数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
2020年春节期间,一场突如其来的疫情在全国蔓延开来,打破了大家原有的工作生活节奏。疫情期间,大家宅在家就能随时看到实时的大数据疫情地图,可以随时刷到自己当前感兴趣的抖音视频,这一切背后依赖的最重要的技术,就是实时大数据处理技术。
现在疫情即将过去,国家提出要加快大数据中心等新型基础设施建设,实时大数据处理平台建设成为企业数智化转型过程中越来越重要的部分。
一、什么是实时计算
在大数据处理领域,通常根据数据的不同性质,将任务划分为实时计算与离线计算,以温度传感器的场景举例:假设某城市安装了大量的温度传感器,每个传感器每隔1min上传一次采集到的温度信息,由气象中心统一汇总,每隔5分钟更新一次各个地区的温度,这些数据是一直源源不断的产生的,且不会停止。实时计算就主要用于“数据源源不断的产生,而且不会停止,需要以最小的延迟获得计算结果”的场景,这种最小的延迟通常为秒级或分钟级。
为了满足这种数据量很大,而且实时性要求又非常高的场景,通常会采用实时计算技术,实时计算的“数据源源不断”的特定决定了其数据处理方式与离线是截然不同的。
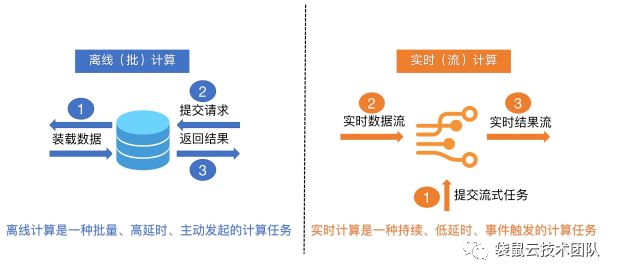
Figure 1 实时计算和离线计算的区别
离线计算的批量、高延时、主动发起的计算特点不同,实时计算是一种持续、低延时、事件触发的计算任务。离线计算需要先装载数据,然后提交离线任务,最后任务计算返回结果;实时计算首先要提交流式任务,然后等实时流数据接入,然后计算出实时结果流。
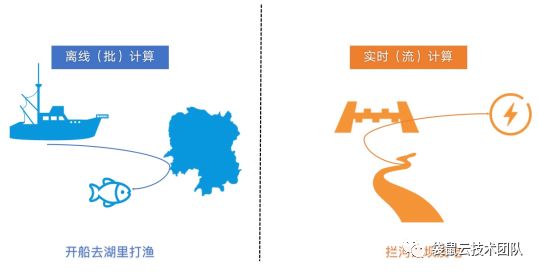
Figure 2 实时计算和离线计算的区别(形象图)
形象点可以理解为离线计算是开着船去湖里(数据库)打渔,实时计算为在河流(数据流)上建立大坝发电。进一步发散,湖泊的形成依赖河流,河流确定上下边界就是湖泊;其实,离线计算可以理解为实时计算的一种特例。
二、实时计算能解决的问题
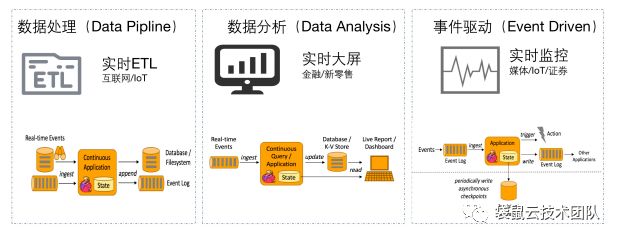
Figure 3 实时计算能解决的问题
从技术领域来看,实时计算主要用于以下场景:
- 基于Data Pipline的实时数据ETL:目的是实时地把数据从A点传输到B点。在传输的过程中可能添加数据清洗和集成的工作,例如实时构建搜索系统的索引、实时数仓中的ETL过程等。
- 基于Data Analysis的实时数据分析:根据业务目标,从原始数据中抽取对应信息并整合的过程。例如,查看每天销售额排行前10的商品、仓库平均周转时间、网页平均点击率、实时推送打开率等。实时数据分析则是上述过程的实时化,通常在终端体现为实时报表或实时大屏。
- 基于Data Driven的事件驱动应用:对一系列订阅事件进行处理或作出响应的系统。事件驱动应用通常需要依赖内部状态,例如点击欺诈检测、风控系统、运维异常检测系统等。当用户的行为触发某些风险控制点时,系统会捕获这个事件,并根据用户当前和之前的行为进行分析,决定是否对用户进行风险控制。
三、实时开发的全链路流程
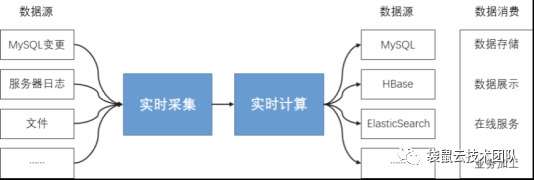
Figure 4 实时开发的全链路流程
实时采集——使用流式数据采集工具将数据流式且实时地采集并传输到大数据消息存储(kafka等),流式数据存储作为实时计算的上游,提供源源不断的数据流去触发流式计算作业的运行。流数据作为实时计算的触发源驱动实时计算运行。因此,一个实时计算作业必须至少使用一个流数据作为源。每一条进入的流数据将直接触发实时计算的一次流式计算处理。数据在实时计算系统中处理分析后随机写到下游数据存储,下游数据库一般与业务相关,可以用来做实时报表、实时大屏等数据消费。
四、实时采集---全链路实时开发平台的关键
整个全链路的实时开发中,实时采集是实时计算的上游。对于很对企业而言,本身已经有数据存储系统,但是很大一部分都是离线的关系型数据库。如何将这些离线的关系型数据库的实时增量数据,提供给实时计算去分析,是一个亟需解决的环节。如下图所示,是袋鼠云实时数据采集工具的功能架构。
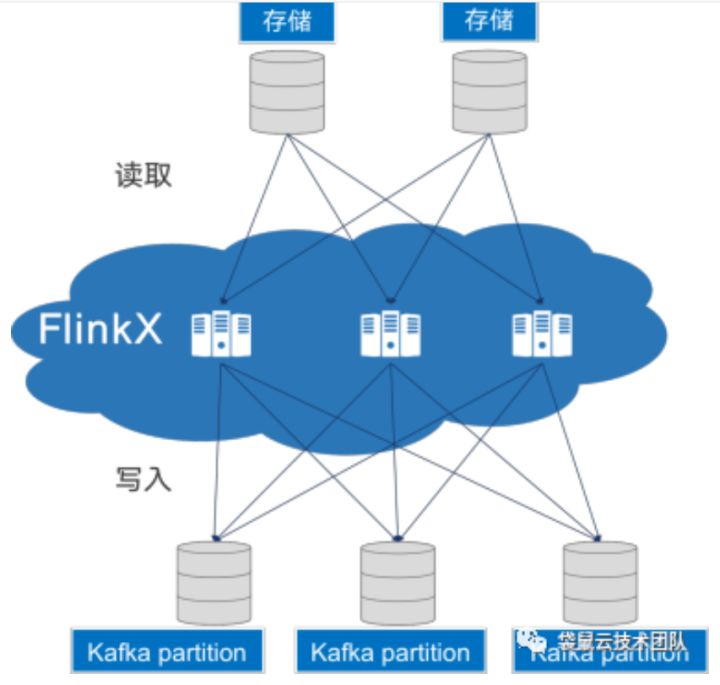
Figure 5 实时数据采集工具FlinkX数据流程
袋鼠云实时数据采集作为StreamWorks平台的一个模块,有以下功能特点。
- FlinkX支持批量数据抽取,同时支持实时捕捉MySQL、Oracle、SQLServer等变化数据,实现批流统一采集。
- 底层基于Flink分布式架构,支持大容量、高并发同步,相比单点同步性能更好,稳定性更高。
- 支持直接读取数据库Binlog的方式实时同步,也支持间隔轮询方式实时同步。
- 支持断点续传和脏数据记录,实时数据采集的metric曲线展示。
五、StreamWorks实时开发平台介绍
袋鼠云实时开发平台(StreamWorks)基于 Apache Flink 构建的云原生一站式大数据流式计算平台,涵盖从实时数据采集到实时数据ETL的全链路流程。亚秒级别的处理延时, Datastream API 作业开发,与已有大数据组件兼容,帮助企业实时数据智能化转型,助力新型基础设施建设。
在以往的数据开发技术栈中,SQL语言能解决大部分业务场景的问题。StreamWorks的核心功能是主打以SQL语义的流式数据分析能力(FlinkStreamSQL),降低开发门槛。提供Exactly-Once的处理语义保证,保证业务精确一致。
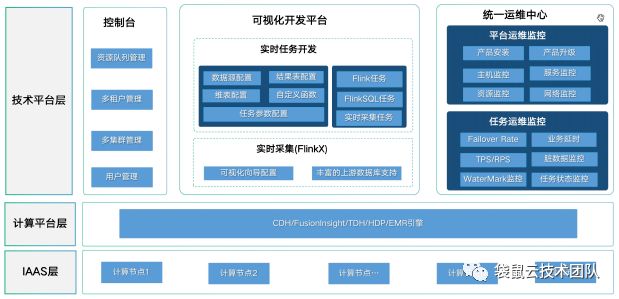
Figure 6 StreamWorks功能架构
如上图所示,StreamWorks包含如下几个模块:
- 实时采集:支持MySQL、SQLServer、Oracle、PolarDB、Kafka、EMQ等数据源实时数据采集,通过速率和并发数控制可帮助用户更准确的控制采集过程。
- 数据开发:支持FlinkSQL、Flink任务类型,FlinkSQL作业提供可视化存储配置、作业开发、语法检查等功能;Flink任务支持上传jar包的方式运行实时开发作业。
- 任务运维:任务运行情况监控,数据曲线、运行日志、数据延时、CkeckPoint、Failover、属性参数、告警配置等功能。
- 项目管理: 用户管理、角色管理、项目整体配置、项目成员管理等。
六、StreamWorks实时大数据开发平台的优势
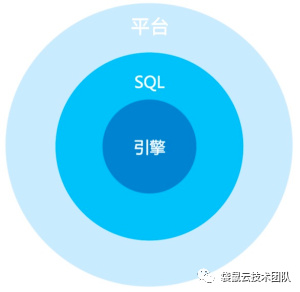
Figure 7 StreamWorks平台层级
如上图所示,StreamWorks实时大数据开发平台基于Apache Flink计算引擎,做了一层SQL化的封装,最上层有一个在线开发的IDE平台。平台有以下几个优势点:
- 简单易用: 提供在线IDE,定制化适配FlinkSQL的开发工具!
- 可视化DDL:提供可视化建表工具,配置参数即可完成DDL!
- 内置函数:提供丰富的FlinkSQL内置函数,简化开发工作!
- 高效运维: 提供多达几十个运行指标,解决开源运维难题!
- 实时采集:提供实时采集工具,支撑全链路实时开发平台!
- FlinkX:自研的批流一体的数据采集工具,已经开源!
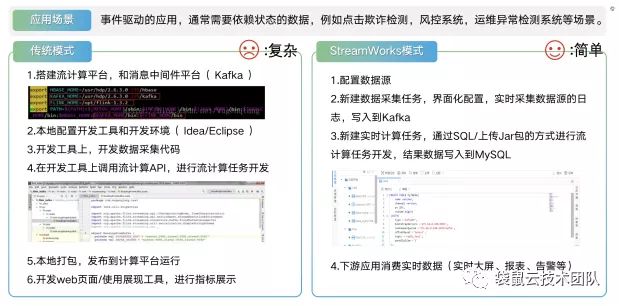
Figure 8 传统开发模式 VS StreamWorks开发模式
七、十四行代码搞定实时业务开发
讲了这么多,我们的产品到底如何方便大家进行实时业务逻辑开发的,我们还是拿最常见的网站流量分析的例子说明下。比如,某网站需要对访问来源进行分析:
如下图所示,从日志服务读取该站点访问日志,解析日志中的来源并检查来源是否在感兴趣的网站列表中(类似来源网站的白名单,保存在MySQL中),统计来自各个网站的流量PV,最终结果写出到MySQL。
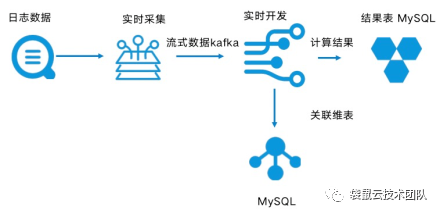
Figure 9 业务逻辑流程图
用StreamSQL代码实现的话非常简单,只需要14行伪代码即可搞定。
CREATE TABLE
log_source(dt STRING, …)
WITH (type=kafka);
CREATE TABLE
mysql_dim(url STRING, …, PRIMARY KEY(url))
WITH (type=mysql);
CREATE TABLE
mysql_result(url STRING, …, PRIMARY KEY(url))
WITH (type=mysql);
INSERT INTO mysql_result
SELECT
l.url, count(*) as pv …
FROM log_source l JOIN mysql_dim d ON l.url = d.url
group by l.url
八、基于StreamWorks构建实时推荐系统
一般的推荐系统都是基于标签来实现的,基于标签的推荐其实应用很普遍,比如头条,比如抖音,都用到了大量的标签,这样的推荐系统有很多优点,比如实现简单、可解释性好等。如何通过标签来实现实时商品或者内容的推荐呢?
首先一个新的用户在注册app账号的时候会填写一些比较固定的数据,比如年龄、职业等信息,这些信息可以通过离线计算分析出长期兴趣标签的结果,存储到长期兴趣标签库。用户在最近感兴趣的内容(比如最近10分钟内关注的信息点)可以通过实时计算分析出短期的兴趣标签结果,然后再通过实时开发的数据流关联维表的功能,把短期的感兴趣标签和长期兴趣标签库做关联,最终生成新的推荐内容给到客户端,形成一个用户数据流的闭环,从而实现一个简单的实时推荐系统。具体流程如下图所示。
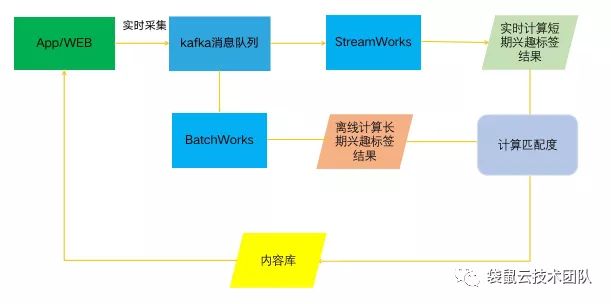
Figure 10 基于StreamWorks构建实时推荐系统
九、结语——把未来变成现在
疫情即将过去,生活还要继续。随着“新基建”建设不断深化下去,越来越多的实时化场景会出现在我们生活中。袋鼠云作为新基建解决方案供应商,我们的口号就是把未来变成现在,在未来会赋能更多的企业实时化转型。










