文章目录
听说点进蝈仔帖子的都喜欢点赞加关注~~
首先,官网附上:
https://aws.amazon.com/cn/blogs/big-data/test-data-quality-at-scale-with-deequ/
软件架构为:
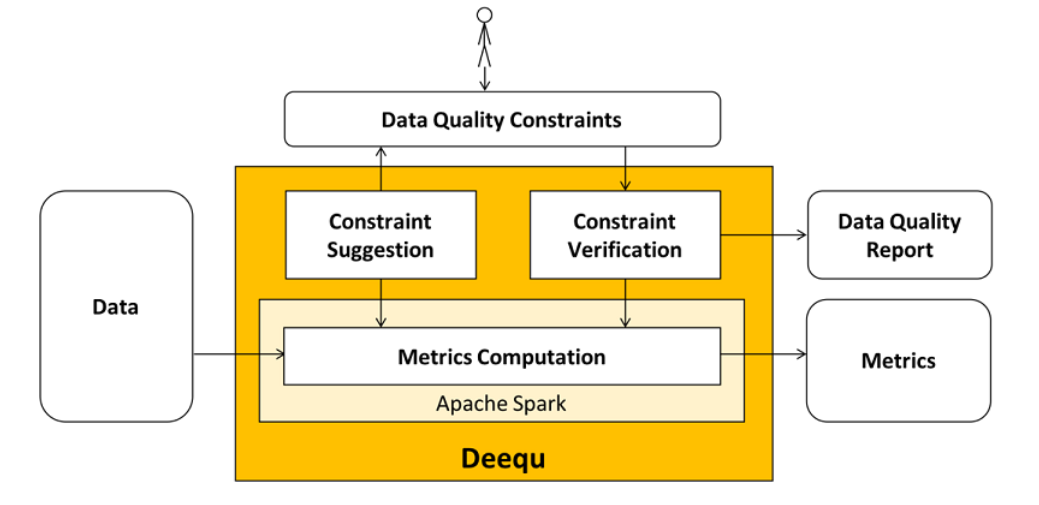
Deequ概述
亚马逊内部正在使用 Deequ 来验证许多大型生产数据集的质量。数据集生产者可以添加和编辑数据质量约束。系统定期计算数据质量指标(使用数据集的每个新版本),验证数据集生产者定义的约束,并在成功时将数据集发布给消费者。在错误情况下,可以停止数据集发布,并通知生产者采取行动。数据质量问题不会传播到消费者数据管道,从而减少它们的爆炸半径。
要使用 Deequ,让我们看一下它的主要组件(也如图 1 所示)。
- 指标计算——Deequ 计算数据质量指标,即完整性、最大值或相关性等统计数据。Deequ 使用 Spark 从 Amazon S3 等源中读取数据,并通过一组优化的聚合查询计算指标。您可以直接访问根据数据计算的原始指标。
- 约束验证——作为用户,您专注于定义一组要验证的数据质量约束。Deequ 负责导出要在数据上计算的所需指标集。Deequ 生成数据质量报告,其中包含约束验证的结果。
- 约束建议- 您可以选择定义自己的自定义数据质量约束,或使用自动约束建议方法来分析数据以推断有用的约束。
安装:启动 Spark 集群
本节展示了在您自己的数据上使用 Deequ 的步骤。首先,在 Amazon EMR 集群上设置 Spark 和 Deequ。然后,加载 AWS 提供的示例数据集,运行一些分析,然后运行数据测试。
Deequ 构建在 Apache Spark 之上,以支持对大型数据集进行快速、分布式计算。Deequ 依赖于 Spark 2.2.0 或更高版本。第一步,使用 Amazon EMR 上的 Spark 创建一个集群。Amazon EMR 会为您处理 Spark 的配置。此外,您可以使用 EMR 文件系统 (EMRFS) 直接访问 Amazon S3 中的数据。为了进行测试,您还可以在单机上以独立模式安装 Spark 。
使用 SSH 连接到 Amazon EMR 主节点。从Maven Repository加载最新的 Deequ JAR 。要加载 1.0.1 版的 JAR,请使用以下命令:
wget http://repo1.maven.org/maven2/com/amazon/deequ/deequ/1.0.1/deequ-1.0.1.jar
启动 Spark Shell 并使用 spark.jars 参数来引用 Deequ JAR 文件:
spark-shell --conf spark.jars=deequ-1.0.1.jar
有关如何设置 Spark 的更多信息,请参阅Spark 快速入门指南和Spark 配置选项概述。
加载数据
作为一个运行示例,我们使用Amazon在 Amazon S3 上提供的客户评论数据集。让我们加载包含 Spark 中“电子”类别评论的数据集。确保在 Spark shell 中输入代码:
val dataset = spark.read.parquet(“s3://amazon-reviews-pds/parquet/product_category=Electronics/”)
如果您在 Spark shell 中运行dataset.printSchema() ,您可以看到以下选定的属性:
根
|-- 市场:字符串(nullable = true)
|-- customer_id:字符串(nullable = true)
|-- review_id:字符串(nullable = true)
|-- product_title:字符串(nullable = true)
|-- star_rating:整数 (nullable = true)
|-- help_votes: 整数 (nullable = true)
|-- total_votes: 整数 (nullable = true)
|-- vine: 字符串 (nullable = true)
|-- 年份: 整数 (nullable = true)
数据分析
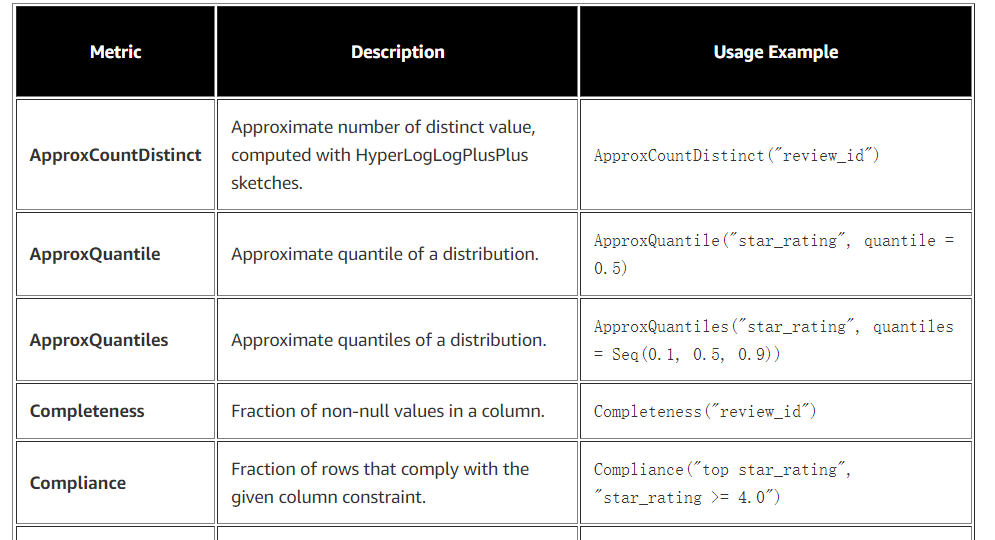
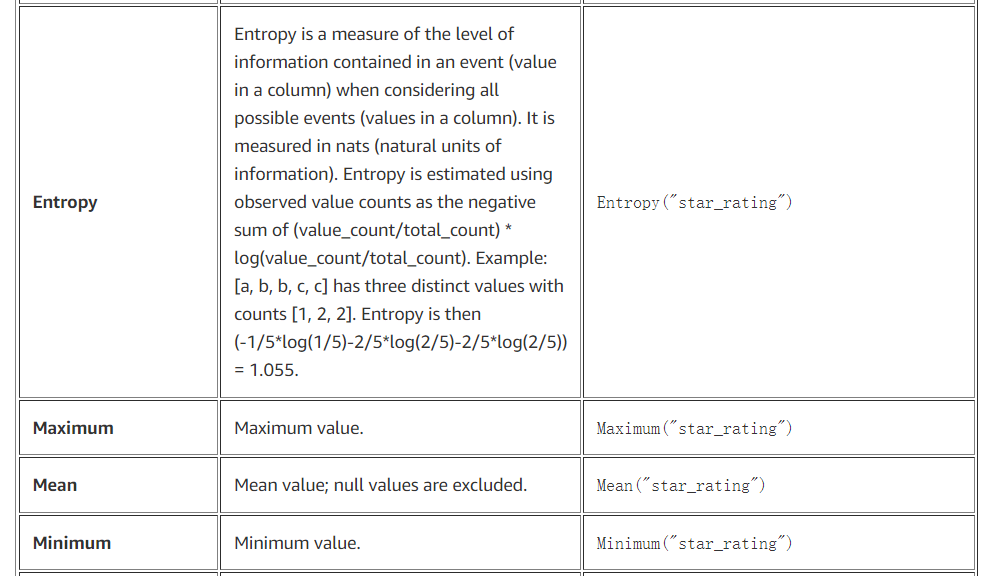
在我们定义数据检查之前,我们要计算数据集的一些统计数据;我们称它们为指标。Deequ 支持以下指标(它们在此 Deequ 包中定义):

import com.amazon.deequ.analyzers.runners.{AnalysisRunner, AnalyzerContext}
import com.amazon.deequ.analyzers.runners.AnalyzerContext.successMetricsAsDataFrame
import com.amazon.deequ.analyzers.{Compliance, Correlation, Size, Completeness, Mean, ApproxCountDistinct}
val analysisResult: AnalyzerContext = { AnalysisRunner
// data to run the analysis on
.onData(dataset)
// define analyzers that compute metrics
.addAnalyzer(Size())
.addAnalyzer(Completeness("review_id"))
.addAnalyzer(ApproxCountDistinct("review_id"))
.addAnalyzer(Mean("star_rating"))
.addAnalyzer(Compliance("top star_rating", "star_rating >= 4.0"))
.addAnalyzer(Correlation("total_votes", "star_rating"))
.addAnalyzer(Correlation("total_votes", "helpful_votes"))
// compute metrics
.run()
}
自动约束建议
如果您拥有大量数据集,或者您的数据集有很多列,则手动定义适当的约束可能具有挑战性。Deequ 可以根据数据分布自动建议有用的约束。Deequ 首先运行数据分析方法,然后对结果应用一组规则。
import com.amazon.deequ.suggestions.{ConstraintSuggestionRunner, Rules}
import spark.implicits._ // for toDS method
// We ask deequ to compute constraint suggestions for us on the data
val suggestionResult = { ConstraintSuggestionRunner()
// data to suggest constraints for
.onData(dataset)
// default set of rules for constraint suggestion
.addConstraintRules(Rules.DEFAULT)
// run data profiling and constraint suggestion
.run()
}
// We can now investigate the constraints that Deequ suggested.
val suggestionDataFrame = suggestionResult.constraintSuggestions.flatMap {
case (column, suggestions) =>
suggestions.map { constraint =>
(column, constraint.description, constraint.codeForConstraint)
}
}.toSeq.toDS()










