自编码网络的一个重要功能就是对数据进行降维,如将数据降维到二维或者三维,之后可以很方便地通过数据可视化技术,观察数据在空间中的分布情况。下面使用测试数据集中的500个样本,获取网络对其自编码后的特征编码,并将这500张图像在编码特征空间的分布情况进行可视化。
edmodel.eval()
TEST_num=500
test_encoder,_=edmodel(test_data_x[0:TEST_num,:])
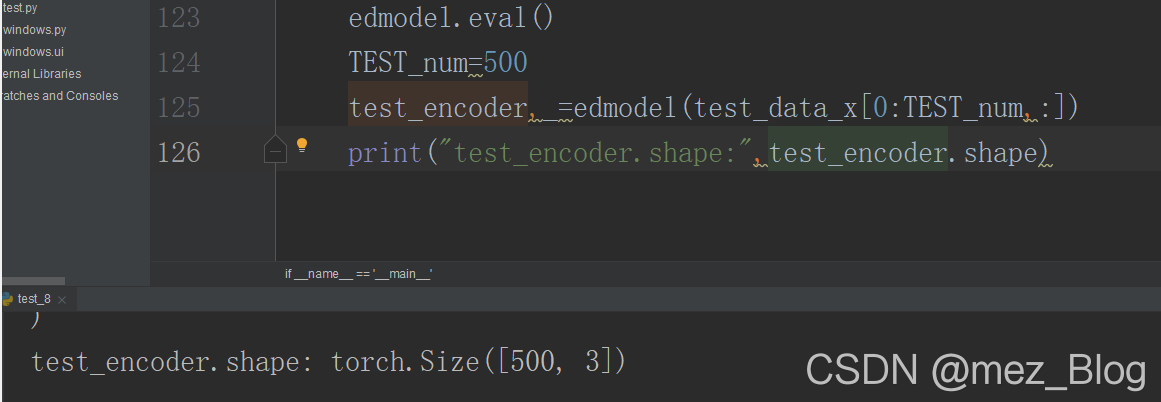
print("test_encoder.shape:",test_encoder.shape)
输出结果如下:
上面的程序是获取500张手写体图像特征编码数据test_encoder,并输出其维度,从输出结果可以发现test_encoder中每个图像的特征编码为三维数据。下面将这些图像在三维空间中的分布情况进行可视化,首先将张量转换为Numpy数组,然后定义每个样本点的X,Y,Z三个维度的坐标,可视化时使用ax1.text()方法在指定的坐标点上,添加每种类别图像的文本数据点,得到的三维可视化图像如下所示:
test_encoder_arr=test_encoder.data.numpy()
fig=plt.figure(figsize=(12,8))
ax1=Axes3D(fig)
X=test_encoder_arr[:,0]
Y = test_encoder_arr[:, 1]
Z = test_encoder_arr[:, 2]
ax1.set_xlim([min(X),max(X)])
ax1.set_ylim([min(Y), max(Y)])
ax1.set_zlim([min(Z), max(Z)])
for ii in range(test_encoder.shape[0]):
text=test_data_y.data.numpy()[ii]
ax1.text(X[ii],Y[ii,],Z[ii],str(text),fontsize=8,
bbox=dict(boxstyle="round",facecolor=plt.cm.Set1(text),
alpha=0.7))
# plt.show()
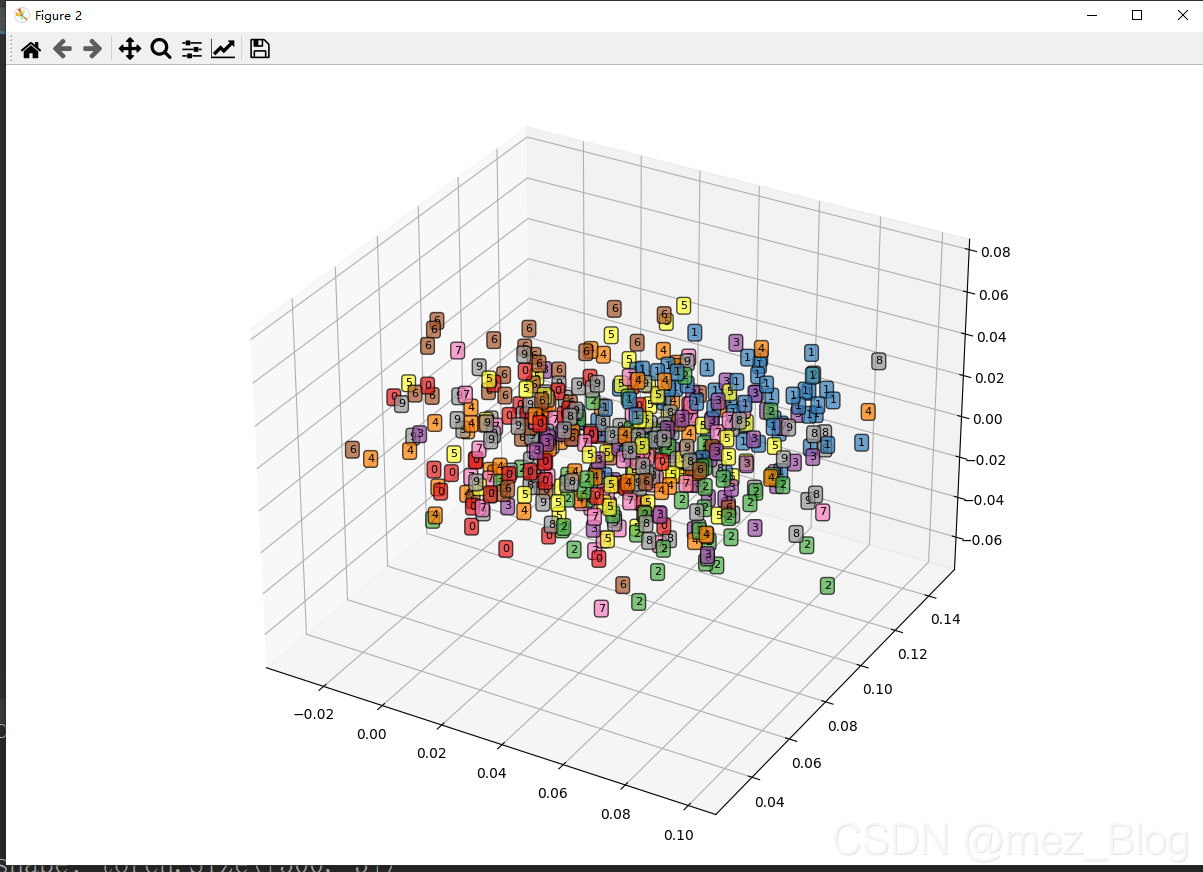
通过观察可以发现,不同类型的手写字体数据在三维空间中的分布都有一定的范围,而且数字1的分布和其它类型数据相比更加集中,而且在空间中和其它类型的数据距离较远,较容易识别,这和实际情况相符。
自编码网络的另一个作用就是对数据进行降维,保留数据中的主要信息的同时,减少数据的维度。当使用其他机器学习方法对特征编码进行分类时,自编码网络的作用是特征提取和变换的模型。下面使用自编码降维,将得到的特征与SVM分类器结合,或者使用主成分分析(PCA)降维到相同的维度与SVM分类器结合,将这两种不同的数据降维方式的效果进行对比,以确定哪种降维对数据分类更有效。
输入训练数据和测试数据,通过自编码网络后的输出特征和相应的类别标签数据,可使用如下所示的程序:
train_ed_x,_=edmodel(train_data_x)
train_ed_x=train_ed_x.data.numpy()
train_y=train_data_y.data.numpy()
test_ed_x,_=edmodel(test_data_x)
test_ed_x=test_ed_x.data.numpy()
test_y=test_data_y.data.numpy()
上述程序对训练集和测试集通过自编码网络提取对应特征编码,并且将数据从张量转化为数组。
针对主成分降维,用sklearn库中的PCA()函数,只保留3个主成分,程序如下:
pcamodel=PCA(n_components=3,random_state=10)
train_pca_x=pcamodel.fit_transform(train_data_x.data.numpy())
test_pca_x=pcamodel.transform(test_data_x.numpy())
print(train_pca_x.shape)
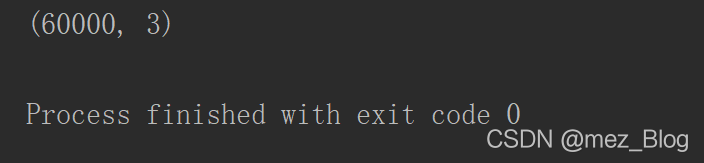
从程序输出中可以看出,数据已经成功降维到三维。在数据准备好后,分别针对两种类型的数据使用相同的参数,建立支持向量机分类器。
先对自编码网络降维的数据建立分类器,使用训练集train_ed_x和train_y对SVM分类器进行训练,然后利用测试集测试SVM分类器的分类精度,并使用accuracy_score()函数和classification_report()函数输出分类器在测试集上的预测效果,程序和结果如下所示:
上面结果显示,用自编码特征建立的SVM分类器在测试集上的预测精度为85.27%。而且每类数据的识别精度都很高,只有数字9、数字4和数字3的识别精度较低。
下面针对主要成分分析降维得到的特征,使用相同的方式在训练集上建立SVM分类器,并在测试集上进行预测,使用的程序和结果如下所示:
encodersvc=SVC(kernel="rbf",random_state=123)
encodersvc.fit(train_ed_x,train_y)
edsvc_pre=encodersvc.predict(test_ed_x)
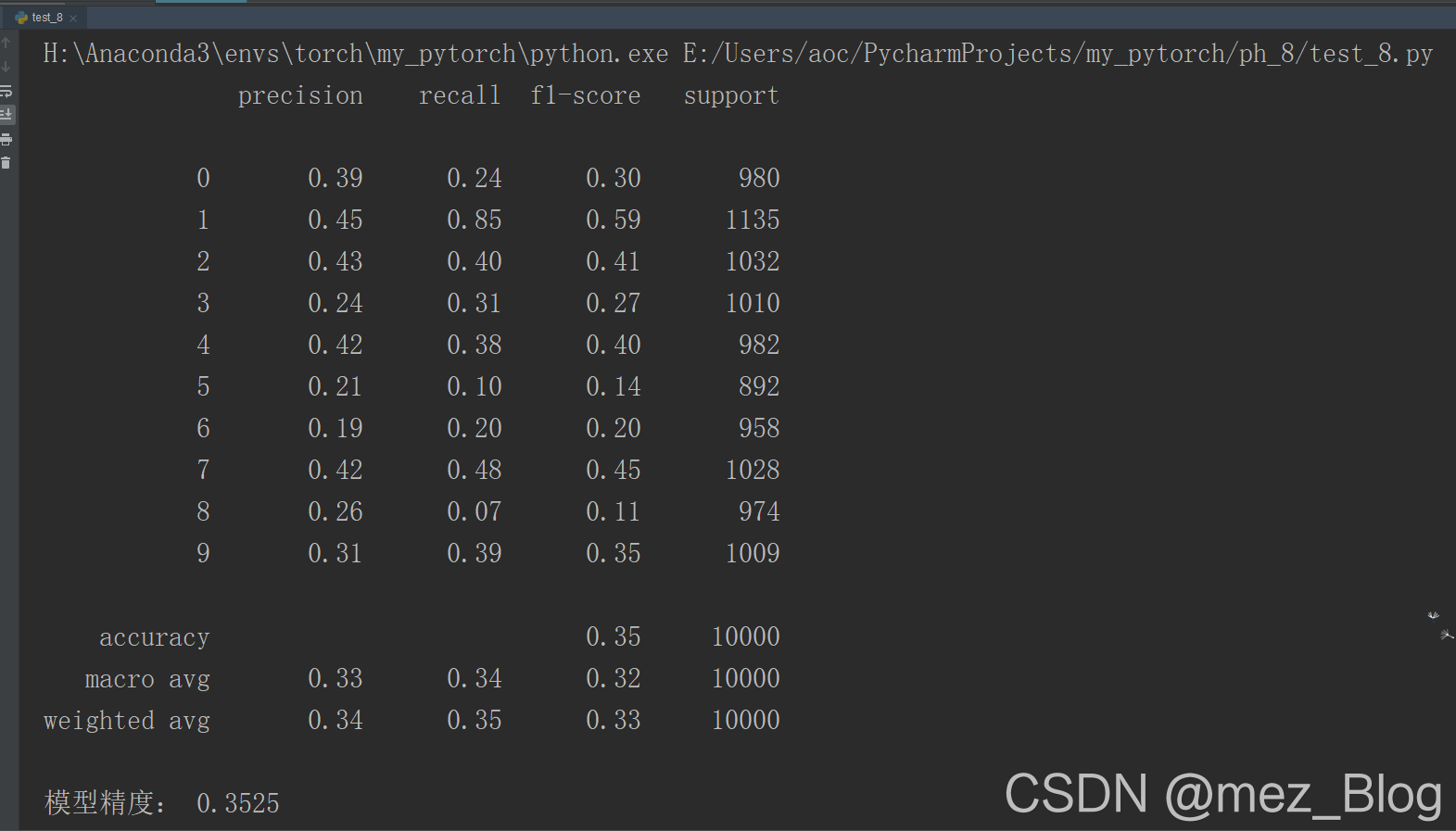
print(classification_report(test_y,edsvc_pre))
print("模型精度:",accuracy_score(test_y,edsvc_pre))
下面针对主要成分分析得到的特征,使用相同的方式在训练集上建立SVM分类器,并在测试集上进行预测,使用的程序和结果如下所示:
pcasvc=SVC(kernel="rbf",random_state=123)
pcasvc.fit(train_pca_x,train_y)
pcasvc_pre=pcasvc.predict(test_pca_x)
print(classification_report(test_y,pcasvc_pre))
print("模型精度",accuracy_score(test_y,pcasvc_pre))
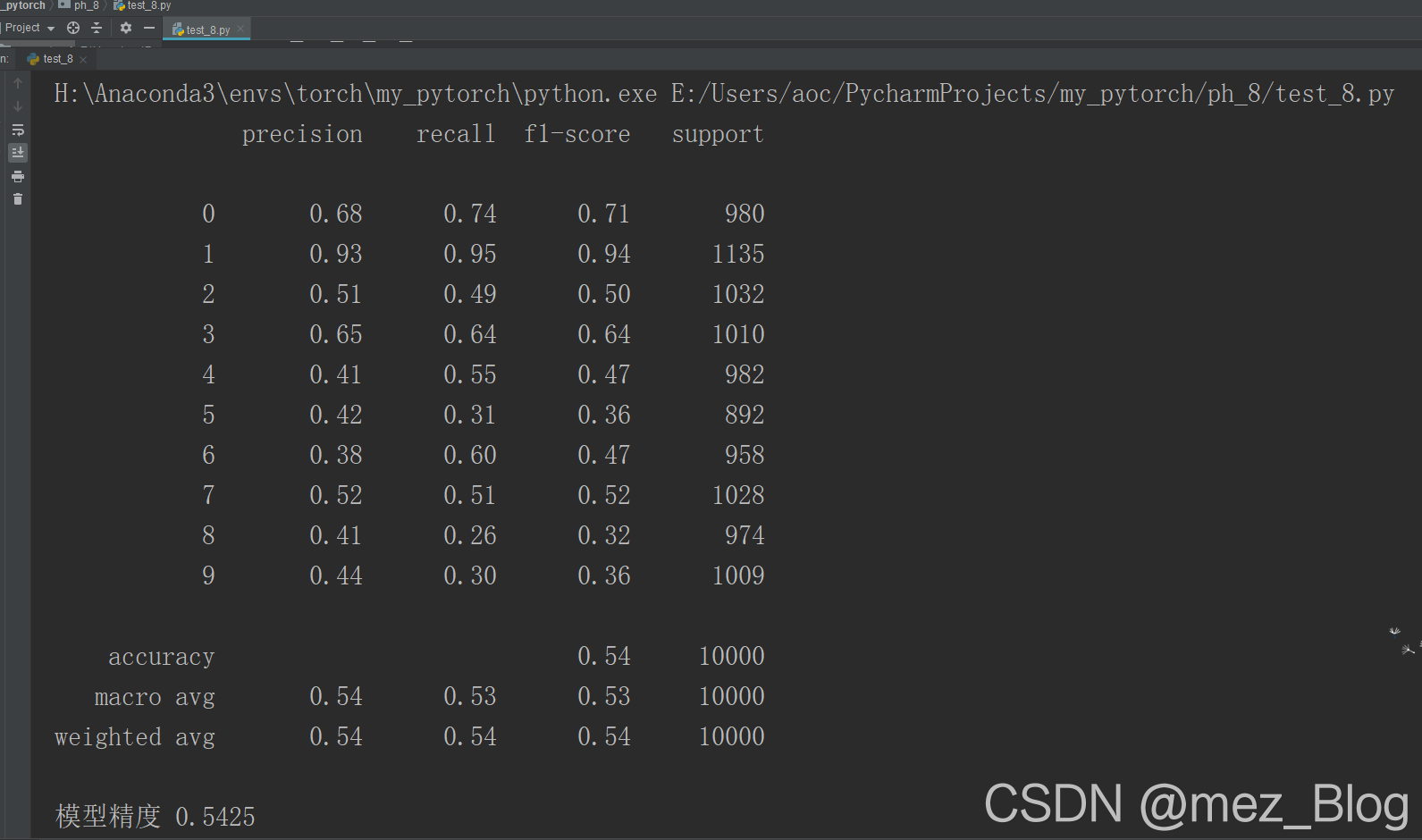
从输出结果中可以发现,使用PCA降维后训练得到的SVM分类器,预测精度只有54.26%,其精度比使用自编码网络得到的特征而训练的分类器精度低很多。而且每类数据的识别精度都不高,只有数字1的识别精度较高,超过了90%。
在介绍了基于线性层的自编码网络后,接下来使用基于卷积层的自编码去噪网络。利用卷积层进行图像的编码和解码,是因为卷积操作在提取图像的信息上有较好的效果,而且可以对图像中隐藏的空间信息等内容进行较好的提取。该网络可用于图像去噪、分割等。
在基于卷积的自编码图像去噪网络中,在网络中输入图像带有噪声,而输出图像则为去噪的原始图像,在编码器阶段,会经过多个卷积、池化、激活层和BatchNorm层等操作,在编码器阶段,会经过多个卷积、池化、激活层和batchNorm层等操作,逐渐降低每个特征映射的尺寸,如将每个特征映射编码尺寸降低到24*24,即图像的大小缩为原来的1/16;而特征映射编码的解码阶段,这可以通过多个转置卷积、激活层和batchNorm层等操作,逐渐将其解码为原始图像的大小并且包含3个通道的图像,即96*96的RGB图像。
为训练得到一个图像降噪自编码器,接下来使用实际的数据集,用Pytorch搭建一个卷积自编码网络,首先导入使用到的库和模块。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from skimage.util import random_noise
from skimage.measure import compare_psnr
import torch
from torch import nn
import torch.nn.functional as F
import torch.utils.data as Data
import torch.optim as optim
from torchvision import transforms
from torchvision.datasets import STL10
先简单介绍一下训练网络使用到的图像数据集-STL10,该数据集可以通过torchvision.datasets模块中的STL10()函数进行下载,该数据集共包含三种类型数据,分别是带有标签的训练集和验证集,分别包含5000张和8000张图像,共有10类数据,还有一个类型包含10万丈的无标签图像,均是96*96的RGB图像,可用于无监督学习。
虽然使用STL10()函数可直接下载该数据集,但数据大小仅约2.5GB,且下载的数据是二进制数据,故建议直接到数据网址(https://cs.stanford.edu/~acoates/stl10/)下载,并保存到指定文件夹。
为了节省时间和增加模型的训练速度,在搭建的卷积自编码网络中只是用包含5000张图像的训练集,其中使用4000张图像用来训练模型,剩余1000张图像作为模型的验证集。
在定义网络之前,首先准备数据,并对数据进行预处理。定义一个从.bin文件中读取数据的函数,并且将读取的数据进行预处理,便于后续的使用,程序如下所示:
def read_image(data_path):
with open(data_path,'rb') as f:
data1=np.fromfile(f,dtype=np.uint8)
images=np.reshape(data1,(-1,3,96,96))
images=np.transpose(images,(0,3,2,1))
return images/255.0
在上面读取图像数据的函数read_image()中,只需要输入数据的路径即可,在读取数据后会将图像转化为【数量,通道,宽,高】的形式。为了方便图像可视化,使用np.transpose()函数将图像转化为RGB格式,最后输出的像素值是在0-1之间的四维数组,第一位表示图像的数量,后面的三维表示图像的RGB像素值。
函数read_image()读取STL10数据的训练数据集train_X.bin程序如下。
data_path="F:/程序/programs/data/STL10/stl10_binary/train_X.bin"
images=read_image(data_path)
print("images.shape:",images.shape)
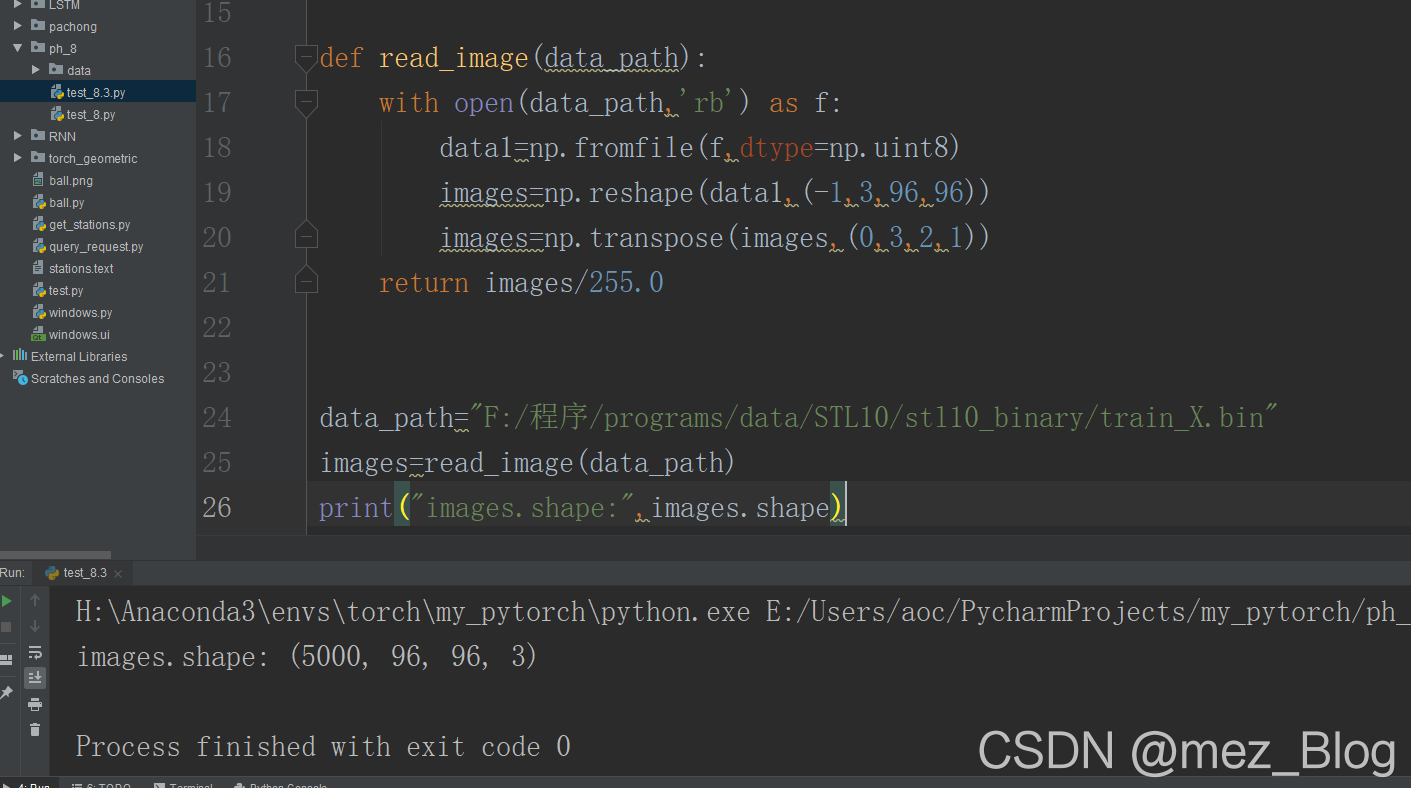
从程序的输出中可发现,共包含5000张图像,每个图像为96*96*3的RGB图像。
下面定义一个为图像数据添加高斯噪声的函数,为每一章图像添加随机噪声,程序如下所示:
def gaussian_noise(image,sigma):
sigma2=sigma**2/(255**2)
images_noisy=np.zeros_like(images)
for ii in range(images.shape[0]):
image=images[ii]
noise_im=random_noise(image,mode="gaussian",var=sigma2,clip=True)
images_noisy[ii]=noise_im
return images_noisy
images_noise=gaussian_noise(images,30)
print("images_noise:",images_noise.min(),"~",images_noise.max())
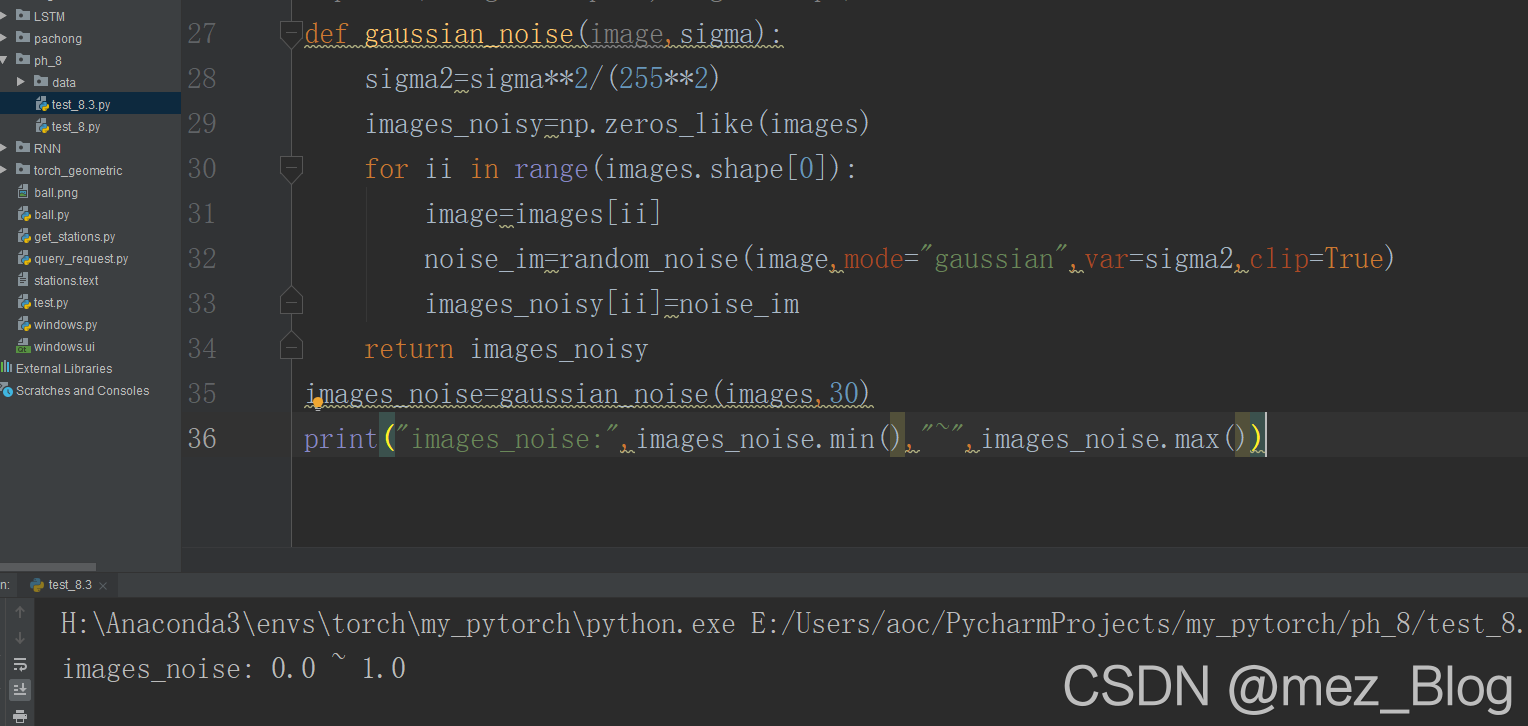
在gaussian_noise()函数中,通过random_noise()函数 为每张图像添加指定方差为sigma2的噪声,并且将带噪图像的像素值范围矗立在0~1之间,使用gaussian_noise()函数后,可得到带有噪声的数据集images_noise.并且从输出可知,所有像素值的最大值为1,最小值为0.









