本文是观看上海交通大学陈谐老师在《人机语音通信》课程的讲座的笔记,原视频链接,本文参考[3] [4]。
1 Model Overview: Transformer Transducer
语音识别发展背景:
首先是GMM-HMM:混合高斯模型作声学模型,n-gram作为语言模型,hmm做时序建模模型;
12年深度学习发展,声学模型和语言学模型分别都逐渐被深度神经网络替换;
最近流行的是end2end模型(用存粹的神经网络模型进行语音识别,也不用hmm),模型更简单,此时可以将声学模型和语言模型联合起来进行优化,不再需要复杂的字典、声学模型和语言学模型等,性能也比较好(错误率比之前更低),这种模型结构有三大类:LAS、CTC、RNN-T。
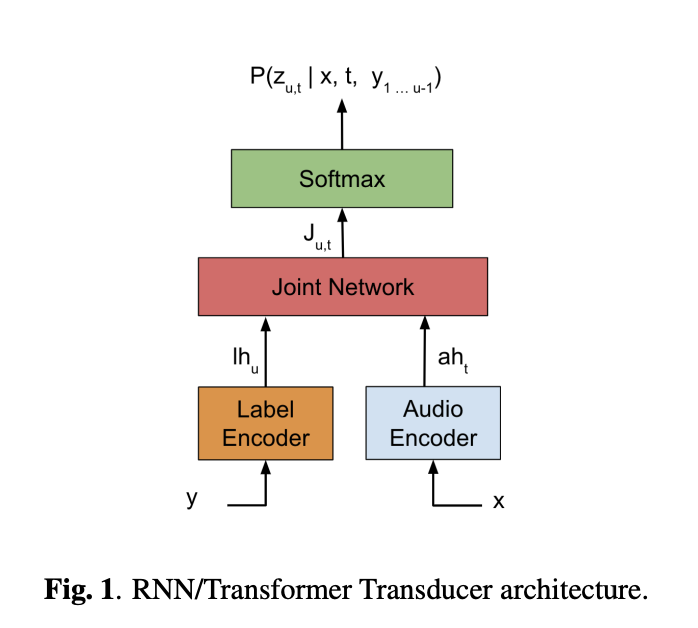
这种端到端的语音识别系统在训练的时候也需要考虑以下因素:准确率、是否能实时处理语音信号、是否能流式处理、域适应问题。目前语音识别领域使用较多、性能较好的是transformer transducer模型[1],结构如下图所示,label encoder和audio encoder两个部分使用的结构是transformer的时候,模型结构为transformer transducer:
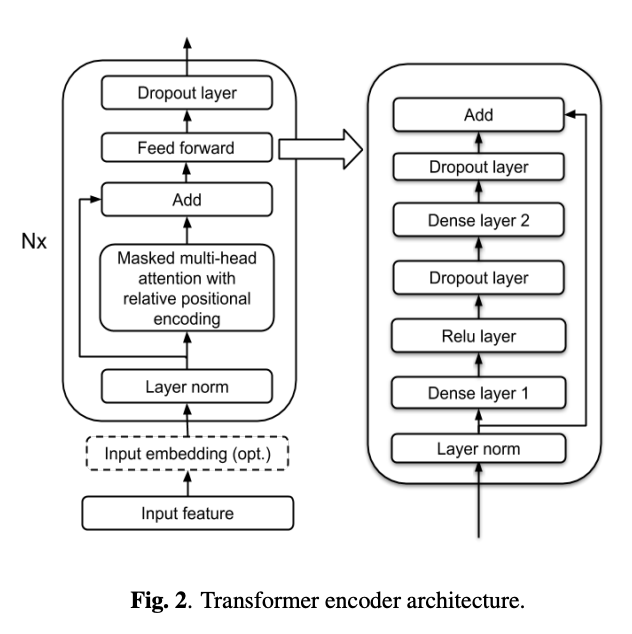
encoder部分使用的transformer结构如下图所示:
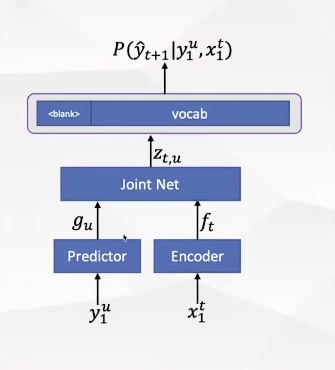
接下来详细解释Neural Transducer的结构如下,一般encoder部分使用transformer结构,predictor部分使用lstm结构,x代表语音信号的输入,y代表识别出来的文字输出,分别经过encoder和predictor之后,代表语音表征f和文字表征g,再将这两个表征进行联合训练(一般是线性层加relu函数)得到表征z,最后利用这个表征z来预测下一个词。
因为输入的语音帧数t一般是远大于文字数u的,因此通常来说,t >> u。为了实现对齐,一般需要在输出的文字中填充blank符号。每一个识别结果填充blank的方式有很多种,对所有填充的可能进行累积起来的概率就是目标函数。
上面这些模型存在两个大问题:
一、流式处理问题
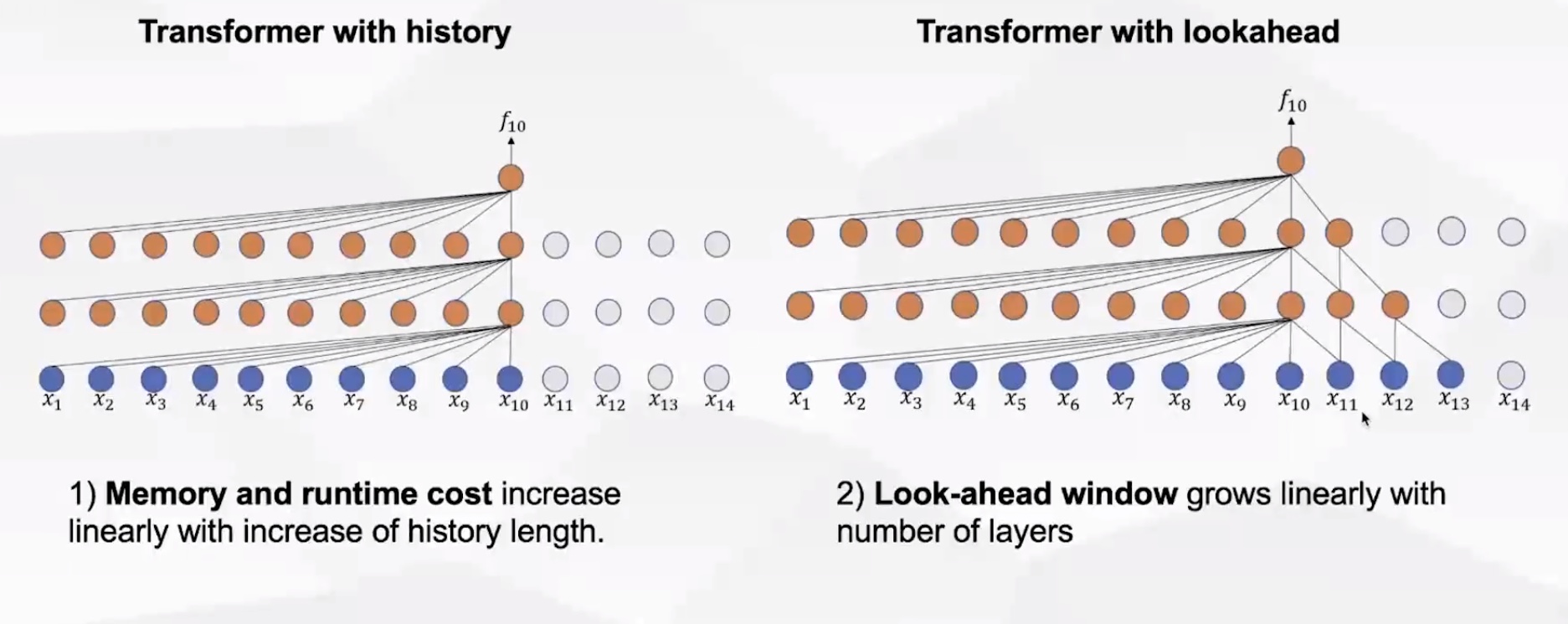
使用transformer做流式处理的时候,由于有attention,会存在两方面的问题:
- 内存和计算量会随着语音帧长的逐渐增加而线性递增;
- 使用未来帧进行预测的时候(允许有一定延迟的情况下,这种方式可以提高识别率),look-ahead window会随着层数的增加而增加。
二、语言自适应问题
此外,传统的声学模型和语言模型分开的情况下,只需要单独在语言模型上进行语言自适应即可,但是transducer模型没有单独的语言模型,因此解决语言自适应问题有困难。
2 Efficient Streaming: Attention Mask is All You Need
针对流式处理问题,使用attention mask is all you need方案来解决,大概是在计算attention weight的时候,设计一个attention mask来决定对哪些帧计算weight,哪些帧不计算weight。
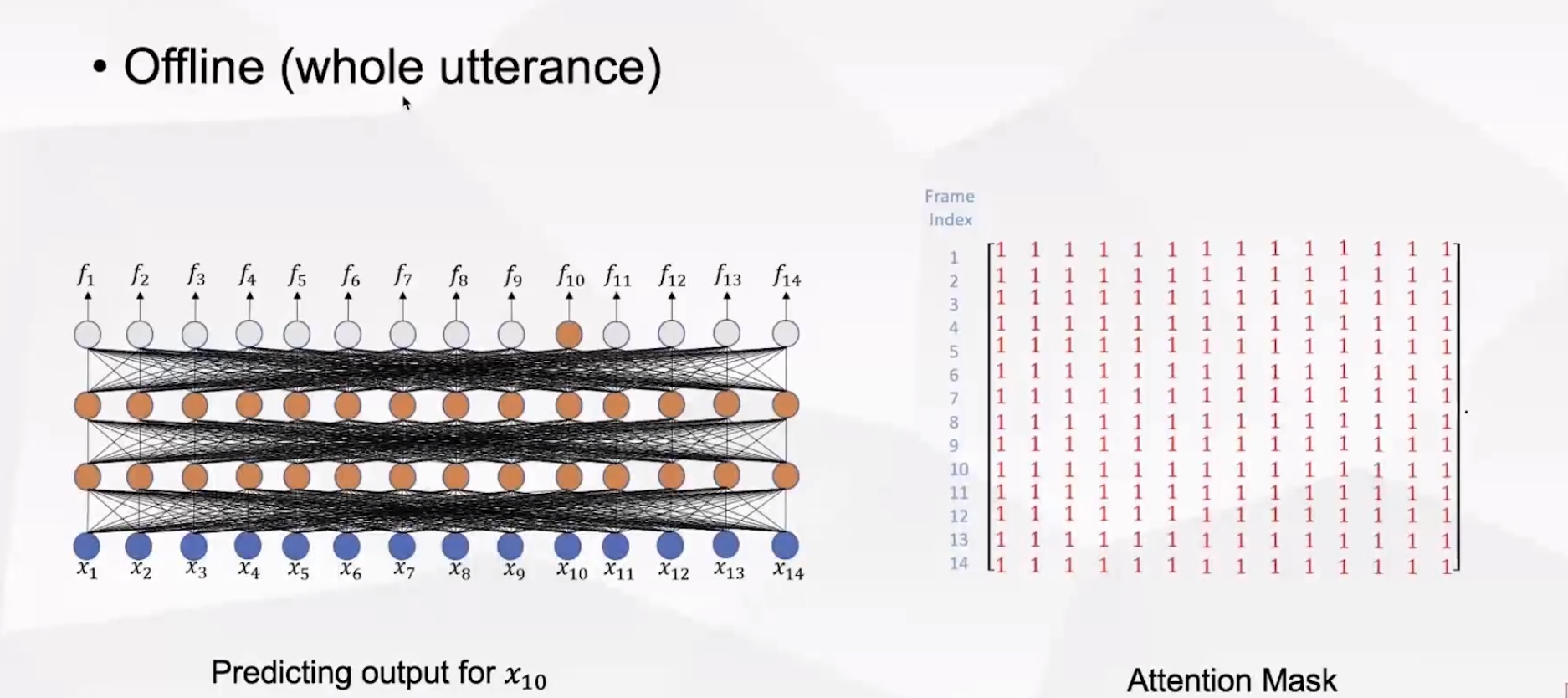
(1)离线系统,对任何一帧的预测都会看到整个句子,此时attention mask设置为全1即可。(非流式识别)
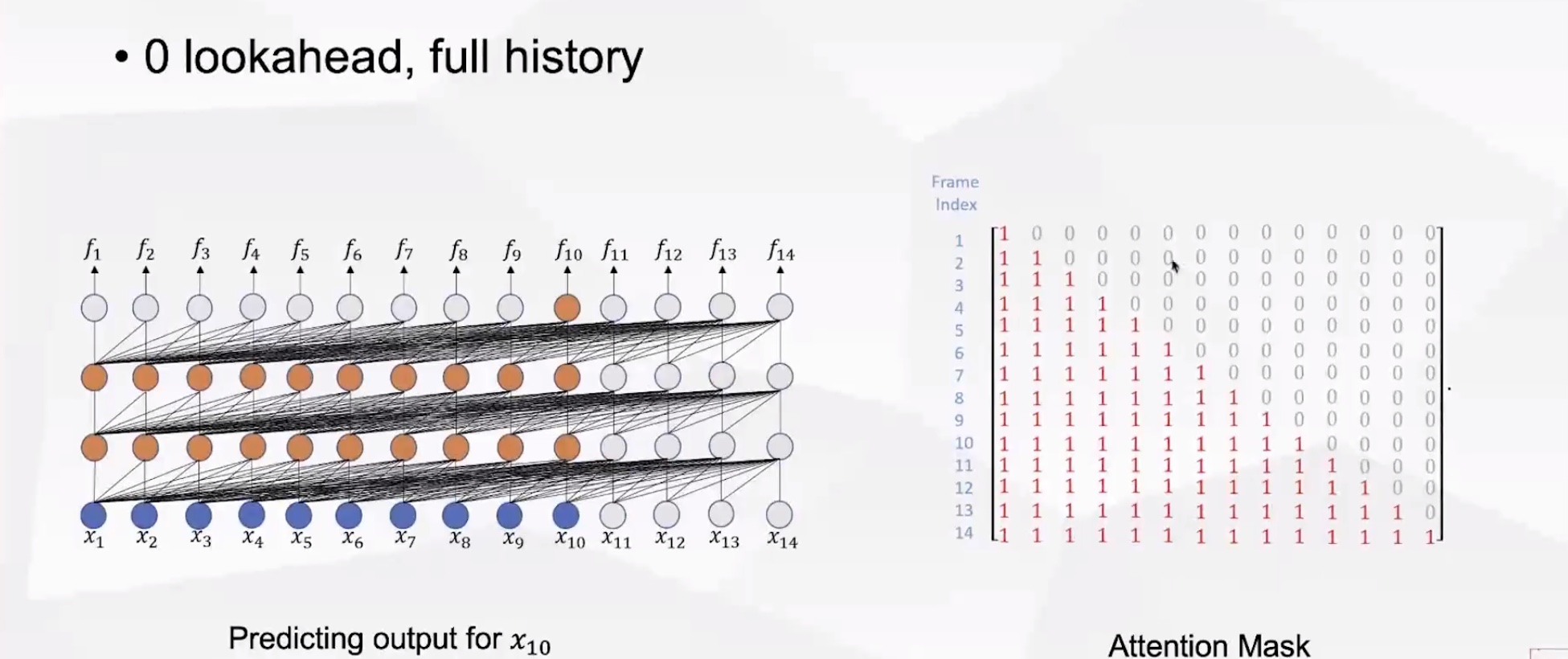
(2)将attention mask设置为下三角,每一帧只能看到历史信息,不能看到未来帧信息,因此不需要等语音结束就可以进行流式识别,但是内存和计算量会随着语音帧长的逐渐增加而线性递增。
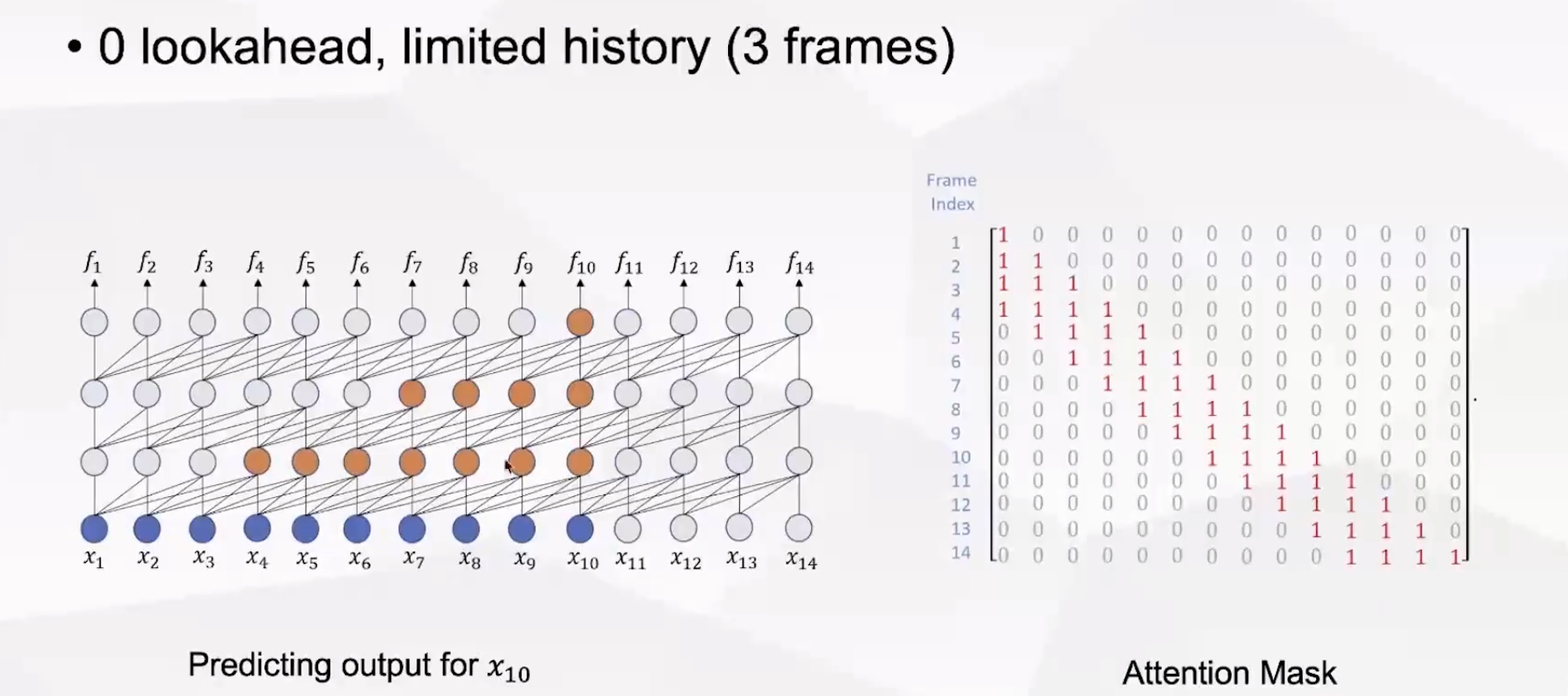
(3)将attention mask中太远的历史帧设置为0,只保存有限的历史帧信息(3帧),因为计算代价不会随着时间的增长而增加(比如识别f10和f100的时候计算量是一样的)。
但是某些情况下,允许存在一定的延迟以提高识别性能,即需要对未来的某些帧也计算attention weight。
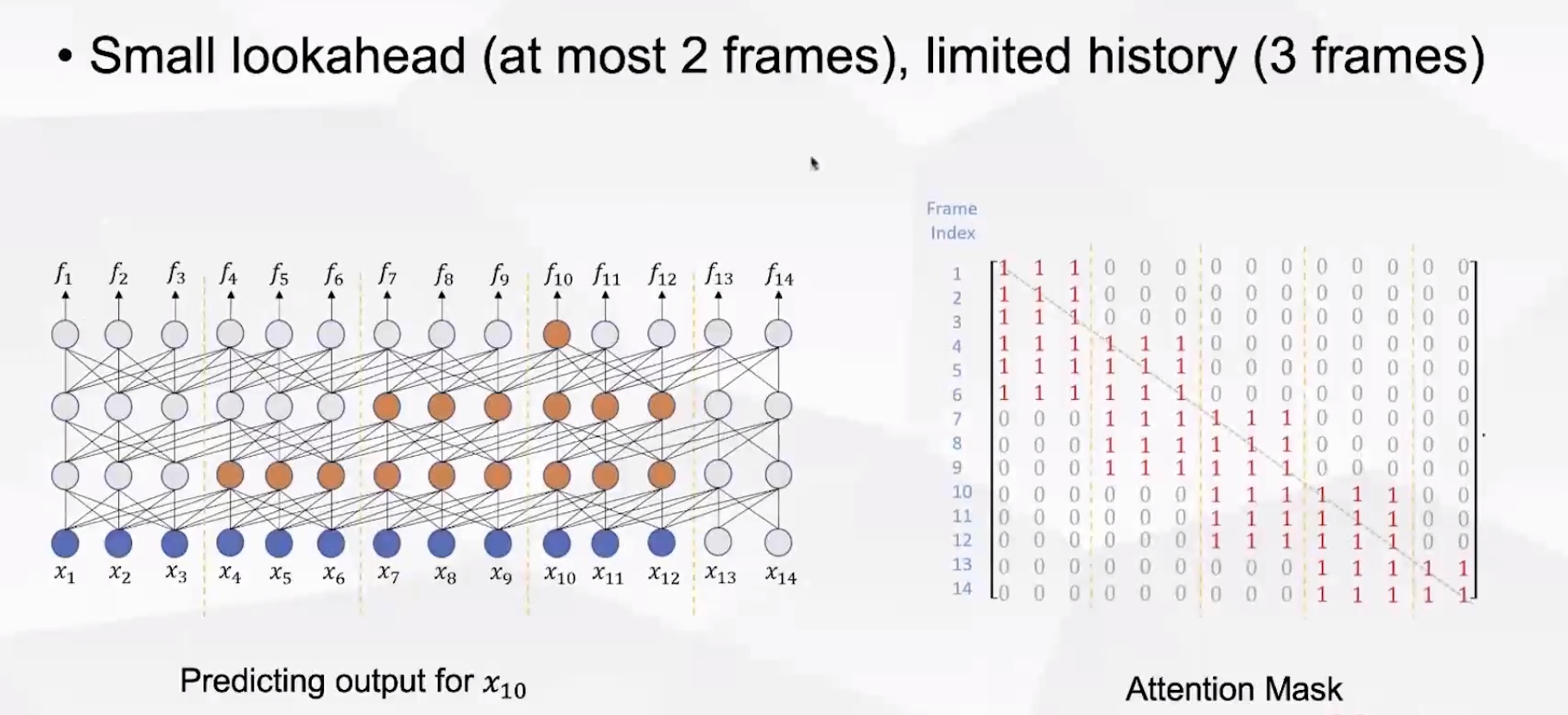
(4)允许看到未来最多两帧(lookahead window为[0, 2]),历史3帧。
(5)上面的mask可能存在某些帧仍然看不到未来帧的信息,因此有了下面的mask,look-ahead window为[1, 3](这种方式计算量难免会稍微增加)
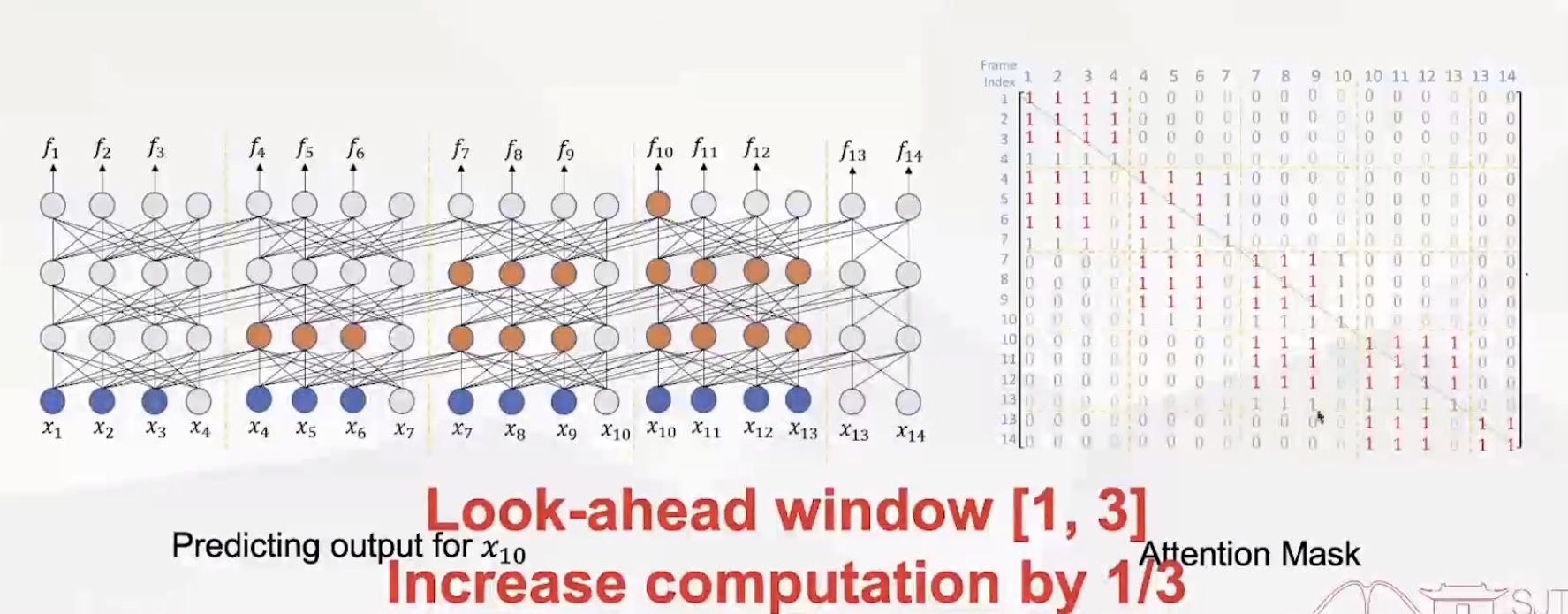
实验表明,每一层也并不需要看到所有帧的历史信息,只需要看到一定数量的历史帧,识别错误率也和全部历史帧的错误率差别不大。
3 Efficient LM Adaptation: Factorized Neural Transducer
针对语言模型自适应问题,目前存在三个解决方法:
(1)基于TTS的方法
首先将目标语言文本进行语音合成,然后将合成的语音和文本输入模型进行finetune,这种方法的缺点就是计算代价比较大。
(2)external LM fusion
(3)fast LM adaptation
对端到端模型中的内部语言模型进行finetune,但是训练流程比较复杂。
因此[2]提出了一种新的解决办法 Factorized Neural Transducer(如下图),将预测blank和预测词的predictor部分分解成两个部分:predictor_b和predictor_v,分别只预测blank和只预测词。因此黄色结构部分就是一个正确的语言模型,它可以用来做语言模型自适应。训练的时候将transducer和语言模型的loss组合起来一起训练,自适应的时候只针对语言模型的loss进行训练。
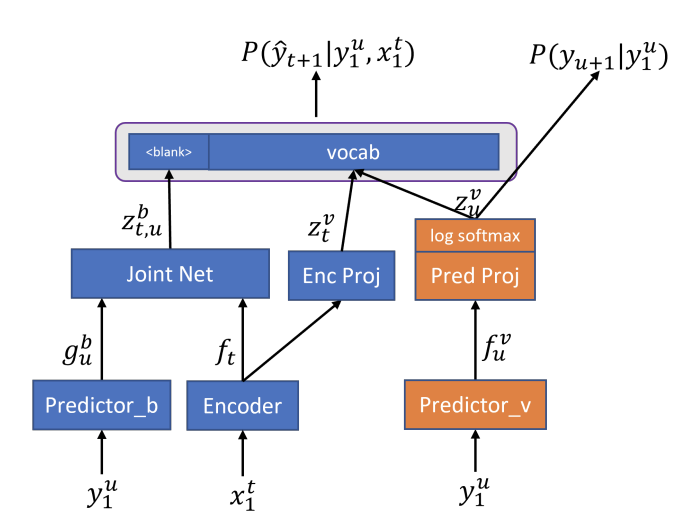
利用文本进行语言模型自适应的实验结果表明,这种模型结构能够有效提升性能。
4 Discussion and Future Work
- 验证语言模型是否真的是语言模型;
- 提高benchmark性能;
- 重新考虑RNN-T中的blank是否科学(正是因为blank的存在才会导致transducer做语言自适应比较复杂),考虑是否需要blank或者是否有更好的blank;
- 还有一些提高性能的问题,比如更好地压缩延迟等。










