3 SQL优化

3.1 插入数据
- 批量插入
insert into tb_user values (1,'Tom'),(2,'Cat'),(3,'Jerry');- 手动事务提交
start transaction;
insert into tb_user values (1,'Tom');
insert into tb_user values (2,'Cat');
insert into tb_user values (3,'Jerry');
commit;- 主键顺序插入(取决于mysql的数据组织结构)
- 主键乱序插入:8 1 9 5 7 2 3 4 6
- 主键顺序插入:1 2 3 4 5 6 7 8 9
- 大批量插入数据load
- 客户端连接服务端的时候,加上参数--local-infile
[root@hadoop ~]# mysql --local-infile -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 13
Server version: 8.0.26 MySQL Community Server - GPL- 查询下全局参数, 0就是没开启
mysql> select @@local_infile;
+----------------+
| @@local_infile |
+----------------+
| 0 |
+----------------+
1 row in set (0.00 sec)- 设置全局参数local_infile 为1,开启从本地加载文件导入数据的开关
mysql> set global local_infile = 1;
Query OK, 0 rows affected (0.00 sec)- 查询下有多少行
[root@hadoop ~]# wc -l load_user_100w_sort.sql
1000000 load_user_100w_sort.sql- 执行load指令将准备好的数据,加载到表结构中(类比hive,有点像 )
- fields terminaled by 每个字段之间以什么分隔
- lines terminaled by 每行之间以什么分隔
mysql> load data local infile '/root/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n';
Query OK, 1000000 rows affected (14.32 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 0mysql> select count(*) from tb_user;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.14 sec)3.2 主键优化
- 相关概念
- 数据组织方式:在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式成为索引组织表。
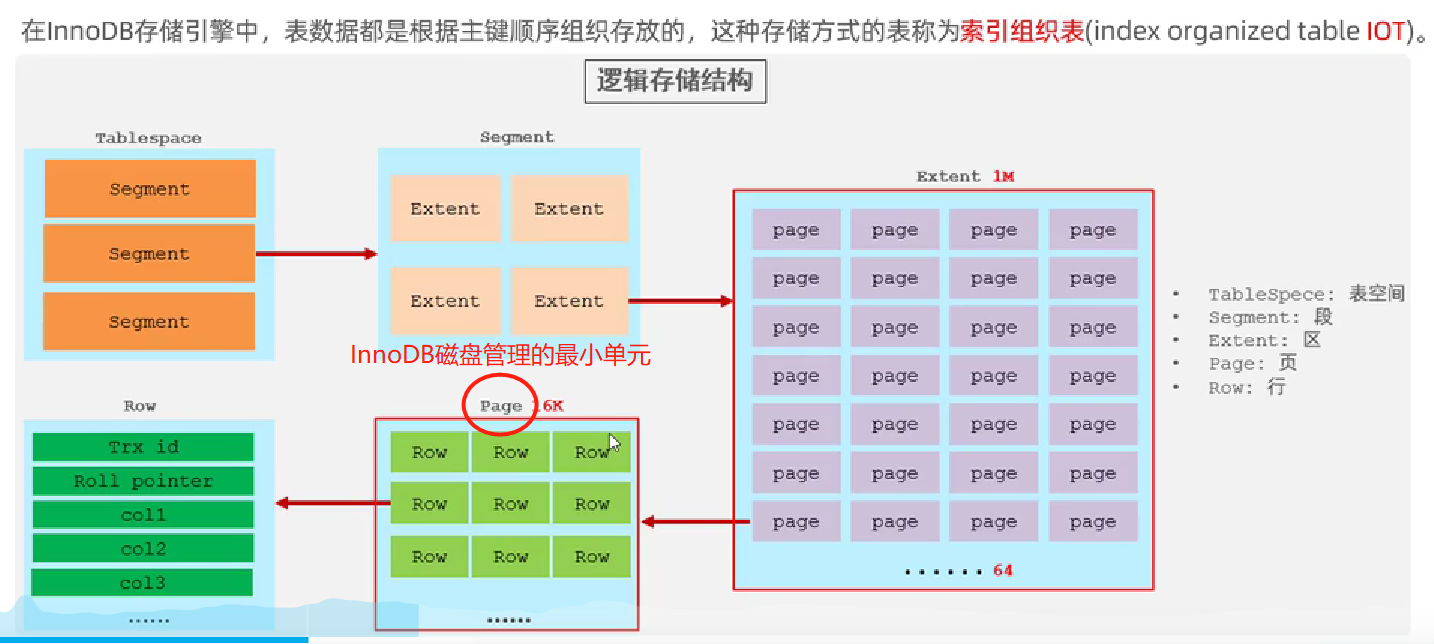
- 页分裂:页可以为空,也可以填充一半,也可以填充100%。每个页包含了2到N行数据(如果某一行数据过大,会行溢出)
- 页合并:当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记的删除并且它的空间变得允许被其他记录声明使用。
- 主键插入方式
- 主键顺序插入

- 主键乱序插入
- 叶子节点记得是有序的,所以在进行乱序插入的时候,如果应该插入的那个页放不下(图一),会把几行数据重新开辟页(图二),因此链表指针需要进行重新的设置(图三),这个过程就叫做页分裂

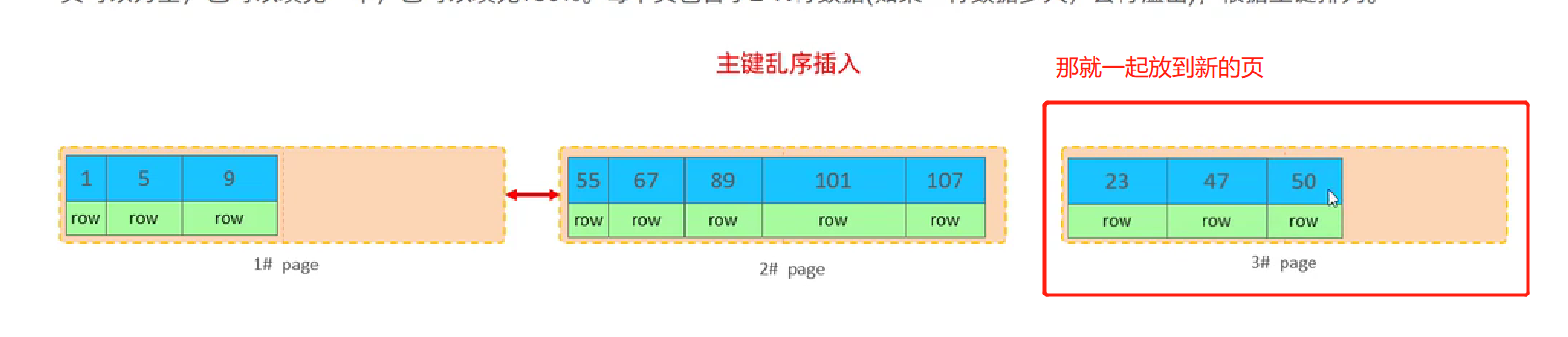

- 主键删除方式
- 主键顺序删除
- 当页中的删除记录达到merge_threshold(默认页的50%),InnoDB会开始寻找最靠近的页(前或者后)看看时候可以将两个合并并优化空间使用,这个过程就叫做页合并
- merge_threshold这个是合并页的阈值,可以自己设置的,在创建表或者创建索引的时候


- 主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度。(主键比较多,二级索引下面全部挂的主键,会浪费磁盘空间,并且搜素的时候会浪费磁盘io)
- 插入数据时候,尽量选择顺序插入,选择使用auto_increment自增主键
- 尽量不要用UUID(通用唯一标示符)做主键或者其他自然主键,如身份证号码那种
- 业务操作时候,避免对主键的修改
3.3 order by 优化
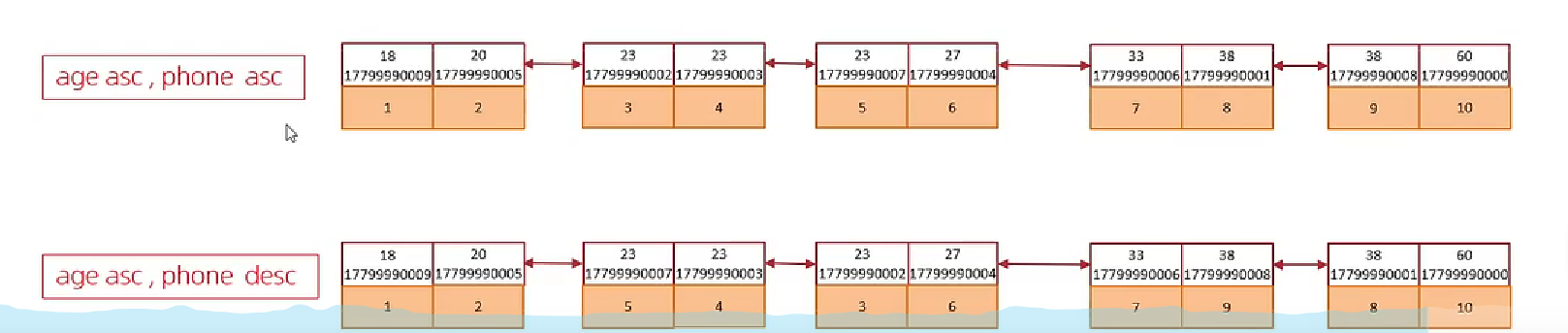
- 概念/分类
-
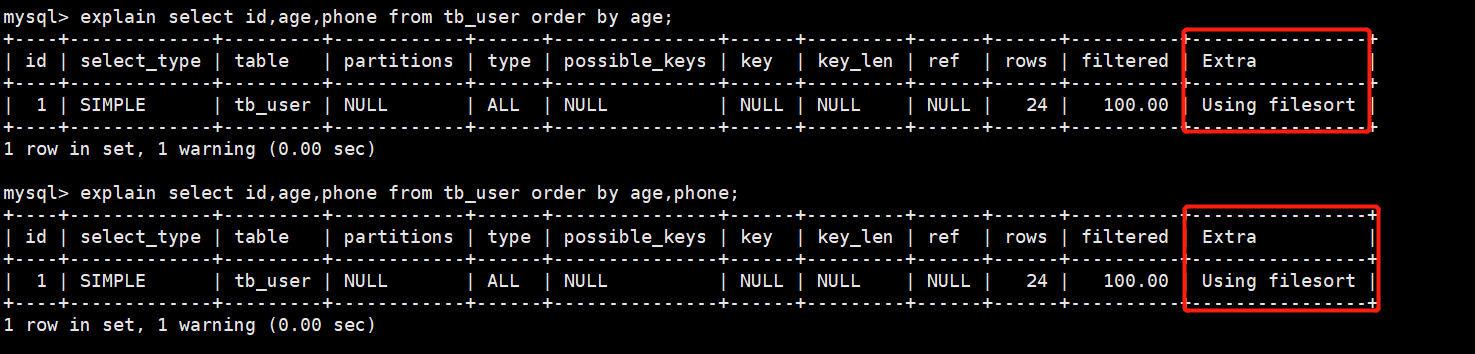
Using filesort:通过表的索引或者全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,即所有不是通过索引直接返回的结果的排序都叫做Filesort
- Using index:通过有序索引顺序扫描返回有序数据,这种情况叫做Using index
- 案例
- Using filesort(没建索引)
- Using index(建了索引),并且查询字段是满足覆盖索引的字段,最后是一个反向扫描索引

- 但是如果查询字段没有将索引的最左字段放在前面,违背了最左前缀法则

- 前升序后降序,后反序的就需要产生额外的排序

- 解决办法,创建前前升序后降序的索引
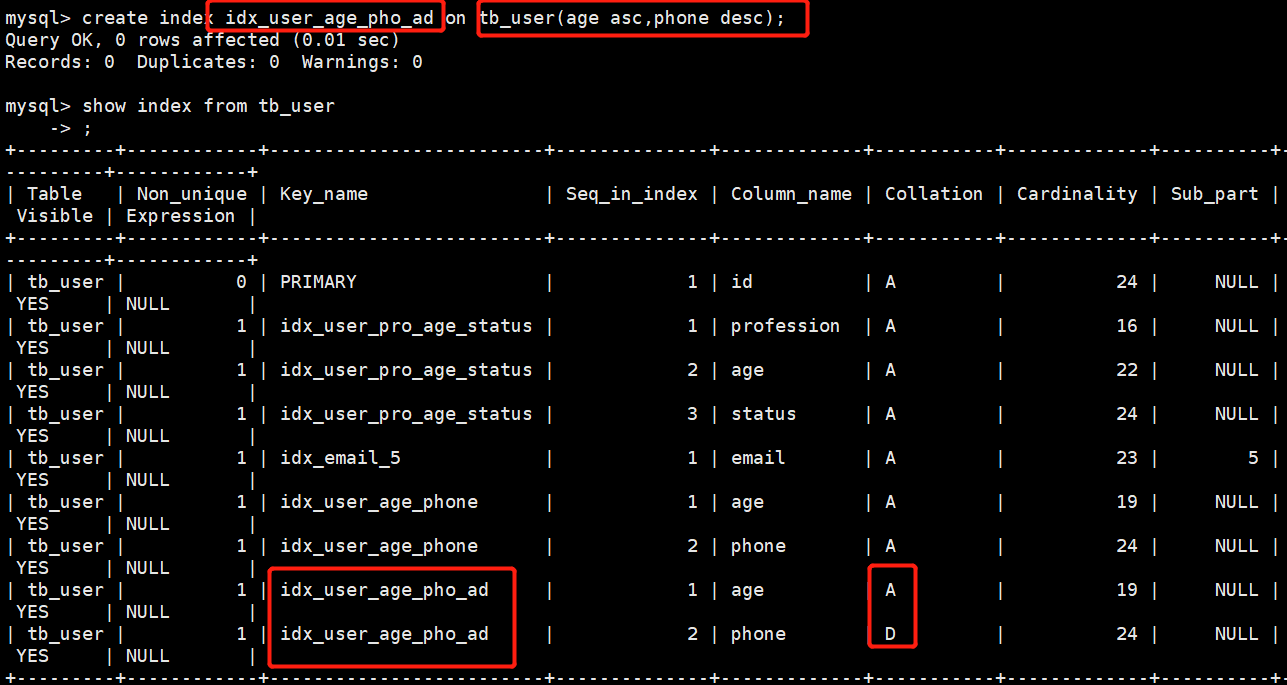

- 索引分析
- 总结
- 根据排序字段建立合适的索引,多字段排序时,也遵守最左前缀法则
- 尽量使用覆盖索引
- 多字段排序,一个升序一个降序,此时注意联合索引可以创建时进行顺序规则的同步
- 如果真的不可避免出现filesort,大数据排序,可是适当增大排序缓冲区大小sort_buffer_size (默认256k),太大就会在磁盘文件中排序
mysql> show variables like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)3.4 group by 优化
- group by 建立索引后的优化
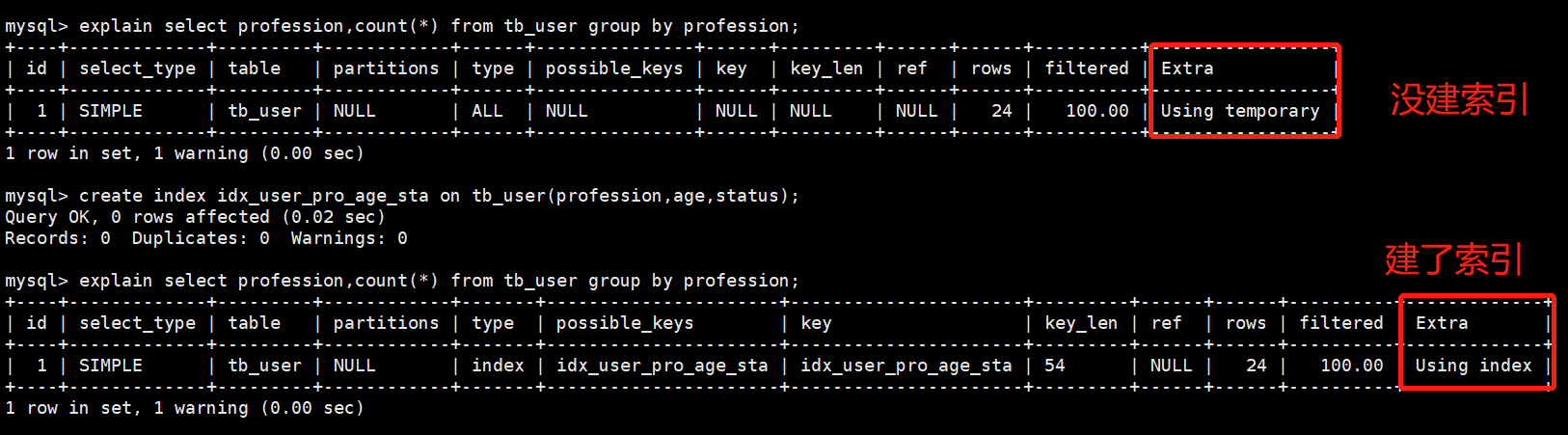
-
不满足最左前缀法则和满足最左前缀法则

- 对最左前缀法则中最左的字段过滤也可以使得对age的分组使用索引

3.5 limit优化
- 场景
- 发现使用limit分页查询的时候,越后面的使用时间越长
- 如MySQL排序前200010记录,仅仅返回200000-200010的记录,其他记录丢弃,查询排序的代价非常大
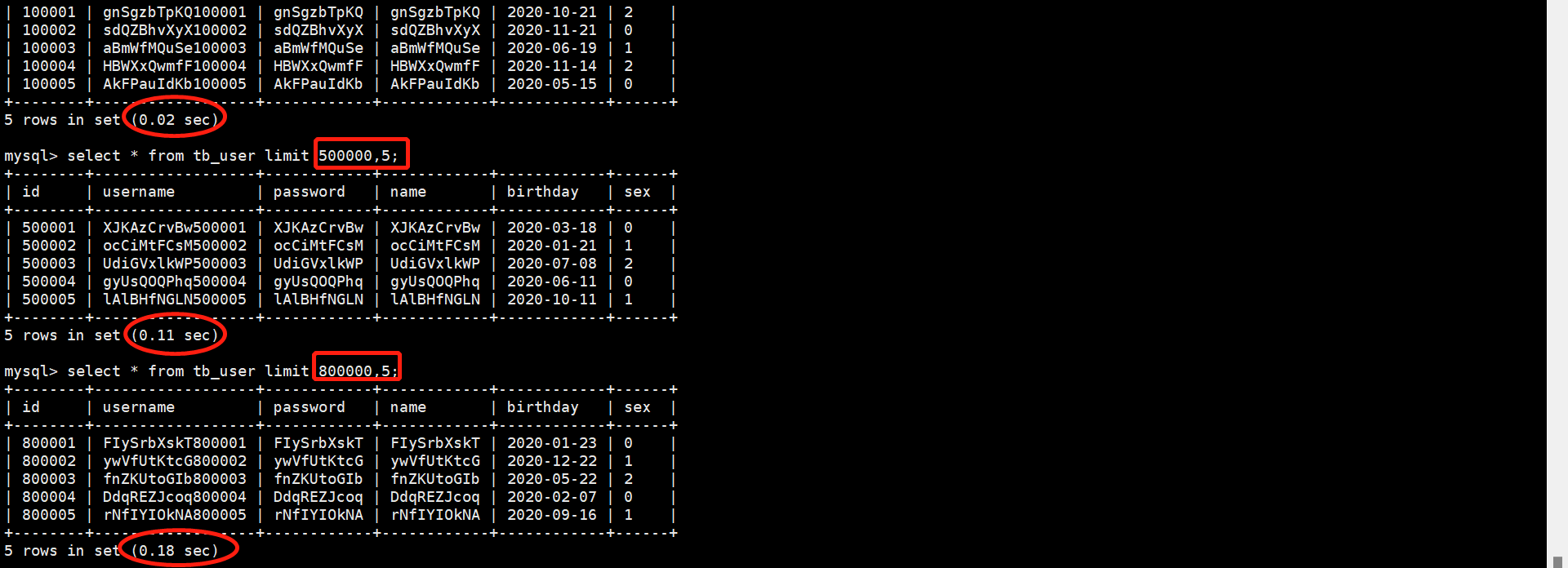
- 优化方法
- 通过覆盖索引加上子查询的方式
mysql>
select
s.*
from
tb_user s,
(
select
id
from
tb_user
order by
id
limit 800000,5
) a
where
s.id = a.id;
+--------+------------------+------------+------------+------------+------+
| id | username | password | name | birthday | sex |
+--------+------------------+------------+------------+------------+------+
| 800001 | FIySrbXskT800001 | FIySrbXskT | FIySrbXskT | 2020-01-23 | 0 |
| 800002 | ywVfUtKtcG800002 | ywVfUtKtcG | ywVfUtKtcG | 2020-12-22 | 1 |
| 800003 | fnZKUtoGIb800003 | fnZKUtoGIb | fnZKUtoGIb | 2020-05-22 | 2 |
| 800004 | DdqREZJcoq800004 | DdqREZJcoq | DdqREZJcoq | 2020-02-07 | 0 |
| 800005 | rNfIYIOkNA800005 | rNfIYIOkNA | rNfIYIOkNA | 2020-09-16 | 1 |
+--------+------------------+------------+------------+------------+------+- 这种子查询版本不适合
mysql> select * from tb_user where id in (select id from tb_user order by id limit 800000,5);
ERROR 1235 (42000): This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'- 或者连接查询
mysql>
select
t.*
from
tb_user t
join
(
select
id
from
tb_user
order by
id
limit 800000,5
) a
where
t.id = a.id;
+--------+------------------+------------+------------+------------+------+
| id | username | password | name | birthday | sex |
+--------+------------------+------------+------------+------------+------+
| 800001 | FIySrbXskT800001 | FIySrbXskT | FIySrbXskT | 2020-01-23 | 0 |
| 800002 | ywVfUtKtcG800002 | ywVfUtKtcG | ywVfUtKtcG | 2020-12-22 | 1 |
| 800003 | fnZKUtoGIb800003 | fnZKUtoGIb | fnZKUtoGIb | 2020-05-22 | 2 |
| 800004 | DdqREZJcoq800004 | DdqREZJcoq | DdqREZJcoq | 2020-02-07 | 0 |
| 800005 | rNfIYIOkNA800005 | rNfIYIOkNA | rNfIYIOkNA | 2020-09-16 | 1 |
+--------+------------------+------------+------------+------------+------+3.6 count优化
- 场景
mysql> select count(*) from tb_user;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.15 sec) - count(*) 原理
- MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*) 的时候会直接返回这个数,效率很高
- InnoDB引擎麻烦了,它执行count(*)的时候,需要一行一行的从引擎中读出来,然后累积计数。
- 优化思路
- 思路:自己计数
- count类型
- count(*) :计算这个表的总记录数,InnoDB专门做了优化,不取值,直接累加
- count(字段):是null的不算
- 没有not null约束,遍历后,服务层会判断是否由null,不为null,就相加
- 有not null约束:遍历后,服务层直接加,不用判断
- count(1): 遍历表,每一行放一个1进去,直接按行进行累加
- count(主键):直接进行相加,服务层计算时候不用考虑是否是null,因为主键不为空
- 总结:按照效率排序,count(字段)<count(主键)<count(1)≈count(*)
3.7 update优化
- 有索引的update
- 由于默认的事务隔离是可重复读repeatable-read,更新一条数据后,没提交,会把这条数据使用行锁给锁住
- 即使两个对话框进行更新的行不一样,也是可以操作的,因为行锁锁的不一样
- 对话框1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update course set name = 'javaEE' where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from course;
+----+--------+
| id | name |
+----+--------+
| 1 | javaEE |
| 2 | PHP |
| 3 | MySQL |
| 4 | Hadoop |
+----+--------+
4 rows in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)- 对话框2
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update course set name = 'Kafka' where id = 4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.00 sec) - 没索引的update
- 没有索引的字段进行更新的时候,会把整整表进行锁住了,导致在进行id = 4 的更新的时候更新不了
-
除非对话框1中commit提交之后,释放锁,对话框2才能执行
- 对话框1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update course set name = 'SpringBoot' where name = 'PHP';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0- 对话框2
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update course set name = 'Kafka' where id = 4;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction- 释放锁的效果


- 对第二点建立索引
- 对话框1
mysql> create index idx_course_name on course(name);
Query OK, 0 rows affected (32.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update course set name = 'Spring' where name = 'SpringBoot';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0- 对话框2
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> update course set name = 'Cloud' where id = 4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0- 说明,建立了name的索引后,表锁没了,只有行锁了
-
总结
- 因为InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且索引不能失效,否则就会从行锁变成表锁,因此根据索引进行update更新!










