简介
线程池想必大家也都用过,JDK的Executors 也自带一些线程池。针对这个问题,我们必须要明确我们的需求是计算密集型还是IO密集型。
计算密集型:
顾名思义就是应用需要非常多的CPU计算资源,在多核CPU时代,我们要让每一个CPU核心都参与计算,将CPU的性能充分利用起来,这样才算是没有浪费服务器配置。
IO密集型
我们现在做的开发大部分都是WEB应用,涉及到大量的网络传输,不仅如此,与数据库,与缓存间的交互也涉及到IO,一旦发生IO,线程就会处于等待状态,当IO结束,数据准备好后,线程才会继续执行。因此从这里可以发现,对于IO密集型的应用,我们可以多设置一些线程池中线程的数量,这样就能让在等待IO的这段时间内,线程可以去做其它事,提高并发处理效率。
代码
package com.kingxunlian.invoice.service.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
@Configuration
@EnableAsync
public class ExecutorConfig {
/**
* 线程池维护线程的最小数量. .
*/
private final int corePoolSize = 30;
/**
* 线程池维护线程的最大数量. .
*/
private final int maxPoolSize = 300;
/**
* 队列最大长度.
*/
private final int queueCapacity = 10240;
@Bean(name = "invoiceExecutor")
public Executor invoiceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setThreadNamePrefix("glj-thread-sf-dk-");
executor.setKeepAliveSeconds(300);
executor.initialize();
return executor;
}
}
上面我们通过使用ThreadPoolTaskExecutor创建了一个线程池,
同时设置了以下这些参数:
核心线程数30:线程池创建时候初始化的线程数
最大线程数300:线程池最大的线程数,只有在缓冲队列满了之后才会申请超过核心线程数的线程
缓冲队列10240:用来缓冲执行任务的队列
允许线程的空闲时间300秒:当超过了核心线程出之外的线程在空闲时间到达之后会被销毁
线程池名的前缀:设置好了之后可以方便我们定位处理任务所在的线程池
线程池对拒绝任务的处理策略:这里采用了CallerRunsPolicy策略,当线程池没有处理能力的时候,该策略会直接在 execute 方法的调用线程中运行被拒绝的任务;如果执行程序已关闭,则会丢弃该任务
代码
package com.glj.test.demo.biz.controller;
import com.glj.test.demo.config.ThreadPoolConfig;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
/**
* @description: TODO
* @author: glj
* @create: 2019-12-04 15:04
**/
@RestController
@Api(tags = "测试接口")
@RequestMapping("/test-demo/thread")
@Slf4j
public class ThreadController {
@Autowired
private ThreadPoolConfig taskExecutePool;
@ApiOperation(value = "测试多线程")
@PostMapping(value = "/thredExecute",produces = MediaType.APPLICATION_JSON_VALUE)
public String thredExecute() {
// 开始执行时间
LocalDateTime startDateTime = LocalDateTime.now();
List<Integer> integerList = IntStream.range(1,1000).boxed().collect(Collectors.toList());
List<CompletableFuture<String>> list = integerList.stream()
.map(e -> CompletableFuture.supplyAsync(()->exc(e),taskExecutePool.getAsyncExecutor())).collect(Collectors.toList());
List<String> res = list.stream()
.map(CompletableFuture::join) // 等待流中Future执行完毕,提取各自返回值
.collect(Collectors.toList());
res.stream().forEach(v -> System.out.println(v));
long s = ChronoUnit.SECONDS.between(startDateTime, LocalDateTime.now());
log.info("执行时间:{}",s);
return String.valueOf(s);
}
@ApiOperation(value = "单个线程执行")
@PostMapping(value = "/execute",produces = MediaType.APPLICATION_JSON_VALUE)
public String execute() {
// 开始执行时间
LocalDateTime startDateTime = LocalDateTime.now();
List<Integer> integerList = IntStream.range(1,1000).boxed().collect(Collectors.toList());
List<String> res= integerList.stream().map(v ->exc(v)).collect(Collectors.toList());
res.stream().forEach(v -> System.out.println(v));
long s = ChronoUnit.SECONDS.between(startDateTime, LocalDateTime.now());
log.info("执行时间:{}",s);
return String.valueOf(s);
}
public String exc(int i ) {
try {
Thread.sleep(20);
log.info("{}开始执行第{}个",Thread.currentThread().getName(),i);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "第"+i+"个";
}
}
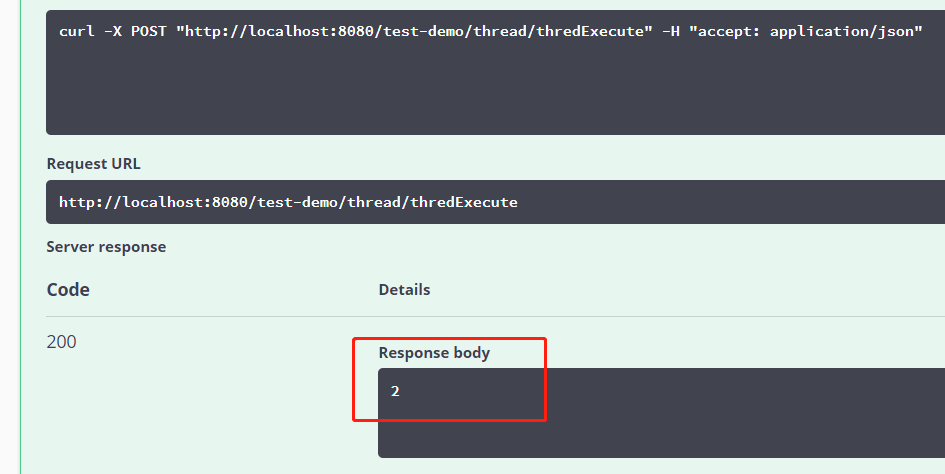
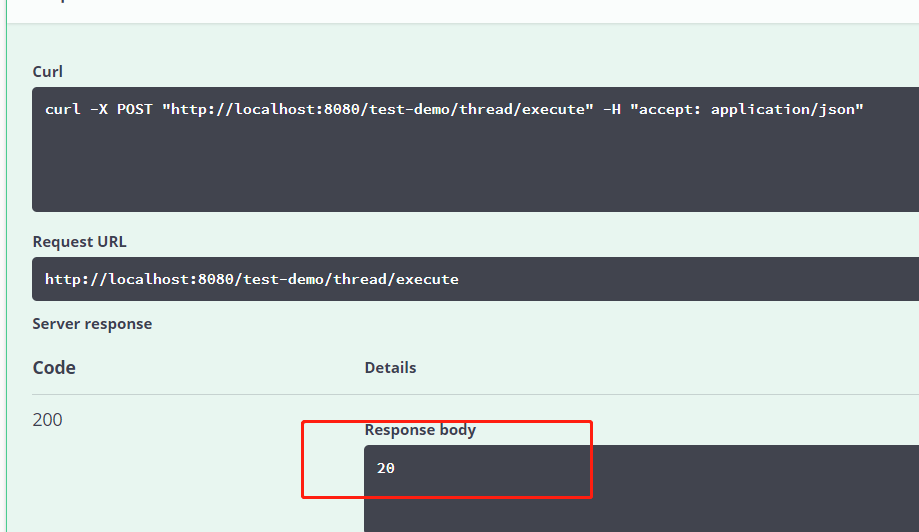
最后咱们通过代码测试一下,同样是遍历一千次,执行操作,单个线程需要20s,而多线程2s就执行完毕了,可见效率高了很多。