
Approach to Incorporating External Knowledge
预训练+微调 neural topic model
Abstract
现存问题
- PWEs:引入预先学好的word embedding
- PLMs:预训练模型
对任务的改进很有限但是需要巨大的计算开销。
提出了一种将外部知识纳入topic model的新策略,模型在大型语料库上进行预训练,然后在目标数据集上进行微调。
- 优于当前最先进的topic model和一些通过 PWEs 或 PLMs 优化的方法。
- 减少了对大量训练数据的需求。
Introduction
主题模型是以无监督的方式从大量文档中发现隐藏的主题。
为了避免基于图模型的方法(如LDA)的复杂而具体的推理过程,
该领域的主要研究方向变为:利用基于神经网络的黑盒推理的topic model。
通常,神经主题模型通过利用文档的词袋(BOW)表示来捕获单词共现模式来推断文档的主题。然而,BOWs表示未能编码丰富的单词语义,导致主题模型生成的主题质量相对较低。
已经提出了一些方法来通过结合外部知识来解决BOWs表示的局限性:
- 静态词嵌入:预训练word embedding (PWEs)
- 动态词嵌入:预训练语言模型 (PLMs)
会根据上下文为单词的每次出现生成特定的单词嵌入。PLM 生成的上下文嵌入编码更丰富的语义并且自然地处理单词多义性。
- 直接的方法是在现有主题模型中用 PLM 的输出替换 BoW 表示或者将 PLM 输出作为附加输入topic model更复杂的方法是将 PLM 的知识提炼成topic model。
Improving Neural Topic Models using Knowledge Distillation.
但是,上述方法仍然存在局限性。
- 以这种方式使用 PLM 进行主题模型训练会导致巨大的计算开销。topic model基于具有少量隐藏单元的浅层多层感知,大多PLMs基于Transformer,因此,整体训练时间以 PLM 为主,如果 PLM 进一步微调会更糟。
- PLMs 和主题模型之间存在训练目标的差距,PLMs 被训练来学习句子中的语义和句法知识,而主题模型专注于提取整个语料库的主题。二者之间有壁。
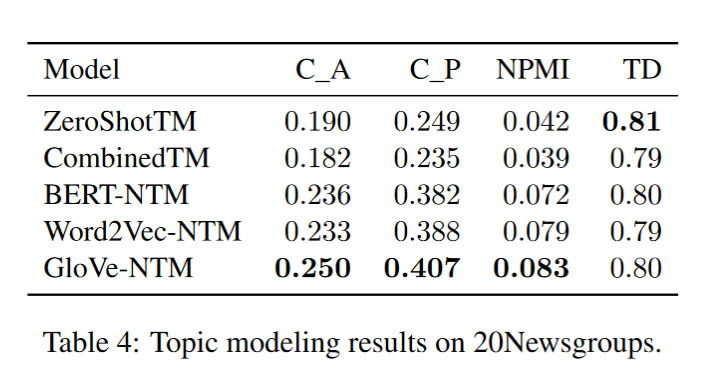
- 表 4 :基于 GloVe 嵌入的模型比基于 PLM 的模型表现更好。
主要贡献:
- 简单有效的topic model训练策略,模型在大型语料库上进行预训练,然后在特定数据集上进行微调。
- 预训练的topic model在主题连贯性和主题多样性方面明显优于baseline。
- 减少了所需的训练数据量。
对 NYTimes 数据集的实验中,使用 1% 的文档微调的预训练模型比在整个数据集上训练的baseline具有更好的性能。
Method
模型
预训练
通过在大型且主题多样的语料库上预训练主题模型,希望该模型能够学习到足够通用的主题相关知识,以便在其他语料库上重用。
预训练语料 是 OpenWebText 数据集的子集(subset00)。

微调
随机重新初始化最后一个编码器和第一个解码器中的参数。

微调过程对训练阶段的开销很小。在推理过程中不会引入任何额外的计算或参数。









