统计学习导论(ISLR)
参考资料:
The Elements of Statistical Learning
An Introduction to Statistical Learning
统计学习导论(ISLR)(二):统计学习概述
统计学习导论(ISLR)(三):线性回归
统计学习导论(ISLR)(四):分类
ISLR统计学习导论之R语言应用(二):R语言基础
ISLR统计学习导论之R语言应用(三):线性回归R语言代码实战
ISLR统计学习导论之R语言应用(四):分类算法R语言代码实战
统计学习导论(ISLR) 第四章课后习题
统计学习导论(ISLR)(五):重采样方法(交叉验证和boostrap)
文章目录
5. 重采样方法
重抽样方法是现代统计学中不可缺少的工具。通过反复从训练集中抽取样本,并在每个样本上重新拟合感兴趣的模型,以获得有关拟合模型的附加信息。例如,为了估计线性回归拟合的可变性,我们可以从训练数据中反复抽取不同的样本,对每个新样本进行线性回归拟合,然后检查结果拟合的差异范围。这种方法可以让我们获得仅使用原始训练样本拟合模型时无法获得的信息。重采样方法的计算成本可能很高,因为它们会使用不同的训练数据集多次拟合相同的统计方法。然而,由于计算能力的最新发展,重采样方法的计算要求通常并不令人望而却步。在本章中,我们将讨论两种最常用的重采样方法,交叉验证和bootstrap。这两种方法都是许多统计学习过程实际应用中的重要工具。例如,交叉验证可用于计算给定统计学习方法相关的测试误差,以评估其性能,或选择适当的灵活性水平,进行超参数调整。评估模型性能的过程称为模型评估,而模型评估为模型选择适当的灵活性水平的过程称为模型选择。bootstrap应用广泛,最常见的是用于测量参数估计或给定统计学习方法的准确性。
5.1 交叉验证
第二章我们讨论了训练误差和测试误差。测试误差是统计学习方法对新数据集预测所产生的平均误差。在给定的数据集下,如果某一特定的统计学习方法测试误差很低,那么这个模型的效果还不错。相比之下,训练误差是比较容易得到和控制的。但正如我们在第二章中所看到的,训练误差通常与测试误差有很大不同,往往训练误差要大于测试误差。在没有可用于直接估计测试误差测试集的情况下,可以使用多种数学技巧调整训练误差,来估计测试误差。之后我们再详细介绍。在这一章中,我们考虑了将数据集划分的方法。我们需要对数据集划分:训练集、验证集、测试集。有时将验证集和测试集放在一起)。
5.1.1 简单的验证集方法
假设我们要估计某一模型的测试误差,对数据集划分成训练集和测试集,如图5.1所示。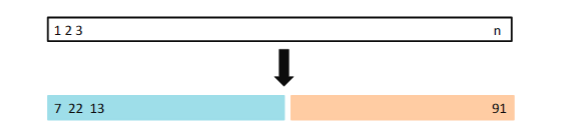
图5.1 验证集划分。对于n个随机数据集,我们把它划分成训练集和测试集,蓝色区域表示训练集,分数区域表示验证集,我们在训练集上面拟合模型,在验证集上面计算测试误差。
我们以
A
u
t
o
Auto
Auto数据为例。记得在第三章线性回归中,我们发现mpg和horsepower之间存在非线性关系,因此使用
h
o
r
s
e
p
o
w
e
r
horsepower
horsepower和
h
o
r
s
e
p
o
w
e
r
2
horsepower^2
horsepower2
预测mpg比线性模型效果更好,因此我们很自然想知道是否三次或者更高次回归模型效果是否更好。在第三章我们是从p值的角度来判断模型是否合适。这里我们使用交叉验证的方法。首先随机将392数据分成两部分,训练集包括196个数据,验证集也包含196个数据。在训练集上拟合模型之后在验证集对模型进行评估,评估指标为MSE。二次拟合的验证集MSE比线性拟合的验证集MSE大得多。然而,三次方拟合的验证集MSE实际上略大于二次拟合的验证集MSE。这意味着在回归中包含一个三次项并不会比简单地使用二次项带来更好的预测。
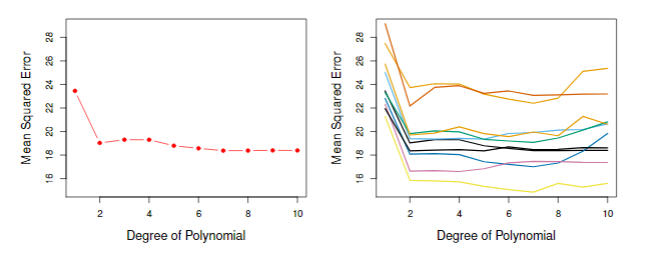
图5.2 验证集方法对不同维度回归测试误差的结果。左图是平均的测试误差,右图是重复十次实验得到的测试误差
回想一下,为了创建图5.2的左侧,我们将数据集分为两部分,一部分是训练集,另一部分是验证集。如果我们重复将样本集随机分成两部分的过程,我们将得到一个稍微不同的测试MSE估计值。如图5.2所示,图5.2的右侧显示了十条不同的MSE曲线,该曲线是通过将观察值分成十个不同的训练集和验证集而生成的。所有十条曲线都表明,与仅具有线性项的模型相比,具有二次项的模型具有显著的小样本验证集MSE。此外,所有十条曲线都表明,在模型中包含三次或高阶多项式项没有多大好处。但值得注意的是,十条曲线中的每一条都会导致所考虑的十个回归模型中的每一个的测试MSE估计值不同。对于哪种模型的验证集MSE最小,这些曲线得到结果并不统一。但我们可以得出线性拟合不适用于这些数据。验证集方法概念简单,易于实现。但它有两个潜在的缺点:
- 正如图5.2所示,测试误差具有多变性,会受到样本的影响,也就是说每一次抽样得到的结果可能没有一致性,在统计学研究中,我们是不希望出现这样的结果
- 在简单的验证集方法中,我们只用了一小部分的数据来拟合模型,这样导致数据集太小而造成偏差,从而导致错误率过高
接下来我们介绍比较常用的交叉验证的方法,解决了上述两个问题
5.1.2 留一法交叉验证(LOOCV)
留一法交叉验证可以看做是上述方法的一种变换。同样将数据集分为两部分,一部分作为验证集,一部分作为训练集,不同的是,我们在这里不选择相同样本量作为验证集,而仅仅选择一个样本
(
x
1
,
y
1
)
(x_1,y_1)
(x1,y1)作为验证集。剩下的n-1个样本作为训练集:
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
{(x_2,y_2),...,(x_n,y_n)}
(x2,y2),...,(xn,yn)。拟合模型。如图5.3所示:
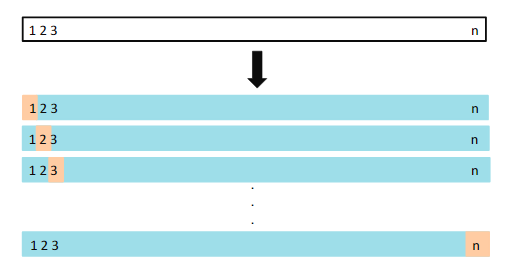
图5.3.留一法交叉验证示意图。将一组数据点重复拆分为一个训练集(蓝色显示)和一个验证集,训练集包含除一个观测值以外的所有观测值,验证集仅包含一个观测值。然后,通过平均得到的MSE来估计测试误差。第一个训练集包含除观测值1之外的所有数据集,第二个训练集包含除观测值2之外的所有数据集,依此类推。
从图5.3可以看出,我们相当于做了n次模型训练,然后将这n次拟合的平均测试误差来估计某一个具体模型的测试误差。第一次训练得到的测试误差为:
M
S
E
1
=
(
y
1
−
y
^
1
)
2
MSE_1=(y_1-\hat{y}_1)^2
MSE1=(y1−y^1)2。重复n次得到:
M
S
E
2
,
.
.
.
,
M
S
E
n
MSE_2,...,MSE_n
MSE2,...,MSEn。最后我们取平均值得到LOOCV估计的测试MSE:
C
V
(
n
)
=
1
n
∑
i
=
1
n
M
S
E
i
.
CV_{(n)}=\frac{1}{n}\sum_{i=1}^{n}MSE_i.
CV(n)=n1i=1∑nMSEi.
与简单的使用验证集方法比较,LOOCV主要有以下几点优势:
- 1.偏差更小,因为我们使用了更多的数据集进行训练
- 2.不会受到抽样的随机性带来的影响。
我们使用Auto数据集通过留一法交叉验证得到测试误差如下图5.4所示:
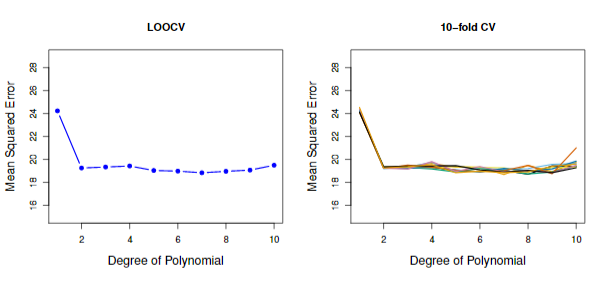
图5.4 交叉验证结果图。左图是留一法交叉验证得到的测试误差随horsepower变量多项式纬度变化图。右图是10折交叉验证得到的多次平均测试误差
留一法交叉验证是一个很general的方法,例如在logistic regression或者naive bayes中都可以运用。
留一法交叉验证有一个缺点是计算量较大,因为我们要拟合n次模型。在当今大数据时代,我们实际遇到的数据往往上万,这时拟合模型会花费太多的时间。
下面我们介绍一下一种在实际中应用更多的方法,K折交叉验证。
5.1.3 K折交叉验证
K折交叉验证的思路是将数据集随机平均的分为K组。第一组作为验证集,剩下的k-1组作为训练集。当k=n时,留一法交叉验证可以看做是K折交叉验证。和留一法交叉验证类似,
M
S
E
1
MSE_1
MSE1可以看做是第一次训练时,验证组的平均误差。重复k次,我们可以得到k-折交叉验证的测试误差:
C
V
(
k
)
=
1
k
∑
i
=
1
k
M
S
E
i
.
CV_{(k)}=\frac{1}{k}\sum_{i=1}^{k}MSE_i.
CV(k)=k1i=1∑kMSEi.
图5.5给出了5折交叉验证的示意图
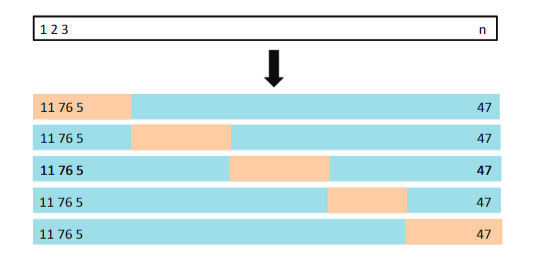
图5.5 5折交叉验证示意图。首先将数据随机的分成5等份,每次拿出一份作为验证集,其余的作为训练集拟合模型,计算在验证集的误差,重复5次后取平均值得到MSE的估计值
在实际中我们常常取k=5或k=10。下面通过模拟数据集,计算了k=10和留一法交叉验证的MSE以及真实的MSE结果如下图5.6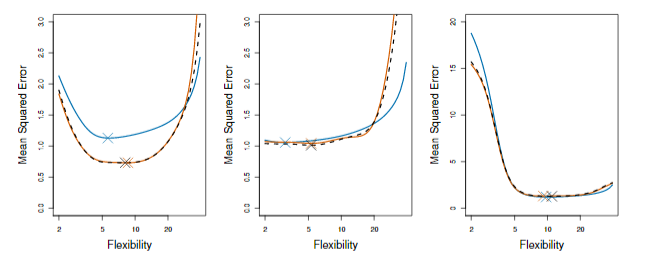
图5.6 模拟数据集下的估计MSE和真实MSE。蓝色曲线代表模拟数据集的真实测试误差。黑色虚线代表留一法交叉验证,橙色曲线代表10折交叉验证。
我们通过交叉验证可以判断一个给定模型在数据集上的效果。上述案例中,我们知道真实的测试误差,要找到使得真实测试误差最小的点。但在实际情况中,我们往往不知道模型的真实测试误差,因此以交叉验证的结果作为对测试误差的估计,我们的目的是要找到使得估计测试误差最低的点作为我们模型的参数。
5.1.4 k折交叉验证的偏差方差权衡
我们上面说K折交叉验证在运算上比留一法交叉验证要好。但除去运算量不考虑,另一个比较重要的优势是通常k折交叉验证对测试误差的估计比留一法交叉验证更准确。
我们之前讨论过,简单的验证集方法会带来较大的偏差,因为他只用了数据集的一部分作为训练集拟合模型,从这一点来看,留一法交叉验证几乎是无偏的,因为他用了n-1个数据训练。同样k=5和k=10也会导致一定的偏差。如果仅仅从偏差的角度来看,留一法似乎表现的更好。但是我们还要考虑方差的问题。对于LOOCV,我们实际上是在平均拟合模型的输出,每个模型都是在几乎相同的观测集上训练的;因此,这些输出彼此高度(正)相关。相比之下,当我们在k<n的情况下执行K折CV时,我们是对相互之间的相关性较小的k个拟合模型的输出进行平均。因为每个模型的训练集重合度较小。因此LOOCV会有较大的方差。
总的来说,取k=5或k=10是一个还不错的水平,方差和偏差都不大。
5.1.5 分类问题上的交叉验证
在上面的分析中,我们都是在回归案例中使用,下面我们讨论一下Y是分类型变量是,此时LOOCV错误率定义为:
C
V
(
n
)
=
1
n
∑
i
=
1
n
E
r
r
i
CV_{(n)} = \frac{1}{n}\sum_{i=1}^{n}Err_i
CV(n)=n1i=1∑nErri
其中,
E
r
r
i
=
I
(
y
i
≠
y
^
i
)
Err_i=I(y_i \neq \hat{y}_i)
Erri=I(yi=y^i),
I
(
)
I()
I()表示示性函数,如果条件成立则取1,否则取0
同样的,我们生成一个二分类模拟数据,拟合多个不同的logistic回归模型。如下图5.7。

图5.7. logistic回归结果图。其中虚线表示贝叶斯决策边界。实线表示不同次方的logistic拟合结果。测试误差分别为:0.201,0.197,0.160,0.162。贝叶斯误差为0.133
注:贝叶斯误差被认为是最小的错误率,已经无法再提升。
可以看出四次多项式的logistic回归模型结果没有提升,而预测因子三次多项式的logistic回归模型拟合效果相较于二次多项式得到了较大的提高。
在实际中,我们并不知道贝叶斯决策边界和测试误差,因此我们通过交叉验证来判断哪个模型最好。如下图所示:
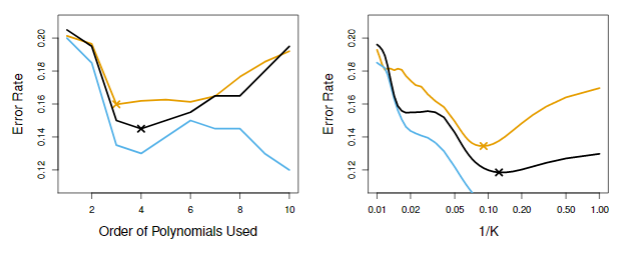
图5.8. 交叉验证结果。左图是不同logistic回归的结果,右图是不同K值的KNN结果。棕色曲线表示测试误差,蓝色曲线表示训练误差,黑色曲线表示十折交叉验证结果。
从图中可以看出,随着模型复杂度的提升,测试错误率呈现先下降后上升的趋势。
5.2 Bootstrap
bootstrap是统计学习中一个特别重要的工具,能够应用于各种统计学习方法中。其基本思想是从一个数据集中每次抽取n个数据作为一个样本,重复多次试验,得到多个数据集,利用样本经验分布来代替总体分布。根据这些抽取出来的样本集估计某一特定的统计量,并根据多次抽取的结果来估计统计量的方差。
在这一部分中,我们希望在一个简单的模型下确定最佳的投资分配。
假设我们希望将给定自己投资两个金融产品中。两个金融产品的收益率分别为
X
X
X和
Y
Y
Y,且
X
X
X和
Y
Y
Y都是随机变量。假设我们投入
α
\alpha
α给X那么
1
−
α
1-\alpha
1−α给Y,因此我们希望选择
α
\alpha
α使得总风险最小,即最小化
V
a
r
(
α
X
+
(
1
−
α
)
Y
Var(\alpha X+(1-\alpha) Y
Var(αX+(1−α)Y。即:
α
=
σ
Y
2
−
σ
X
Y
σ
X
2
+
σ
Y
2
−
2
σ
X
Y
\alpha = \frac{\sigma_Y^2-\sigma_{XY}}{\sigma_X^2+\sigma_Y^2-2\sigma_{XY}}
α=σX2+σY2−2σXYσY2−σXY
同意我们计算
1
−
α
=
σ
X
2
−
σ
X
Y
σ
X
2
+
σ
Y
2
−
2
σ
X
Y
1-\alpha = \frac{\sigma_X^2-\sigma_{XY}}{\sigma_X^2+\sigma_Y^2-2\sigma_{XY}}
1−α=σX2+σY2−2σXYσX2−σXY
可以发现其中的规律,取决定性因素的是各自的方差
σ
X
2
\sigma_X^2
σX2和
σ
Y
2
\sigma_Y^2
σY2。
实际我们不知道
σ
X
,
σ
Y
,
σ
X
Y
\sigma_X,\sigma_Y,\sigma_{XY}
σX,σY,σXY等值,因此我们需要用过去的值估计。再来估计:
α
^
\hat \alpha
α^。
下面我们通过模拟数据来估计
α
\alpha
α,我们每次抽取100对X和Y数据作为样本集,据此来估计
σ
X
2
,
σ
Y
2
,
σ
X
Y
\sigma_X^2,\sigma_Y^2,\sigma_{XY}
σX2,σY2,σXY。图5.9显示了四次模拟中得到
α
^
\hat \alpha
α^
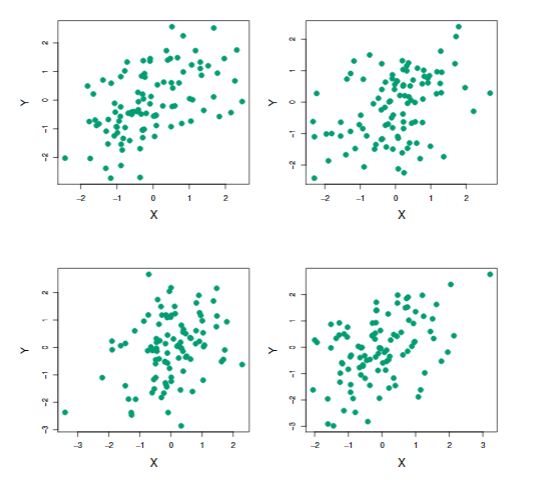
图5.9.模拟数据集。每张图都包含100个模拟数据集,上面四次模拟得到的
α
\alpha
α分别为0.576,0.532,0.657,0.651。
我们要想知道估计参数的准确性。因此很自然的想要估计
α
\alpha
α的方差。因此,我们重复1000次抽取样本,得到1000个
α
\alpha
α的估计值。
α
^
1
,
.
.
.
,
α
^
1000
\hat \alpha_1,...,\hat \alpha_{1000}
α^1,...,α^1000。我们设定的模拟数据集参数为
σ
X
2
=
1
,
σ
Y
2
=
1.25
,
σ
X
Y
0
.
5
\sigma_X^2=1,\sigma_Y^2=1.25,\sigma_{XY}^0.5
σX2=1,σY2=1.25,σXY0.5,我们能计算得到真实的
α
=
0.6
\alpha=0.6
α=0.6。而经过1000次的估计值:
α
ˉ
=
1
1000
∑
r
=
1
1000
α
^
r
=
0.5996
\bar\alpha = \frac{1}{1000}\sum_{r=1}^{1000}\hat{\alpha}_r=0.5996
αˉ=10001r=1∑1000α^r=0.5996
结果非常接近真实值0.6,标准差如下:
S
E
(
α
^
)
=
1
1000
−
1
∑
r
=
1
1000
(
α
^
r
−
α
ˉ
)
2
=
0.083
SE(\hat \alpha)=\sqrt{\frac{1}{1000-1}\sum_{r=1}^{1000}(\hat{\alpha}_r-\bar\alpha)^2=0.083}
SE(α^)=1000−11r=1∑1000(α^r−αˉ)2=0.083
可以看出标准差为0.083,说明我们的估计效果还算不错。下面我们对其进行可视化如图5.10.
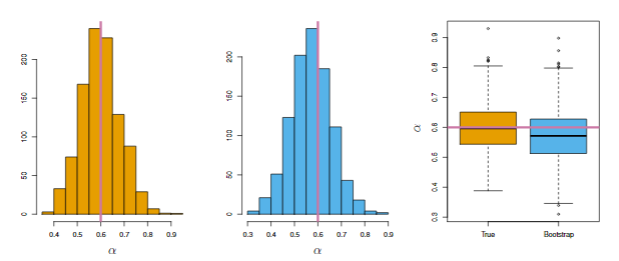
图5.10 棕色代表真实
α
\alpha
α的分布情况,蓝色表示boostrap得到的
α
^
\hat \alpha
α^分布。
从图5.10可以看出bootstrap得到的分布与真实的分布很接近,这说明bootstrap方法可以有效的估计
α
\alpha
α的分布情况。
但在实际应用中,我们得不到真实的 α \alpha α分布。bootsrap可以从原始数据集中不断的获取新样本集,这样就可以在不要求新的样本估计 α \alpha α。例如原始数据集有M个,每次我们随机有放回的抽取样本,假设抽取N个作为样本集,这样我们最多可以得 M N M^N MN个样本集合。
下面我们举一个非常简单的例子,如下图5.11所示。
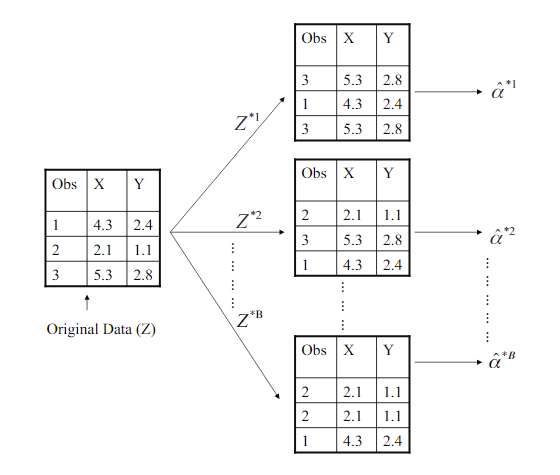
图5.11 bootstrap方法示意图
如图5.11,我们原始数据集一共有3个数据(M=3),假设我们每次有放回的抽取样本个数为3的集合,得到
Z
∗
1
,
.
.
.
Z
∗
B
Z^{*1},...Z^{*B}
Z∗1,...Z∗B。每次抽取的样本集都可以得到一个
α
∗
1
\alpha^{*1}
α∗1估计值。我们可以计算这些估计值的平均值并进一步估计方差
S
E
B
(
α
^
)
=
1
B
−
1
∑
r
=
1
B
(
α
^
∗
r
−
1
B
∑
r
=
1
B
α
^
∗
r
)
2
SE_B(\hat \alpha)=\sqrt{\frac{1}{B-1}\sum_{r=1}^{B}(\hat{\alpha}^{*r}-\frac{1}{B}\sum_{r=1}^{B}\hat{\alpha}^{*r})^2}
SEB(α^)=B−11r=1∑B(α^∗r−B1r=1∑Bα^∗r)2
bootstrap总结:
bootstrap的核心思想就是利用经验分布代替总体分布。
(1) 采用随机放回抽样从原始样本中抽取一定数量的样本
(2) 根据抽出的样本计算待估计的统计量。
(3) 重复上述步骤(一般大于1000次),得到n个估计值。
(4) 据此来计算方差以及分布情况
