本篇文章主要介绍下FLink的内存模型,在介绍Flink内存模型之前,我们首先学习下JVM内存结构
1. JVM内存结构
Java7 升级为 Java8的时候,JVM内存结构发生了改变,咱们看下区别是什么。这部分内容原文 Java8 JVM内存结构
1.1 Java7 对应的 JVM 内存结构

很多人愿意将方法区称作永久代。
本质上来讲两者并不等价,仅因为Hotspot将GC分代扩展至方法区,或者说使用永久代来实现方法区。在其他虚拟机上是没有永久代的概念的。也就是说方法区是规范,永久代是Hotspot针对该规范进行的实现。
1.2 Java8 对应的 JVM 内存结构

元空间MetaSpace存在于本地内存,意味着只要本地内存足够,它不会出现像Java7永久代中“java.lang.OutOfMemoryError: PermGen space”这种错误。
那为什么用MetaSpace代替了方法区呢?是因为通常使用PermSize和MaxPermSize设置永久代的大小就决定了永久代的上限,但是不知道应该设置多大合适, 如果使用默认值很容易遇到OOM错误。
当使用元空间时,可以加载多少类的元数据就不再由MaxPermSize控制, 而由系统的实际可用空间来控制。
1.3 JVM 堆内堆外内存什么含义?
这部分内容原文 堆内堆外内存
堆内内存
- 在JVM的这些分区中,占用内存空间最大的一部分叫做“堆(heap)”,也就是我们所说的堆内内存(on-heap memory)。JVM中的“堆”主要是存放所有对象的实例。这一块区域在java虚拟机启动的时候被创建,被所有的线程所共享,同时也是垃圾收集器的主要工作区域,因此这一部分区域除了被叫做“堆内内存”以外,也被叫做“GC堆”(Garbage Collected Heap)。
堆外内存
- 为了解决堆内内存过大带来的长时间GC停顿的问题,以及操作系统对堆内内存不可知的问题,java虚拟机开辟出了堆外内存(off-heap memory)。堆外内存意味着把一些对象的实例分配在Java虚拟机堆内内存以外的内存区域,这些内存直接受操作系统(而不是虚拟机)管理。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。同时因为这部分区域直接受操作系统的管理,别的进程和设备(例如GPU)可以直接通过操作系统对其进行访问,减少了从虚拟机中复制内存数据的过程。
- java 在NIO 包中提供了ByteBuffer类,对堆外内存进行访问。
- 虽然堆外内存本身不受垃圾回收算法的管辖,但是因为它是由ByteBuffer所创造出来的,因此这个buffer自身作为一个实例化的对象,其自身的信息(例如堆外内存在主存中的起始地址等信息)必须存储在堆内内存中。
2. Flink 内存模型
Flink1.10 对Flink的内存模型进行了改造,咱们分开来介绍Flink1.10之前版本,已经Flink1.10之后版本
2.1 Flink1.10前的Flink内存模型
首先看下内存模型图
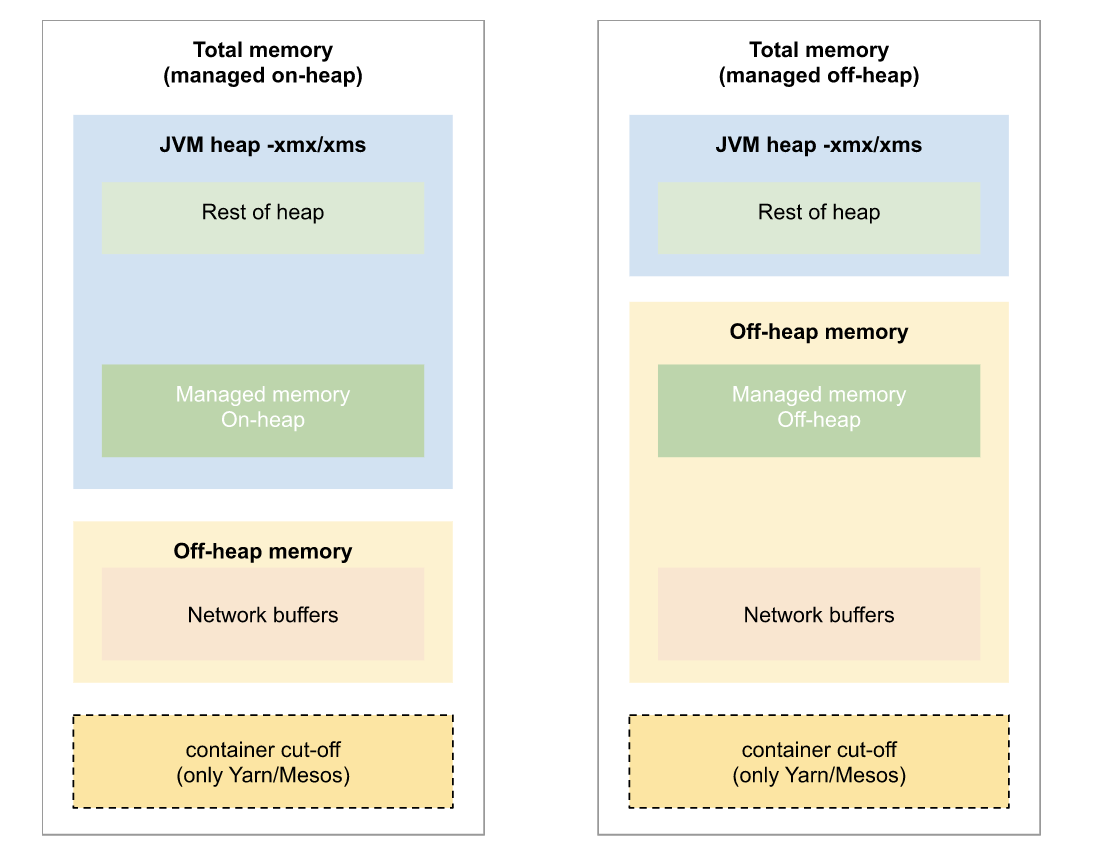
看下flink源码,来分析下内存各个分区大小是怎么设置的,入口 ContaineredTaskManagerParameters#create 方法
/**
* Computes the parameters to be used to start a TaskManager Java process.
*
* @param config The Flink configuration.
* @param containerMemoryMB The size of the complete container, in megabytes.
* @return The parameters to start the TaskManager processes with.
*/
public static ContaineredTaskManagerParameters create(
Configuration config,
long containerMemoryMB,
int numSlots) {
// (1) try to compute how much memory used by container
final long cutoffMB = calculateCutoffMB(config, containerMemoryMB);
// (2) split the remaining Java memory between heap and off-heap
final long heapSizeMB = TaskManagerServices.calculateHeapSizeMB(containerMemoryMB - cutoffMB, config);
// use the cut-off memory for off-heap (that was its intention)
final long offHeapSizeMB = containerMemoryMB - heapSizeMB;
// (3) obtain the additional environment variables from the configuration
final HashMap<String, String> envVars = new HashMap<>();
final String prefix = ResourceManagerOptions.CONTAINERIZED_TASK_MANAGER_ENV_PREFIX;
for (String key : config.keySet()) {
if (key.startsWith(prefix) && key.length() > prefix.length()) {
// remove prefix
String envVarKey = key.substring(prefix.length());
envVars.put(envVarKey, config.getString(key, null));
}
}
// done
return new ContaineredTaskManagerParameters(
containerMemoryMB, heapSizeMB, offHeapSizeMB, numSlots, envVars);
}
}
container cut-off 区域
- check cutoff ratio,memoryCutoffRatio 默认是0.25
- check min cutoff value, 默认最小cutoff区域是600MB
- cutoff区域大小:containerMemoryMB * memoryCutoffRatio
- 这部分区域是预留内存,RocksDB使用的native内存,或者 JVM overhead都是使用这部分区域。Network buffers 区域(也就是 Off-heap 区域)
- 用于网络传输(比如 shuffle、broadcast)的内存 Buffer 池,属于 Direct Memory 并由 Flink 管理。
- taskmanager.memory.segment-size 默认是 32kb
- taskmanager.network.memory.fraction 默认是 0.1
- Network buffers 区域大小:( containerMemoryMB - cutoffMB ) * taskmanager.network.memory.fraction,并且介于 64MB ~ 1GB之间Heap 区域
- Heap 区域大小: containerMemoryMB - cutoffMB - networkReservedMemory
- 可以使用JVM参数 -Xms 和 -Xmx 来设置上下限
2.2 Flink1.10及之后版本的Flink内存模型
首先看下内存模型图
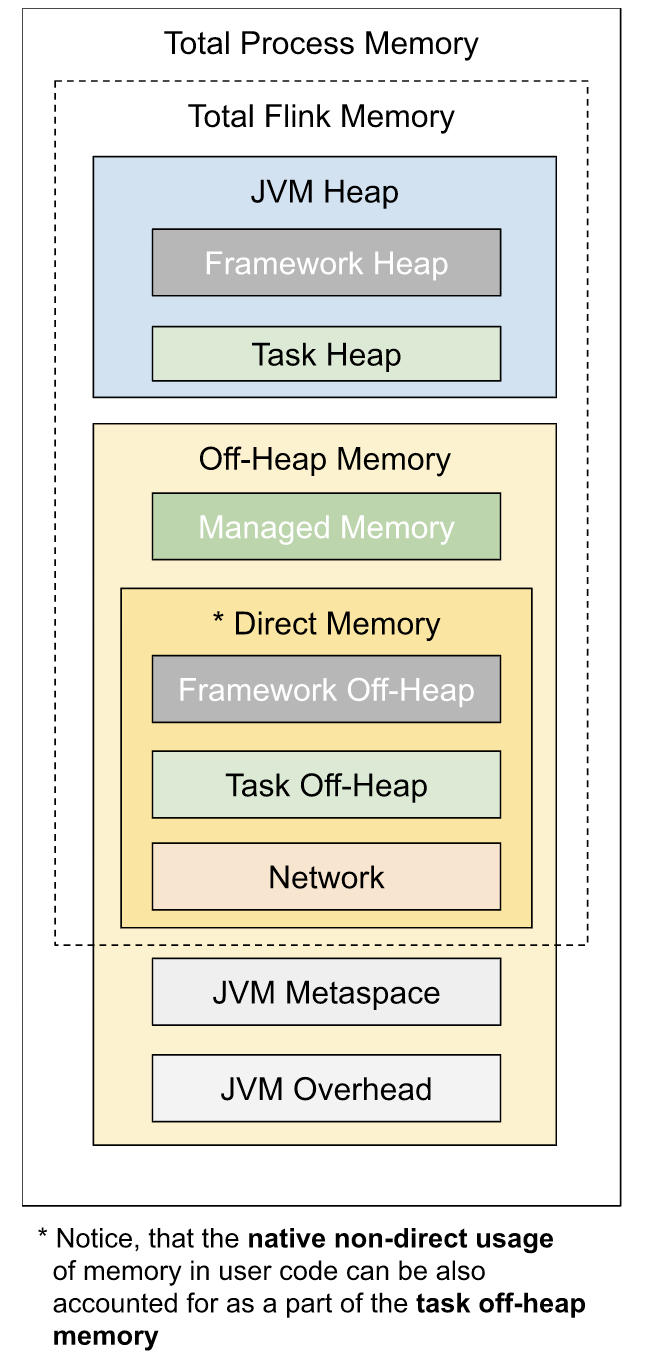
看下flink源码,来分析下内存各个分区大小是怎么设置的,入口 AbstractContainerizedClusterClientFactory#getClusterSpecification 方法,这个方法是在集群提交作业的时候被调度。
@Override
public ClusterSpecification getClusterSpecification(Configuration configuration) {
checkNotNull(configuration);
// JM 内存模型
final int jobManagerMemoryMB =
JobManagerProcessUtils.processSpecFromConfigWithNewOptionToInterpretLegacyHeap(
configuration, JobManagerOptions.TOTAL_PROCESS_MEMORY)
.getTotalProcessMemorySize()
.getMebiBytes();
// TM 内存模型
final int taskManagerMemoryMB =
TaskExecutorProcessUtils.processSpecFromConfig(
TaskExecutorProcessUtils
.getConfigurationMapLegacyTaskManagerHeapSizeToConfigOption(
configuration,
TaskManagerOptions.TOTAL_PROCESS_MEMORY))
.getTotalProcessMemorySize()
.getMebiBytes();
int slotsPerTaskManager = configuration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS);
return new ClusterSpecification.ClusterSpecificationBuilder()
.setMasterMemoryMB(jobManagerMemoryMB)
.setTaskManagerMemoryMB(taskManagerMemoryMB)
.setSlotsPerTaskManager(slotsPerTaskManager)
.createClusterSpecification();
}
咱们主要是分析TM的内存模型,也就是直接看下TaskExecutorProcessUtils.processSpecFromConfig方法,该方法主要做了下面几件事情
2.2.1. 首先初始化TM进程内存选项
对应TaskExecutorProcessUtils.TM_PROCESS_MEMORY_OPTIONS对象,根据configure文件读取,涉及到下面几个参数:
1.1 task 和 managed 内存相关
- taskmanager.memory.task.heap.size: task heap大小,没有默认值。
- taskmanager.memory.managed.size:flink框架manage 内存大小,没有默认值
1.2 Total Flink Memory 内存
- taskmanager.memory.flink.size: Total Flink Memory大小,没有默认值。
1.3 Total Process Memory 内存
- taskmanager.memory.process.size: Total Process Memory大小,没有默认值。
1.4 Jvm Metaspace和 Overhead 内存
- taskmanager.memory.jvm-metaspace.size: jvm-metaspace大小,主要存储类的元数据信息,默认值 256MB
- taskmanager.memory.jvm-overhead.min:jvm-overhead区域的最小值,默认值是 192 MB
- taskmanager.memory.jvm-overhead.max:jvm-overhead区域的最大值,默认值是 1GB
- taskmanager.memory.jvm-overhead.fraction:jvm-overhead占内存比例,默认值是0.1
static final ProcessMemoryOptions TM_PROCESS_MEMORY_OPTIONS =
new ProcessMemoryOptions(
Arrays.asList(
TaskManagerOptions.TASK_HEAP_MEMORY,
TaskManagerOptions.MANAGED_MEMORY_SIZE),
TaskManagerOptions.TOTAL_FLINK_MEMORY,
TaskManagerOptions.TOTAL_PROCESS_MEMORY,
new JvmMetaspaceAndOverheadOptions(
TaskManagerOptions.JVM_METASPACE,
TaskManagerOptions.JVM_OVERHEAD_MIN,
TaskManagerOptions.JVM_OVERHEAD_MAX,
TaskManagerOptions.JVM_OVERHEAD_FRACTION));
2.2.2. 接下来看下FLink内存模型,内存大小怎么计算的
如果指定了Total Process Memory大小,可以接下来看 ProcessMemoryUtils#deriveProcessSpecWithTotalProcessMemory方法
根据设置的Total Process Memory大小,来计算其他区域内存大小
(1) 内存第一部分: Jvm Metaspace大小
- 如果在conf文件中设置了taskmanager.memory.jvm-metaspace.size,就按照设置的来,否则走默认值 256MB
(2) 内存第二部分: Jvm Overhead 大小
- 根据 taskmanager.memory.jvm-overhead.fraction比例来计算,OverheadMemorySize = totalProcessMemorySize * taskmanager.memory.jvm-overhead.fraction
如果,OverheadMemorySize正好介于taskmanager.memory.jvm-overhead.min(192MB)和 taskmanager.memory.jvm-overhead.max(1GB)之间,那取值就是OverheadMemorySize
否则,if OverheadMemorySize > taskmanager.memory.jvm-overhead.max ,那取值就是taskmanager.memory.jvm-overhead.max。
if OverheadMemorySize < taskmanager.memory.jvm-overhead.min ,那取值就是taskmanager.memory.jvm-overhead.min
(3) 内存第三部分: Total Flink Memory 大小
- totalFlinkMemorySize = totalProcessMemorySize - jvmMetaspaceSize - jvmOverheadSize
2.2.3. Total Flink Memory 内,各个分区大小计算
Total Flink Memory中又涉及到好几块区域,分别来看下计算规则,都是基于totalFlinkMemorySize来计算的。对应TaskExecutorFlinkMemoryUtils#deriveFromTotalFlinkMemory方法,该方法主要做了下面几件事情:
- 获取frameworkHeap大小,可以通过taskmanager.memory.framework.heap.size参数修改,默认值是128MB
- 获取frameworkOffHeap大小,可以通过taskmanager.memory.framework.off-heap.size参数修改,默认值是128MB
- 获取taskOffHeap大小,可以通过taskmanager.memory.task.off-heap.size参数修改,默认值是0
- managedMemorySize 大小
- 如果指定了taskmanager.memory.managed.size,按照设置的来
- 否则按照taskmanager.memory.managed.fraction,默认值是0.4,那取值就是totalFlinkMemorySize * taskmanager.memory.managed.fraction
- Managed Memory托管内存由Flink管理,以native内存的方式进行分配,使用的是off-heap堆外内存。以下场景会用到Managed Memory
- Streaming Job 的 RocksDB 使用这部分内存
- Batch Job 使用 Managed Memory 进行 sort/hash table
- Streaming Job 或者 Batch Job 执行Python的自定义UDF使用该内存
- networkMemorySize 大小
- 如果设置了taskmanager.memory.network.min(64MB),taskmanager.memory.network.max(1GB),taskmanager.memory.network.fraction(0.1)其中的任意一个,那么networkMemorySize = taskmanager.network.numberOfBuffers(2048) * taskmanager.memory.segment-size(32KB)
- 否则 networkMemorySize = totalFlinkMemorySize * taskmanager.memory.network.fraction(0.1),不过networkMemorySize要介于taskmanager.memory.network.min(64MB)与 taskmanager.memory.network.max(1GB)之间
- taskHeapMemorySize 大小
- taskHeapMemorySize = totalFlinkMemorySize - frameworkHeapMemorySize - frameworkOffHeapMemorySize - taskOffHeapMemorySize - managedMemorySize - networkMemorySize
至此,Flink内存模型已经介绍完成。
3. 指定TM内存模型的方式
整个TM内存模型可以通过三种方式来指定
- 通过指定 taskmanager.memory.task.heap.size 和 taskmanager.memory.managed.size来确定
- 通过指定 taskmanager.memory.flink.size 也就是 Total Flink Memory大小
- 通过指定 * taskmanager.memory.process.size* 也就是 Total Process Memory大小
对应源码ProcessMemoryUtils#memoryProcessSpecFromConfig方法
public CommonProcessMemorySpec<FM> memoryProcessSpecFromConfig(Configuration config) {
if (options.getRequiredFineGrainedOptions().stream().allMatch(config::contains)) {
// all internal memory options are configured, use these to derive total Flink and
// process memory
return deriveProcessSpecWithExplicitInternalMemory(config);
} else if (config.contains(options.getTotalFlinkMemoryOption())) {
// internal memory options are not configured, total Flink memory is configured,
// derive from total flink memory
return deriveProcessSpecWithTotalFlinkMemory(config);
} else if (config.contains(options.getTotalProcessMemoryOption())) {
// total Flink memory is not configured, total process memory is configured,
// derive from total process memory
return deriveProcessSpecWithTotalProcessMemory(config);
}
return failBecauseRequiredOptionsNotConfigured();
}
4. 总结
本文介绍了Flink1.9 和 Flink1.12的内存模型以及各个区域的计算方法。
简单总结下Flink1.10之后的内存模型:
本质上 Java 应用使用的内存(不包括 JVM 自身的开销)可以分为三类:
- JVM 堆内存:Heap
- 不在 JVM 堆上但受到 JVM 管理的内存:Direct
- 完全不受 JVM 管理的内存:NativeDirect 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM 内存或者非 JVM 内存都是讲得通的。
Flink UI中 metric 加在一起为什么不是 TM 的总内存?
一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面?
这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 Native 内存,也就是 1.10 中的 Manage Memory。flink 1.10里将RocksDBStateBackend改为使用managed memory,统一使用 offheap 内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM 管理的内存:Native”这个?
是的不是太清楚offheap和direct以及native的关系是怎样的?
Flink 配置项中的 task/framework offheap,是包括了 direct 和 native 内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。Overhead 主要涉及到哪部分信息存储?
使用的native内存,主要存储线程栈,code cache, garbage collection space等。为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 taskmanager.memory.process.size 的值?
这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM 的参数,也并不是所有的Overhead 都有参数可以控制(比如栈空间)。










