目录
开篇
是时候给生活来点调味剂了,我就打开 CSDN 逛逛有什么新鲜事。发现了这样一个活动:腾讯云 Finops Crane 集训营。
正好我在上一家公司负责过 Kubernetes 容器集群管理,所以抱着学(na)习(jiang)的目的报名了,想看看这个获得 FinOps 基金会授予的全球首个认证降本增效开源的方案有何过人之处。
介绍
一直以来,云原生用户在确保业务稳定和优化运营成本之间,做着两难的选择,为了保证业务的稳定运行,多数用户面临着服务资源配置浪费、现有资源难以管理、计费方式不够灵活透明等诸多问题。
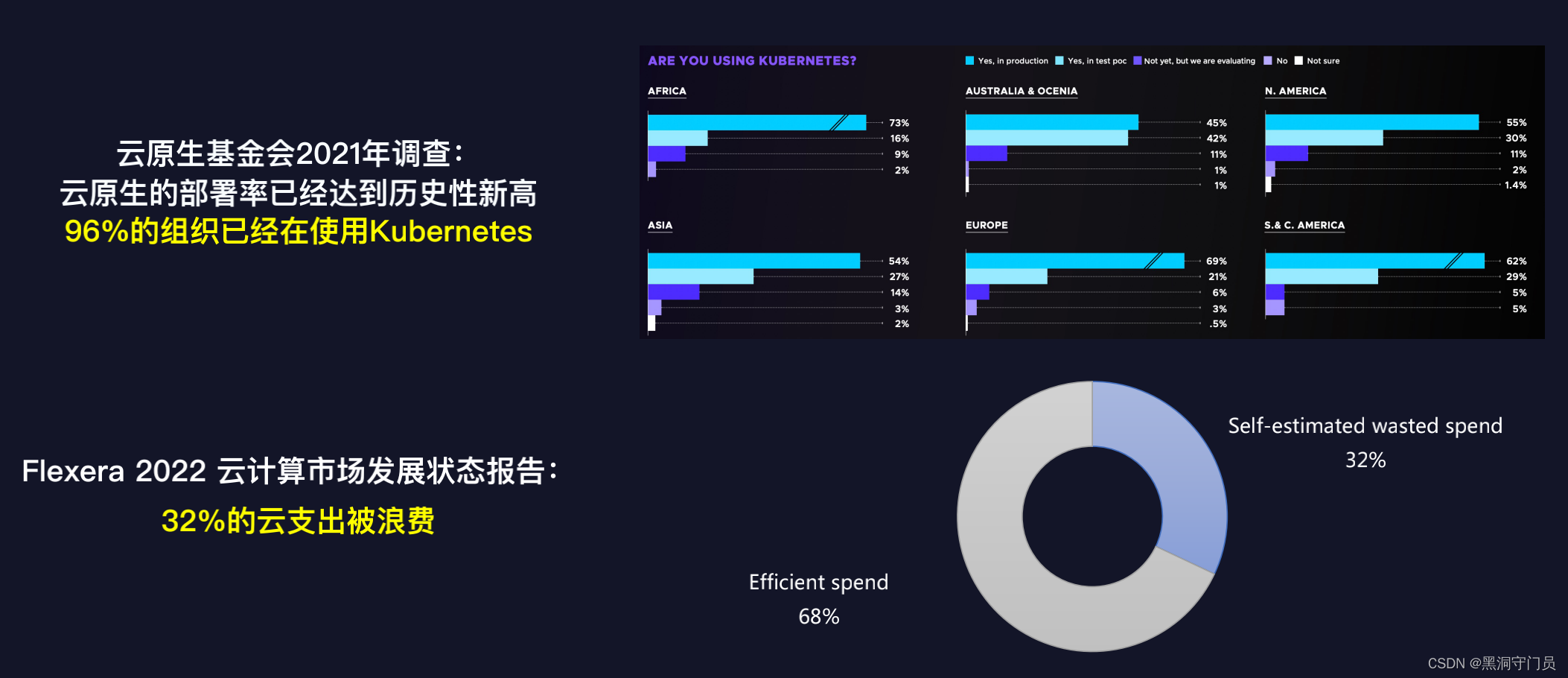
基于越来越多的企业开始拥抱云上服务,腾讯云率先在国内推出了基于云原生技术的成本优化开源项目 Crane。
Crane 遵循 FinOps 标准,依托云原生技术,结合智能预测、自动调度、业务混部等多种手段,将优化措施应用到了云成本优化的多个关键环节,以可视化的方式帮助用户快速决策、简化运维效率、提升系统稳态、全面降本增效,从而为云原生用户提供一站式的云成本优化解决方案。
那么其实际效果如何呢?
众所周知网易新闻的体量是非常巨大的,而以其自身的使用来看,Grane 在落地的两个月内,管控数万 CPU 核 ,大盘总核数缩减11%,下线30台56C物理机,每个月节省10W费用。这样的降本增效效果,堪称一绝。
搭建环境
作为一个云服务管理的菜鸟,在先后经历了 Finops Crane 项目直播简介、开发者集训营实战指导后,我信心满满的开始实操了。
第一步
首先需要安装这几个东西:kubectl、helm、kind、Docker
分别运行下面的命令
# install kubectl
brew install kubectl
# install helm
brew install helm
# 如果 brew 安装不成功,试试
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
# 如果还是不能成功,需要配置下科学上网
如果是版本问题,helm 会告诉你,然后升级下系统版本就好了。我用的是个老的mac 直接在 helm 这里就卡住了,然后换了公司的电脑,还算顺利。

# install kind
brew install kind
# 这里需要验证下是否装成功了,运行
kind create cluster --help
最后安装下 docker
传送门,直接点击对应的版本,下载,安装就可以了。

第二步
接下来,本地安装 Crane 并成功启动
mkdir training
cd training
# 这一步可能需要科学上网
curl -sf https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh | sh -
这一步也是有点慢,最后装完的时候会提示你运行两个命令来访问 Crane Dashboard,看下图
# 按照上图的提示执行这两个命令,这一步配置 KUBECONFIG 环境变量,
export KUBECONFIG=${HOME}/.kube/config_crane
# 这一步部署运行 crane-system项目
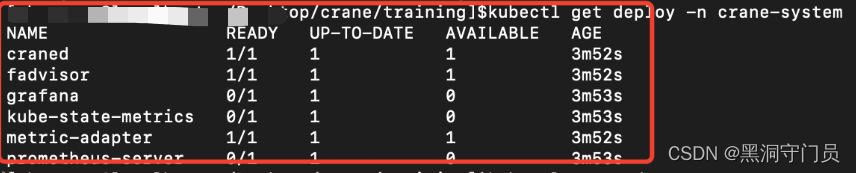
kubectl get deploy -n crane-system
出现下面的截图就算是成功
继续运行
kubectl get pod -n crane-system

看到系统中的镜像状态,有的已经启动,有的则还在拉取,有的正在创建,这时候依然耐心等待,一直到所有的镜像都运行

第三步
直接运行下面的命令
kubectl -n crane-system port-forward service/craned 9090:9090
这一步是把 Kubernetes 内部 service/craned 服务的端口 9090 映射到宿主机的9090,这样可以通过本地主机访问 Kubernetes 操作的内部集群
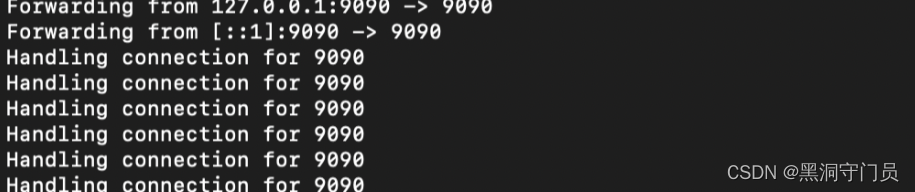
这样就可以访问 Grane 的 dashboard 了。
⚠️:后续的所有操作都需要在一个新的终端上进行,开始一个新终端,需要再次运行export KUBECONFIG=${HOME}/.kube/config_crane
添加集群
在页面中点击添加集群,地址填写: http://dashboard.gocrane.io
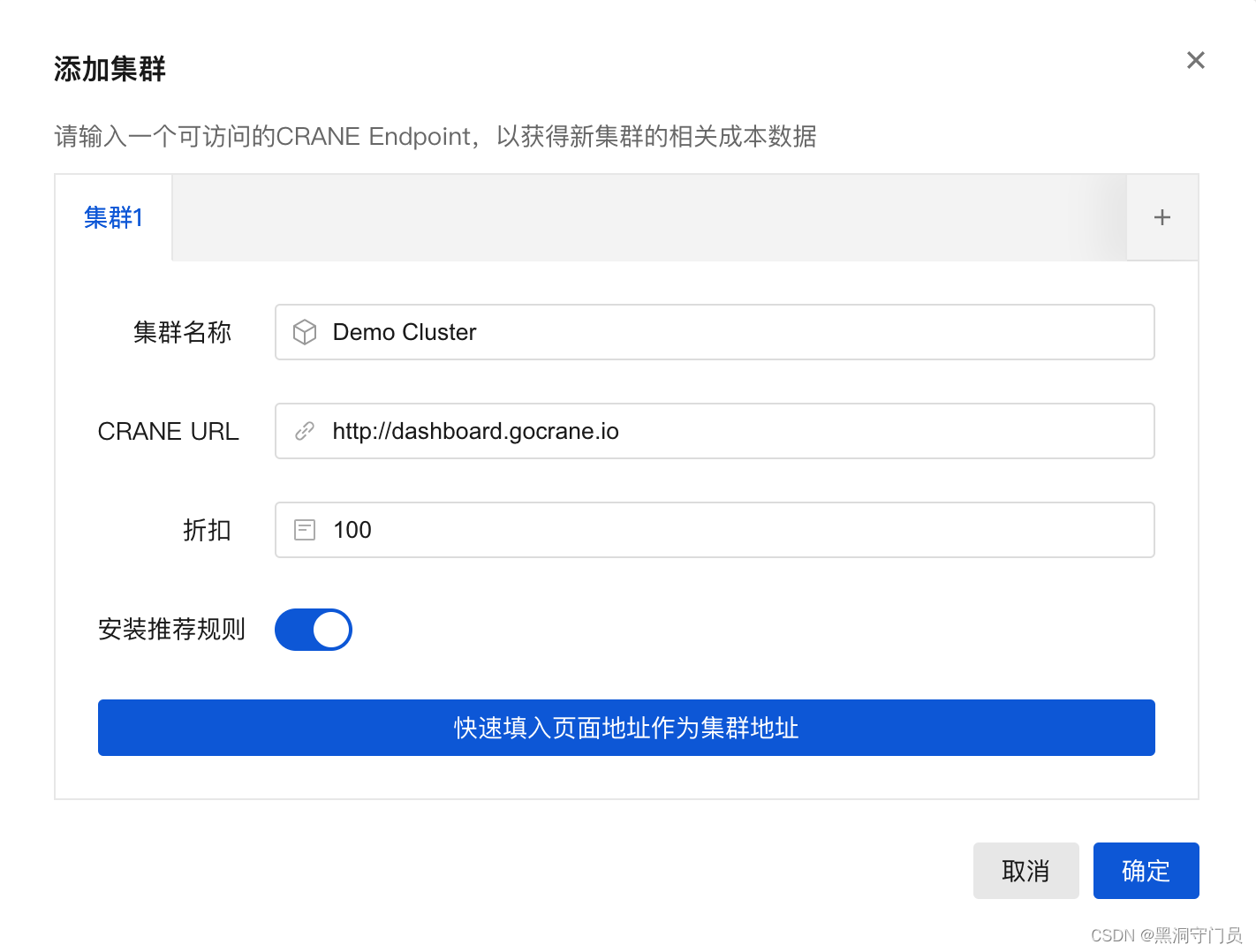
链接成功后就可以在首页看到数据信息
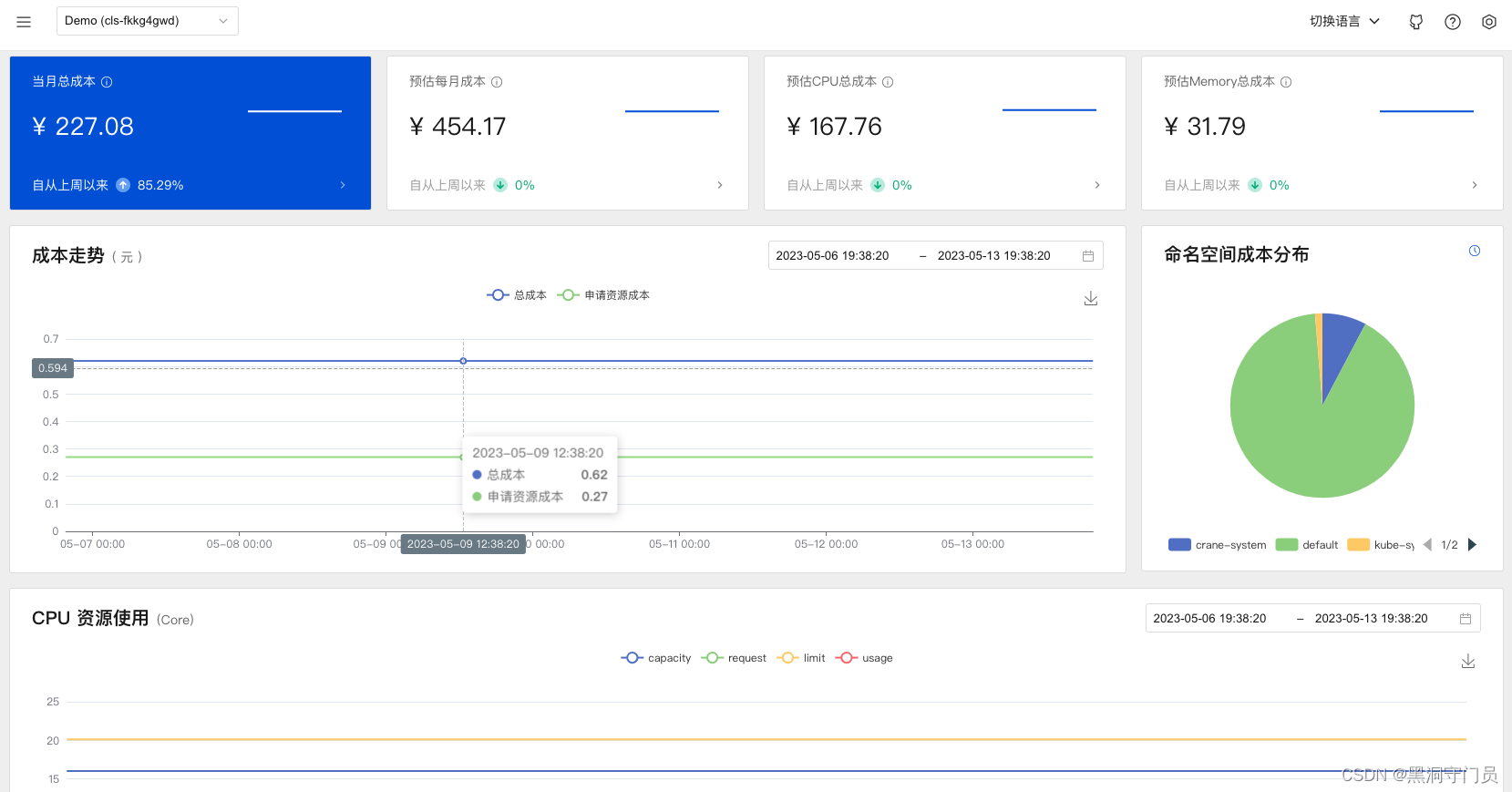
成本洞察
成本洞察可以快速查看集群中的相关信息,比如 cpu 、 内存等占用信息,各个应用信息,成本,碳排放等。这里不做过多的赘述。
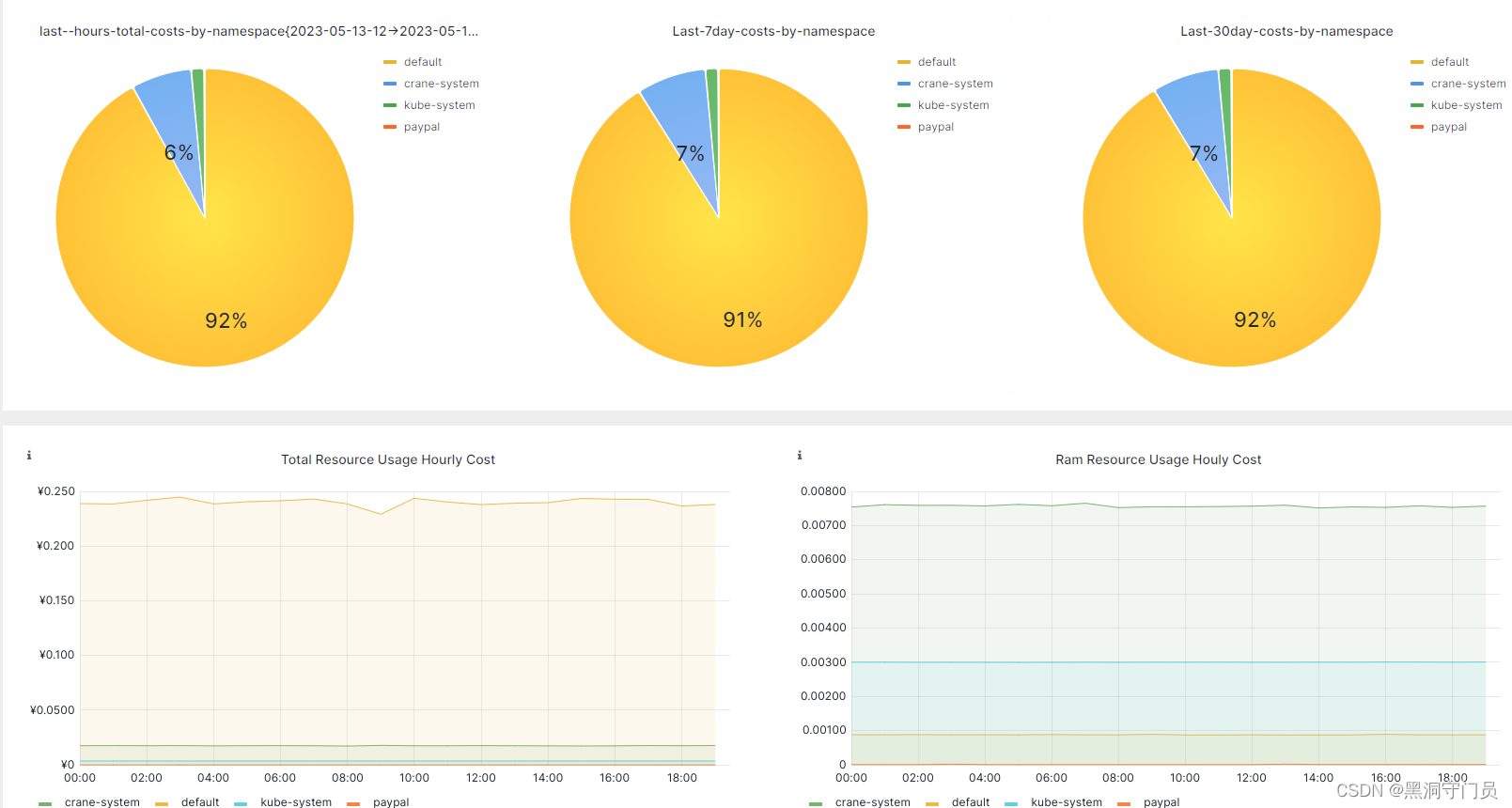
成本分析
成本分析模块会自动分析集群中各种资源的运行情况并给出优化的建议。其实现的流程为:
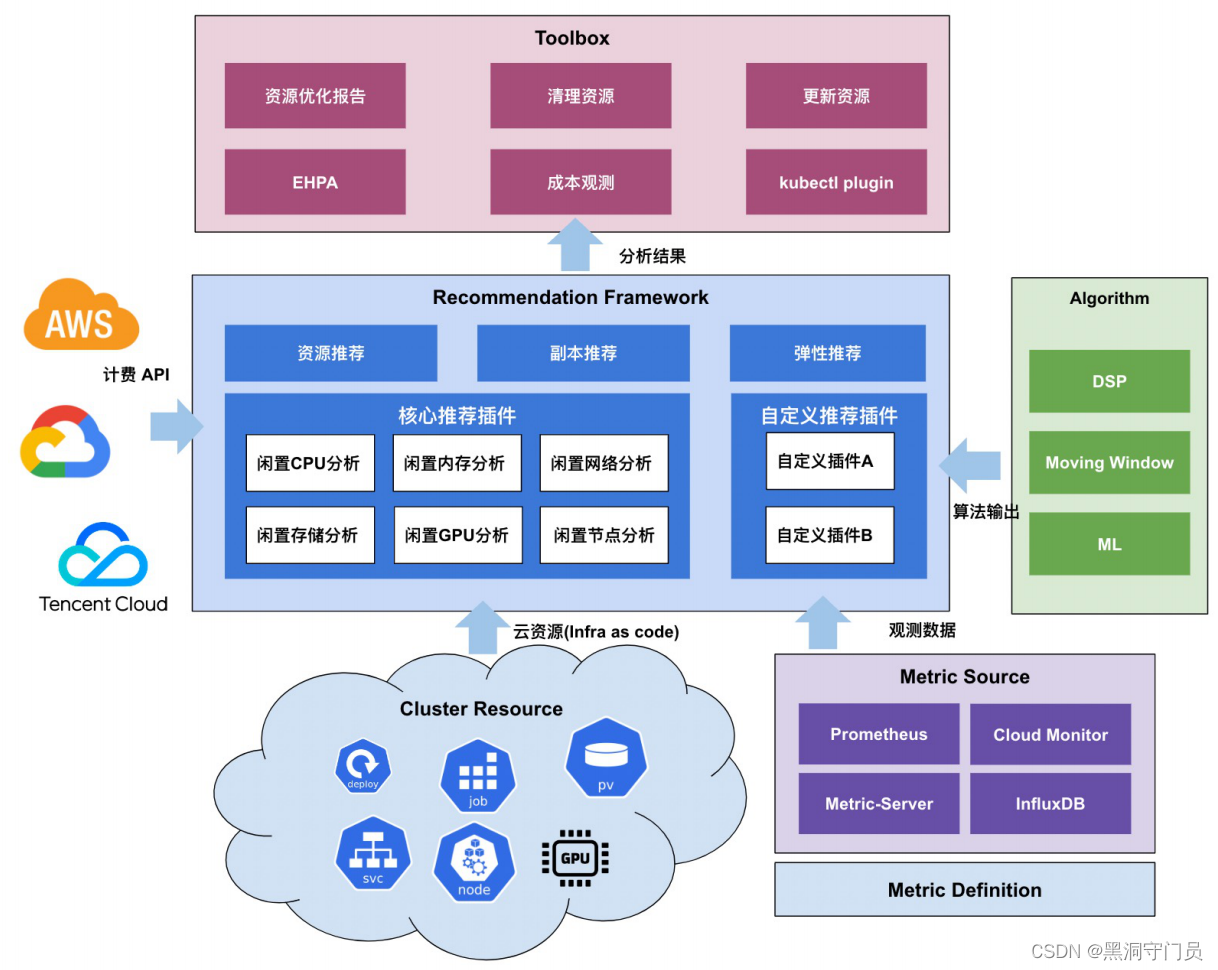
从上图可以看出,成本分析模块会执行四个步骤:
- 从监控系统拉取用量数据
- 从Kubernetes平台拉取作业配置信息
- 从云厂商计费API拉取资源单价
- 通过多种算法分析成本组成并给出优化建议
整个分析过程中的数据会首先通过可视化面板展示给用户
那么,Grane 是通过什么东西进行的成本分呢?点开推荐规则,可以看到系统内置了两条规则
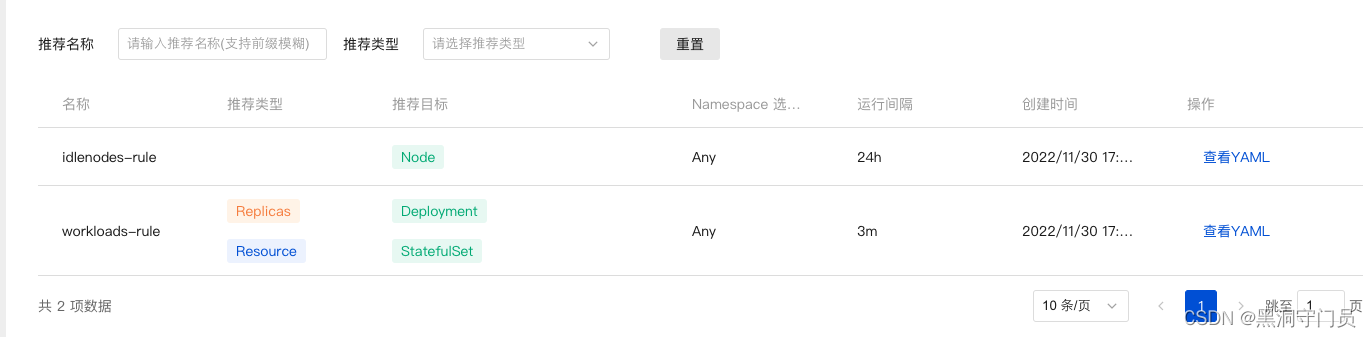
Grane正是依据这两个文件中的规则来进行成本分析的。
我们可以运行这个命令(新终端):kubectl get RecommendationRule,来查看这两个内置的文件。

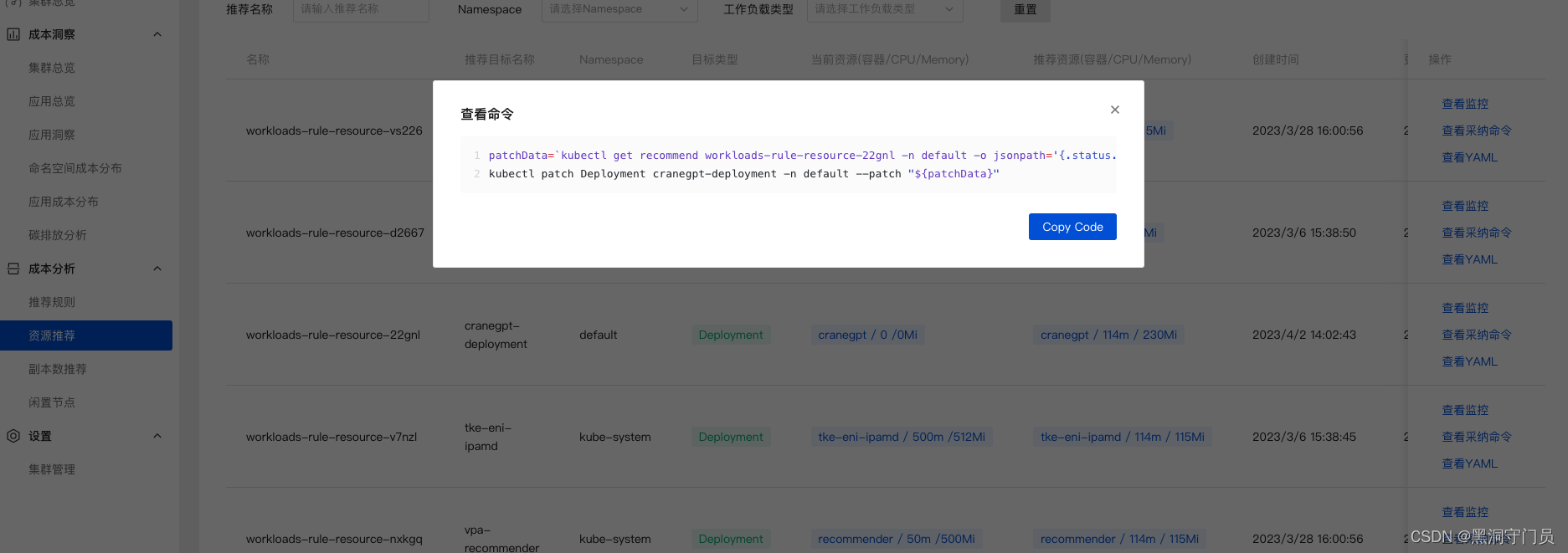
资源推荐与副本数
通过上面的成本分析,最后会生成一个资源推荐列表,并且资源推荐会提供多种 Recommender 来实现针对不同资源的优化建议。
这样做的一个显而易见的好处在于,我们在配置应用资源时常常是基于自己的经验或者网上的信息来设置 request 和 limit,但是这种设置是否真的适用于当前场景犹未可知。
通过成本分析的算法分析应用的真实用量,从而推断出更有效的资源配置,可以帮助我们大大提升集群的资源利用效率。
当然,对于副本数也是一样的。大部分用户在创建应用资源时通常基于过往经验来配置副本数。副本数推荐算法能够分析应用的真实用量,因此能推荐给用户更合适的副本配置,参考它可以大大提升集群的资源利用率。
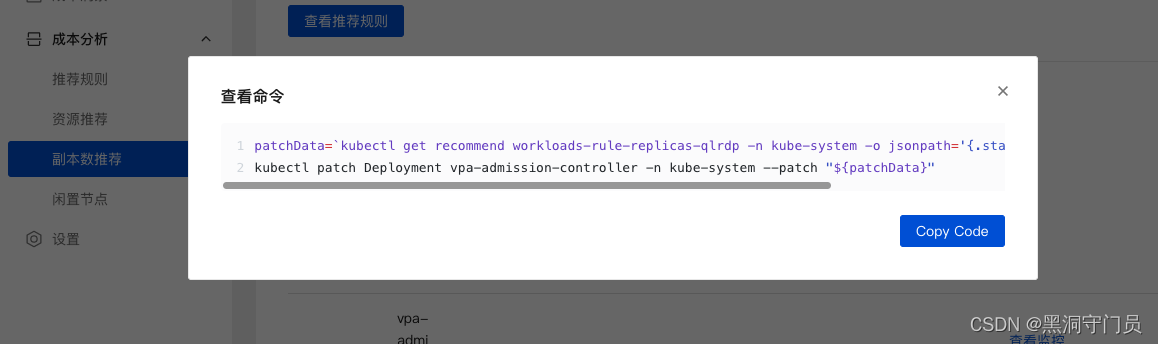
智能预测与自动扩缩容
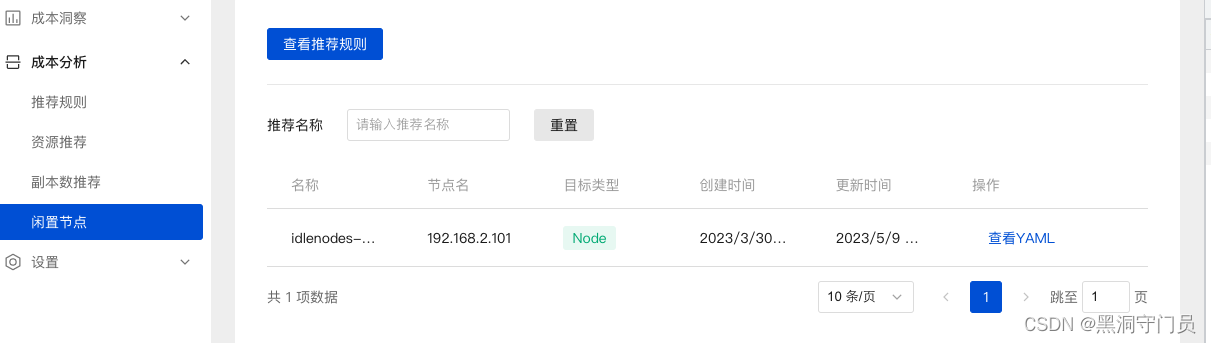
除了推荐的相关内容,成本分析还列出了一段时间内的闲置节点,从而让用户根据需要来自由的扩容或者缩容。
⚠️:应用在监控系统(比如 Prometheus)中的历史数据越久,推荐结果就越准确,建议生产上超过两周时间。对新建应用的预测往往不准。
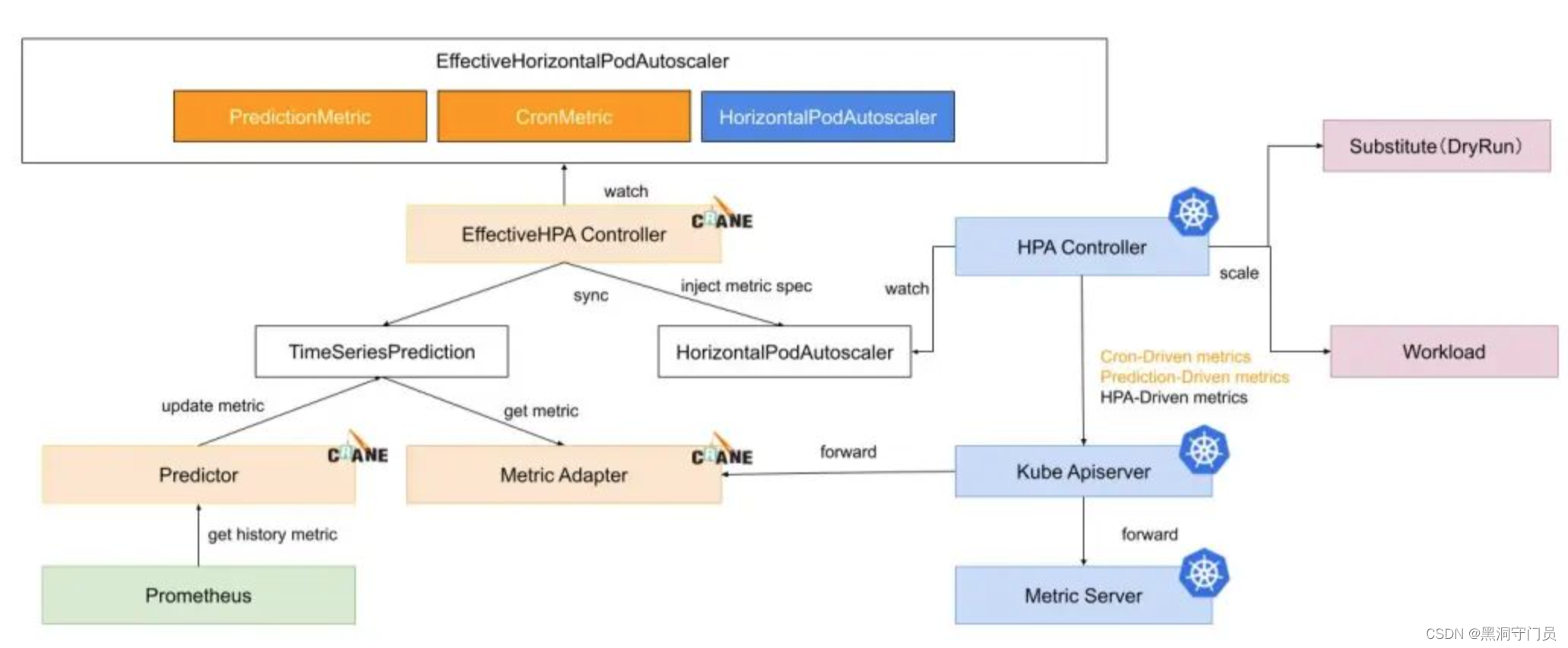
EHPA
当然了,除了手动的扩容与缩容,Grane 还能自动实现扩缩容。Grane 基于社区 HPA 做底层的弹性控制实现了一个名为 EffectiveHorizontalPodAutoscaler(简称 EHPA)的弹性伸缩产品,支持丰富的弹性触发策略(预测,观测,周期),例如:
- 提前扩容:算法预测未来的流量洪峰,如保证节假日的流量洪峰,避免服务器突增大量流量导致的拥堵甚至宕机。
- 减少无效缩容:预测未来可减少不必要的缩容,稳定工作负载的资源使用率,消除突刺误判。
- 支持 Cron 配置:支持 Cron-based 弹性配置,应对大促等异常流量洪峰。
- 兼容社区:使用社区 HPA 作为弹性控制的执行层,能力完全兼容社区。
EHPA 采用时间序列算法(FFT快速傅里叶变换算法),基于 Custom Metric,可靠性与准确性都比较高,而且完全兼容社区 HPA ,支持 Dryrun 观测,指标支持 Prometheus Metric,可以说是 Grane 的超级手指。
那么如何使用这个超级手指呢?
安装Metrics Server
首先安装 Metrics Server,依然是在新的那个终端上运行下面的命令:
kubectl apply -f installation/components.yaml
kubectl get pod -n kube-system
创建测试应用
接下来创建用于测试的应用:启动一个 Deployment 用 hpa-example 镜像运行一个容器, 然后将其暴露为一个 服务(Service)
kubectl apply -f https://raw.githubusercontent.com/gocrane/crane/main/examples/autoscaling/php-apache.yaml
kubectl apply -f https://raw.githubusercontent.com/gocrane/crane/main/examples/analytics/nginx-deployment.yaml
创建 EffectiveHPA
运行
kubectl apply -f https://raw.githubusercontent.com/gocrane/crane/main/examples/autoscaling/effective-hpa.yaml
# 查看 EffectiveHPA 的当前状态:
kubectl get ehpa
可以看到这样的数据即是成功

增加负载
# 在单独的终端中运行它
# 如果你是新创建请配置环境变量
export KUBECONFIG=${HOME}/.kube/config_crane
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
# 现在执行
# 准备好后按 Ctrl+C 结束观察
kubectl get hpa ehpa-php-apache --watch
随着请求增多,CPU利用率会不断提升,可以看到 EffectiveHPA 会自动扩容实例。
整体流程
其整体流程如下图所示:
调度优化
Kubernetes 原生调度器只能通过资源的 requests 值来调度 pod,这很容易导致负载不均的问题:
-
实际负载与资源请求相差不大,导致很大概率出现稳定性问题。
-
实际负载远小于资源请求,导致资源的巨大浪费。
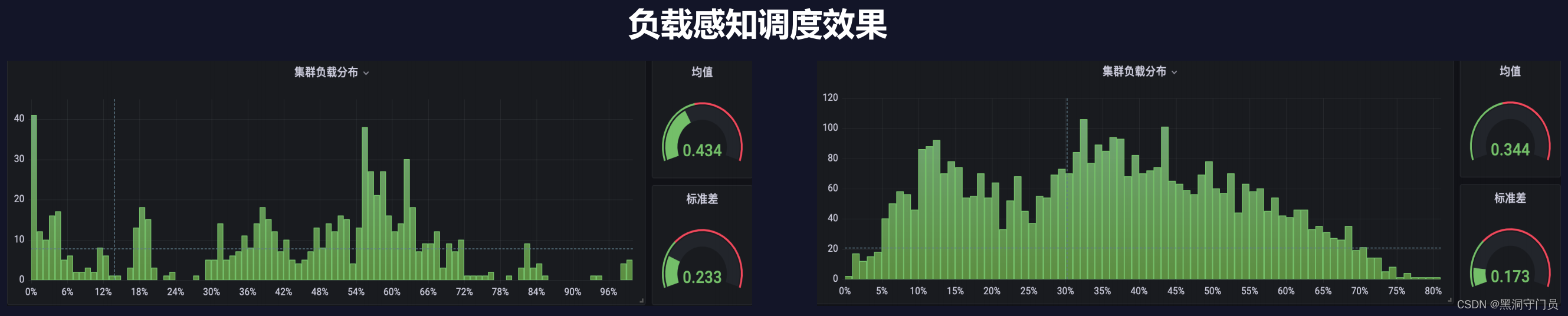
基于这个问题,Grane 也交出了一份比较给力的答卷。Crane-scheduler 是一个可以实现负载感知调度和拓扑感知调度的调度器插件。
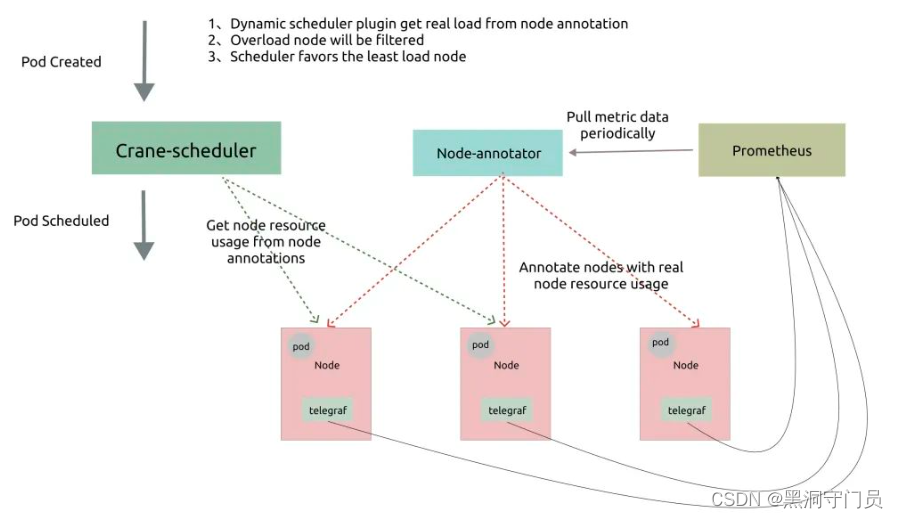
负载感知调度
- 基于真实负载的调度器
- 底层依赖 Prometheus 采集的真实负载,代替Request值
- 引入节点历史负载指标 (1h内最大利用率,1天内最大利用率),感知业务波峰
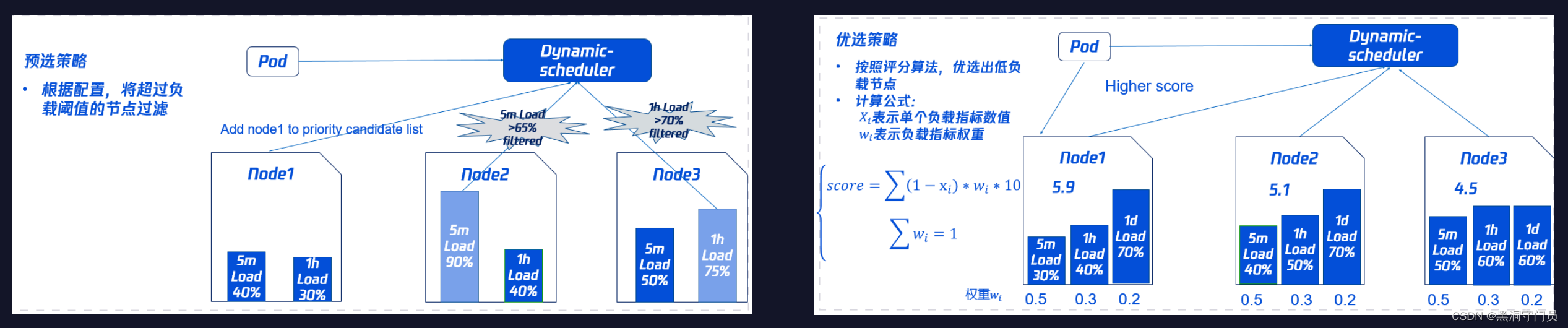
如图所示:根据预选策略(剔除高负载节点)和优选策略(优先低负载节点),动态地调度任务到不同的节点上,以达到负载均衡的目的,可以有效地提高系统的资源利用率和任务执行效率。
拓扑感知调度
- 优先选择Pod能绑定在单NUMA Node内的节点
- 优先选择在同一个NUMA Socket内的NUMA Node
- 优先选择空闲资源更多的NUMA Node
- 解决原生CPU Manager导致集群负载过低的问题
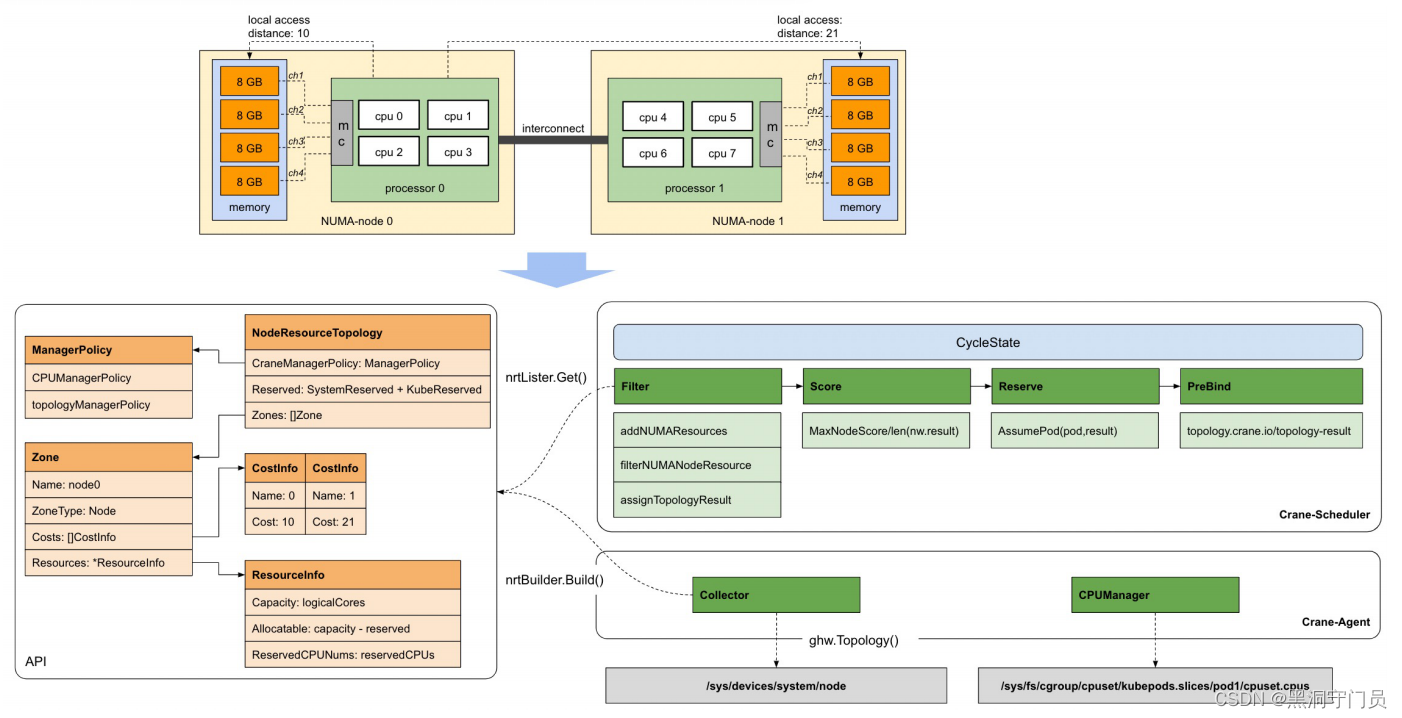
Grane 拓扑感知调度基于TEG星辰算力团队的技术支撑,通过感知网络的拓扑结构,将任务分配到网络拓扑结构相近的节点上,从而减小任务执行的时延和能耗,并提高任务执行的效率,保证系统的性能和可靠性。
混部
- 业界首创无侵入架构
- 声明式节点和业务QoS规则管理
- 多算法支持
- 依托腾讯TencentOS的全维度资源隔离
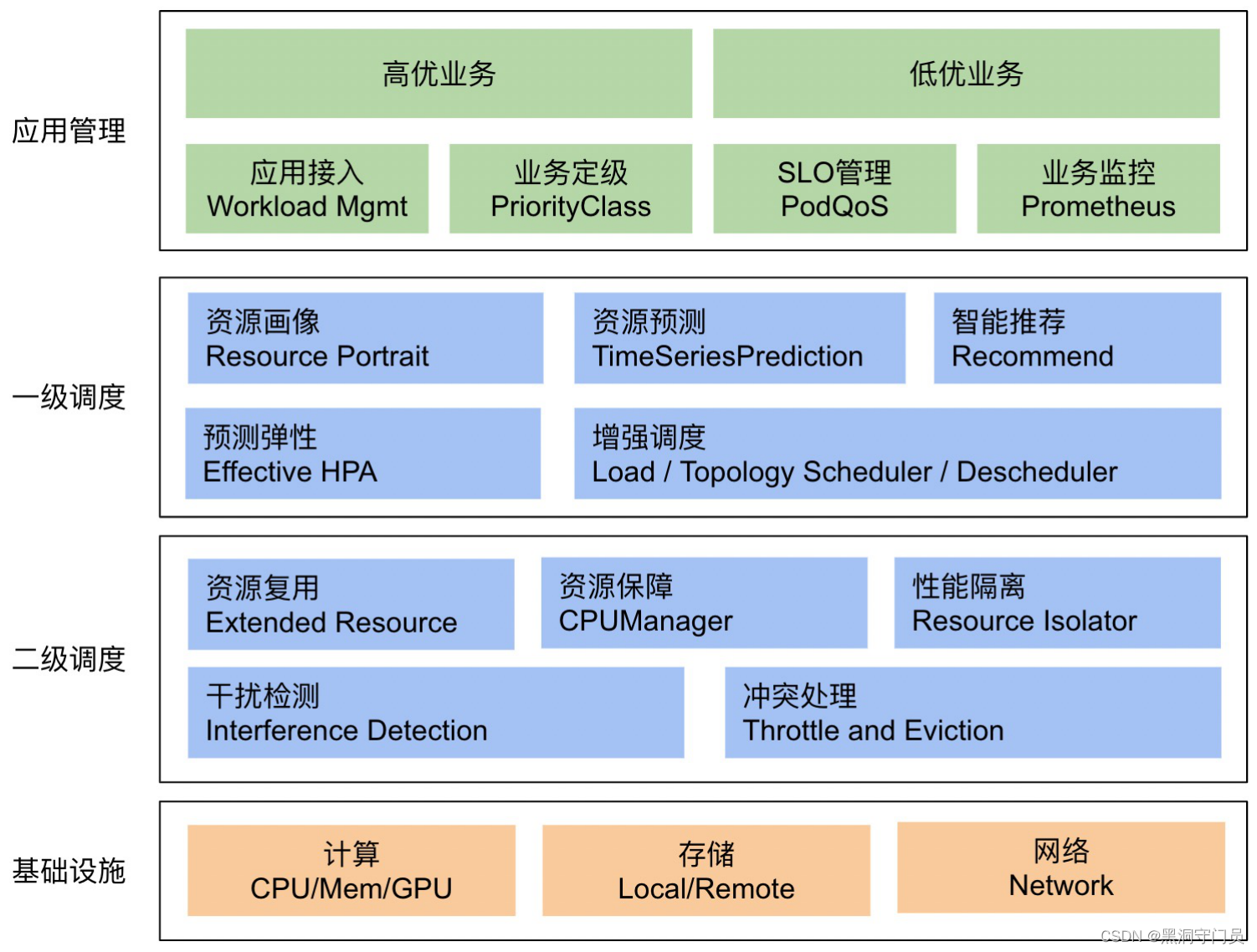
混部内核确保高优业务稳定性,可参考下面的图
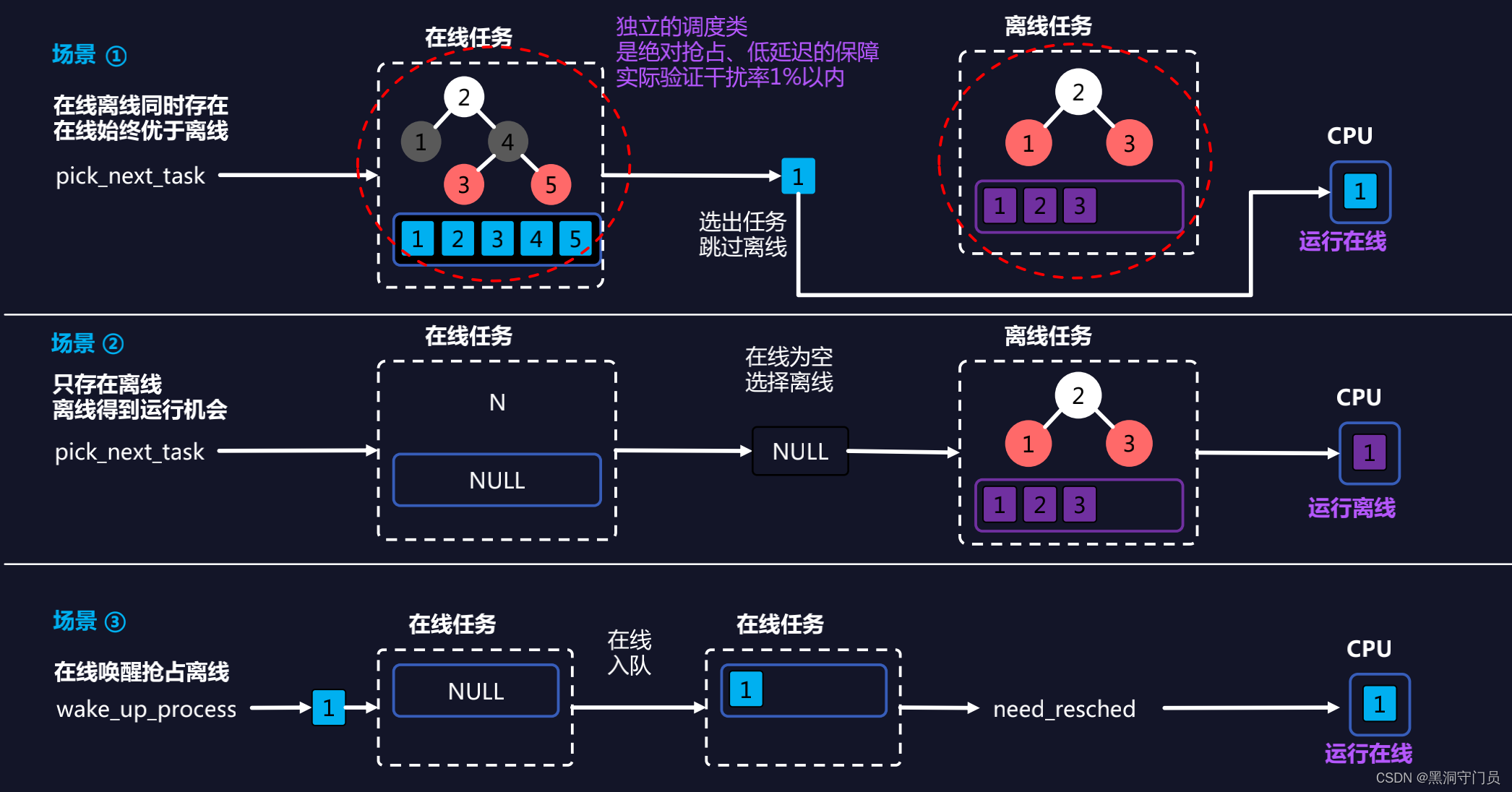
以上就是关于 Grane 的一些知识整理。
清理环境
实操完成以后,可以将本地的集群清理删除:
kind delete cluster --name=crane
关于 pr & issue
项目鼓励所有参与者积极提交 issue 和 pr。
毕竟众人拾柴火焰高,尤其开源项目,想要走的更远,除了项目的参与者持之以恒的燃烧热情和奉献自己,社区和其他个人的关注与参与也是必不可少的一部分。
所以我也在力所能及的范畴提交了两个 pr,从 pr 的整体流程上和与项目开发者的沟通上看,着实学到了很多东西。
小伙伴有兴趣也可以看看:pr776
提交的几个 issue 都是在使用的过程中发现的,有的顺手做了修复,无能为力的就只能单纯的提交等反馈。
Grane的开源地址在这里👉 传送(PS:离开前请记得评论收藏点赞哦)
总结
这次活动,总体来说让我受益匪浅。
抛开可能获得的物质奖励,参与活动的这些天,让人感觉很充实,仿佛一下子回到了大学的时候。曾经在五月的花海为社团活动四处奔走,与这种在工作之外的细碎时光里忙碌于自己的所想,何其相似呢。
作为一个技术菜鸟,我每天都忙碌于和需求与bug的相爱相杀之中,只不过日复一日,周复一周,日子总有种平平无奇的赶脚,陷落于几个项目代码的固定枷锁,久而忘记作为技术人的安身立命之本,是不断的学习和超越。
这次参与腾讯云联合 CSDN 的【腾讯云 Finops Crane 集训营】活动,正好是个提升的机会,让我对之前一直不怎么趁手的 Kubernetes 有了更多的信心。
尤其是来自于项目核心团队的老师,在直播间里从零开始的讲解,每一个步骤能够遇到的问题都有说明,每一个关键环节的操作都有演示,事无巨细,精益求精。
而且活动还提供了录播,方便我这种掉队的可以二刷三刷四刷,这哪是活动啊,这不是福利吗!(🐶)
当然由于本人是一枚菜鸟,还在持续不断的学习之中,所以内容就先到这里了,后续学习新的内容我也会随时更新,欢迎志同道合的朋友们点赞收藏。
PS:关于腾讯云 Finops Crane 集训营
Finops Crane集训营主要面向广大开发者,旨在提升开发者在容器部署、K8s层面的动手实践能力,同时吸纳Crane开源项目贡献者,鼓励开发者提交issue、bug反馈等,并搭载线上直播、动手实验组队、有奖征文等系列技术活动。既能让开发者通过活动对 Finops Crane 开源项目有深入了解,同时也能帮助广大开发者在云原生技能上有实质性收获。
为奖励开发者,我们特别设立了积分获取任务和对应的积分兑换礼品。
👉活动介绍送门:https://marketing.csdn.net/p/038ae30af2357473fc5431b63e4e1a78
👉开源项目: https://github.com/gocrane/crane










