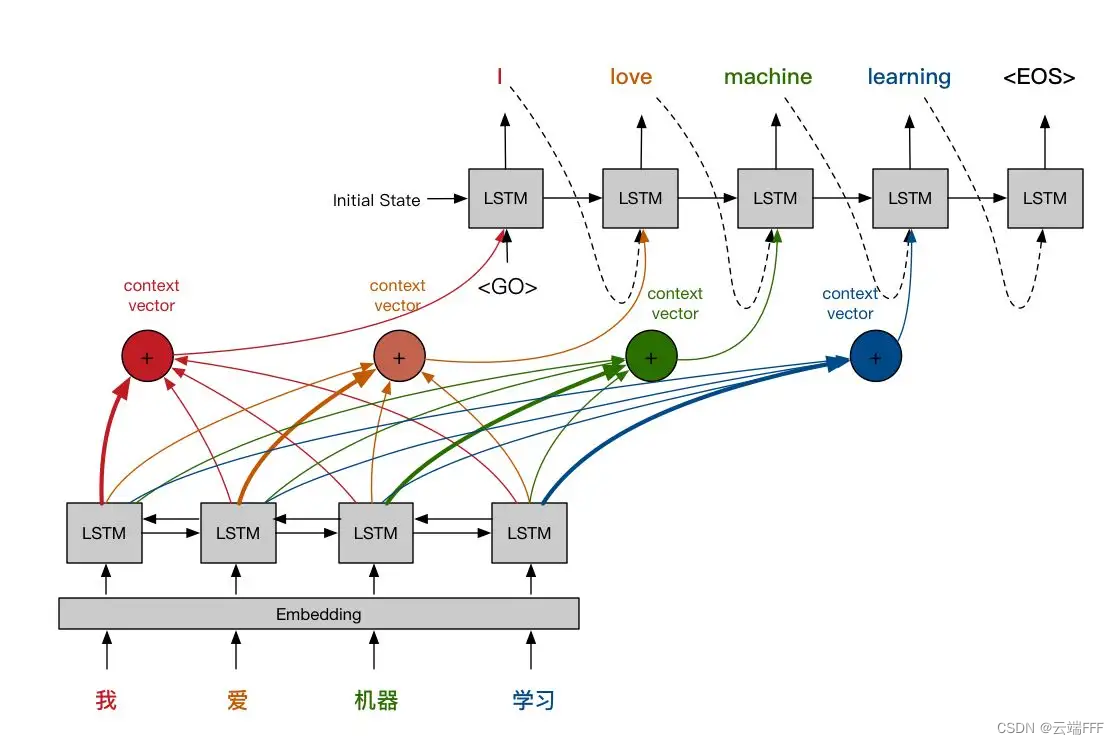
-
下面不严谨地歇写一下上下文向量的计算过程
- 利用
注意力评分函数$a$,计算输入 Decoder 的隐状态 $\pmb{s}_j$ 和 Encoder 的所有样本输出 $\pmb{h}_1,...,\pmb{h}_m$ 的注意力得分$\alpha_1,...,\alpha_m$,这个得分体现的是 $\pmb{s}_j$ 和 Encoder 各个输出 $\pmb{h}_i$ 的相关性 $$ \alpha_i = a(\pmb{h}_i,\pmb{s}_j) $$ - 对注意力得分进行 softemax,转为权重形式 $$ \alpha_1,...,\alpha_m \leftarrow \text{softmax}(\alpha_1,...,\alpha_m) $$
- 利用权重对 Encoder 各个输出进行汇聚,得到解码当前 token 所需的
上下文向量,直接将其作为解码 $\pmb{s}$ 时输入 RNN Decoder 的附加信息即可 $$ \pmb{c}j = \sum{k}\alpha_k \pmb{h}_k $$
上述过程总结成一句话就是:利用 $\pmb{s}$ 和 $\pmb{h}$ 的相关性对 $\pmb{h}$ 加权求和得到 $\pmb{c}$。这里有一个问题,直接用原始的 $\pmb{s}$ 和 $\pmb{h}$ 向量往往不够灵活,比如二者维度可能不同,或者我们想在更高维度计算相关性,又或者想在更高维度汇聚 $\pmb{h}$ 中的信息,于是我们可以加一步抽象化
- 使用矩阵 $\pmb{Q}$ 对 $\pmb{s}$ 的维度进行变换,得到
查询向量query$\pmb{q}$ - 使用矩阵 $\pmb{K}$ 对 $\pmb{h}$ 的维度进行变换,得到
键向量key$\pmb{k}$ - 使用矩阵 $\pmb{V}$ 对 $\pmb{h}$ 的维度进行变换,得到
值向量key$\pmb{v}$
这里的 $\pmb{Q},\pmb{K},\pmb{V}$ 矩阵都是自己学出来的,在汇聚上下文向量 $\pmb{c}$ 时,通过 $\pmb{q},\pmb{k}$ 计算相关性,对 $\pmb{v}$ 加权求和进行汇聚,如下图所示
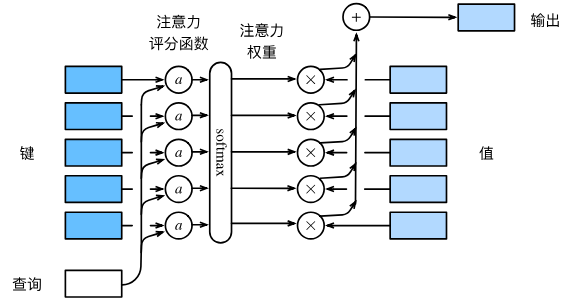
- 利用
-
注意力评分函数可以有多种设计
- 原始论文中使用的是
加性注意力additive attention,它允许 $\pmb{q}$ 和 $\pmb{k}$ 是不同长度的向量(事实上原始论文中的 $\pmb{q}$ 和 $\pmb{k}$ 就是 $\pmb{s}$ 和 $\pmb{h}$ 本身),给定 $\pmb{q}\in\mathbb{R}^q, \pmb{k}\in\mathbb{R}^k$,注意力得分为 $$ a(\mathbf q, \mathbf k) = \mathbf w_v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R}, $$ 其中可学习的参数包括 $\mathbf W_q\in\mathbb R^{h\times q}, \mathbf W_k\in\mathbb R^{h\times k}, \mathbf w_v\in\mathbb R^{h}$ - 现在主流用的是 transformer 使用的
缩放点积注意力scaled dot-product attention,它的计算效率更高,但要求 $\pmb{q}$ 和 $\pmb{k}$ 是相同长度的向量。假设查询和键的所有元素都是独立的 $d$ 维随机变量, 且都是均值0方差1,那么两个向量的点积的均值为0方差为$d$,将点积除以 $\sqrt{d}$ 使其方差为1,注意力得分为 $$ a(\mathbf q, \mathbf k) = \frac{\mathbf{q}^\top \mathbf{k}}{\sqrt{d}}
$$
- 原始论文中使用的是
-
引入 attention 机制,要求模型显式地考虑输出 token 和输入句子各个 token 间的相关性,可以解决传统 Seq2Seq 模型的遗忘问题。通过可视化训练后的 attention 向量,发现机器确实能够学到输入句子和输出句子各个 token 间合理的相关性
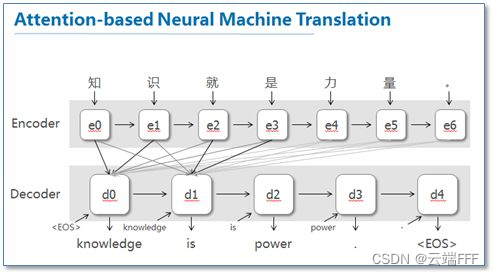 但这种能力是有代价的,设输入序列长 $m$,输出序列长 $t$,对传统模型引入 attention 机制会使计算复杂复从 $Q(m+t)$ 大幅上升到 $Q(m\times t)$
但这种能力是有代价的,设输入序列长 $m$,输出序列长 $t$,对传统模型引入 attention 机制会使计算复杂复从 $Q(m+t)$ 大幅上升到 $Q(m\times t)$值得注意的是,这种和传统序列模型结合的 attention 在 transformer 语境中被称为 cross attention,用来强调 attention 计算发生在 Decoder 和 Encoder 之间
2.2 自注意力机制 (Self-Attention)
- Self-Attention 机制提出于 2016 年的论文 Long Short-Term Memory-Networks for Machine Reading,原始的 attention 机制仅能用于 Seq2Seq 模型,而 self-attention 解除了这个限制,可以用于所有的 RNN/LSTM 结构的模型上
- Self-Attention 的思想也很简单,其实和 2.1 节的在计算上没有任何区别,只是原始 attention 机制计算的是输出句子各个 token 和输入句子各个 token 之间的 attention;Self-Attention 只考虑一个句子,它计算自己的各个 token 和该 token 位置之前的其他 token 的 attention,然后基于这个从之前的所有 token 中汇聚上下文 $\pmb{c}$,直接代替传统 RNN 中的隐状态 $\pmb{s}$,或者作为附加信息和 $\pmb{s}$ 拼在一起使用,Self-Attention 和 SimpleRNN 结合的一个简单示例如下
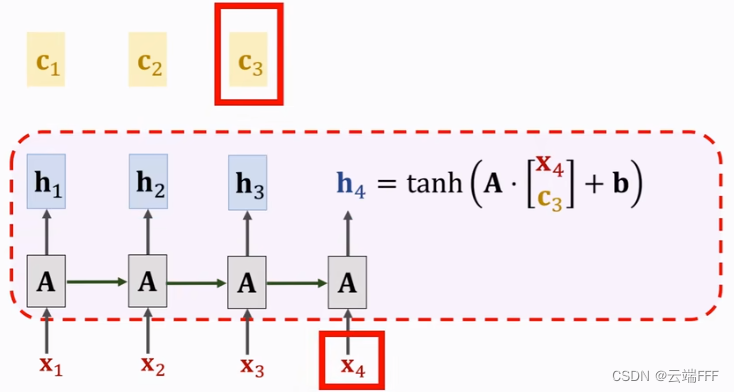 这里 $\pmb{h}$ 代表隐状态,而且在更新隐状态计算时直接用汇聚向量 $\pmb{c}$ 代替 $\pmb{h}$ 使用
这里 $\pmb{h}$ 代表隐状态,而且在更新隐状态计算时直接用汇聚向量 $\pmb{c}$ 代替 $\pmb{h}$ 使用 - 直观地看,Self-Attention 就是在更新 RNN/LSTM 隐状态时显式地要求模型重新看一遍之前的所有历史序列样本,从而避免遗忘,思想本质和 Attention 机制没有区别,不同之处在于 Self-Attention 的主要目的是用文本中的其它 token 来增强目标 token 的语义表示。从 attention 向量的可视化结果看,Self-Attention 可以避免遗忘,还能帮助传统 RNN/LSTM 更加关注有相关性的 token

值得注意的是,这种和传统序列模型结合的 self-attention 在 transformer 语境中被称为 masked self-attention,它其实只关注了句子中该 token 之前的部分
3. 现代序列模型
- 在 Attention 机制大幅提升传统序列模型的性能后,人们发现完全去掉传统序列模型,只用 Attention 机制其实就足以处理序列数据了,即所谓的 “Attention is all you need”。自从仅用 Attention 的 Encoder-Decode 模型 Transformer 出现后,带动了如下了一系列仅依赖于 attention 机制的现代序列模型
- 这个图仍在增长中,最近大火的 ChatGPT 来自 GPT3.5 系列,其实就是 GPT3 换了个基于 RL 的优化方法
btw,这个 RL 优化方法总体可以分两阶段
- 用我以前介绍过的 论文理解【IL - IRL】 —— Deep Reinforcement Learning from Human Preferences 这个 “从人类偏好中学习的” IRL 方法学出奖励
- 用 PPO 优化
ChatGPT 很会一本正经地胡说八道,其实也是那个 IRL 方法固有问题的体现
3.1 Transformer
- Transformer 模型提出于 2017 年的文章 Attention is all you need,它是一个仅依赖 Attention 层和 MLP 层组成的 Encoder-Decoder 模型,在众多自然语言处理问题中取得了非常好的效果
3.1.1 总体结构
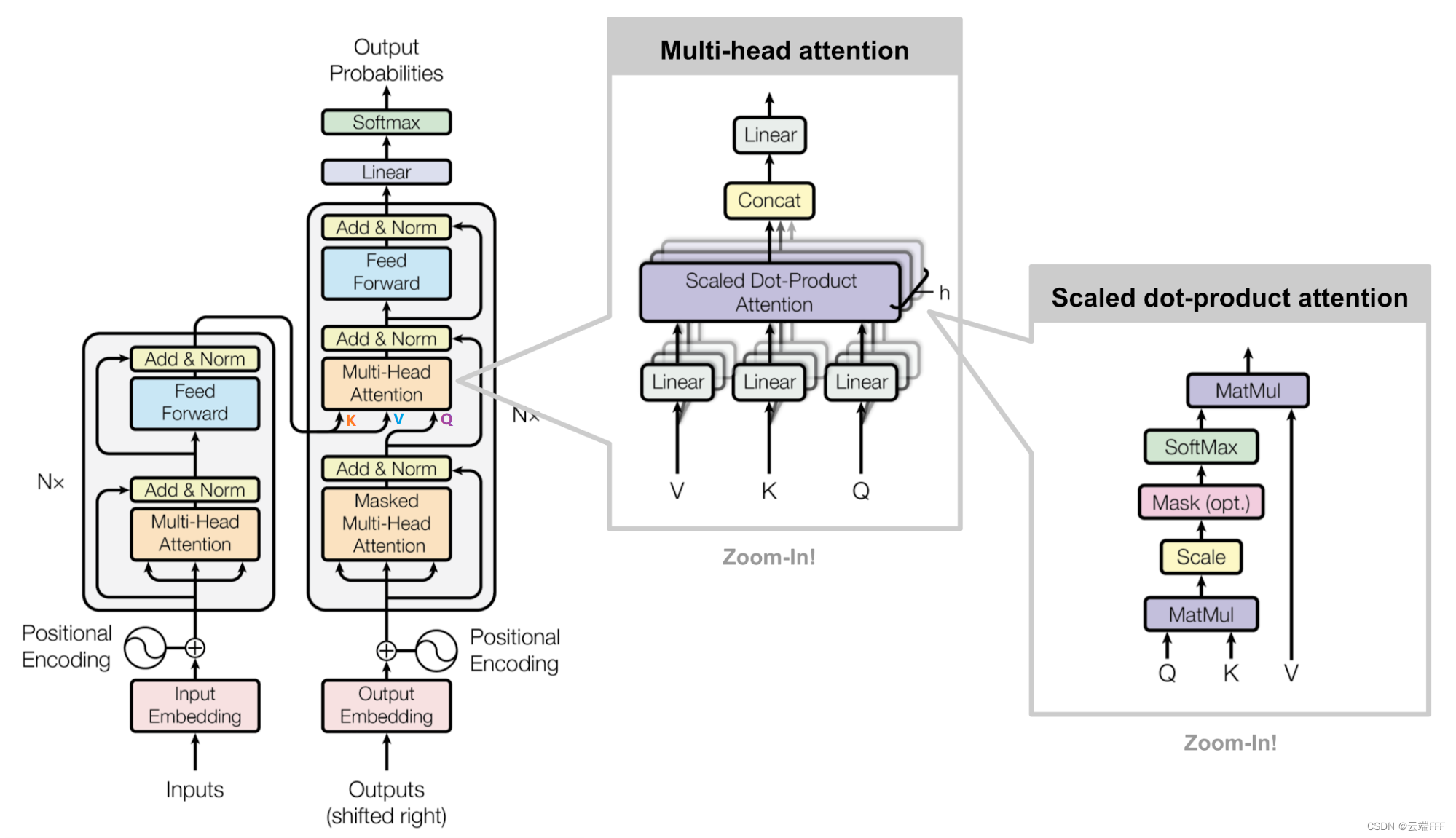
- 先看一下 Transformer 的总体结构图
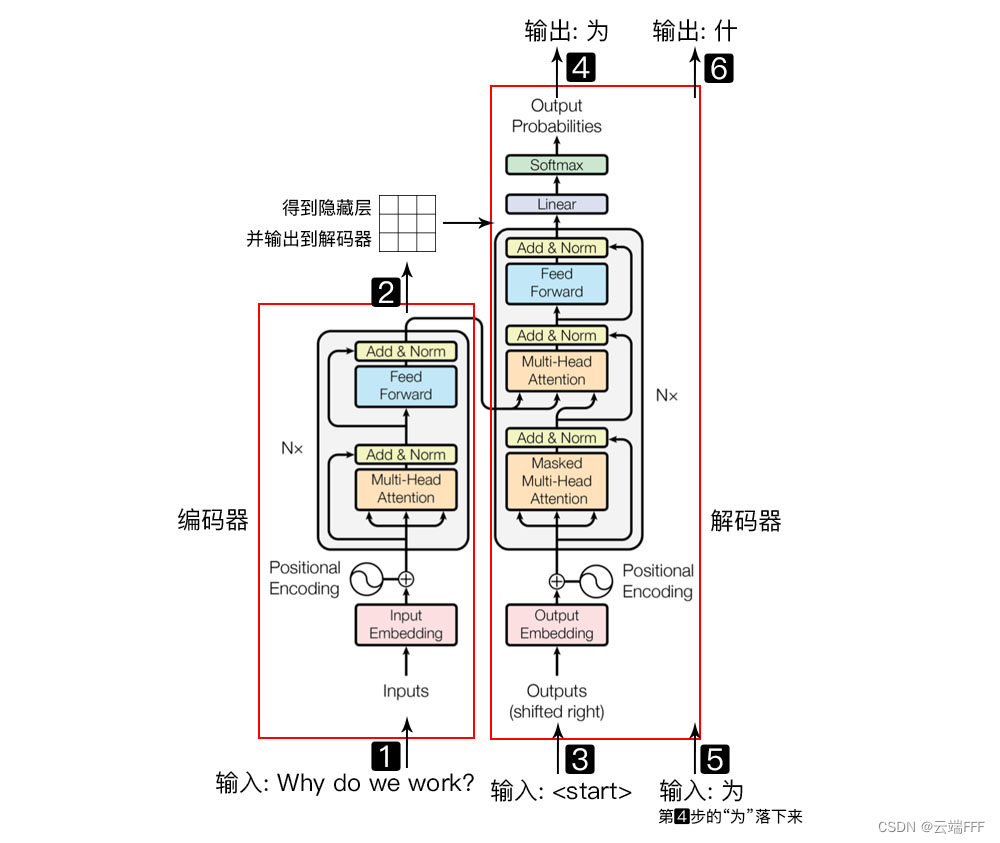 左边是 Encoder,它是一个
左边是 Encoder,它是一个自编码器,可以数据序列中提取特征;右边是 Decoder,它是一个自回归器,可以生成目标序列。从整体上看,Transformer 的外部输入输出和过去基于 RNN 等传统序列模型的 Encoder-Decoder 模型完全一致。请看图中数字编号- 数字 1 是 Encoder 输入,是 n 个 token 组成的序列
- 数字 2 是 Encoder 输出,是 n 个 特征向量组成的序列,每一个输出可以看做对应位置输入 token 的动态嵌入特征
- 数字 3/4/5/6 描述了 Decoder 的 Autoregress 过程
3.1.2 Encoder
- 本节介绍 transformer encoder 的结构,先给出结构图

- 我们从下往上看,假设做翻译任务,首先准备一个 batch 的源语言句子,全部拆开为 token 序列,通过增加 PAD token 补全到同样长度,然后用 Embedding 层将所有 token 投影到嵌入空间转换为 token embedding 向量,接下来就是四大组件
-
Positional Encoding:由于 Transformer 模型没有循环神经网络的迭代操作,所以我们必须提供每个字的位置信息给 Transformer,这样它才能识别出句子中的顺序关系。具体而言,我们会对序列中的每个位置(0,1,2...max_length)给出一个和 token embedding 维度相同的 positional embedding 向量,再直接将其和 token embedding 相加
- 有人可能会疑惑为什么两个 embedding 是相加关系,这是因为之前 Input Embedding 的具体操作是先把原始 token 都转换为的 one-hot vector 表示,再用一个矩阵做线性变换到嵌入维度,而原始 token 的 one-hot vector 直接 concat 一个位置的 one-hot vector,再一起做线性变换到嵌入维度,就等价于分别做线性变换再加起来
- 这里位置信息的嵌入向量是用一个公式计算出来的,思想来自数的二进制表示,可以参考 Transformer 修炼之道(一)、Input Embedding。这个计算出来的嵌入不一定是最好的,后面比如 BERT 里就是让网络自己学出来的了
-
Multi-Head Attention:这个就是一个使用 2.1 节最后介绍的缩放点积注意力评分函数的 self-attention 层,对于序列中的每一个 token,都用它的 query 向量,和此句中所有 token 的 key 向量计算相似度得到 attention,再根据 attention 加权汇聚此句中所有 token 的 value 向量,最终得到这个 token 在这个句子中的一个动态嵌入特征。而所谓 “Multi-Head”,其实就是我们需要用多组不同初始化的 $Q,K,V$ 矩阵算出多个汇聚向量,它们联合起来可以得到更丰富的特性信息,能更好地刻画这个 token 的动态嵌入特征。最后我们把所有这些汇聚向量 concat 连接起来一起用一个矩阵线性变换到 token embedding 维度,得到 token 的动态词嵌入向量
- 下图显示了一个 self-attention 头的计算过程,每个token 都得到了它对应的一个汇聚向量,注意这个汇聚向量的维度可以和 token embedding 不同

- 所谓 “动态嵌入特征”,是指 token 的这个特征受到了它所处句子中其他 token 的影响。举例来说,如果训练材料是描述农业种植的,那么 “苹果” 这个 token 的嵌入特征向量和 “香蕉” 的距离,会小于 “苹果” 和 “手机” 的距离;而如果训练材料是描述电子产品的,则正好相反。这种词向量的动态嵌入能力也是现代序列模型相对传统序列模型的一大优势
- 这里的多头注意力,可以类比 CNN 中同时使用多个滤波器的作用,每个注意力头,只关注一个独立的 “表示子空间”。举例来说,当你浏览网页的时候,你可能在颜色方面更加关注深色的文字,而在字体方面会去注意大的、粗体的文字。这里的颜色和字体就是两个不同的表示子空间。同时关注颜色和字体,可以有效定位到网页中强调的内容。使用多头注意力,也就是综合利用各方面的信息/特征
- 可以用下图来描述整个多头自注意力层的处理过程
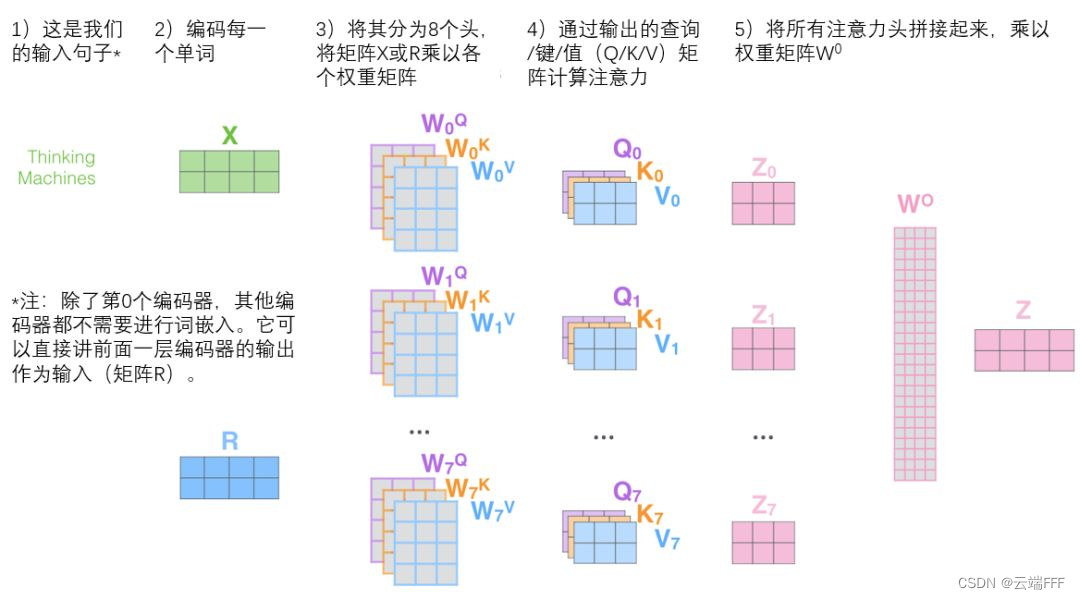
- 下图显示了一个 self-attention 头的计算过程,每个token 都得到了它对应的一个汇聚向量,注意这个汇聚向量的维度可以和 token embedding 不同
-
残差连接和 Layer Normalization:注意上面多头自注意力层的输出维度和 token embedding 维度一致,所以可以直接残差连接这是一个常见的避免梯度消失的 trick。Layer Normalization 则是一种常见的加速训练的 trick,它对每个样本的不同特征维度做归一化,使得每个样本内的各个特征维度的均值为0,方差为1
-
Feed Forward & Add norm:最后这个带残差连接的前馈网络是 Poswised 的。注意第 3 步的输出是 n 个 token 的动态特征嵌入向量,维度都是 token embedding 维度,这个 Feed Forward 就是一个输入层和输出层都是 token embedding 维的 MLP,它会被依次接到每一个嵌入向量上,这也可以理解为每个嵌入向量都接了一个维持维度的 MLP,然后所有 MLP 共享参数。它也会做残差连接以及 Layer Normalization 来加速。我理解中这一步就是为了对 token 的动态特征嵌入向量做一个增强
-
- 上面组件中的 2/3/4 合在一起称为一个 Transformer Encoder Block,由于它的输入输出都是 n 个维度相同的 token embedding 向量,这个 Encoder Block 可以堆叠多层来增加模型容量,原始 Transformer 中叠了 6 层,最后一层的输出,即 Transformer Encoder 的输出,就是输入序列中所有 token 的动态特征嵌入向量了
3.1.3 Decoder
- 如图可见,Transformer Decoder 的结构和 Encoder 几乎一致,它也可以输入 m 个 token,先用 Embedding 层和 Positional Encoding 组成初始的 token 嵌入向量,然后过一个多层堆叠的 Transformer Decoder Block 得到这 m 个 token 的动态嵌入向量,最后用一个线性层和 softmax 组成的多分类头生成新 token。下面仅对 Decoder 和 Encoder 不同的地方进行说明
- Transformer Decoder Block 最开始是一个 masked self-attention 层,这个层和 self-attention 层的计算完全一致,但是它会对每个 token 计算的注意力得分向量进行 mask,使得该 token 之后位置的注意力得分全部为 0,这样在汇聚信息时,只会汇聚该 token 以及它之前的部分序列。这个思想是好理解的,因为 Decoder 本身是一个自回归器,它在任意时刻只能知道该位置及之前的序列信息,后面的还不知道。这个结构其实和 2.2 节中完全一致
- Transformer Decoder Block 中还出现了一个 Encoder 中没有的 cross attention 层,这部分是连接 Encoder 和 Decoder 的桥梁,其结构和 2.1 节中介绍的完全一致。具体而言,计算多头注意力的方法完全没变,只是现在 $Q,V$ 矩阵作用于 Encoder 最后一层输出的 n 个输入序列 token 的动态特征嵌入向量上,$K$ 矩阵作用于前面 masked self-attention 输出的 Decoder token 的嵌入向量上,这样就能让每一个 Decoder token 关注到输入序列的全部 token 信息
- 下图显示了 cross attention 的计算过程
- 下图显示了宏观连续形式,最后一个 Transformer Encoder Block 的输出被连接到所有 Transformer Decoder Block 上

- 下图显示了 cross attention 的计算过程
- 最后一个 Transformer Decoder Block 的输出上连接了一个由 linear 层和 softmax 组成的多分类头,这个头类似所有 Transformer block 中最后的 Feed Forward 层,是 Poswised 的。总体上看,最后一个 Transformer Decoder Block 的每一个输出,都是 Decoder 输入序列中对应位置 token,在考虑了它和他之前的历史 Decoder 序列以及完整的 Encoder 输入序列后得到特征向量(例如把 “I love you” 翻译成 “我爱你”,在翻译到 “爱” 这个 token 时,Decoder 对应位置的输出,是综合考虑完整的原序列 “I love you” 和当前已经翻译的部分序列 “我爱” 之后得到的动态特征向量)。在标准语言模型的语境下,所有 Decoder 输出在地位上都是相同的,它代表的历史序列特征,可以直接用作下一个 token 的特征,因此这个多分类头只要依次连接到每一个输出上就能生成出下一个 token 了,即 3.1.1 总图中的 “根据 3 生成 4” & “根据 5 生成 6”
3.1.4 Transformer 的优点和缺点
-
相比基于传统序列模型的 Encoder-Decoder 模型,Transformer 主要有两大优点
- 完全依赖 attention 机制提取特征,所有要提取的部分都有显式网络结构连接,配合多头机制,不会出现特征损失
- Encoder 和 Decoder 都可以并行训练,即所有 token 对应的嵌入特征向量可以同时计算,而不用像 RNN 之类的循环结构那样必须一个一个地计算。
- 需要注意的是,为了实现全并行,Decoder 必须进行 teacher-forcing 形式的训练,而我们最后想让 Decoder 做 autoregress,所以这样学到的模型会有一点偏差,请参考 关于Teacher Forcing 和Exposure Bias的碎碎念。虽然也可以直接让 Decoder 做 autoregress 形式的训练,但是这样就没法并行了
- 另外,训练完做推理时还是串行的,因为 autoregress 本身就是一个串行的行为
-
Transformer 的缺点在于计算量巨大,由于任意两个 token 之间都要算 attention,一个 self-attention 的复杂度就从 $O(n)$ 提升到 $Q(n^2)$,带来两个后果
- 虽然并行了,但是计算速度还是比传统序列模型慢很多
- 虽然理论上 Transformer 不限制处理序列的长度,但是实际上还是没法处理太长的序列
目前也提出了很多通过稀疏化 attention 来降低复杂度的方法,可以参考 降低Transformer的计算复杂度
3.2 GPT 和 BERT
-
回顾第一节的分析,很多序列任务并不是 Seq2Seq 的,比如情感分类这种 many-to-one 任务,又或者文本生成这种 one-to-many 任务,而 Transformer Encoder 作为一个 AutoEncoder 可以做特征提取,适用于前一类任务;Transformer Decoder 作为一个 AutoRegresser 可以做序列生成,适用于后一类任务。直接把二者拆开,就得到了 GPT 和 BERT 模型,如下所示
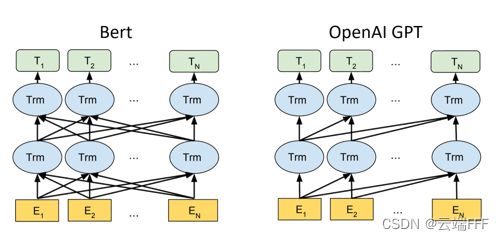 其中 BERT 和 Transformer Encoder 结构完全一致;GPT 是 Transformer Decoder 去掉 cross-attention 和最后的多分类头之后的部分,这样处理之后,二者结构上的区别仅在于 BERT 使用 self-attention 层,而 GPT 使用 masked self-attention 层。由于模型结构上没有什么新东西,这里就不再过多分析了
其中 BERT 和 Transformer Encoder 结构完全一致;GPT 是 Transformer Decoder 去掉 cross-attention 和最后的多分类头之后的部分,这样处理之后,二者结构上的区别仅在于 BERT 使用 self-attention 层,而 GPT 使用 masked self-attention 层。由于模型结构上没有什么新东西,这里就不再过多分析了 -
虽然模型上看和 Transformer 变化不大,但是他们的训练方式不同了,二者都可以使用自监督方式进行训练,这就意味着不需要标好的数据,具体而言
- BERT 可以自监督地构造 “完形填空” 和 “上下句判断” 任务的数据
- GPT 可以自监督地构造 “预测下一个 token” 任务的数据
通过自监督学习,可以无成本地获取大量带标签数据,能完美满足这类超大容量的 Transformer 模型对数据复杂度的极高要求。在 Transformer 出现之前,NLP 领域由于缺乏类似 ImageNet 这样的大型带标记数据集,几何没法用 CV 领域成熟的 “pre-train + fine-turn” 训练模式,而随着 BERT 和 GPT 的诞生,有了这种自监督方案之后,这条路线就打通了,这促成了 NLP 领域近年来的爆发式突破
-
事实上,由于使用自监督方案之后训练成本几乎仅限于算力,我们可以不断增大模型容量,训练巨量参数组成的超大网络,这就是 GPT / GPT2 / GPT3 / GPT3.5 / ChatGPT 这一路主要在做的事情(CPT3.5 改用 RL 训练了,可以参考这个)。更恐怖的是,目前没有看到这种方式的有性能饱和的趋势,只要不断增大模型,增大数据量和算力,学出模型的性能几乎可以无限提升,这也带动了一般 “大模型” 的浪潮。如果对模型容量和性能感兴趣,可以参考 从模型容量的视角看监督学习
-
另外,因为各种监督学习问题大都能转换为序列预测问题,而 self-attention 的约束足够弱,表示能力足够强,近年来我们看到 transformer 在各个领域疯狂乱杀,最近我在关注如何把这些结构用到 Offline-RL 中










