内容目录
需要完成的事情:一张全量表,计算任务七天平均开始结束时间
一、介绍数据
数据表为一个全量同步表,分区是按照日期,里面有每个任务开始时间、结束时间、开始时间总秒数(到凌晨总秒数)、结束时间总秒数(到凌晨总秒数)。
分区数值举例:log_date=‘20220218’,并非’2022-02-18’
现在需要求出每个任务的七天平均结束和开始时间
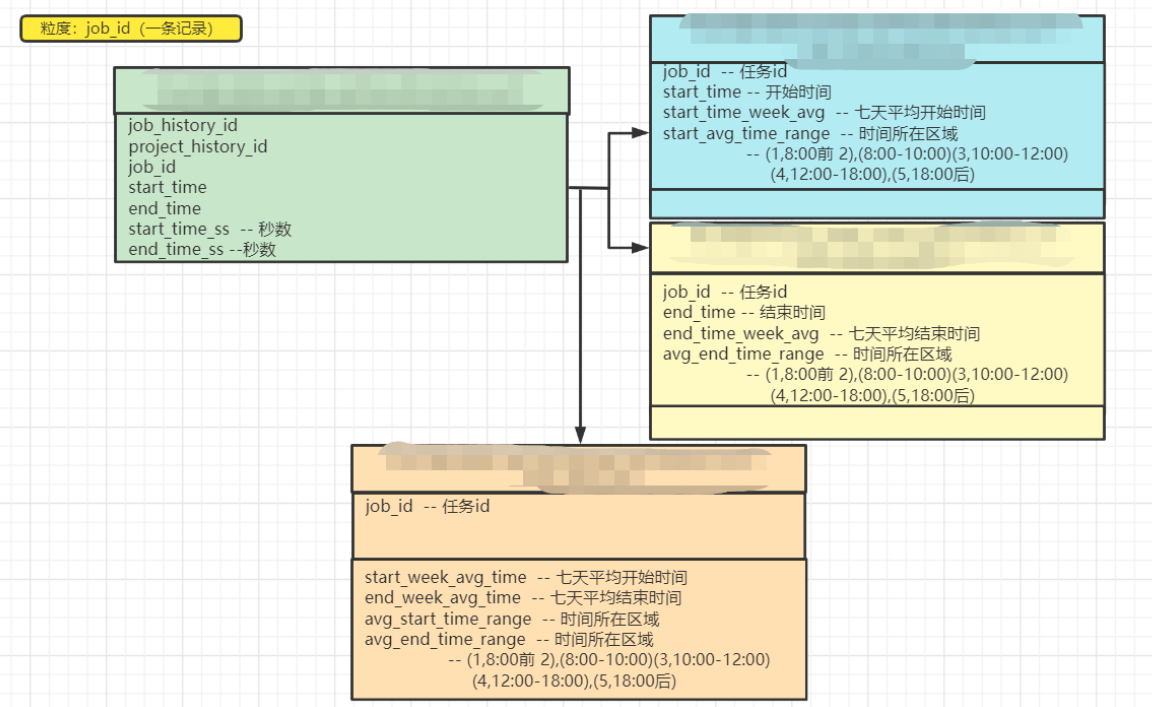
二、ER模型
在分析一个需求的时候,尽量先理清字段关系和我们想要得到的结果,模型建立之后,思路就会打开了,这个需求的ER模型其实很明确,数据粒度自然就是一个任务的一条记录,然后无非就是求得平均开始时间,平均结束时间,然后判断时间所在的范围,然后连接一下即可
三、思路梳理
- 首先,毫无疑问的是需要使用到开窗函数
- 其次开窗函数中怎么设置分区
- 因为是七天内,所以还需要将数据排序吧,按照哪个字段进行排序呢
- 因为分区格式是‘20220218’,如果自动获取日期,格式则是‘2022-02-18’,所以怎么进行转换
- 七天平均时间,不能直接日期总和求均值吧,怎么对时间求平均数
- 求得的时间平均数,又如何进行转换变成时间
大概需要考虑以上几个问题,当这几个问题考虑好了,就可以进行正常的代码编写了
四、问题解决
将以上的几个小问题一一解决
-
开窗函数
开窗函数的使用再回忆一下,
使用语法:
udf() over(partition by ... order by ... rows ... ... ...)在这里我们所要实现的函数就是取平均值,因此就是
avg(values) over(...) -
开窗函数怎么设置分区
首先了解我们需要达到的目的,我们的数据粒度是一个任务的一条记录,要求的七天平均值,所以就要将同一个job的数据进入到一个窗口,所以自然按照job进行分区
avg(values) over(partition by job_id ... ... ...) -
数据怎么排序
因为进入窗口的数据有好多,但是我们只要往前七天的,所以需要进行倒序排序拿到前七天数据,所以应该按照我们的开始时间进行排序,这里注意,如果是求开始时间就用开始时间,如果是结束时间,就用结束时间排序
avg(values) over(partition by job_id order by start_time ...) -
日期格式如何转换
如果自动获取日期,日期格式默认是‘2022-02-18’这种格式,和分区的要求不一样,所以怎么转换
刚开始我没找到相应的方法,就是用的先转成时间戳,然后再由时间戳转化为时间的时候设定为‘yyyyMMdd’
select from_unixtime(unix_timestamp('2022-02-18','yyyy-mm-dd'),'yyyymmdd') -
对于时间求平均值
不可以直接求,比如‘2022-02-18 12:00:00’和‘2022-02-17 12:00:00’,求得平均值明显就是‘2022-02-18 00:00:00’,显然不符合要求,我们需要的应该是“12:00:00”,所以在求平均值的时候,就要转换为到凌晨零点的总秒数,然后求均值
hour(start_time)*3600 + minute(start_time)*60 + second(start_time)但是,在表中有个字段已经记录了这个数据,所以可以直接拿来用
-
当我们求得了总秒数的均值,怎么转换为时间格式呢
比如3600s怎么转换为时间‘01:00:00’
可以这样:
concat(floor(36839/3600),':',floor((36839%3600)/60),':',floor((36839%3600)%60))这样可以转换,但是有一个问题,时间“12:00:00”,会被解析成“12:0:0”,显然不符合美观,那么就可以使用判断函数,判断如果为一位,就补上一个0
concat_ws(':', if(length(cast(floor(t2.avg_start_time/3600) as string)) = 1,concat('0',cast(floor(t2.avg_start_time/3600) as string)),cast(floor(t2.avg_start_time/3600) as string)) ,if(length(cast(floor(t2.avg_start_time%3600/60) as string)) = 1,concat('0',cast(floor(t2.avg_start_time%3600/60) as string)),cast(floor(t2.avg_start_time%3600/60) as string)) ,if(length(cast(t2.avg_start_time%3600%60 as string)) = 1,concat('0',cast(t2.avg_start_time%3600%60 as string)),cast(t2.avg_start_time%3600%60 as string))) start_time_week_avg, -- 秒数转换为时分秒但是在真正的生产中,建议可以把这种封装到udf中,一个是简化代码,另一个是这种函数真的很常用到
五、总sql编写
所有的小问题解决完了,就把这些小问题总结在一起
SELECT
t2.jb job_id,
t2.st start_time,
t2.et end_time,
t2.sts start_time_ss,
t2.ets end_time_ss,
case
when t2.avg_start_time<28800 then 1
when t2.avg_start_time<36000 then 2
else 3 end avg_start_time_range,
case
when t2.avg_end_time<28800 then 1
when t2.avg_end_time<36000 then 2
else 3 end avg_end_time_range,
concat_ws(':',
if(length(cast(floor(t2.avg_start_time/3600) as string)) = 1,concat('0',cast(floor(t2.avg_start_time/3600) as string)),cast(floor(t2.avg_start_time/3600) as string))
,if(length(cast(floor(t2.avg_start_time%3600/60) as string)) = 1,concat('0',cast(floor(t2.avg_start_time%3600/60) as string)),cast(floor(t2.avg_start_time%3600/60) as string))
,if(length(cast(t2.avg_start_time%3600%60 as string)) = 1,concat('0',cast(t2.avg_start_time%3600%60 as string)),cast(t2.avg_start_time%3600%60 as string))) start_time_week_avg, -- 秒数转换为时分秒
concat_ws(':',
if(length(cast(floor(t2.avg_end_time/3600) as string)) = 1,concat('0',cast(floor(t2.avg_end_time/3600) as string)),cast(floor(t2.avg_end_time/3600) as string))
,if(length(cast(floor(t2.avg_end_time%3600/60) as string)) = 1,concat('0',cast(floor(t2.avg_end_time%3600/60) as string)),cast(floor(t2.avg_end_time%3600/60) as string))
,if(length(cast(t2.avg_end_time%3600%60 as string)) = 1,concat('0',cast(t2.avg_end_time%3600%60 as string)),cast(t2.avg_end_time%3600%60 as string))) end_time_week_avg -- 秒数转换为时分秒
from
(SELECT
t1.job_id jb,
t1.start_time st,
t1.end_time et,
t1.start_time_ss sts,
t1.end_time_ss ets,
floor(t1.avg_start) avg_start_time,
floor(t1.avg_end) avg_end_time
from
(select
job_id,
start_time,
end_time,
start_time_ss,
end_time_ss,
AVG(start_time_ss)
over(partition by job_id order by start_time desc rows BETWEEN 7 preceding and current row) avg_start,
AVG(end_time_ss)
over(partition by job_id order by end_time desc rows BETWEEN 7 preceding and current row) avg_end
from table_name
where log_date='20220218') t1) t2;
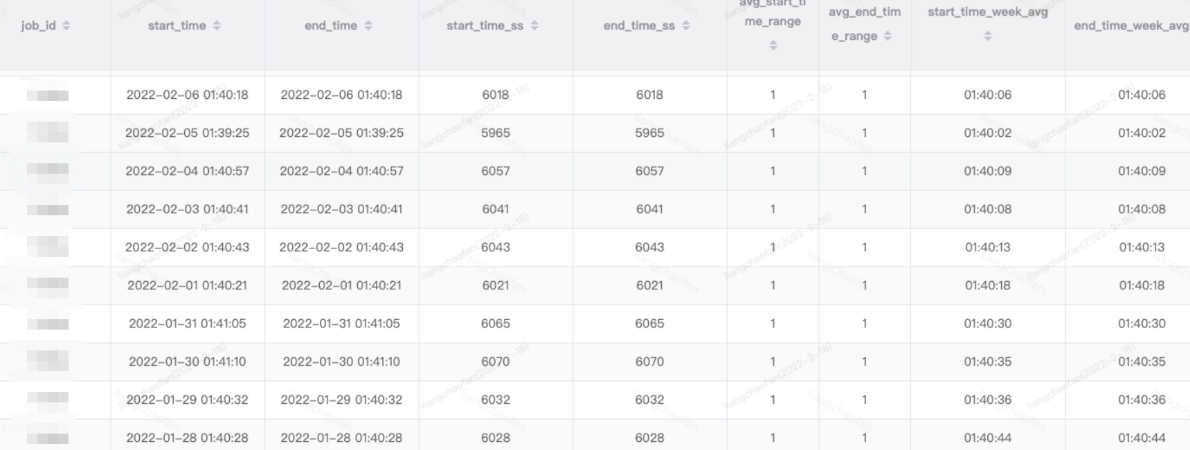
六、运行结果展示