前言
【问诊一】

MySql 索引失效、回表解析 【陈先生们,先看这篇】
【问诊二】
正文
话不多说,先当场整点货,搞个200w条数据:
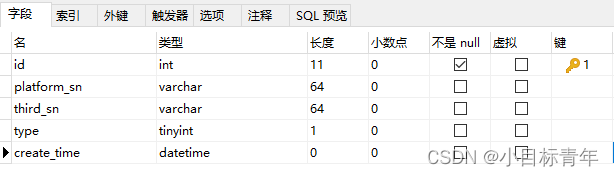
准备一张表:
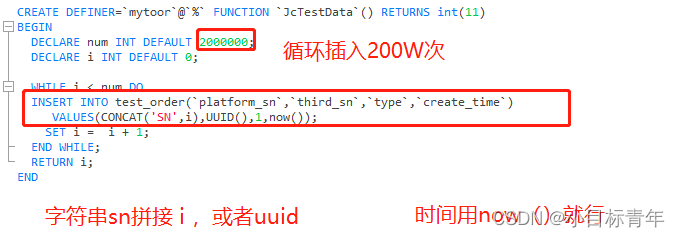
建个函数来造数据:
估计很多初学者可能很少写这些,没关系,可以一起动手试着玩玩:
CREATE DEFINER=`mytoor`@`%` FUNCTION `JcTestData`() RETURNS int(11)
BEGIN
DECLARE num INT DEFAULT 2000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO test_order(`platform_sn`,`third_sn`,`type`,`create_time`)
VALUES(CONCAT('SN',i),UUID(),1,now());
SET i = i + 1;
END WHILE;
RETURN i;
END
简单说一嘴,看明白的可以无视这个(还是那句话学习,是先知后知而已):
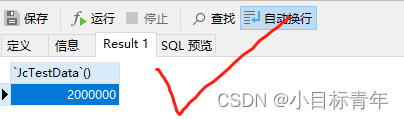
点击运行:

29秒造完,还可以。
货到齐了,准备开搞:
开始演练:
先给type加个索引,模拟一下真实查询场景:

再把几条数据的type数据稍微改一下,:
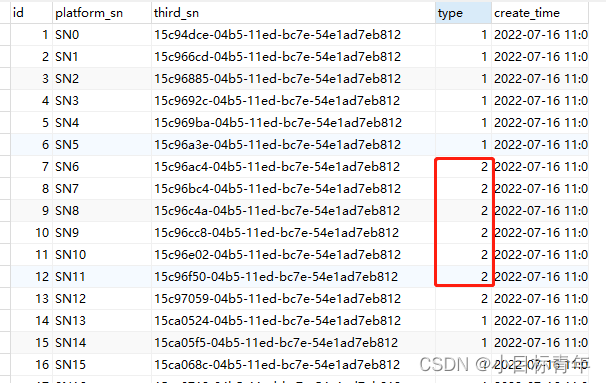
先按照正常的场景分页查询 limit 0,50:
sql:
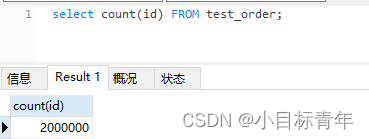
select * FROM test_order where type=1 limit 0,50;
可以看到查询 limit 0,50 速度是很快的,0.022秒:
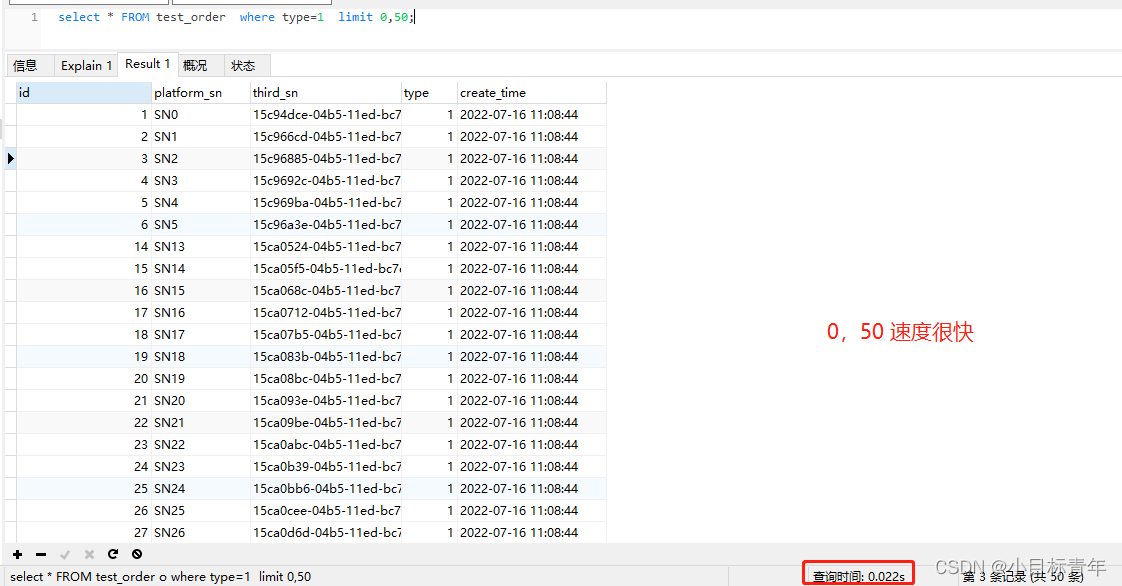
我们接下来模拟成查询N页之后的数据 limit 1200000,50:
120W 条后,偏移 50条数据,roll出来
sql:
select * FROM test_order where type=1 limit 1200000,50;
看看效果,用了3.765秒:
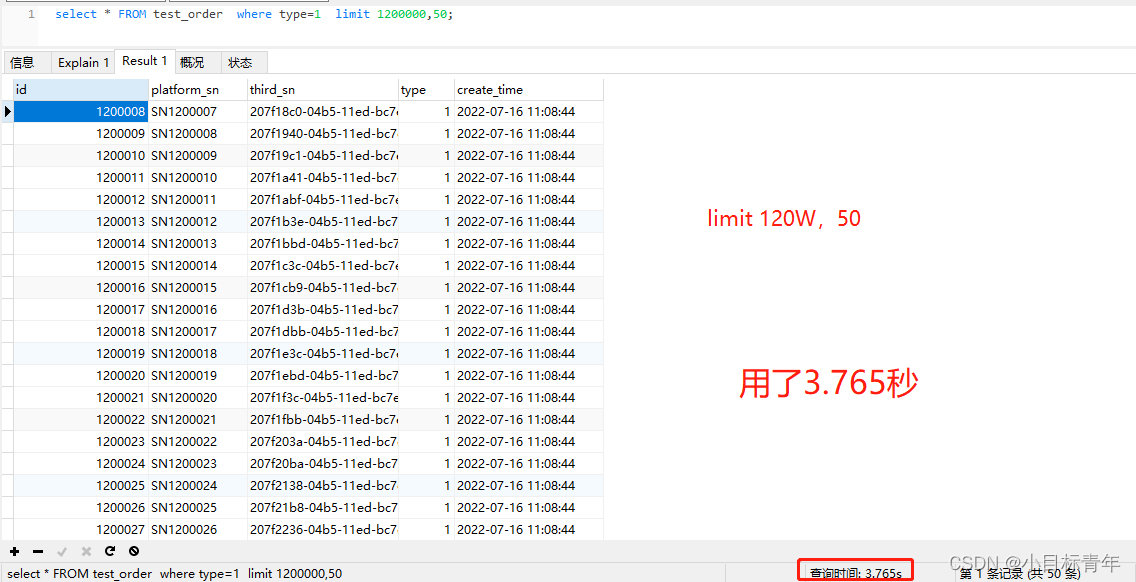
explain:

可以看到已经命中了索引 index_type ,但是还是比较慢,为什么呢?
慢的原因 ①
① 索引 index_type 是非聚簇索引, 而我们查询的语句 是select * ,包含了其他字段。
通过非聚簇索引 index_type roll出来的数据列,只有type 和 id ,那么为了拿其他字段,
就会通过先取聚簇索引 id ,再根据id 拿出所有列值,这也就是回表操作。
慢的原因 ②
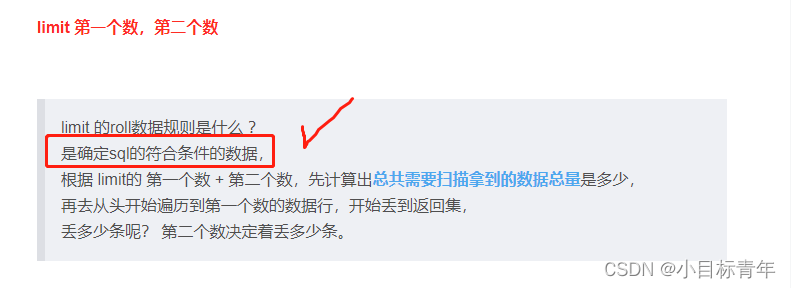
limit 第一个数,第二个数
limit 的roll数据规则是什么 ?
是确定sql的符合条件的数据,
根据 limit的 第一个数 + 第二个数,先计算出总共需要扫描拿到的数据总量是多少,
再去从头开始遍历到第一个数的数据行,开始丢到返回集,
丢多少条呢? 第二个数决定着丢多少条。
limit 示例讲解
也就是limit 0,50 :
计算 0+ 50 =50 , 拿出符合条件的50条 , 从头开始匹对第一个数 0,OK,从0开始就可以把数据丢到返回集。
丢多少? 第二个数是 50,所以会一条条丢,丢50条 ,最后返回数据。
那么如果是我们文章里面执行的 limit 1200000,50 :
120w+50 ....
意味着为了拿50条数据,需要扫描出 1200050 条数据,然后开始迅速得检索第一个数是120W,开始丢掉前面120W条没有意义的数据,然后确定第二个数是50,开始整50条数据丢到返回集里面,最后返回数据。
那么既然知道了这个情况, 我们可以开始玩优化操作。
方案1 :
针对回表方面做优化
如果我们能拿到我们知道返回数据的 id 集,作为条件,这样通过命中非聚簇索引type的时候,直接就能拿到id,这样通过id拿数据列,这样就方便了。
sql:
select * FROM test_order where id in
(
select id from (select id FROM test_order where type=1 limit 1200000,50) child
)
看下效果:
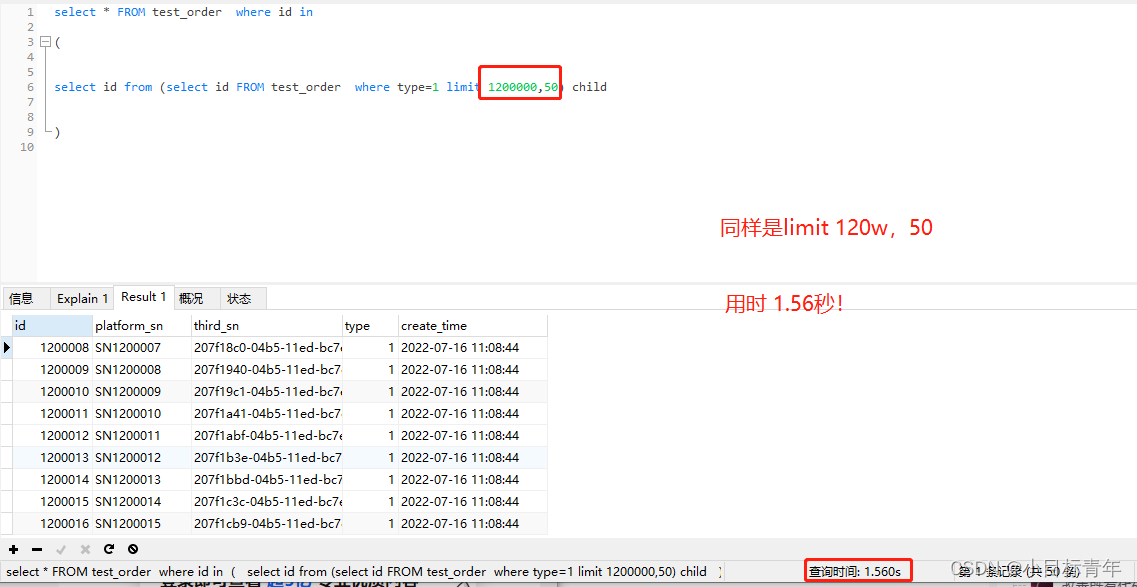
3.765秒 变成了 1.56秒 !!!
3.765秒 变成了 1.56秒 !!!
3.765秒 变成了 1.56秒 !!!
为啥?
explain看看:
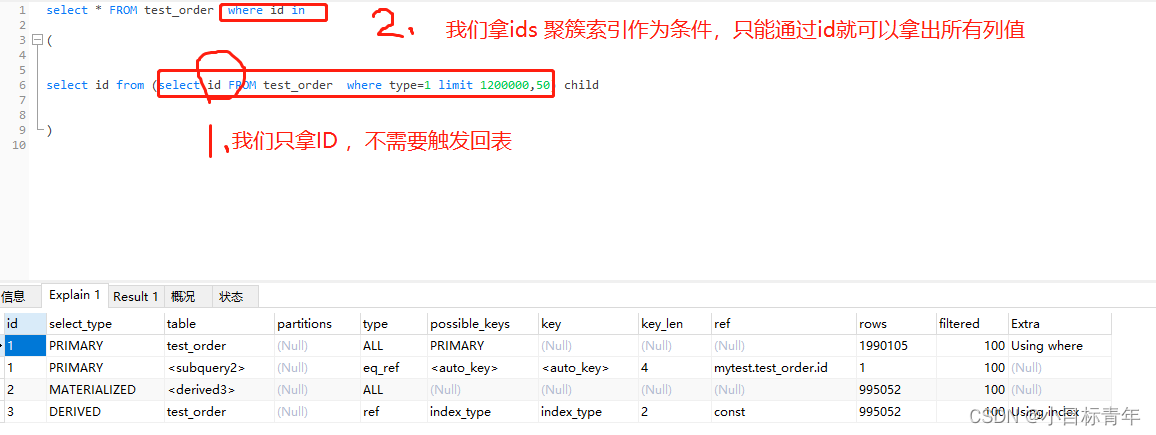
这种情形已经是快了很多了, 但是还有没有操作空间?
回答 : 有。
可以看到当前的优化sql ,其实 还是涉及到了 limit 1200000,50 ,这也就是主要耗费时间的地方。
方案2:使用最小条件值
分页查询避免跳页查询, 我们把上一页的id,作为下一页的起始条件。
上面分析这个sql的规则 :
看一下这个limit 120W,50的数据情况:
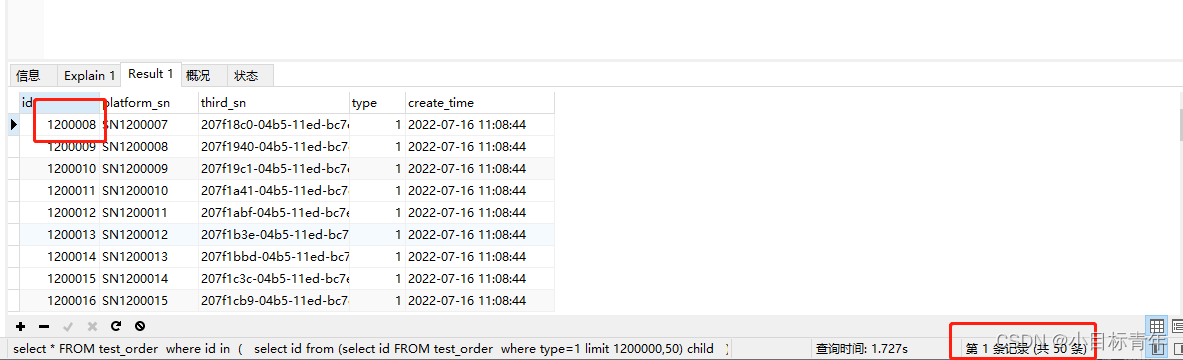
如果我们加上 条件 id >=1200008 , 是不是就非常nice了 。
sql:
select * FROM test_order where type=1 and id >=1200008 limit 50;
看看效果,0.022秒,就跟直接 limit 0,50 一样了效率了:
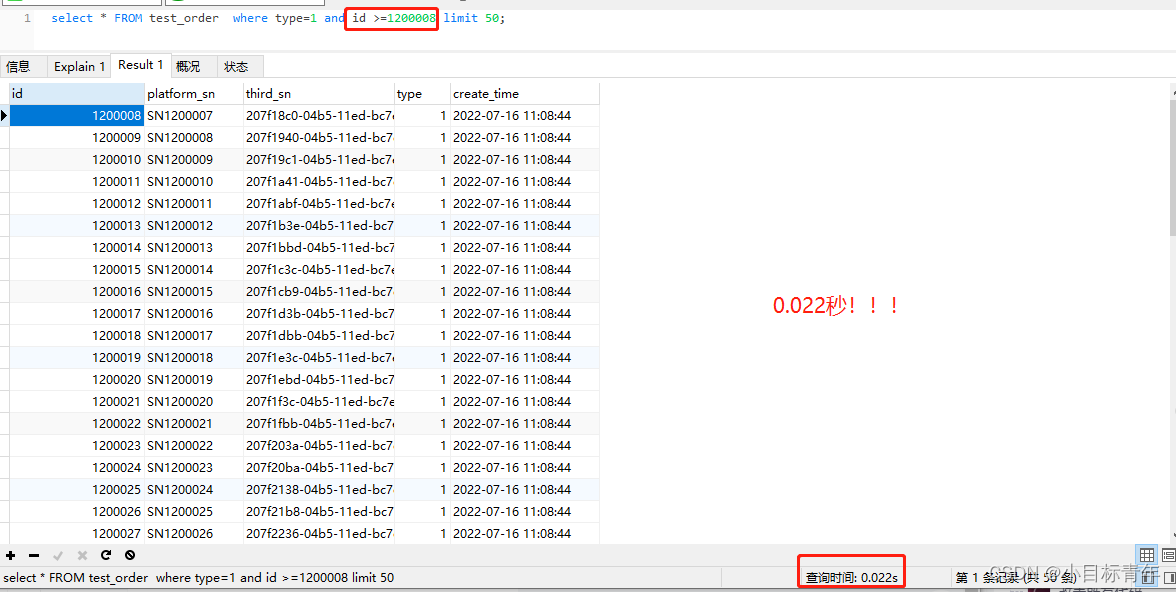
explain:
都中了主键索引了,key:PRINARY

服务端使用方案2:
这种情况,如果是我们代码里面去使用,只需要在操作大批量数据的时候,将上一批数据的最后一条数据的id拿出来。
给到下一批筛选数据,作为最小ID的 条件即可。
其实也就是之前我写过一篇文章留下来的分页优化操作空间:
可以在这篇基础上,加上 上一批次的最小ID作为条件,效率翻倍!
配合前端使用方案2:
给大家看一个现成的大系统的一个触发机制调用图:
随着滑动,自动加载下一页数据, 起始也就是把上一页的最小ID值(可以传其他条件值也可以)透传到下一页。这种其实我们产品体验上的滑动加载,瀑布流形式。
好了,该篇就到这,关注我,点赞,收藏(给我知道你们在,给我知道你们懂我)。










