CMR
看一张比较有说服力的图(是师姐让我看的这个文章,她觉得对她的论文有用。我就开始看,然后把图直接pia给她,她说“好有说服力的一张图”)。
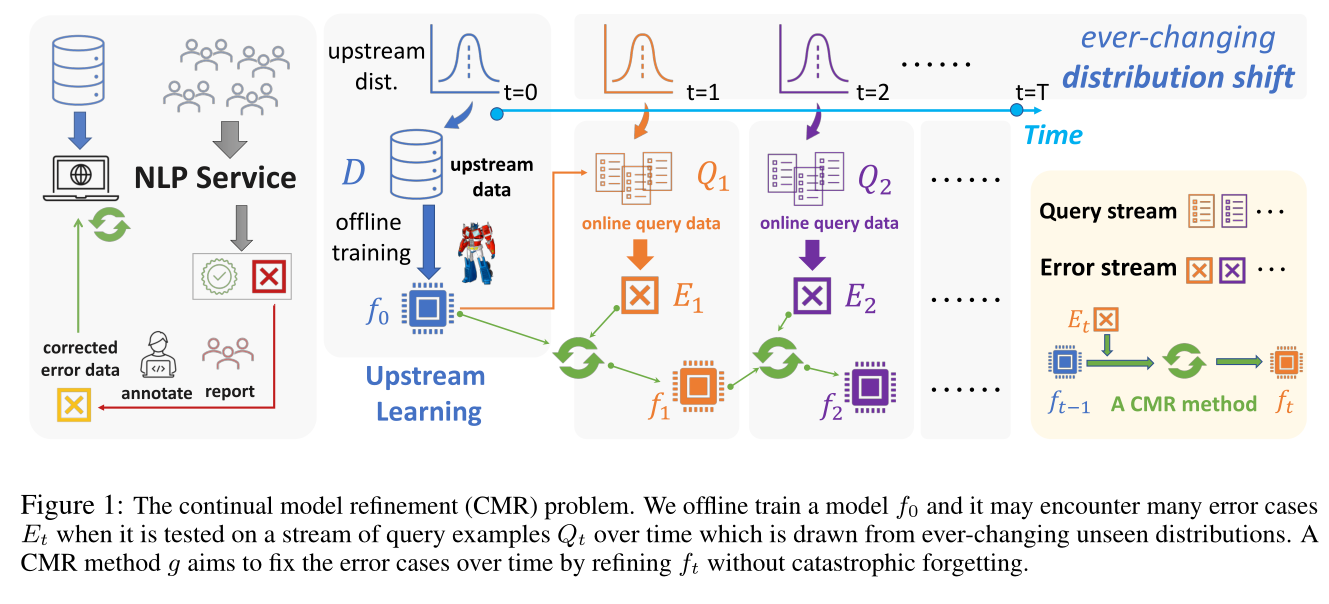
当我们离线训练好一个模型$f_0$之后,我们把它部署出去,当他遇到分布外的数据(out of distribution data)的时候,就会报错,产生一个$E_1$。然后我们就需要回来把这个模型更新,就得到我们的新模型$f_1$,然后再把它部署上线;它又会遇到分布外的一些数据,然后会报错产生一个$E_2$ ,然后我们再把这个模型拿回来再更新,得到一个$f_2$
。如此循环往复。
CMR 方法 旨在通过在不发生灾难性遗忘的情况下改进 $f_t$ 来修复错误情况。
关于持续学习和交代一下遗忘的概念:
方法
基本模型:
使用 BART-base 作为基础模型。
注意,文中的任务目标不是用上游数据集 $D$ 离线训练一个完美的上游模型 $f_0$,而是专注于可以不断改进给定上游模型的 CMR 方法。
持续性微调 Continual fine-tuning:
最直接的方法是始终使用普通优化器(例如Adam )在$Et$ 上以较小的学习率微调 $f{t−1}$ 模型几个 epoch,目标是在 $Et$ 上最小化损失 $L{Error(t)}$得到微调模型 $f_t$。这样的精炼模型 $f_t$ 应该能够为这些已知错误输出正确的输出。
但是这种方法可能会在这些错误数据上过拟合,从而导致忘记了以前获得的知识,也就是灾难性遗忘。
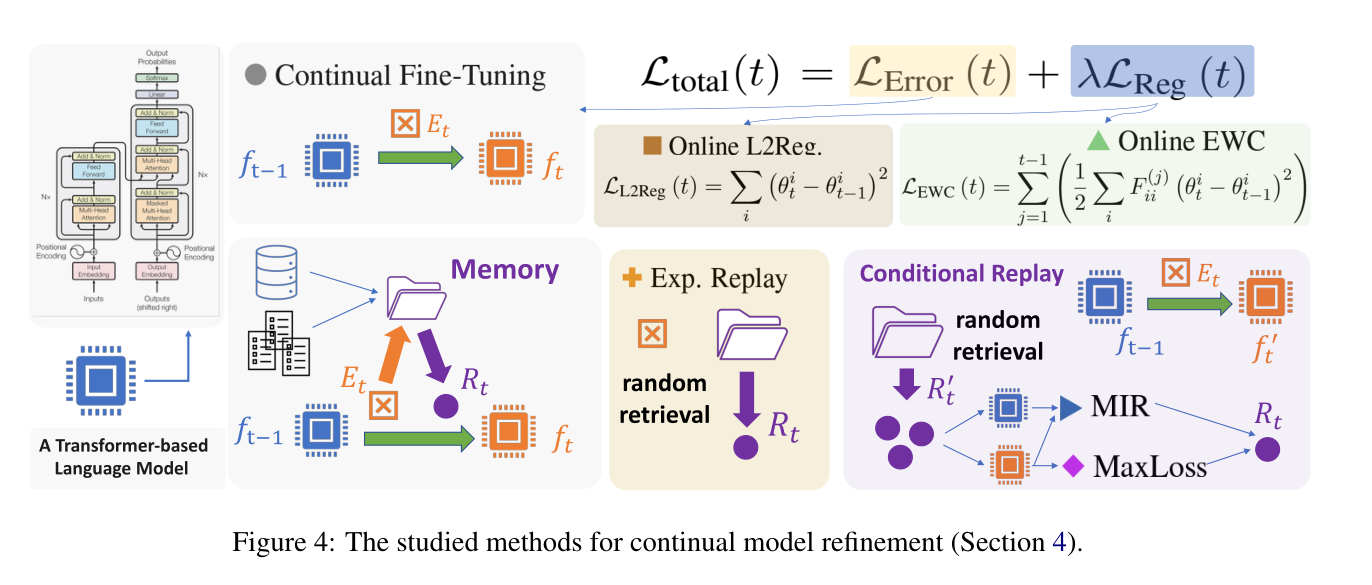
用到的正则化方法
结合上图,接下来我们介绍几种正则化方法。
防止遗忘的一个常见解决方案是在损失中添加一个时间正则化项以进行连续微调:$L{total(t) }= L{Error (t) }+ λL{Reg (t)}$,从而限制从 $f{t−1}$ 到 $f_t$ 的参数变化,以避免产生过拟合。
- Online L2Reg
计算参数之间的 L2 距离使用直观的正则化项。
$$
\mathcal{L}{\mathrm{L} 2 \mathrm{Reg}}(t)=\sum{i}\left(\theta{t}^{i}-\theta{t-1}^{i}\right)^{2}
$$
其中$θ_t$ 是 $f_t$ 的参数。
这个正则化项通过对每个参数变化施加惩罚来缓解遗忘问题。
- Online EWC
弹性权重合并 (Kirkpatrick et al., 2017) 是持续学习(continual learning)的典型正则化方法。和L2正则化不同,L2正则化对每个参数变化给予相等的惩罚,EWC产生加权惩罚。使得对先前任务更重要的参数将具有更大的惩罚权重,引导参数变化找到重叠空间,使先前的知识和新知识都可以的存储在参数中。特别是,它有效地估计了 Fisher 信息矩阵 $F ^{(t)}{ ii}$ 并将它们用于合并加权惩罚:
$$
\mathcal{L}{\mathrm{EWC}}(t)=\sum{j=1}^{t-1}\left(\frac{1}{2} \sum{i} F{i i}^{(j)}\left(\theta{t}^{i}-\theta{t-1}^{i}\right)^{2}\right)
$$
我们在运算中维护一个值来保存 $F{ii}$ 总和,对 EWC 扩展,可以用来避免模型调优过程中的计算成本增长。
Replay 方法
持续学习中用到的另一种方法是Replay。
Experience replay
是一种简单而有效的重放方法,它将先前的样本存储到内存模块$M$中,M会随着时间发展不断变大。然后,我们定期(每 $k$ 个时间步长)对$M$的一小部分进行采样得到 $R_t$,作为模型细化的额外训练样本。它使用两个阶段的过程:在 $Rt$ 上微调 $f{t-1}$ 以获得,然后在 $Et$ 上微调 $f'{t-1}$ 以获得 $f_{t}$。
Maximally interfered replay (MIR)
MIR 不是从 $M$ 中随机选择 $Rt$ ,而是以当前的 $f{t-1}$ 和 $E_t$ 为条件,选择replay最容易被模型遗忘的样本。MIR从$M$中采样出一个小一点的样本候选池$C$, $C ⊂ M$ ,然后按照“干扰分数”对 $C $中的样本进行排名。最后,MIR 的 $R_t$ 是 $C$ 中得分最高的子集。
在这里加了一个步骤,需要计算干扰分数,我们首先在 $Et$ 上微调 $f{t-1}$ 以获得一个虚拟模型 $\hat{ft}$。然后,我们计算 C 中每个样本的 $f{t-1}$ 和 $\hat{ft}$ 的损失,以获得干扰分数(即损失增量):
$$
\operatorname{score}\left(x{i}, y{i}\right)=: \operatorname{loss}\left(\hat{f}{t}\left(x{i}\right), y{i}\right)-\operatorname{loss}\left(f{t-1}\left(x{i}\right), y_{i}\right)
$$
MaxLoss replay
这个是作者自创的replay方法。
- Accelerating deep learning by focusing on the biggest losers.
- Ordered SGD: A new stochastic optimization framework for empirical risk minimization.
上边两篇文章表明使用损失最大的样本进行学习可以提高学习效率,因此通过将MIR中的评分函数重新定义为$\operatorname{score}^{\prime}\left(x{i}, y{i}\right)=: \operatorname{loss}\left(\hat{f}{t}\left(x{i}\right), y_{i}\right)$,并将其称为 MaxLoss,它采用虚拟模型 $\hat{f_t}$ 中损失最大的样本(而不是 MIR 中的最大增量)。
CMR 的扩展:
-
Bi-Memory: 在 CMR 中维护两种类型的知识:
- 上游任务的知识$D$
- 模型后期遇到的错误 $E_t$
考虑到上游数据D远大于后期模型实践中遇到的错误 $E_t$ ,作者认为在其他连续学习问题中使用单个内存模块是不合理的。因此,文章中使用两个独立的内存模块 $M_U$ 和 $M_O$,其中上游任务的样本 是 $M_U=D$ ,后期错误积累 $M_O$ 通过添加 $E_t$ 不断扩大。
- Mixed-Tuning: 我们选择混合 $R_t$ 和 $Et$ 来微调 $f{t-1}$ ,而不是遵循使用 $R_t$的两阶段方法(在 $Rt$ 上微调 $f{t-1}$ 以获得,然后在 $Et$ 上微调 $f'{t-1}$ 以获得 $f_{t}$)。
评价指标
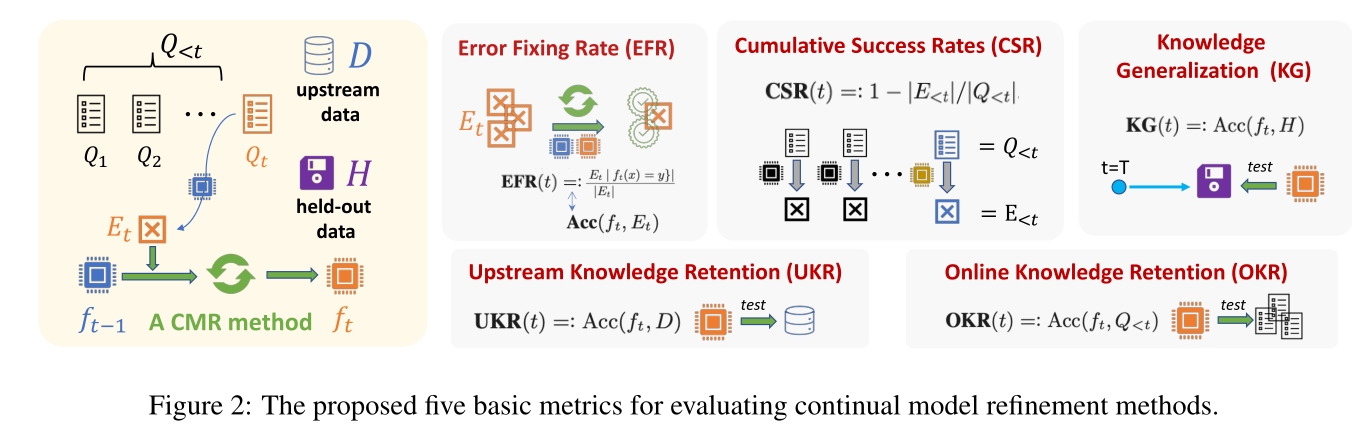
模型采用了5种评价指标:
- Error-fixing rates (EFR) 1
$$
\boldsymbol{\operatorname { E F R }}(t)=: \boldsymbol{\operatorname { A c c }}\left(f{t}, E{t}\right)=: \frac{\left|\left{(x, y) \in E{t} \mid f{t}(x)=y\right}\right|}{\left|E_{t}\right|} .
$$ -
Knowledge retention (UKR&OKR) 2
$$
\mathbf{U K R}(t)=: \operatorname{Acc}\left(f{t}, D\right)\\mathbf{O K R}(t)=: \operatorname{Acc}\left(f{t}, Q_{<t}\right)
$$ - Cumulative success rates (CSR) 1
$$
\operatorname{CSR}(t)=: 1-\left|E{<t}\right| /\left|Q{<t}\right|
$$ - Cumulative success rates (CSR) 1
$$
\mathbf{K G}(t)=: \operatorname{Acc}\left(f_{t}, H\right)
$$
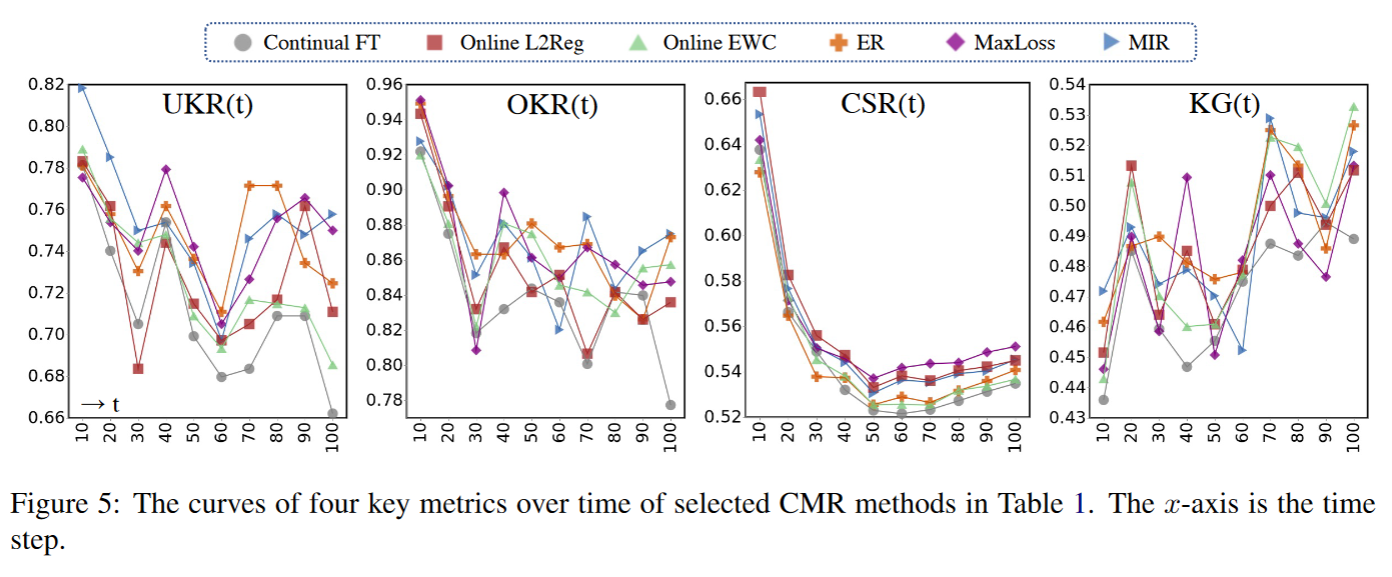
结果可视化