最近在处理下载支付宝账单的需求,支付宝都有代码示例,功能完成还是比较简单的,唯一的问题就在于下载后的文件数据读取。账单文件可大可小,要保证其可用以及性能就不能简单粗暴的完成开发就行。
文件下载是是csv格式,此文件按照行读取,每一行中各列数据直接用逗号,隔开的。
前置设置:
- 开启了设置内存大小以及GC日志输出配置
-Xms800m -Xmx800m -XX:+PrintGCDetails - 测试文件
total-file.csv数据量: 100万,文件大小:176M - 定义账单文件的属性字段:
private static final List<String> ALI_FINANCE_LIST = new ArrayList<>(
Arrays.asList("FINANCE_FLOW_NUMBER", "BUSINESS_FLOW_NUMBER", "MERCHANT_ORDER_NUMBER", "ITEM_NAME", "CREATION_TIME", "OPPOSITE_ACCOUNT", "RECEIPT_AMOUNT", "PAYMENT_AMOUNT", "ACCOUNT_BALANCE", "BUSINESS_CHANNEL", "BUSINESS_TYPE", "REMARK"));
相关推荐阅读:
图形化监控工具JConsole
虚拟机的日志和日志参数
第一版:简单粗暴
直来直往,毫无技巧
拿到文件流,直接按行读取,把所有的数据放入到List<Map<String, Object>>中(其中业务相关的校验以及数据筛选都去掉了)
代码如下
@ApiOperation(value = "测试解析-简单粗暴版")
@GetMapping("/readFileV1")
public ResponseEntity readFileV1(){
File file = new File("/Users/ajisun/projects/alwaysCoding/files/total-file.csv");
List<Map<String, Object>> context = new ArrayList<>();
try (
InputStream stream = new FileInputStream(file);
InputStreamReader isr = new InputStreamReader(stream, StandardCharsets.UTF_8);
BufferedReader br = new BufferedReader(isr)
) {
String line = "";
int number = 1;
while ((line = br.readLine()) != null) {
//去除#号开始的行
if (!line.startsWith("#")) {
if (number >= 1) {
//csv是以逗号为区分的文件,以逗号区分
String[] columns = line.split(",", -1);
//构建数据
Map<String, Object> dataMap = new HashMap<>(16);
for (int i = 0; i < columns.length; i++) {
//防止异常,大于预定义的列不处理
if (i > ALI_FINANCE_LIST.size()) {
break;
}
dataMap.put(ALI_FINANCE_LIST.get(i), columns[i].trim());
}
context.add(dataMap);
}
number++;
}
}
// TODO 存表
System.out.println("=====插入数据库,数据条数:"+context.size());
System.out.println("对象大小:"+(ObjectSizeCalculator.getObjectSize(context)/1048576) +" M");
context.clear();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
输出日志以及Jconsole的监控如下
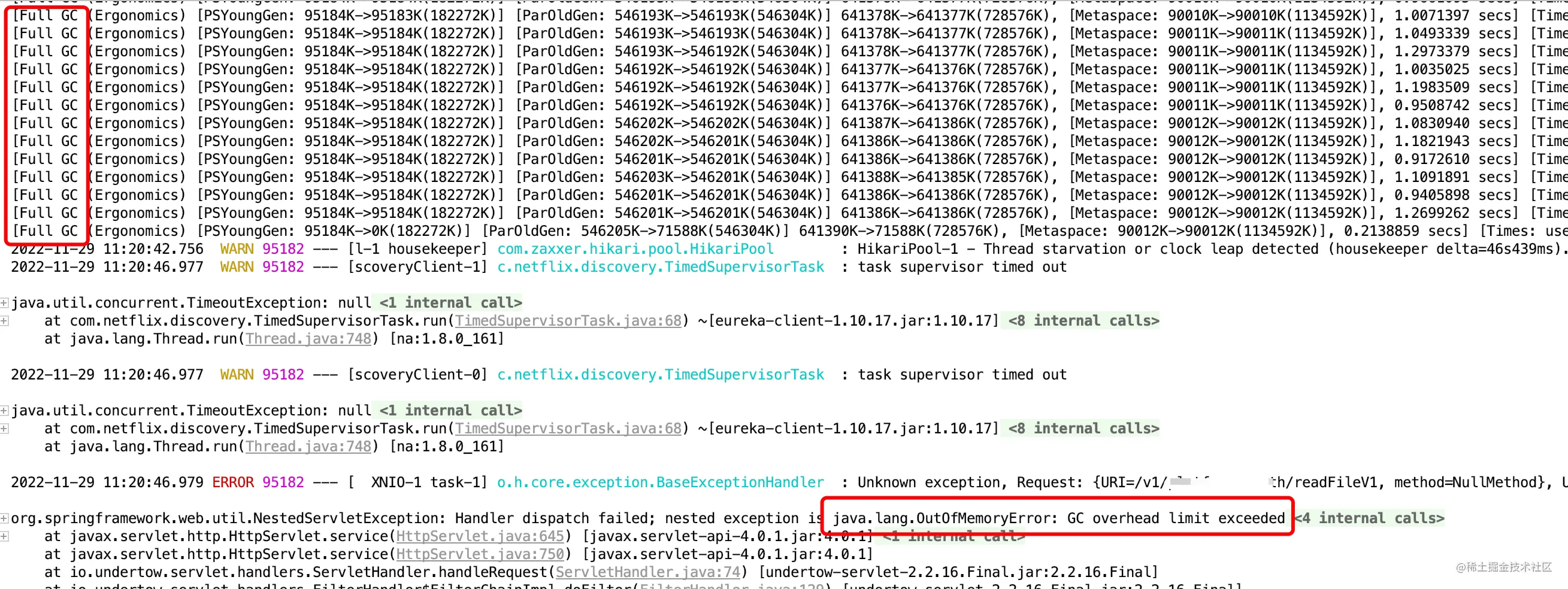
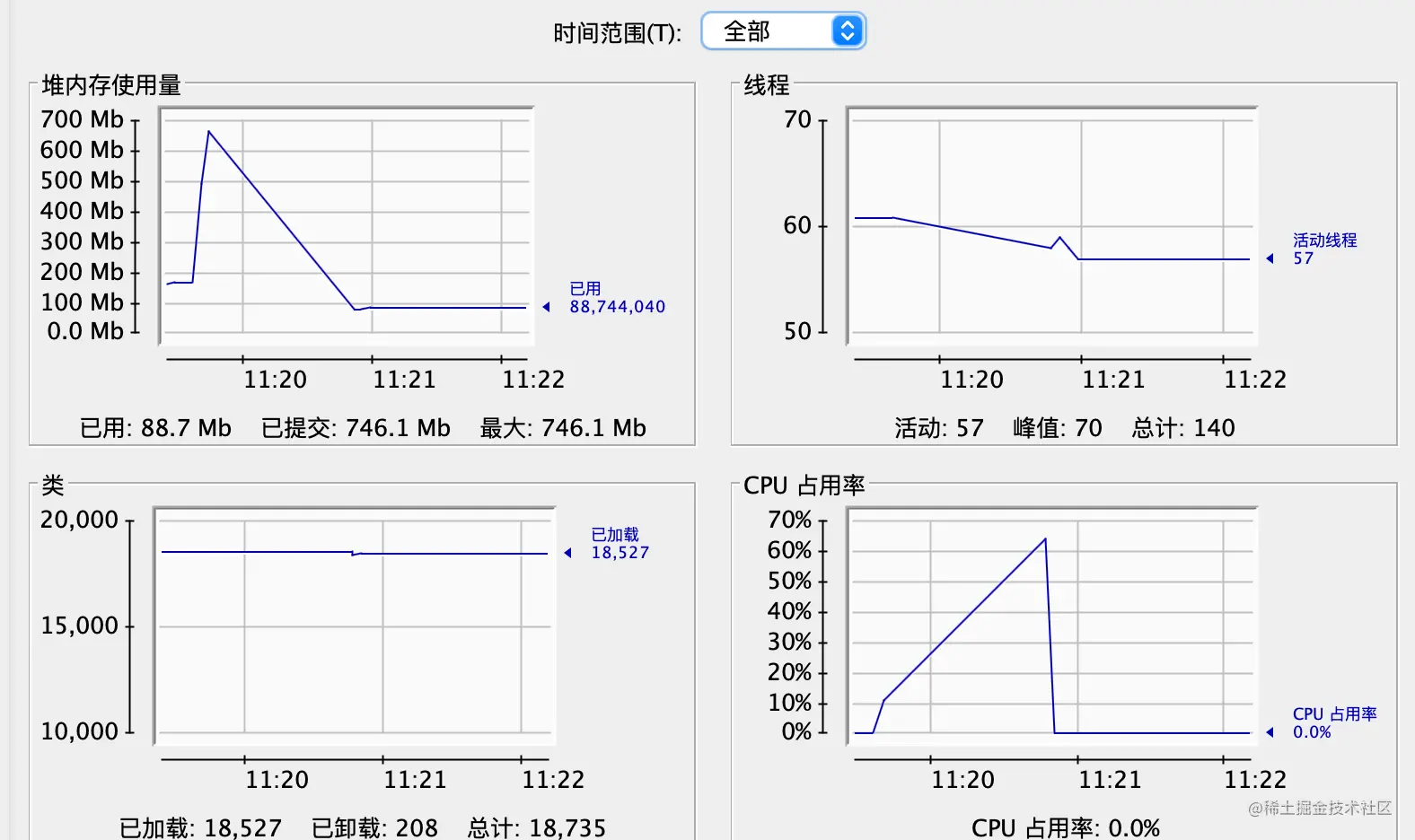
由上面的图可以看出内存和CPU的使用率都比较高,会不断触发Full GC,最终还出现了OOM,内存基本使用完了,cpu使用也达到了近70%。
去除-Xms800m -Xmx800m的内存大小限制后可以把全部数据拿到,结果如下图所示

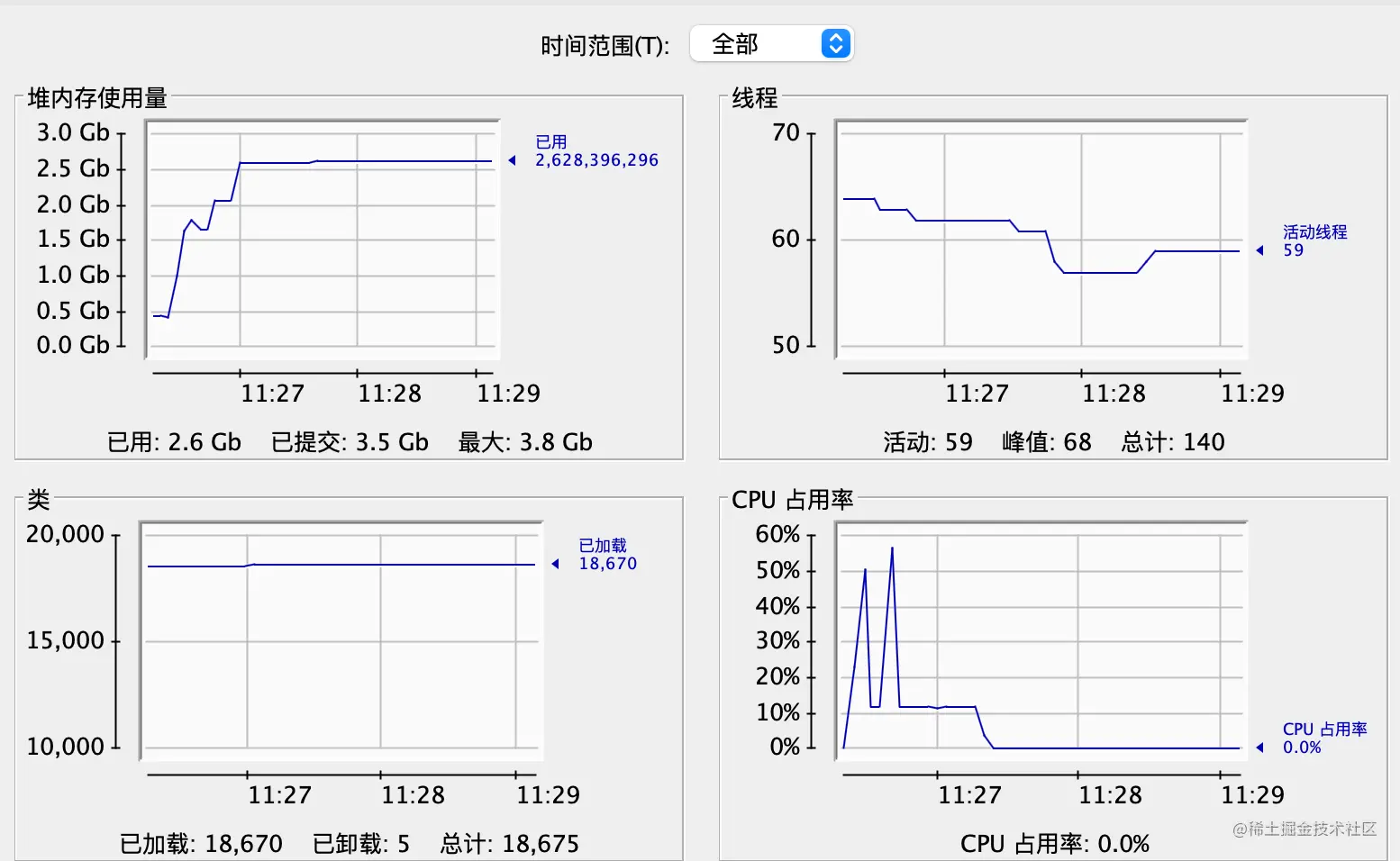
所有数据可以正常解析读取,Full GC也没用前一次频繁,没有出现OOM。10w条数据大小有1.2G,所占用的内存更是达到2.5G,CPU也是近60%的使用率。
仅仅是200M的csv文件,堆内存就占用了2.5G,如果是更大的文件,内存占用不得起飞了

严重占用了系统资源,对于大文件,此方法不可取。
第二版:循序渐进
缓缓图之,数据分批
第一版内存、CPU占用过大,甚至OOM,主要原因就是把所有数据全部加载到内存了。为了避免这种情况,我们可以分批处理。
参数说明:
- file:解析的文件
- batchNumOrder:批次号
- context:存放数据的集合
- count:每一批次的数据量
1. 接口API
@ApiOperation(value = "测试解析-数据分批版")
@GetMapping("/readFileV2")
public ResponseEntity readFileV2(@RequestParam(required = false) int count) {
File file = new File("/Users/ajisun/projects/alwaysCoding/files/total-file.csv");
List<Map<String, Object>> context = new ArrayList<>();
int batchNumOrder = 1;
parseFile(file, batchNumOrder, context, count);
return null;
}
2. 文件解析
文件解析,获取文件流
private int parseFile(File file, int batchNumOrder, List<Map<String, Object>> context, int count) {
try (
InputStreamReader isr = new InputStreamReader(new FileInputStream(file) , StandardCharsets.UTF_8);
BufferedReader br = new BufferedReader(isr)
) {
batchNumOrder = this.readDataFromFile(br, context, batchNumOrder, count);
} catch (Exception e) {
e.printStackTrace();
}
return batchNumOrder;
}3. 读取文件数据
按行读取文件,分割每行数据,然后按照#{count}的数量拆分,分批次存储
private int readDataFromFile(BufferedReader br, List<Map<String, Object>> context, int batchNumOrder, int count) throws IOException {
String line = "";
int number = 1;
while ((line = br.readLine()) != null) {
//去除#号开始的行
if (!line.startsWith("#")) {
if (number >= 1) {
//csv是以逗号为区分的文件,以逗号区分
String[] columns = line.split(",", -1);
//构建数据
context.add(constructDataMap(columns));
}
number++;
}
if (context.size() >= count) {
// TODO 存表
System.out.println("=====插入数据库:批次:" + batchNumOrder + ",数据条数:" + context.size());
context.clear();
batchNumOrder++;
}
}
// 最后一批次提交
if (CollectionUtils.isNotEmpty(context)) {
System.out.println("=====插入数据库:批次:" + batchNumOrder + ",数据条数:" + context.size());
context.clear();
}
return batchNumOrder;
}4.组装数据
把每一行数据按照顺序和业务对象ALI_FINANCE_LIST匹配 ,组装成功单个map数据
public Map<String, Object> constructDataMap(String[] columns) {
Map<String, Object> dataMap = new HashMap<>(16);
for (int i = 0; i < columns.length; i++) {
//防止异常,大于预定义的列不处理
if (i > ALI_FINANCE_LIST.size()) {
break;
}
dataMap.put(ALI_FINANCE_LIST.get(i), columns[i].trim());
}
return dataMap;
}5.执行结果
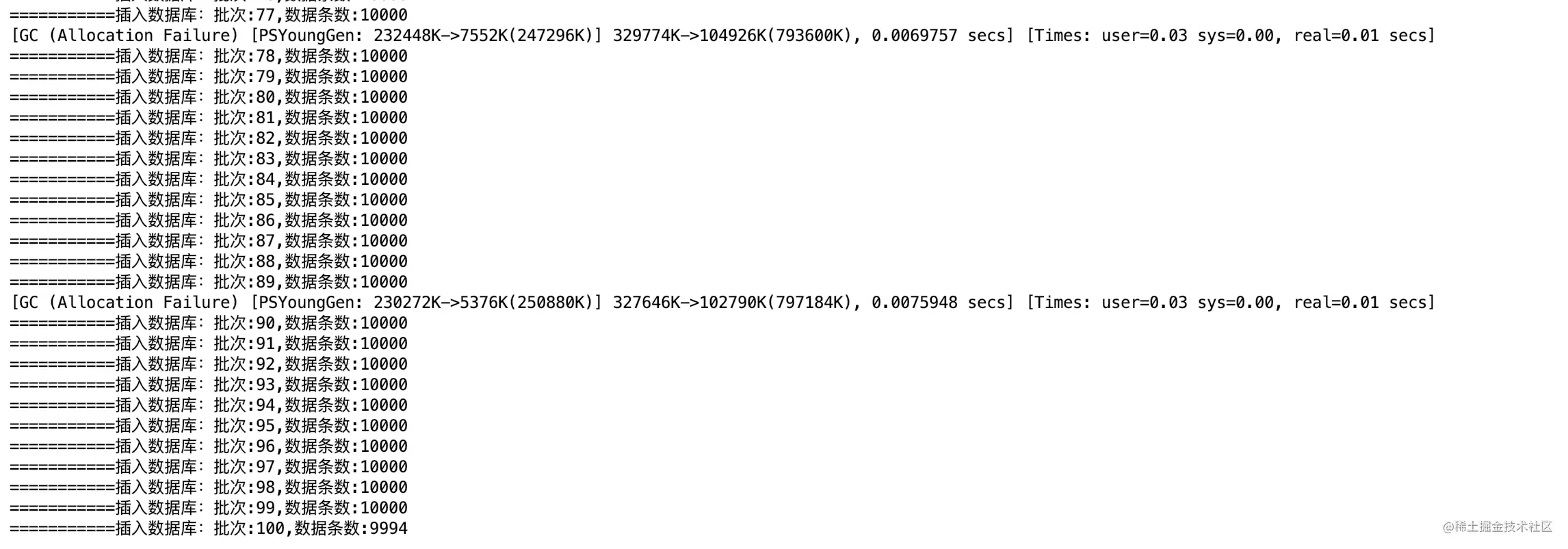
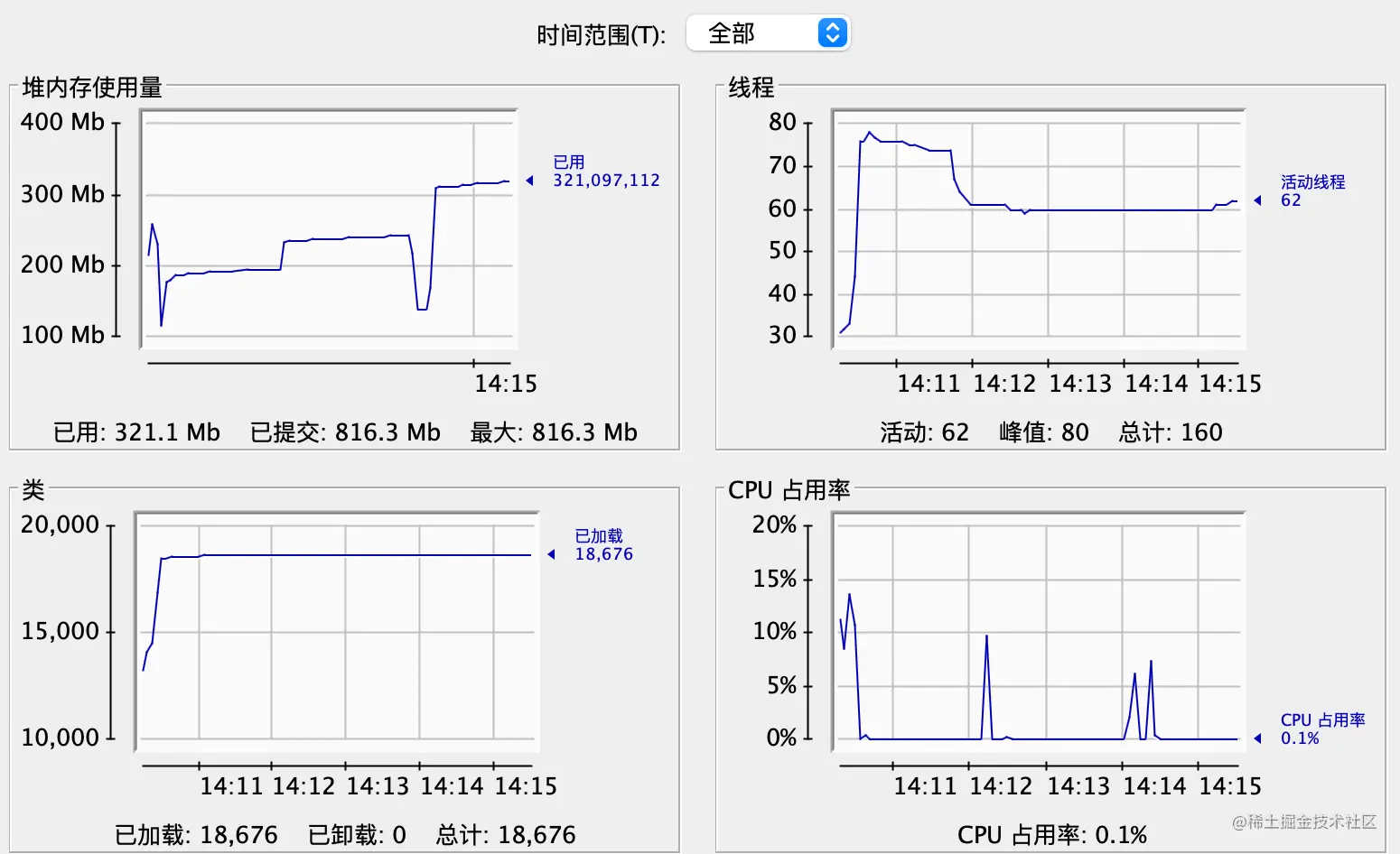
把文件分批读取插入数据库,可以减少内存的占用以及解决高CPU的问题。已经可以很好的处理文件读取问题了。
但是如果一个文件更大,有1G,2G 甚至更大,虽然不会造成OOM ,但是整个解析的时间就会比较长,然后如果中间出现问题,那么就需要从头再来。
假如是1000万数据的文件,按照一批次1万条插入数据库,然而到999批次的时候失败了(不考虑回滚),那么为了保证数据的完整性,该文件就需要重新上传解析。但实际上只需要最后一批次数据即可, 多了很多重复操作。
可以使用另一种方式处理,第三版
第三版:大而化小
分而治之,文件拆分
主要改动就是在第二版的基础增加文件拆分的功能,把一个大文件按照需求拆分成n个小文件,然后单独解析拆分后的小文件即可。其他方法不变。
1.接口API
获取拆分后的文件,循环解析读取
@ApiOperation(value = "测试解析-文件拆分版")
@GetMapping("/readFileV3")
public ResponseEntity readFileV3(@RequestParam(required = false) int count){
if (StringUtils.isEmpty(date)) {
this.execCmd();
}
File file = new File("/Users/ajisun/projects/alwaysCoding/files");
File[] childs = file.listFiles();//可以按照需求自行排序
for (File file1 : childs) {
if (!file1.getName().contains(".csv") && file1.getName().contains("total-file-")) {
file1.renameTo(new File(file1.getAbsolutePath() + ".csv"));
}
}
int batchNumOrder = 1;
List<Map<String, Object>> context = new ArrayList<>();
for (File child : childs) {
if (!child.getName().contains("total-file-")){
continue;
}
batchNumOrder = parseFile(child, batchNumOrder, context, count);
}
return null;
}
2.文件拆分
按照需求使用Linux命令拆分文件,大而化小,然后按照一定规则命名
public List<String> execCmd() {
List<String> msgList = new ArrayList<String>();
String command = "cd /Users/ajisun/projects/alwaysCoding/files && split -a 2 -l 10000 total-file.csv total-file-";
try {
ProcessBuilder pb = new ProcessBuilder("/bin/sh", "-c", command);
Process process = pb.start();
BufferedReader ir = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line;
while ((line = ir.readLine()) != null) {
msgList.add(line);
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(msgList);
return msgList;
}这种方式的处理在内存与CPU的占用和第二版基本没有差别。
如果采用这种方式记得文件的清理,避免磁盘空间的占用
技术扩展:文件拆分
cd /Users/ajisun/projects/alwaysCoding/files && split -a 2 -l 10000 total-file.csv total-file-
上述字符串是两个命令用&&连接,第一个是进入到指定文件夹,第二个就是按照10000行拆分total-file.csv,而且子文件命名以total-file-开头,后缀默认两位字母结尾.
执行后的结果如下图
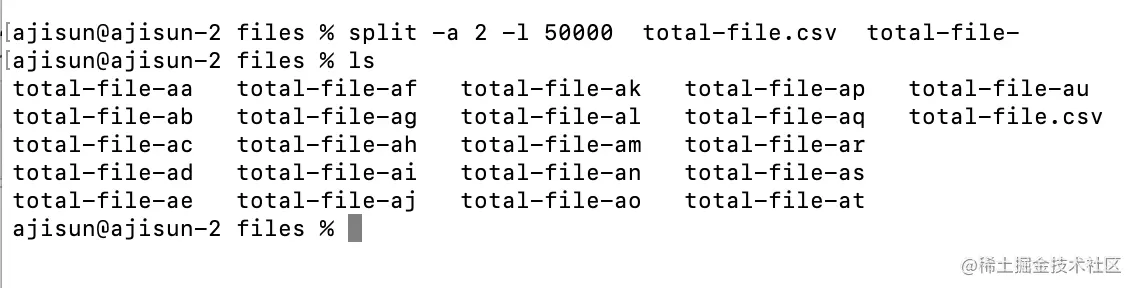
mac下不能用数字命名(linux下可以的),只能是默认的字母命名
Linux下:ajisun.log文件按照文件大小50m切割,后缀是2位数字结尾的子文件,子文件以ajisun-开头

总结总结
如果确定了解析的文件都是小文件,而且文件中的数据最多也就几万行,那么直接简单粗暴使用第一版也没问题。
如果文件较大,几十兆,或者文件中的数据有大几十万行,那么就使用第二版的分批处理。
如果文件很大,以G为单位,或者文件中的数据有几百万行,那么就使用第三版的文件拆分
这里只是做文件解析以及读取相关的功能,但是在实际情况中可能会存在各种各样的数据校验,这个需要根据自己的实际情况处理,但是要避免在解析大文件的时候循环校验,以及循环操作数据库。必要时还可以引入中间表存储文件数据(不做任何处理),在中间表中做数据校验 再同步到目标表。
还有没有其他更好,更优的方式,欢迎评论区讨论










