OB 的 TABLEGROUP 是个利器,用不好的话会适得其反。
TableGroup 的设计目的
表分组(TableGroup) 是 OB 特有的一个功能,这个概念倒不是很新。以前在 ORACLE 运维里,DBA 会把频繁访问的大表放到一个独立的表空间(TABLESPACE)里,以将 ORACLE 的 IO 压力分散,提升 ORACLE 整体性能。表空间是运维的设计,业务通常不关注。当然 OB 跟 ORACLE 不同的是,IO 不会首先成为瓶颈。OB 的表分组跟表空间一样,主要是运维设计。不是必需操作,可做可不做,做了性能更好。熟悉 HBASE 的朋友,知道 HBASE 有个 Column Family 的功能,将不同的列聚合在一个文件里,不同 Column Family 的列在不同的文件里,提升高频访问的 SQL 的访问性能。OB 的表分组的设计跟这个用意一样。
OB 是完全自研的原生分布式数据库,其 SQL 和事务引擎都是原生,所以对业务是透明,用户感觉就像是一个单实例一样。除此之外,其他分布式细节都是 OB 内核里的功能,用户往往看不见。看过我前面文章《揭秘OceanBase的弹性伸缩和负载均衡原理》的朋友都了解,OB 以集群形式部署(至少三台机器),但是使用的是其中的租户。OB 每个租户(也叫逻辑实例)的位置对业务是不可见,在集群内部也不是固定的(当集群规模在 6 台以上的时候)。OB 的实例没有主备的说法,实例里的数据(分区)都有三副本,只有具体的分区的副本才有主备的概念(1 主 2 备)。同样,OB 分区的位置也不是固定的(当租户规模在 6 节点以上的时候)。OB 这特殊的流动性使得在集群发生节点故障或者集群扩容/缩容时,OB 内核能自动的去做数据均衡(数据迁移),完全不需要运维介入。并且在扩容或者缩容过程中,即使发生节点故障然后故障排除后,OB 也能自动恢复之前的扩容/缩容任务。
默认情况下,当OB 集群和租户都有一定规模(比如说 6 节点)。实例的多个表对应的分区副本可能是分散在多个节点(包括副本的主备角色也是分散的)。业务 SQL 如果用到表连接涉及到多个分区主副本的关联操作,可能就会跨节点。这个在分布式数据库里叫分布式连接。OB 支持这个连接算法,这类 SQL 的执行计划类型是分布式 SQL。此外即使没有表连接,由于 OBPROXY 特有的路由策略,在一个事务里如果先后访问多个表,并且这些表的主副本在不同节点上时,在 OB 内部也会有跨节点的请求。这类 SQL的执行计划类型是远程 SQL。那些只发生节点内部的 SQL 执行计划类型就是本地 SQL。从理论上来说本地 SQL 的性能要优于分布式 SQL 和远程 SQL。说到这里可能有少数人就会关注性能差多少。在说性能差多少之前其实更应该业务先问对数据库的性能需求是多少。只要 SQL 的相应延时在业务需求内部,SQL 的类型是不用关心的。而另外一个理论是当 SQL 的并发增加的时候,SQL 的平均延时也会逐步增加(有些 SQL 快,有些 SQL 慢,呈类似正态分布特征)。所以在高并发下,SQL 的延时很可能会超出业务需求。这时候优化 SQL 执行计划类型是一个很有用的方法。即将分布式 SQL 和远程 SQL 优化为本地 SQL。
分布式 SQL 和远程 SQL 的产生主要是被访问的分区的副本位置决定的。如果把要访问的相关分区副本都约束在同一个节点内部,那么一个业务事务请求访问的所有 SQL 都是本地 SQL 了。OB 的表分组就是实现这个目的的。定义一个表分组,然后把相关表加入到这个表分组中。那么相关表的分区及其相应的同类角色副本都在同一个节点内部(注意,同一个分区的三副本仍然在三个节点内部)。在数据迁移的过程中,同一个表分组内的分区(组成分区组)会尽可能同时迁移,并呈现最终在一起的状态(手牵手不分离)。这听起来很好的,实际使用情形还是很复杂的。表分组可能会被误用以及过度使用。比如说把所有表都放一个表分组里。也就是所有表的分区都约束在一个节点内部,那这个跟集中式数据库设计就没有多大区别,不能发挥到分布式多机能力。所以,表分组跟索引一样,只能为最重要的业务场景优化使用,滥用就适得其反。此外,OB 支持分区表,为分区表建表分组的时候,实际上约束在一个节点内部的单位是分区组(同一个表分组下分区表的同号分区组成分区组)。如果很多表都是分区表,放到一个表分组里有好处的话也是可以的。
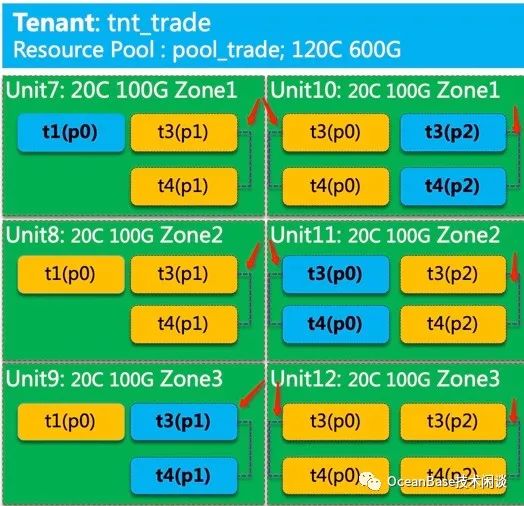
目前在 OLTP 场景内,表分组主要是为那些使用哈希分区的表使用的。针对 RANGE 分区、LIST 分区,我还没有看到使用场景。可能在 ROLAP 场景,针对 RANGE 分区或者 LIST 分区表建表分组可能会找到场景。由于 RANGE 分区会经常加减分区,我估计这个表分组也需要相应运维操作。就目前表分组能力而言,用在 RANGE 分区表上可能没有多大收益。
TableGroup 语法
TableGroup 有自己的创建语法,官网文档给的示例不够详细,所以有不少朋友不知道怎么创建。这里给一些示例。语法结构图就请查看官网文档。
- 创建简单的表分组
create tablegroup tgtest1;- 查看所有表分组
show tablegroups;- 查看具体表分组语法
show create tablegroup tgtest1\G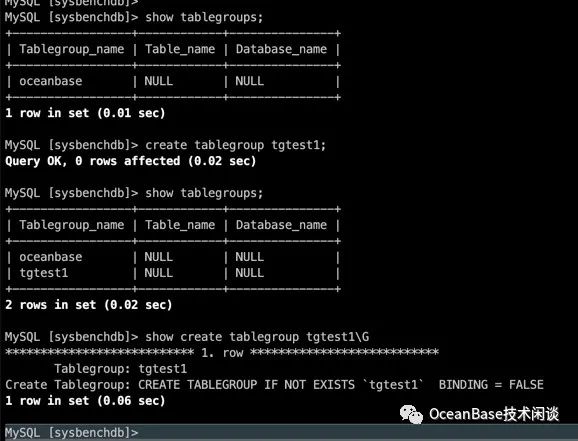
生成的表分组 DDL 语句中有个属性 BINDING=FALSE。这个是表分组的一个设计,默认值是由一个集群参数(enable_pg)控制的(租户下可以读取这个参数)。·这个参数的设计目的是在存储层针对分区组的事务做优化。这是一个试验特性,默认是不启用。生产环境当前版本还不推荐修改为 True。
此外,当前版本(227)开启这个特性后对表分组的修改操作有不少限制,所以后面示例都不开启这个特性。
show parameters like 'enable_pg';
- 向表分组里加入表
alter tablegroup tgtest1 add sbtest1, sbtest2;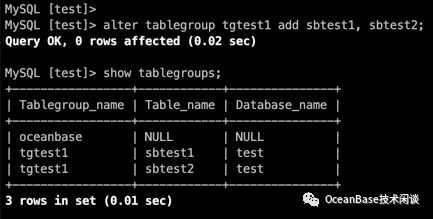
也可以直接修改表的表分组
alter table sbtest3 tablegroup='tgtest1';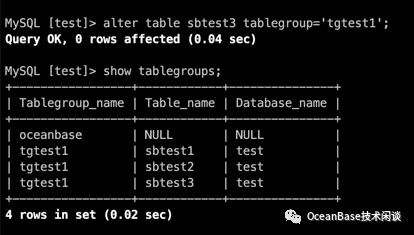
- 从表分组里删除表
alter tablegroup 没有 remove 或者 delete 方法,所以从表分组里移除表只能一个个修改表的表分组属性。
alter table sbtest1 tablegroup='';
alter table sbtest2 tablegroup='';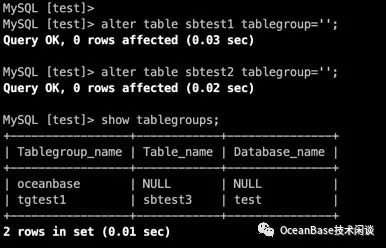
- 删除表分组
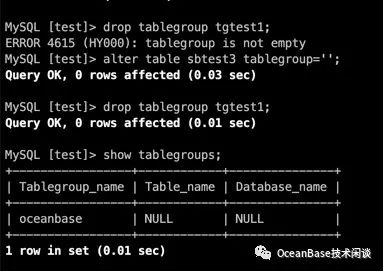
drop tablegroup tgtest1;如果表分组不为空,是不能删除表分组的。
- 表分组的
PRIMARY_ZONE 属性
表分组也有 PRIMARY_ZONE 属性。如果表分组的 PRIMARY_ZONE 跟表的 PRIMARY_ZONE 属性不一致,这个表是不能加入到表分组里。表的 PRIMARY_ZONE 默认继承自所在数据库(database,指 MySQL 租户下)。如果 database 没有默认 PRIMARY_ZONE 属性,就继承自所在租户的默认PRIMARY_ZONE设置。如果是 ORACLE 租户,表的PRIMARY_ZONE没有设置的时候就继承自租户的PRIMARY_ZONE属性。PRIMARY_ZONE 设置主副本的分布策略,可以在线修改,效果等同于主备切换。至于是修改表还是修改整个数据库(database)或者实例(租户),其区别只是在多大范围内发起主备切换。这也是 OB 的一个独特能力(OB集群内部 没有主备机器、主备实例的说法。不过 OB 有主备集群的概念)。
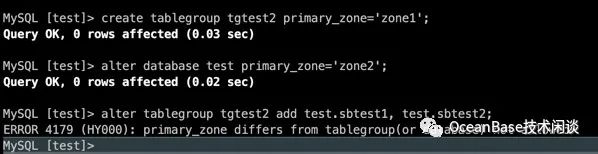
create tablegroup tgtest2 primary_zone='zone1';
alter database test primary_zone='zone2';
alter tablegroup tgtest2 add test.sbtest1, test.sbtest2;PRIMARY_ZONE不一致时会报错:ERROR 4179 (HY000): primary_zone differs from tablegroup(or database) not allowed。
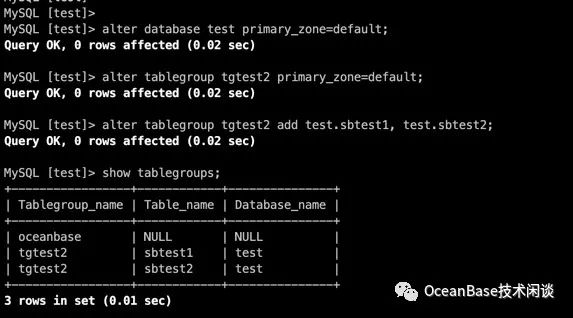
一旦租户和 database 的PRIMARY_ZONE设置没有设置正确,就需要改回去重新设计。清空PRIMARY_ZONE的方法就是设置为 DEFAULT。
- HASH 分区表的表分组
普通的表分组是不能加入分区表的,会报错:ERROR 4179 (HY000): table and tablegroup use different partition options not allowed
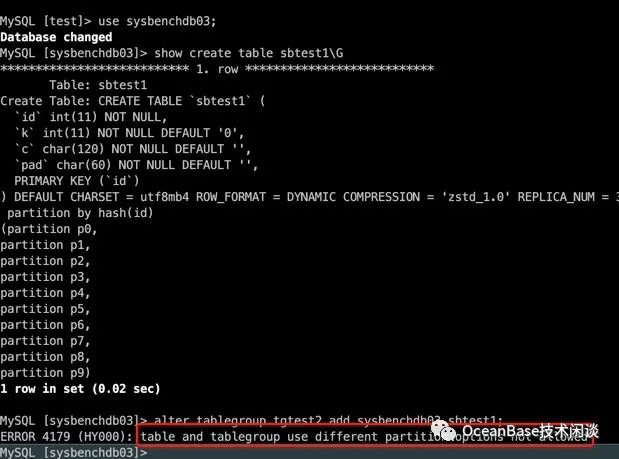
所以为分区表单独创建表分组。
create tablegroup tghash partition by hash partitions 10;
alter tablegroup tghash add sysbenchdb03.sbtest1 ;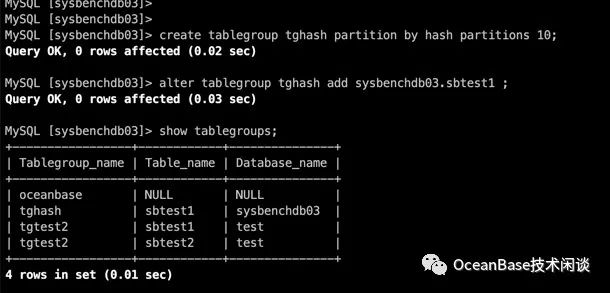
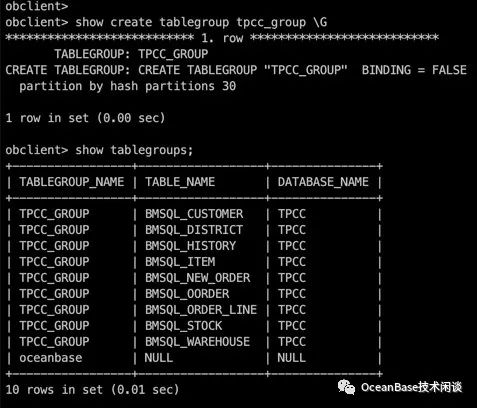
上面是 MySQL 租户的哈希分区表的表分组。ORACLE 租户下的哈希分区的表分组一样。(TPCC场景)。
- LIST 分区表的表分组
MySQL 跟 ORACLE 的 LIST 分区用法还不完全一样。
MySQL 租户示例:
create table test.t_list_1(id int not null primary key, c2 varchar(50)) partition by list columns(id) (
partition p0 values in (1,3,5,7,8,10,12),
partition p1 values in (4,6,9,11),
partition p2 values in (2)
);
create table test.t_list_2(id int not null primary key, c2 varchar(50)) partition by list columns(id) (
partition p0 values in (1,3,5,7,8,10,12),
partition p1 values in (4,6,9,11),
partition p2 values in (2)
);
create tablegroup tg_list binding false partition by list columns 1 (
partition p0 values in (1,3,5,7,8,10,12),
partition p1 values in (4,6,9,11),
partition p2 values in (2)
);
alter tablegroup tg_list add test.t_list_1, test.t_list_2 ;
show tablegroups;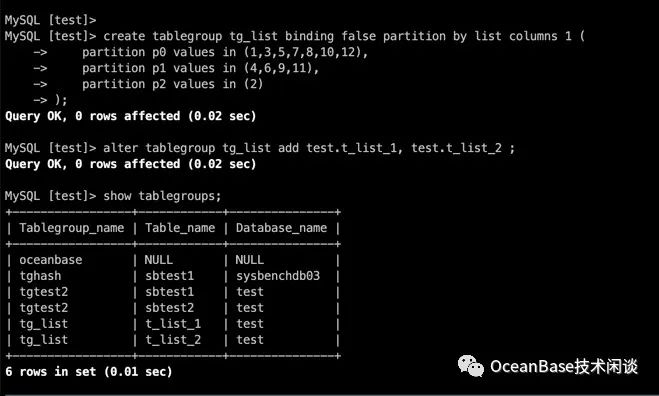
ORACLE 租户示例:
create table tpcc.t_list_3(id number not null primary key, c2 varchar2(50)) partition by list(id) (
partition p0 values (1,3,5,7,8,10,12),
partition p1 values (4,6,9,11),
partition p2 values (2)
);
create table tpcc.t_list_4(id number not null primary key, c2 varchar2(50)) partition by list(id) (
partition p0 values (1,3,5,7,8,10,12),
partition p1 values (4,6,9,11),
partition p2 values (2)
);
create tablegroup tg_list binding false partition by list columns 1 (
partition p0 values (1,3,5,7,8,10,12),
partition p1 values (4,6,9,11),
partition p2 values (2)
);
alter tablegroup tg_list add tpcc.t_list_3, tpcc.t_list_4 ;
show tablegroups;
- RANGE 分区表分区组
正如我说的,在 OLTP 场景下看不到 RANGE 分区表的分区组的使用价值。这里还是把 SQL 示例给一下。
//RANGE分区(mysql mode)
create tablegroup tgrange1 binding false
partition by range columns 1
(
partition p0 values less than (10),
partition p1 values less than(20)
);
create table t_range_test_1(id1 int, id2 int) tablegroup tgrange1
partition by range columns(id1)
(
partition p0 values less than (10),
partition p1 values less than(20)
);
create table t_range_test_2(id1 int, id2 int)
partition by range columns(id1)
(
partition p0 values less than (10),
partition p1 values less than(20)
);
alter table t_range_test_2 tablegroup='tgrange1';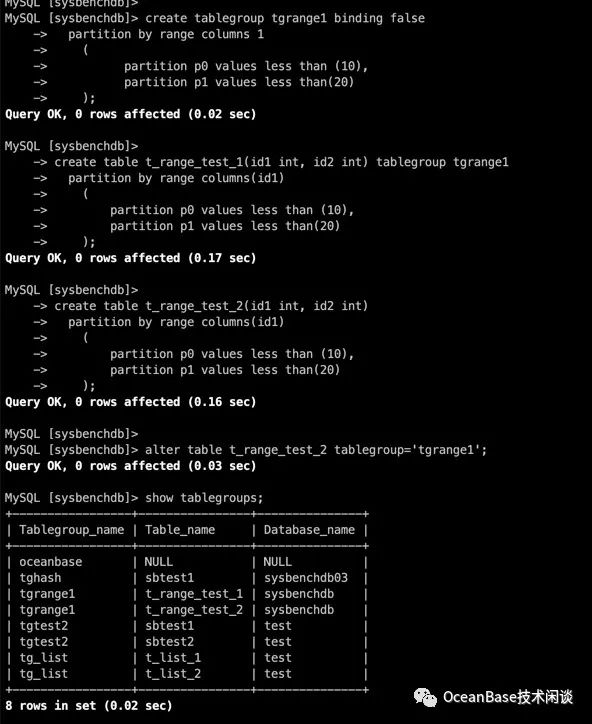
MySQL租户针对日期类型的 RANGE 分区表的表分组创建当前版本没法支持。主要是 MySQL 日期的 RANGE 分区表语法的分区定义中使用字符串代替日期类型。到表分组语法里,就没有办法区分这是字符串还是日期类型。最终就会报错。
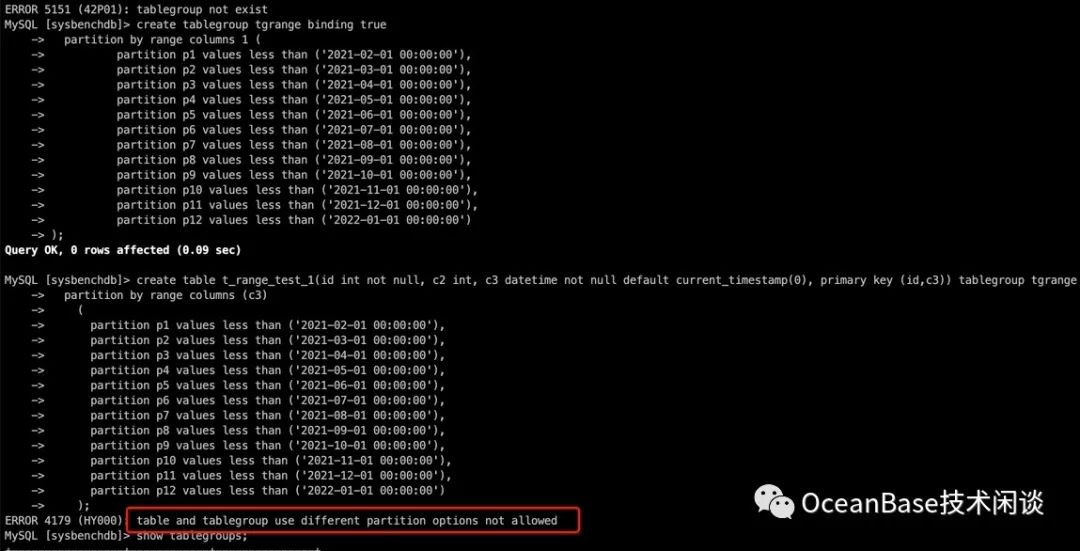
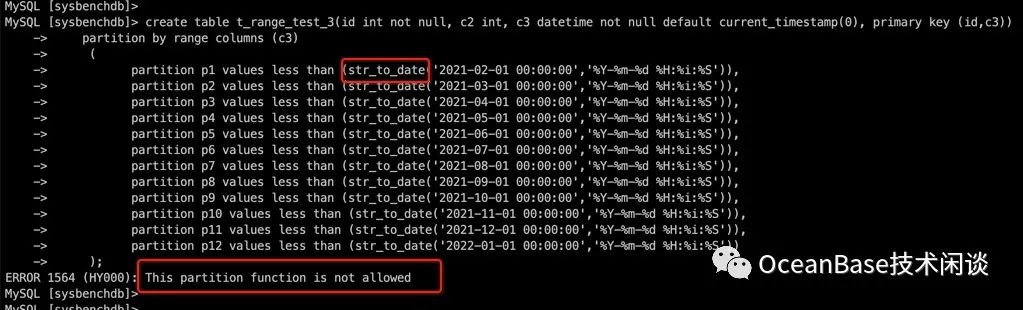
好在 ORACLE 租户的 RANGE 分区允许使用函数。
create tablegroup tgrange binding false
partition by range columns 1 (
partition p1 values less than (to_date('2021-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p2 values less than (to_date('2021-03-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p3 values less than (to_date('2021-04-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p4 values less than (to_date('2021-05-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p5 values less than (to_date('2021-06-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p6 values less than (to_date('2021-07-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p7 values less than (to_date('2021-08-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p8 values less than (to_date('2021-09-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p9 values less than (to_date('2021-10-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p10 values less than (to_date('2021-11-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p11 values less than (to_date('2021-12-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p12 values less than (to_date('2022-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss'))
);
create table tpcc.t_range_test_3(id number not null, c2 number, c3 date not null default sysdate, primary key (id,c3))
partition by range (c3)
(
partition p1 values less than (to_date('2021-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p2 values less than (to_date('2021-03-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p3 values less than (to_date('2021-04-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p4 values less than (to_date('2021-05-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p5 values less than (to_date('2021-06-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p6 values less than (to_date('2021-07-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p7 values less than (to_date('2021-08-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p8 values less than (to_date('2021-09-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p9 values less than (to_date('2021-10-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p10 values less than (to_date('2021-11-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p11 values less than (to_date('2021-12-01 00:00:00','yyyy-mm-dd hh24:mi:ss')),
partition p12 values less than (to_date('2022-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss'))
);
alter tablegroup tgrange add tpcc.t_range_test_3 ;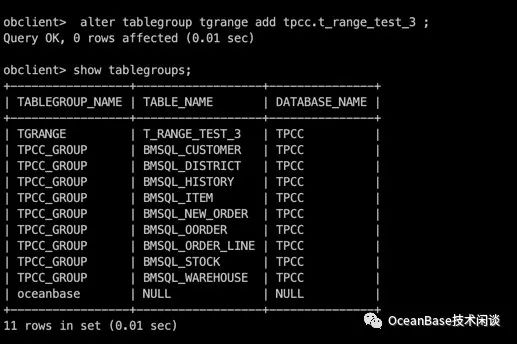
- 二级分区表的表分组用法
二级分区使用的场景并不多,一般只有历史表会用到,数据量非常大才会使用到二级分区(又叫组合分区)。通常是一级按日期 RANGE 分区和二级按用户 HASH 分区。就目前版本,使用二级分区的场景建议不要使用了表分组,会让情形变得非常复杂。等 OB 的 OLAP 场景案例多了后,再总结这块最佳实践。
TableGroup 相关元数据视图
下面一个 SQL 就可以理清楚租户、表、数据库、表分组、分区之间的关系了。
SELECT t.tenant_id, a.tenant_name, t.table_name, d.database_name, tg.tablegroup_name , t.part_num , t2.partition_id, t2.ZONE, t2.svr_ip
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE a.tenant_id IN (1001,1002 ) AND t.table_type IN (3)
AND tg.tablegroup_name IN ('tgrange1','tgtest2','tghash')
ORDER BY t.tenant_id, tg.tablegroup_name, d.database_name, t.table_name, t2.partition_id
;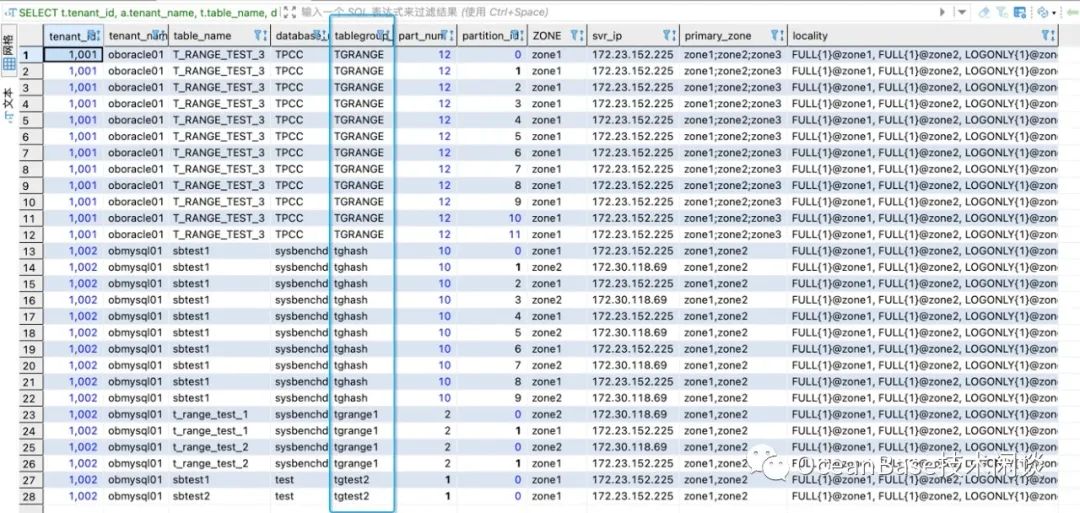
当 MySQL 租户和 ORACLE 租户的数据在一起展示的时候,就可以看出 MySQL 和 ORACLE 大小写风格的不一致。OB 兼容 ORACLE 和 MySQL,都保留了。如果没有接触过 MySQL 或 ORACLE 而直接接触 OB 的话,这一点会看起来会很奇怪。
非分区表跟分区表的远程 SQL 优化
上面的表分组要么针对非分区表,要么针对分区表。一个表分组没有办法同时包含非分区表和分区表。想想道理也很简单,分区表有多个分区,散落在多个节点,非分区表只有一个分区,它要跟分区表的哪个的分区绑定在一起呢?
不过 OB 针对这种场景提供了一个方案就是复制表方案。非分区表创建为复制表时,则可以在租户的每个资源单元中都有一个副本。也就是在一个 2-2-2 的租户里,复制表不一定是 3 副本,而可以是 6 副本(1 主 5 备,全同步策略,强一致)。这里就不展开了。
表分组和复制表的最佳实践案例就是 TPC-C 。
参考
揭秘OceanBase的弹性伸缩和负载均衡原理
OceanBase 2.x体验:用BenchmarkSQL跑TPC-C
OceanBase 使用讨论区
