1、Kafka为什么采用分区的概念
Kafka消息采用 主题(Topic) - 分区(partition) - 消息的三级结构,每条消息只会保存在某一个分区中,而不会在多个分区被保存多份。
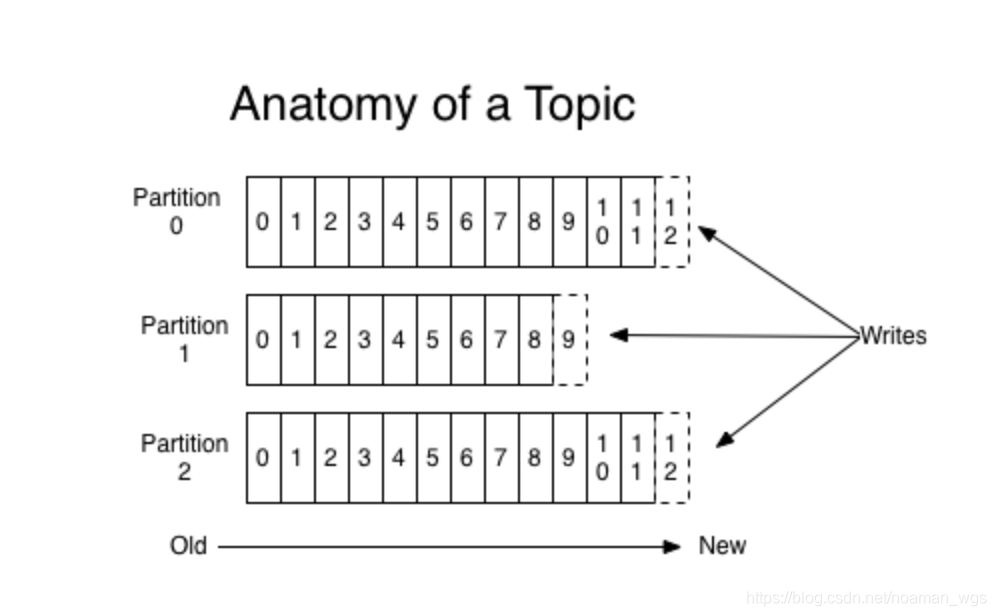
采用分区的作用就是 提供负载均衡的能力,实现系统的高伸缩性。
不同的分区放在不同的节点机器上,数据的读写操作针对的是分区这个粒度,每个节点的机器能够独立执行各自分区的读写处理请求,并且还可以通过添加新的节点机器来增加整体系统的吞吐量。
此外,利用分区还可以实现业务上消息顺序的问题。同一分区上可以保证消息发送的顺序问题,可以通过指定key让消息发送到同一分区上来解决业务上消息顺序的问题,
2、常见的分区策略有哪些
分区策略是指生产者将消息发往哪个分区,常见的分区策略有:
- 轮询策略:顺序分配给不同的分区,默认策略,有比较优秀的负载均衡的能力,也是比较推荐的。
- 随机策略:将消息发往任意一个分区。
- 指定消息键保存:同一个key的消息会被发往同一个分区中,且每个分区下消息的处理都是有序的。
- 自定义策略,实现
org.apache.kafka.clients.producer.Partitioner接口
3、生产者压缩算法
压缩是指用CPU时间去换磁盘空间或者网络I/O传输量,以较小的CPU开销带来更少的磁盘占用或者更少的网络I/O传输。
(1) 压缩
Kafka中压缩发生在两个地方:生产者与Broker端。
生产者端通过props.put("compression.type", "gzip");来开启和使用压缩功能。
Broker端通常不会对消息进行重新压缩,接收到消息只会会保存原封不动地发送出去。对消息进行压缩有两种场景:
- Broker 端指定了和 Producer 端不同的压缩算法
- Broker 端发生了消息格式转换
Broker端采用compression.type 来设置压缩算法,如果该值和生产者端值不一样,那么就会对收到的消息进行解压缩再压缩。(容易造成CPU飙升)
消息格式有多个版本,如果同时存在新老版本的消息集合,那么Broker端会将新消息向老版本的消息进行转换。
(2)解压缩
通常来说解压缩发生在消费者端。生产者端压缩消息,Broker端接收并保存消息,消费者端接收并解压缩消息。
生产者端会将使用何种压缩算法封装在消息集合(注:不是消息,是消息集合)中,消费者端读取消息集合时会根据设置的压缩算法,对消息集合中的消息进行解压缩。
Broker端对接收到的每个消息集合需要进行解压缩操作(注:不是消息,消息不会解压缩,除非发生上述两种Broker端重新压缩的场景后才会对消息进行再压缩和再解压的操作)。
(3)何时开启压缩算法
- Producer端运行的程序机器上CPU资源充足,否则启用消息集合会导致CPU飙升导致CPU被占用;
- 带宽资源有限,建议开启压缩,能极大节省网络资源消耗;
- 尽量避免消息格式转换带来的压缩/解压缩问题。
4、生产者端如何保证消息发送不丢失
当我们通过业务程序向Kafka发送消息的时候,有哪些因素会导致消息发送没有成功呢:
- 网络抖动,Producer发送的消息压根没有发送到Broker端;
- 消息过大超过Broker端承受能力导致拒收
- Broker端宕机(这种情况无药可救,只能找运维尽快去解决)
以上都会导致Producer端发送的消息出现“丢失”的假象。
那么如何解决上述问题呢?
Producer端要使用带回调的发送API producer.send(msg, callback),不要使用无回调的API producer.send(msg)。带回调的API中回告诉你Broker端是否接收到Producer端发送的消息,如果未发送成功,就可以知道情况并针对性地去处理,比如重试。
详细实例见:Kafka生产者消息发送代码示例
/**
* 异步发送kafka消息
*
* @param topic
* @param key
* @param message
*/
public void asyncSendMsg(String topic, String key, String message) {
ProducerRecord producerRecord = new ProducerRecord(topic, key, message);
producer.send(producerRecord, (recordMetadata, e) -> {
if (e != null) {
System.out.println("!!!+++error!!!!");
log.error("kafka msg send error, topic={}, key={}, message={}, e={}", topic, key, message, e);
return;
}
// send success
if (recordMetadata != null) {
System.out.println(">>>>>>>message:" + message);
log.info("kafka msg send success, topic={}, key={}, partition:{}, offset:{}, timestamp:{}", topic, key, message, recordMetadata.partition(),
recordMetadata.offset(), recordMetadata.timestamp());
} else {
log.info("kafka msg send success result is null, topic={}, key={}, timestamp:{}", topic, key, message, recordMetadata.timestamp());
}
});
}
生产中,处理消息不丢失的方法:
(1) Producer端配置:
- 使用带回调通知的send API:
producer.send(msg, callback); - 设置
acks=all,代表所有副本Broker都接收到消息才算是“已提交”;
设置retries > 0, 代表Producer的自动重试。当网络出现瞬时抖动时,消息发送可能会失败,
retries > 0的Producer能够自动重试消息发送,避免消息丢失。
(2) Broker端配置
-
unclean.leader.election.enable = false:当某些Broker落户原先Leader数据过多时,如果成为新Leader可能造成消息丢失;设置为false表示不允许 该类Broker成为新Leader; -
replication.factor >= 3:副本数最少为3,让消息在多个Broker上保存,避免单个Broker宕机导致消息丢失; -
min.insync.replicas > 1:消息至少写入几个副本才算“已提交”,保证写入副本的下限,只有在acks=-1的时候生效。 -
replication.factor > min.insync.replicas:如果相等,只要有一个副本挂了,Producer都无法写入。比如都为2,有1个副本挂了,那么min.insync.replicas=2则无法满足。一般推荐设置成 replication.factor = min.insync.replicas + 1。
(3) Consumer端配置
enable.auto.commit设置为false,代码中采用手动提交位移的方式。
5、Kafka Producer TCP管理
Kafka的生成者、消费者、Broker端之间的通信都是采用TCP协议进行通信的,可以使用TCP的一些高级特性,如:多路复用。
(1)生产者与Broker端创建TCP连接的时机
- 生产者与在创建KafkaProducer实例的时候,会在后台创建并启动一个Sender线程,该线程运行时会创建与Broker的连接。
只要我们指定了bootstrap.servers参数值,Prodcuer就会创建与这些配置的Broker的TCP连接,然后会向Broker发送metadata请求尝试获取集群元数据信息。
注:一个Producer会默认向集群中所有的Broker都创建TCP连接,及时可能只会跟其中3台Broker真正进行通信。 - 当Producer尝试给未知的主题topic(不知道topic对应的Partition信息、对应节点信息)发送消息时,会发送requestUpdate请求给Kafka集群,尝试获取最新的元数据信息;
- Producer 通过
metadata.max.age.ms参数定期地去更新元数据信息,默认值为5分钟;
(2)TCP关闭连接的时机
- 用户主动关闭:
producer.close - Producer端通过设置
connections.max.idle.ms参数,表示Producer端与Broker保持TCP连接会话的时机,默认是9分钟。超过9分钟无任何请求Kafka就会关闭TCP连接。设置成-1表示永久保持连接。
6、Kafka Producer 如何保证消息不重复发送
Producer端消息交付可靠性保障有3种:
- 最多一次(at most once):Producer只会发送一次,所以消息不会被重复发送,但是消息可能会丢失;如:因为网络瞬时抖动导致Broker端未接收到消息,消息丢失;
- 至少一次(at least once):消息不会丢失,但有可能被重复发送;通过让Producer禁止重试来实现。
- 精确一次(exactly once):消息不会被丢失,且不会被重复发送。
实际运行中,我们肯定需要保障消息不能丢失,所以一般采用第2或第3种方式。
所以Producer保证消息不重复发送默认前提是消息不会被丢失。现在看看如何实现:
- 幂等
- 事务
(1)幂等性Producer
Kafka自0.11.0.0版本引入幂等性Producer,只要通过props.put(“enable.idempotence”, ture)设置即可,代码不需要任何变动,Kafka会自动进行消息去重。当Producer发送具有相同字段值的消息后,Broker会知晓消息重复并丢弃。
但是幂等性Producer只能保证某个主题在单分区上消息不重复;其次,如果服务重启,这种幂等性就会丢失。
(2)事务性Producer
事务性Producer能够保证将消息原子性写入多个分区;并且服务重启后依然能够保证它们发送消息的exactly once。










