什么是云计算
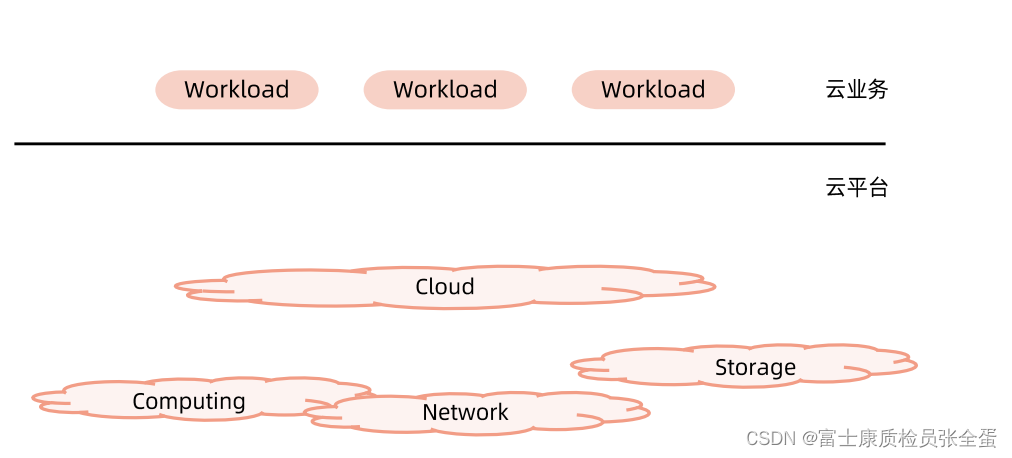
云计算平台分类
一openstack这种的云管平台,将很多物理机在这基础之上安装hypervisor,然后上面再启动一些虚拟机,然后再将这些虚拟机组成大的云平台,这是以openstack为例的,它最终的交付形态是一个一个的操作系统,在操作系统之上需要部署你的应用。
另外一类就是google的borg系统为主,它没有使用虚拟化技术,它的主要的实现方式是轻量级的作业调度,它调度的是一个一个的进程,Borg就是这样一个平台,Borg本身利用了容器技术,比如cgroup,就是Google开源给Linux的,
Borg架构
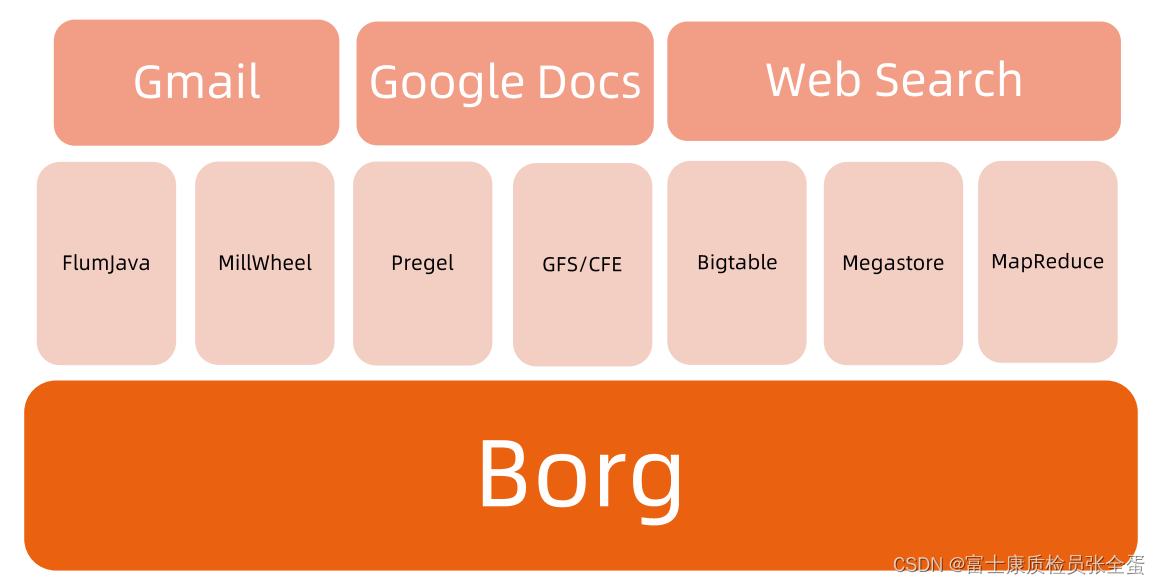
Borg主要支撑了两类业务,一类是生产业务,叫做production workload,比如邮箱服务,比如文档服务,还有一种是离线作业。
离线业务和在线业务有什么差别呢?在线业务要求高可用,要求永远在线,对资源的开销可能没有那么大,他不是大量消耗某些计算资源这种,除非负载非常大的时候。
离线业务一般是做批处理作业的,它对资源的开销会比较高,比如启动一个AI训练的时候它会疯狂的去吃CPU,离线作业的好处是对可用性的要求会稍微低,发起一个批处理作业的时候,你不能要求他马上返回,运行的时间可能几分钟,几小时,几天。所以对于离线作业的时效性要求低。
Google就是通过在线业务和离线业务混合部署方式,使得整个数据中心的资源利用率有本质上的提升。
Google Borg 简介
特性
- 物理资源利用率高。(没有使用虚拟化技术,不需要模拟操作系统,所有的资源都是用来做计算的)
- 服务器共享,在进程级别做隔离。
- 应用高可用,故障恢复时间短。
- 调度策略灵活。
- 应用接入和使用方便,提供了完备的 Job 描述语言,服务发现,实时状态监控和诊断工具。
有事21:
优势
- 对外隐藏底层资源管理和调度、故障处理等。(用户不需要管我怎么调度,只要告诉需要多少资源)
- 实现应用的高可靠和高可用。
- 足够弹性,支持应用跑在成千上万的机器上。
基本概念

Borg 架构
Borgmaster 主进程:(用来接收所有用户请求,请求提交给Rest API)
- 处理客户端 RPC 请求,比如创建 Job,查询 Job 等。
- 维护系统组件和服务的状态,比如服务器、Task 等。
- 负责与 Borglet 通信。
Scheduler 进程:(寻找一个最合适的机器,将作业调度过去)
调度策略:
- worst fit
- best fit
- hybrid
调度优化:
- Score caching: 当服务器或者任务的状态未发生变更或者变更很少时,直接采用缓存数据,避免重复计算。
- Equivalence classes: 调度同一 Job 下多个相同的 Task 只需计算一次。
- Relaxed randomization: 引入一些随机性,即每次随机选择一些机器,只要符合需求的服务器数量达到一定值时,就可以停止计算,无需每次对 Cel l中所有服务器进行 feasibility checking。
Borglet:(每个节点上面的代理,有好几个职责,第一个职责是将节点的计算资源和节点健康状态上报给master,调度器就可以从master里面获取集群所有节点的健康状态和资源的计算能力)
- Borglet 是部署在所有服务器上的 Agent,负责接收 Borgmaster 进程的指令。
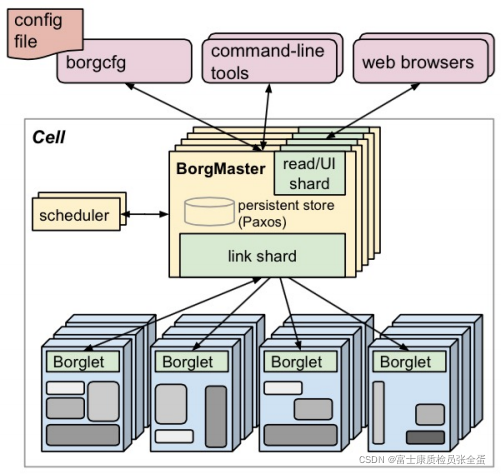
cell里面是一个集群,cell里面有成千上万的节点,这批节点会被分为两类,一类叫做管理节点。
master节点本身是不多的, 可能就几台master,其次就是worker节点,worker节点是用来真正跑业务的节点,master上面会提供interface,作业提交到master之后,会由scheduler调度器去工作。
它会按照资源需求,会去集群里面选择最适合运行作业的节点,完成调度之后,作业和节点就会产生绑定关系。
在每个节点上面会跑一个代理叫做borglet,borglet会去接受master的指令负责将这个应用启动起来,运行你的业务。
调度器就有很多模式和策略了,下面是调度器里面常用的概念和模式了
worst fit:调度器会去找这个集群里面,资源利用率最低的一个节点,也就是找一个最闲的节点给你,空闲的资源和你资源需求实际上是非常大的,这样其实就是永远使用集群当中资源利用率最低的节点,这样就使得集群节点的作业负载平均。
best fit:恰好满足你需求的节点,他会去找能够满足你需求的节点
应用高可用
- 被抢占的 non-prod 任务放回 pending queue,等待重新调度。
在线业务的命是高可用,一个业务失去了高可用那么就完全没法提供在线服务,这个后果是不可承担的。
在线业务要永远保持在线业务的高可用,比如你要去部署或者扩容在线业务,他就会为你这个在线业务去做调度,当集群里面没有可用资源了怎么办?那么就要去杀掉离线业务,会将离线业务的资源抢过来,将其应用杀掉,将这个资源交给在线业务,这样先让在线业务先跑,但是离线业务不能丢,所以会将离线业务放进pending queue,等什么时候有资源了再重新跑。这样即保证了在线业务的高可用,又保证了离线业务的作业不可丢。
- 多副本应用跨故障域部署。所谓故障域有大有小,比如相同机器、相同机架或相同电源插座等,一挂全挂。
高可用怎么来,高可用往往通过冗余部署来,比如服务平时需要一个副本,如果副本坏了那么这个服务就不是高可用的,要确保服务高可用可以多部署几份,前面配置负载均衡,如果后面有一个实例坏了,那么还有其他实例支撑着,但是冗余部署,这三个副本跑在一台机器上面,那么这个机器坏了,那么冗余部署是没有意义的。所以Borg提供了跨故障域的部署,包括跨节点,跨机架,跨可用区域。
- 对于类似服务器或操作系统升级的维护操作,避免大量服务器同时进行。
- 支持幂等性,支持客户端重复操作。
有些命令可以反复去敲的,不管你输入多少次,返回的都是统一的结果
- 当服务器状态变为不可用时,要控制重新调度任务的速率。因为 Borg 无法区分是节点故障还是出现了短暂的网络分区,如果是后者,静静地等待网络恢复更利于保障服务可用性。
- 当某种“任务 @ 服务器”的组合出现故障时,下次重新调度时需避免这种组合再次出现,因为极大可能会再次出现相同故障。
- 记录详细的内部信息,便于故障排查和分析。
- 保障应用高可用的关键性设计原则是:无论何种原因,即使 Borgmaster 或者 Borglet 挂掉、失联,都不能杀掉正在运行的服务(Task)。
Borg 系统自身高可用
• Borgmaster 组件多副本设计。
• 采用一些简单的和底层(low-level)的工具来部署 Borg 系统实例,避免引入过多的外部依赖。
• 每个 Cell 的 Borg 均独立部署,避免不同 Borg 系统相互影响。
资源利用率
通过在线和离线业务的混合部署,使得资源利用率非常的高,如果我们只跑在线,一定会有些问题,业务波谷的资源是空闲的,为了节省整个资源中心数据成本,
• 通过将在线任务(prod)和离线任务(non-prod,batch)混合部署,空闲时,离线任务可以充分利用计算资源,繁忙时,在线任务通过抢占的方式保证优先得到执行,合理地利用资源。
• 98% 的服务器实现了混部。
• 90% 的服务器中跑了超过 25 个 Task 和 4500 个线程。
• 在一个中等规模的 Cell 里,在线任务和离线任务独立部署比混合部署所需的服务器数量多出约 20%-30%。可以简单算一笔账,Google 的服务器数量在千万级别,按 20%算也是百万级别,大概能省下的服务器采购费用就是百亿级别了,这还不包括省下的机房等基础设施和电费等费用。
Borg 调度原理
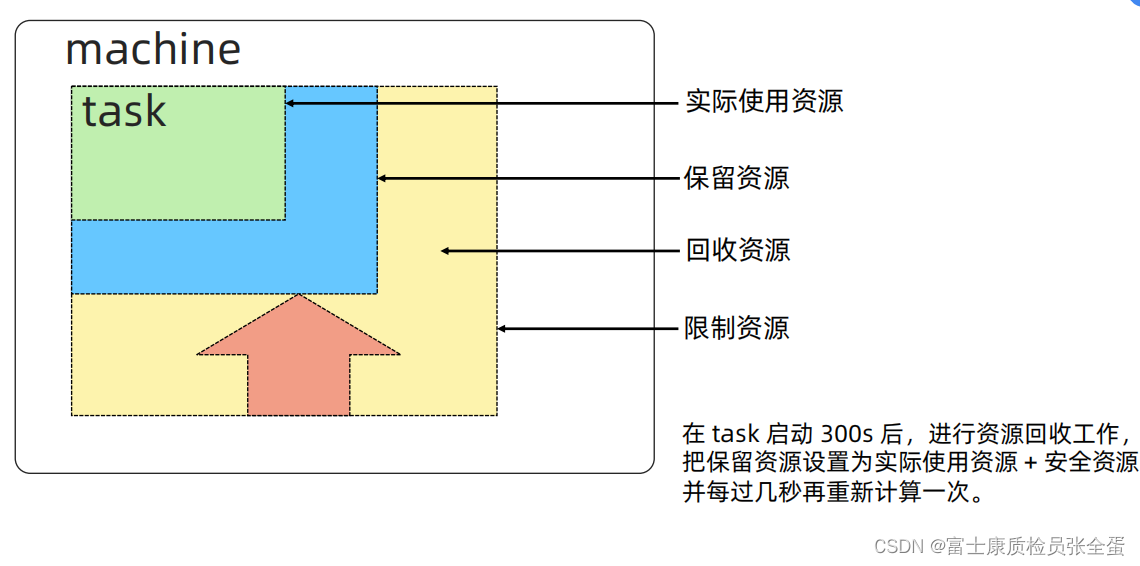
如果你是开发人员,你的任务除了写好业务逻辑,还可能想保证业务的高可用,这样就需要代码的健壮和留够足够的资源。
怎么样才算留够足够的资源?这就需要做压力测试,用了多少资源,或者基于现状去做一个压力测试看用了多少资源,然后在申请资源的时候,然后将这个预估的量给出来,因为可能突然来一个业务高峰要抗的住,所以要多申请一点资源。
但是多申请的资源如果没有业务高峰,那么都是浪费掉的,Borg实现了一种机制,Borg启动你的任务之后就需要去做不停的监控,看看到底使用了多少资源,大框是用户申请的资源,如果任务就使用了绿色框那么多资源,你们Borg就会去做回收,它以绿框再乘一个阈值比如1.2 1.3,作为你的保留资源,剩下黄色的部分全部回收掉,这样有效提升了整个集群资源的利用率,你可以声明很高,但是没有真实达到的时候会将声明的部分会收走的,这部分的资源交给其他人去使用。
隔离性
安全性隔离
- 早期采用Chroot jail,后期版本基于Namespace。
性能隔离
- 采用基于Cgroup的容器技术实现。
- 在线任务(prod)是延时敏感(latency-sensitive)型的,优先级高,而离线任务(non-prod,Batch)优先级低。
- Borg 通过不同优先级之间的抢占式调度来优先保障在线任务的性能,牺牲离线任务。· Borg将资源类型分成两类∶(从资源配额的维度看)
- 可压榨的(compressible),CPU是可压榨资源,资源耗尽不会终止进程(cpu是分时复用的原理,反正我就这么多cpu时间片,你告诉我应该怎么样去分配,每个人雨露均沾,每个人都给一点,这是可压榨资源,当竞争大的时候,那么大家一起按照预先分配的比例每个人都去分配一些,你的性能会慢一些,但是你的程序不会退出)
- 不可压榨的(non-compressible),内存是不可压榨资源,资源耗尽进程会被终止。
- 磁盘也是不可压榨资源,对于不可压榨资源,用尽了只能终止这个进程。
什么是 Kubernetes(K8s)?
Kubernetes 是谷歌开源的容器集群管理系统,是 Google 多年大规模容器管理技术 Borg的开源版本,主要功能包括:
• 基于容器的应用部署、维护和滚动升级(一个应用先跑3个实例,在升级的时候一个个滚动着升级,对用户来说这是无感知的,悄悄的就把版本换掉了)
• 负载均衡和服务发现
• 跨机器和跨地区的集群调度
• 自动伸缩(监控业务cpu等metrics,超过你设置的一些阈值的话,会自动做伸缩的)
• 无状态服务和有状态服务
• 插件机制保证扩展性
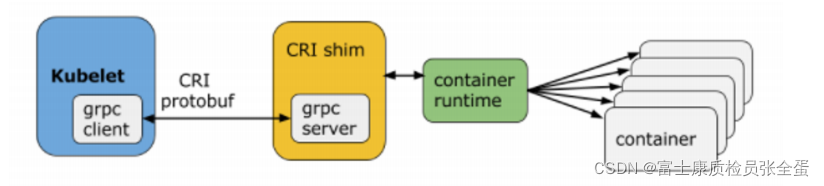
可以看到Kubernetes最终去运行应用的时候,这些应用都是容器化的应用,Kubernetes有核心的组件叫做kubelet,类似于Borglet,它会去调用CRI的接口,通过runtime运行时将一个一个容器进程运行起来。
命令式( Imperative)vs 声明式( Declarative)
声明式系统关注“做什么”
在软件工程领域,声明式系统指程序代码描述系统应该做什么而不是怎么做。仅限于描述要达到什么目的,如何达到目的交给系统。

所谓声明式系统是你将请求提交给这个平台,然后这个平台记录下来,在后台不断慢慢的调整系统当前状态和你期望的状态一致。
声明式系统更多的是对你的期望是什么,剩下的交给系统去管理,中间过程我不关心。
命令式系统关注 “如何做”
在软件工程领域,命令式系统是写出解决某个问题,完成某个任务,或者达到某个目标的的明确步 骤。此方法明确写出系统应该执行某指令,并且期待系统返回期望结果。
命令式就是要你做什么,每一步都得告诉清楚,而且要严格按照所说的做,就比如遥控器,你跳台的时候,或者调整音量的时候,你按一下遥控器它就变一下,这种特性是响应比较快,你给他一个指令就立马返回,基于这个返回再去做下一步的指示。


Kubernetes:声明式系统
Kubernetes 的所有管理能力构建在对象抽象的基础上,核心对象包括:
• Node:计算节点的抽象, 用来描述计算节点的资源抽象,健康状态等;
• Namespace:资源隔离的基本单位,可以简单理解为文件系统中的目录结构(对于不同的用户可以通过权限控制来决定用户可以访问哪个namespace,这样也是可以说是资源隔离,每个用户访问特定命名空间下的资源)
• Pod:用来描述应用实例,包括镜像地址,资源需求等。 Kubernetes 中最核心的对象,也是打通
应用和基础架构的秘密武器;
• Service:服务如何将应用发布成服务,本质上是负载均衡和域名服务的声明。
声明式系统,提供一些API,这些API接收的收声明,可以将期望的状态告诉API,接下来将状态存储到数据库里面,相当于可以做一个持久化,这样就知道系统任何长什么样的,可以有个追述。
对于实时系统,可以以阻塞的方式,你敲一条命令,让其给你一个respones,但是对于分布式的系统,如果每个请求都是阻塞的,那么整个平台效率都不会高的。阻塞的话意味着CPU就等在那了,即使有CPU被人也没有办法获得CPU。
声明式系统更多的是将声明告诉你,然后告诉你期望值,然后一直去满足我的需求,只需要返回一个接收到我的声明式请求就行了。对于客户端就是非阻塞的,就可以去做其他事情,这样就有利于提高整个平台的效率。
之所以定义了这些对象,除了有一个声明式系统,同时跟业界的各个公司一起定规范,形成了一个统一的API,这套API就是云原生以后统一的API。










