爬虫的基本操作
爬虫基础知识
什么是爬虫?
在最开始,还没有诞生Google和百度等一系列搜索引擎的公司的时候,人们进入一些公司的网站只能通过在浏览器地址栏输入网址的方式访问,如同在很早之前前手机不流行的时候,我们会把各个好友的电话号码抄写在一个电话本上一样将各个公司的网站记录在文档中,很不方便。
当搜索引擎公司出现的时候,这些搜索引擎公司来做了一个大黄页,把所有网站的网址搜集起来,用户不用和各个公司打交道,而是直接和搜索引擎公司打交道,让搜索引擎帮助自己在它自己制作的大黄页中找出用户需要的内容返回给用户使用。简单点说,就是公司把信息交给搜索引擎公司,让搜索引擎公司在有用户需要本公司信息的时候提交给用户。
搜索引擎公司搜集数据不光是公司或个人主动上传,主要还会通过网络爬虫爬去网上信息并且提取出关键字更网友搜索。
整个网络可以理解为通过a标签链接起来的蜘蛛网,可以在网络中获取任何信息。
爬虫的作用就是搜集网络信息为我所用。
爬虫的分类
定向爬虫:只爬取某一个或某几个网站,根据自己的需要有专一目的性爬取。
非定向爬虫:随机爬去整个网络的网站,见什么爬什么。
爬虫爬取大体步骤
假设我们爬取“汽车之家”的相关数据:https://www.autohome.com.cn/news/

下载页面:
请求网站:https://www.autohome.com.cn/news/ ,返回的为 HTML 页面字符串。
筛选信息:
使用正则表达式筛选出我们需要的信息。(python非常牛逼的是有大神把正则表达式写好了,都在开源模块里边了。)
开源模块使用的简单案例
# __author : "王佳伟"
# date : 2019-01-16
import requests
from bs4 import BeautifulSoup
# 1.request 模块
respone = requests.get("https://www.autohome.com.cn/news/")
respone.text
# 2.BeautifulSoup 模块
soup = BeautifulSoup(respone.text, features='html.parser') # 把HTML文本转换为对象
target = soup.find(id='auto-channel-lazyload-article')
print(target)爬取汽车之家数据案例
爬取汽车之家新闻列表的标题即链接
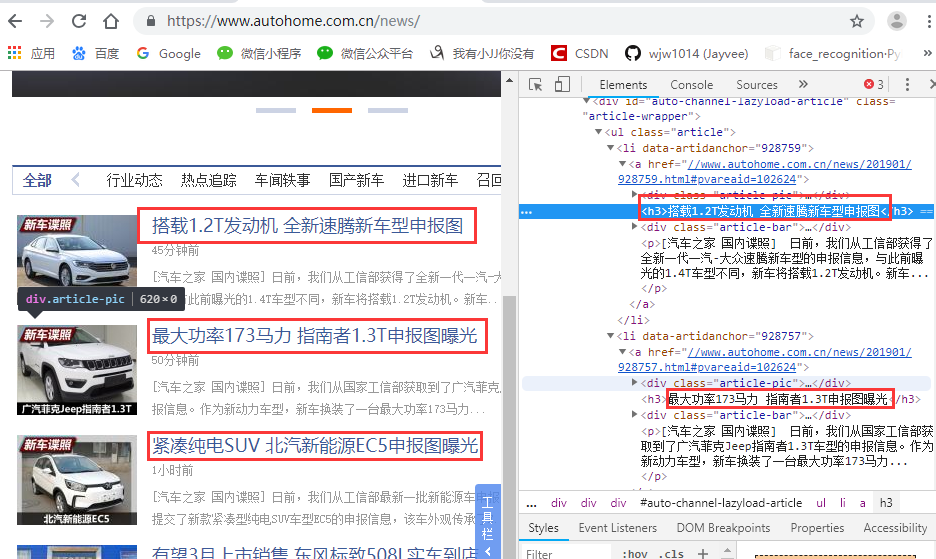
1 # __author : "王佳伟"
2 # date : 2019-01-16
3
4 import requests
5 from bs4 import BeautifulSoup
6
7 # 1.request 模块
8
9 # 下载目标网站的HTML源码
10 response = requests.get(
11 url="https://www.autohome.com.cn/news/"
12 )
13 # 编码查看网页头
14 # respone.encoding='gb2312'
15 # 拿到文本并转换为网页自己的编码
16 response.encoding = response.apparent_encoding
17 # print(response.text)
18
19 # 2.BeautifulSoup 模块
20
21 # 把HTML文本转换为对象,features表示以什么引擎处理 html.parser / lxml
22 soup = BeautifulSoup(response.text, features='html.parser')
23 # 根据id属性找,找到对象中 id = auto-channel-lazyload-article 的标签
24 target = soup.find(id='auto-channel-lazyload-article')
25 # 打印输出
26 # print(target)
27 # 根据标签找 找到所有标签为li的所有标签
28 li_list = target.find_all('li')
29 # print(obj)
30
31 # 循环列表
32 for i in li_list:
33 # 找到每个li标签中包含的a标签
34 # a = i.find('a')
35 # print(a)
36 a = i.find('a')
37 if a:
38 # print(a.attrs) # 找到a标签的所有属性
39 print(a.attrs.get('href')) # 找到a标签的href属性
40 txt = a.find('h3') # 获取a标签中的h3标签
41 print(txt)
42 # print(txt.text) 
爬取下载汽车之家新闻列表的图片
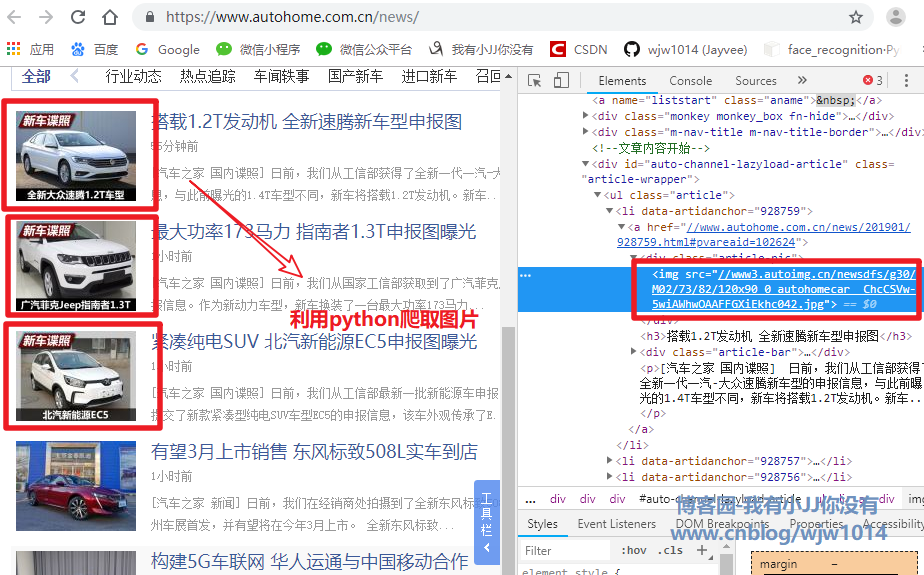
1 # __author : "王佳伟"
2 # date : 2019-01-16
3
4 import requests
5 from bs4 import BeautifulSoup
6
7 # 1.request 模块
8
9 # 下载目标网站的HTML源码
10 response = requests.get(
11 url="https://www.autohome.com.cn/news/"
12 )
13 # 编码查看网页头
14 # respone.encoding='gb2312'
15 # 拿到文本并转换为网页自己的编码
16 response.encoding = response.apparent_encoding
17 # print(response.text)
18
19 # 2.BeautifulSoup 模块
20
21 # 把HTML文本转换为对象,features表示以什么引擎处理 html.parser / lxml
22 soup = BeautifulSoup(response.text, features='html.parser')
23 # 根据id属性找,找到对象中 id = auto-channel-lazyload-article 的标签
24 target = soup.find(id='auto-channel-lazyload-article')
25 # 打印输出
26 # print(target)
27 # 根据标签找 找到所有标签为li的所有标签
28 li_list = target.find_all('li')
29 # print(obj)
30
31 # 循环列表
32 for i in li_list:
33 # 找到每个li标签中包含的a标签
34 # a = i.find('a')
35 # print(a)
36 a = i.find('a')
37 if a:
38 # print(a.attrs) # 找到a标签的所有属性
39 # print(a.attrs.get('href')) # 找到a标签的href属性
40 txt = a.find('h3') # 获取a标签中的h3标签
41 # print(txt)
42 print(txt.text)
43 # 找a标签中的img标签的src属性
44 img_url = a.find('img').attrs.get('src')
45 print(img_url)
46 # 下载图片
47 img_response = requests.get(url='https:'+img_url)
48 # 设置文件名
49 import uuid
50 # 随机生成文件名
51 file_name = str(uuid.uuid4()) + '.jpg'
52 with open(file_name,'wb') as f:
53 f.write(img_response.content) 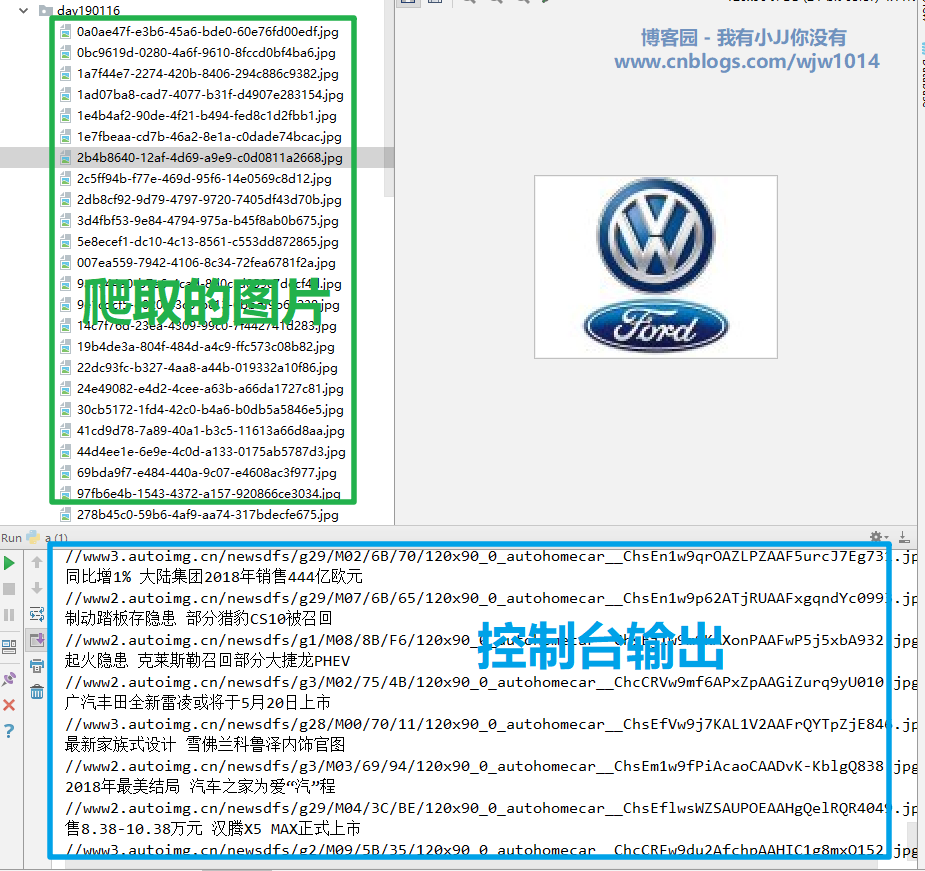
总结
requests 模块的使用
# 导包
import requests
# 爬取那个网站,填写URL地址
response = requests.get('URL')
# 获取对象的文本内容
response.text
# 获取图片/视频内容
response.content
# 设置编码
response.encoding
# 获取网站自己的编码类型
response.apparent_encoding
# 获取状态码
response.status_code
BeautifulSoup 模块的使用
# 导包
from bs4 import BeautifulSoup
# 获取对象
soup = BeautifulSoup('<html>......</html>', features='html.paeser')
# 找到它孩子第一个符合条件的第一个div
v1 = soup.find('div')
# 找它孩子中第一个 id = d1 的标签
v1 = soup.find(id='d1')
# 找到它孩子第一个id=d1的div
v1 = soup.find('div', id='d1')
# 用法同find,找所有,返回值为列表
v2 = soup.find_all('div')
v2 = soup.find_all(id='d1')
v2 = soup.find_all('div', id='d1')
obj = v1
obj = v2[0]
# 获取值
obj.text
# 获取属性
obj.attrs
# 获取属性值
obj.attrs.get('属性')
完成!
【版权声明】本博文著作权归作者所有,任何形式的转载都请联系作者获取授权并注明出处!
【重要说明】本文为本人的学习记录,论点和观点仅代表个人而不代表当时技术的真理,目的是自我学习和有幸成为可以向他人分享的经验,因此有错误会虚心接受改正,但不代表此刻博文无误!
【Gitee地址】秦浩铖:https://gitee.com/wjw1014









