最近在自学用python进行网页数据抓取,结果被中文乱码的问题折腾了好久。网上google了各种解决方案都无法解决我遇到的问题,索性自己深入的研究了下,终于把这难题给解决了。在此梳理下整个分析过程。
网站&开发工具
- 网站:http://www.jjwxc.net/fenzhan/noyq/
- python v2.7
- BeautifulSoup v4.0
遇到的问题
一开始我的代码是这样写的:
<pre><code>response = requests.get('http://www.jjwxc.net/fenzhan/noyq/')
soup = bs4.BeautifulSoup(response.text, "html.parser")
print soup.title
</code></pre>
执行后返回的结果中文部分都变成了乱码。很显然,是中文编码在转换过程中出现了问题。
分析
查看jjwxc.net的源码,可以得知该网站的中文编码是gb18030
<pre><code><meta http-equiv="Content-Type" content="text/html; charset=gb18030" /></code></pre>
查阅requestes以及BeautifulSoup的相关文档,可知requests会自动将从服务器端获取到的内容自动转换成unicode, 而beauifulsoup也会将获取到内容自动解码成unicode。既然response.text已经是unicode形式,那么再传递给beautifulsoup,是unicode->unicode之间的直接传递,应该不存在编码转换错误的情况,那么为什么最后print出来的会是乱码呢?
于是进一步查阅requests和bs4的官方文档,发现了这样两段描述:
大意是requests和beautifulsoup都会自行猜测原文的编码方式,然后用猜测出来的编码方式进行解码转换成unicode。大多数时候猜测出来的编码都是正确的,但也有猜错的情况,如果猜错了可以指定原文的编码。
OK,那让我们看一下requests和beautifulsoup是否猜对了原文编码。
<pre><code>response = requests.get('http://www.jjwxc.net/fenzhan/noyq/')
print response.encoding
soup = bs4.BeautifulSoup(response.text, "html.parser")
print soup.original_encoding
<br />运行结果:
ISO-8859-1
None</code></pre>
可以发现是由于requests这里对原文的编码猜错了导致乱码的出现,所以我们需要在response.text传给beautifulsoup之前指定编码:
<pre><code>response = requests.get('http://www.jjwxc.net/fenzhan/noyq/')
response.encoding = 'gb18030'
soup = bs4.BeautifulSoup(response.text, "html.parser")
print soup.title</code></pre>
但是运行后发现输出的结果还是乱码。
继续查阅上述语句的相关官方文档,发现beautifulsoup对于输出内容的编码方式有这样一段介绍:
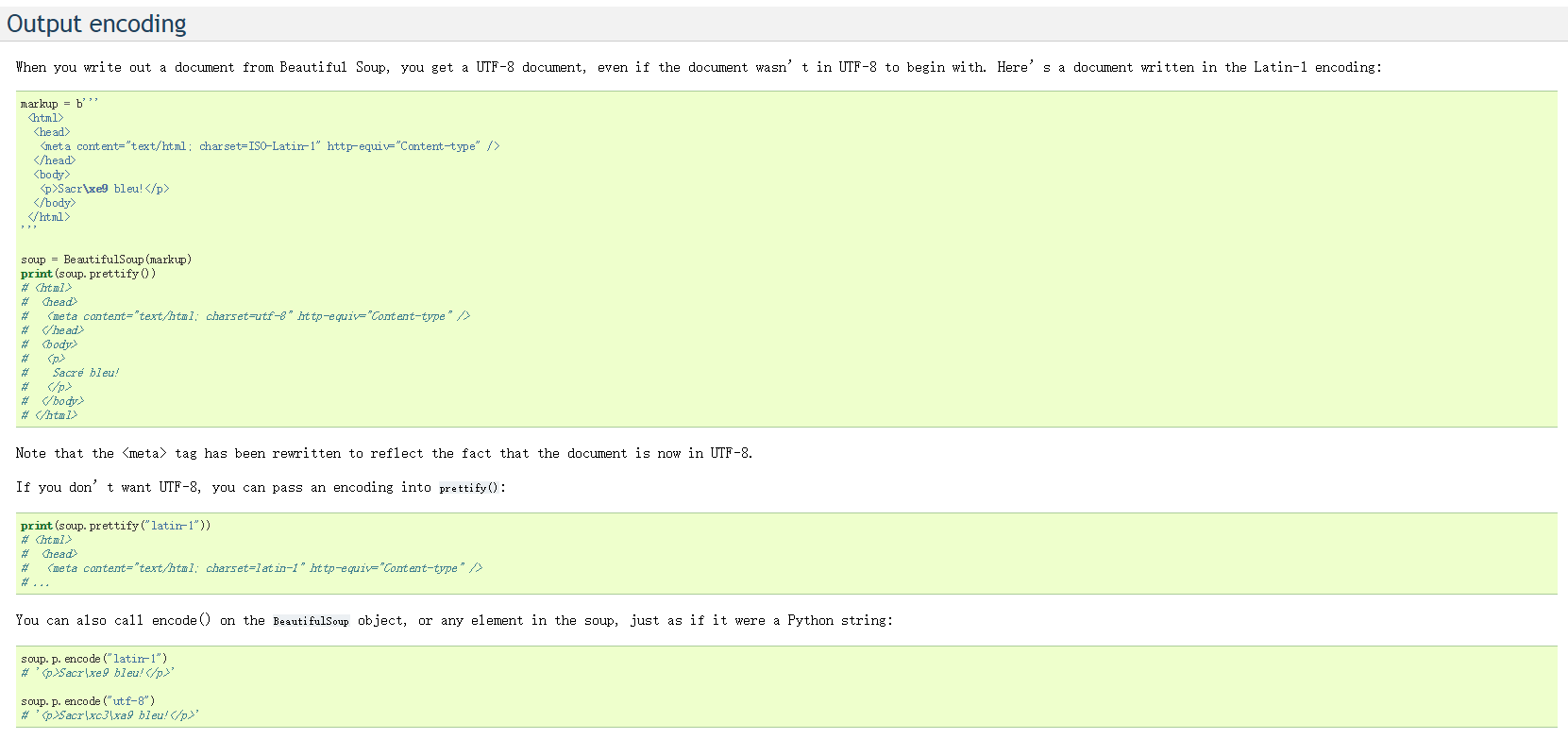
意即beautifulsoup在输出文本时默认以UTF-8的方式编码,无论原文是否以它进行编码的。如果你不希望以UTF-8的方式编码,可以用prettify()或则encode()方式来指定编码。
所以我们将代码更改下:
<pre><code>response = requests.get('http://www.jjwxc.net/fenzhan/noyq/')
response.encoding = 'gb18030'
soup = bs4.BeautifulSoup(response.text, "html.parser")
print soup.title.prettify('gb18030')
print soup.title.encode('gb18030')
<br />运行结果:
<title>
非言情小说网|同人小说|古代纯爱小说|现代纯爱小说|同人纯爱小说|动漫同人小说【晋江文学城】bl小说站
</title>
<title>非言情小说网|同人小说|古代纯爱小说|现代纯爱小说|同人纯爱小说|动漫同人小说【晋江文学城】bl小说站</title></code></pre>
可以看到两种指定方式都可以获得无乱码的中文内容。
这里再介绍下prettify()的功能,prettify()除了可以制定输出的编码方式,它的最主要功能是对beautifulsoup的k语法分析树重新排版,使输出的内容整洁易读。这里用一段代码说明:

至此,中文乱码的问题解决了。在查找解决方案的过程中,我另外查了下unicode、byte、以及编码和解码方面的知识点。这一块的东西解释起来一时半会儿说不完,而且有些细节的地方我也没完全搞懂,暂时就不卖弄了。对这块内容感兴趣的可以先看下下面这两位大牛的文章,写得非常通俗易懂:
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets
- 字符编码笔记:ASCII,Unicode和UTF-8










