2 索引
2.1 安装linux下的mysql
- 去官网下载mysql
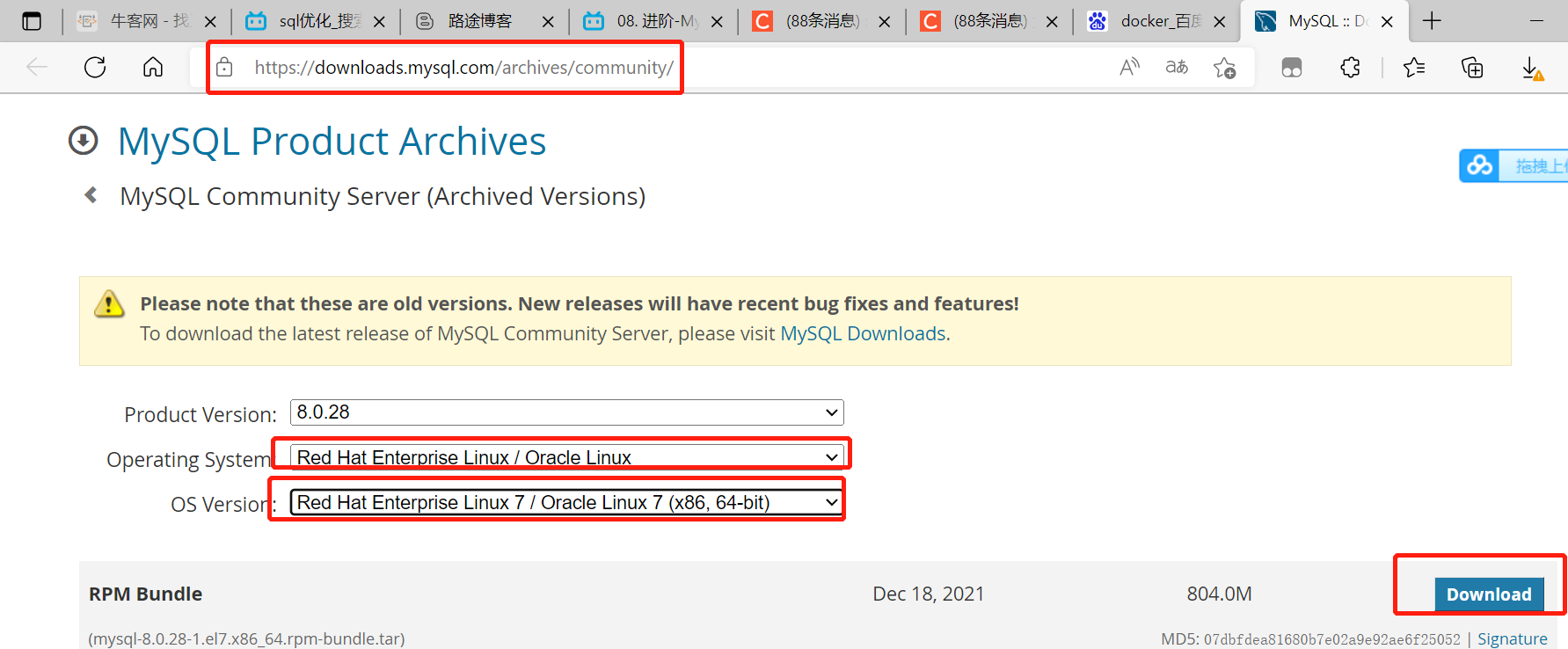
- 解压并安装
- 压缩文件通过xftp解压并且使用rpm安装依赖
[root@hadoop soft]#tar -xvf mysql-8.0.26-1.el7.x86_64.rpm-bundle.tar -C /home/hadoop/app/
[root@hadoop soft]cd ..
[root@hadoop hadoop]#cd app
[root@hadoop app]# rpm -ivh mysql-community-common-8.0.26-1.el7.x86_64.rpm
[root@hadoop app]# yum remove mysql-libs
[root@hadoop app]# rpm -ivh mysql-community-client-plugins-8.0.26-1.el7.x86_64.rpm
[root@hadoop app]# rpm -ivh mysql-community-libs-8.0.26-1.el7.x86_64.rpm
[root@hadoop app]# rpm -ivh mysql-community-libs-compat-8.0.26-1.el7.x86_64.rpm
[root@hadoop app]# yum install openssl-devel
[root@hadoop app]# rpm -ivh mysql-community-devel-8.0.26-1.el7.x86_64.rpm- 安装客户端
[root@hadoop app]#rpm -ivh mysql-community-client-8.0.26-1.el7.x86_64.rpm- 安装服务端
[root@hadoop app]#rpm -ivh mysql-community-server-8.0.26-1.el7.x86_64.rpm- 启动mysql服务
[root@hadoop app]# systemctl start mysqld- 去日志找下随机生成的mysql的root密码
[root@hadoop app]# vim /var/log/mysqld.log
/password- 登录mysql
[root@hadoop app]# mysql -u root -p
Enter password: 嫌麻烦练习的时候直接跳过密码算了:(88条消息) Linux系统安装MySQL报错“ Access denied for user ‘root‘@‘localhost‘ (using password: YES)“_二木成林的博客-CSDN博客
- 把密码等级调低并且更改密码
mysql>set global validate_password_policy = LOW;
mysql>set global validate_password.length = 8;mysql>ALTER USER 'root'@'localhost' IDENTIFIED BY 'xxxxxxxx';- 创建供远程访问的一个用户
mysql>drop user 'root'@'%';
mysql>flush privileges;
mysql>create user 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'xxxxxxxx';
表示在所有的主机上都能访问- 给创建可以远程访问的root用户分配权限
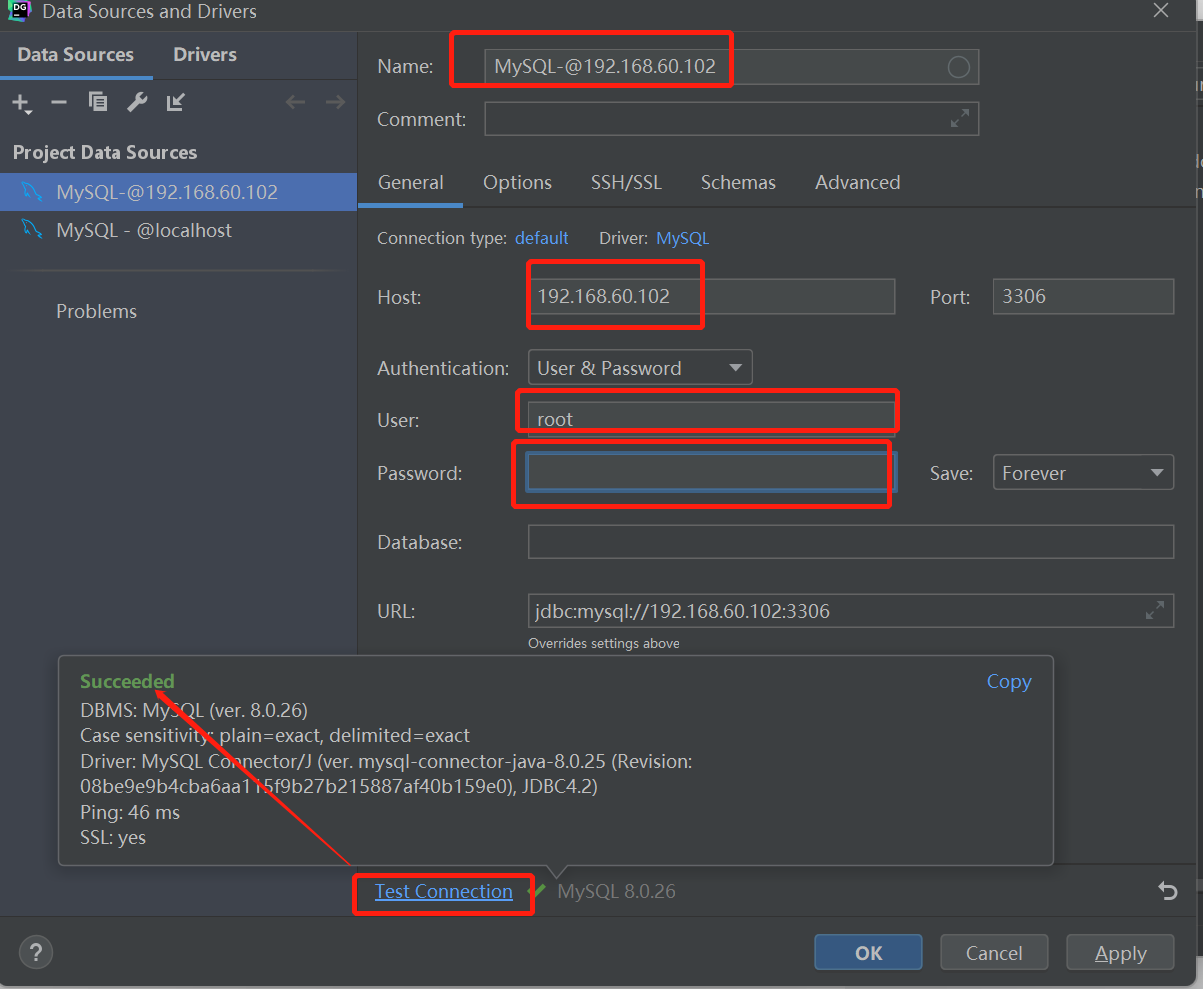
mysql>grant all on *.* to 'root'@'%';- 用datagrip连接看看
- 如果连不上看下linux的防火墙有没有开放3306的端口,或者直接关闭防火墙吧~
2.2 索引概述
- 含义:是帮助MySQL高效获取数据的数据结构(有序)。在数据结构上实现高级查找算法引用(指向)数据。
- 比较
- 无索引,全表扫描,直至结束。性能极低。
- 有索引
- 假如是二叉查找树来一个:如果select * from user from age = 45,那么45会跟36比较,走右边,然后再跟48比较,走左边,然后就找到45了,只需要匹配3次。效率高。
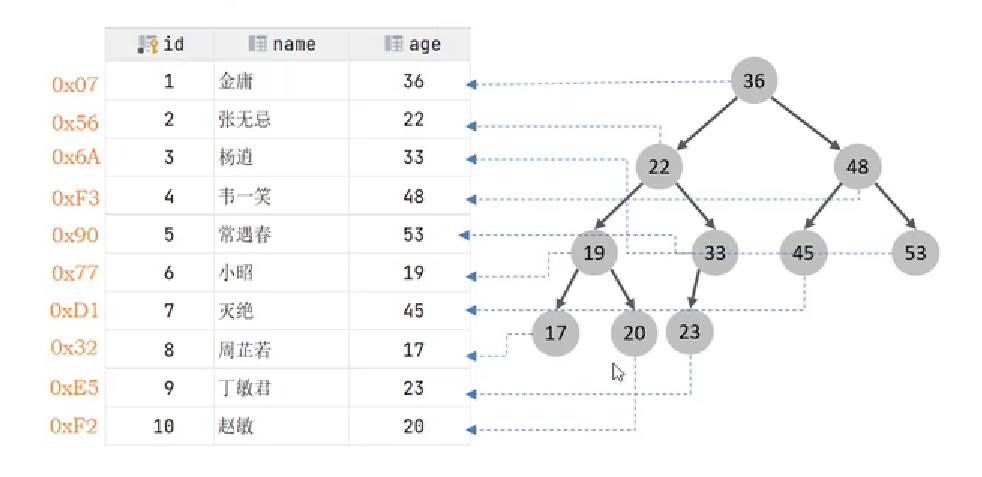
- 假如是二叉查找树来一个:如果select * from user from age = 45,那么45会跟36比较,走右边,然后再跟48比较,走左边,然后就找到45了,只需要匹配3次。效率高。
- 优缺点
- 优点:
- 高效的获取数据,降低数据库获取数据的磁盘IO成本。
- 通过索引对数据进行排序,降低数据排序成本,降低CPU的消耗。
- 缺点:
- 索引也是要占空间滴
- 提高查询效率,但是降低表的更新效率,因为也要维护索引
2.3 索引结构
- 含义:索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构。
- 分类

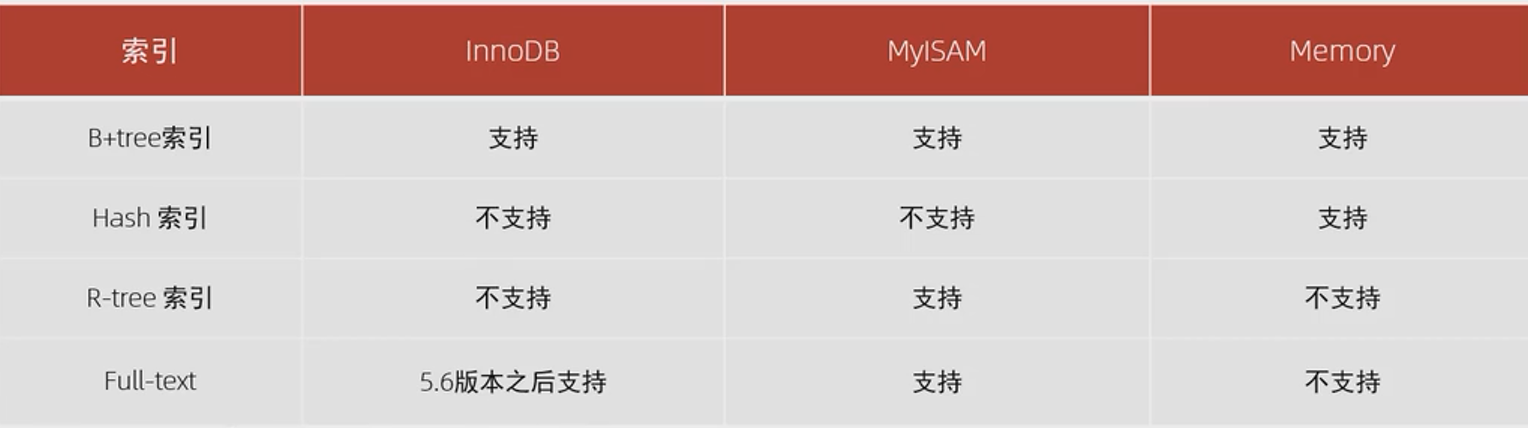
- 二叉树
- 左边节点小于自身,右侧节点大于自身
- 顺序插入,形成链表,性能降低。针对大量数据,层次深,检索满。
-
解决办法:左旋右旋形成红黑树(平衡二叉查找树)
- 但是还是因为只有两个节点导致的在大量数据会形成较深的层次的,因此检索慢的问题

- B-Tree(多路平衡查找树)
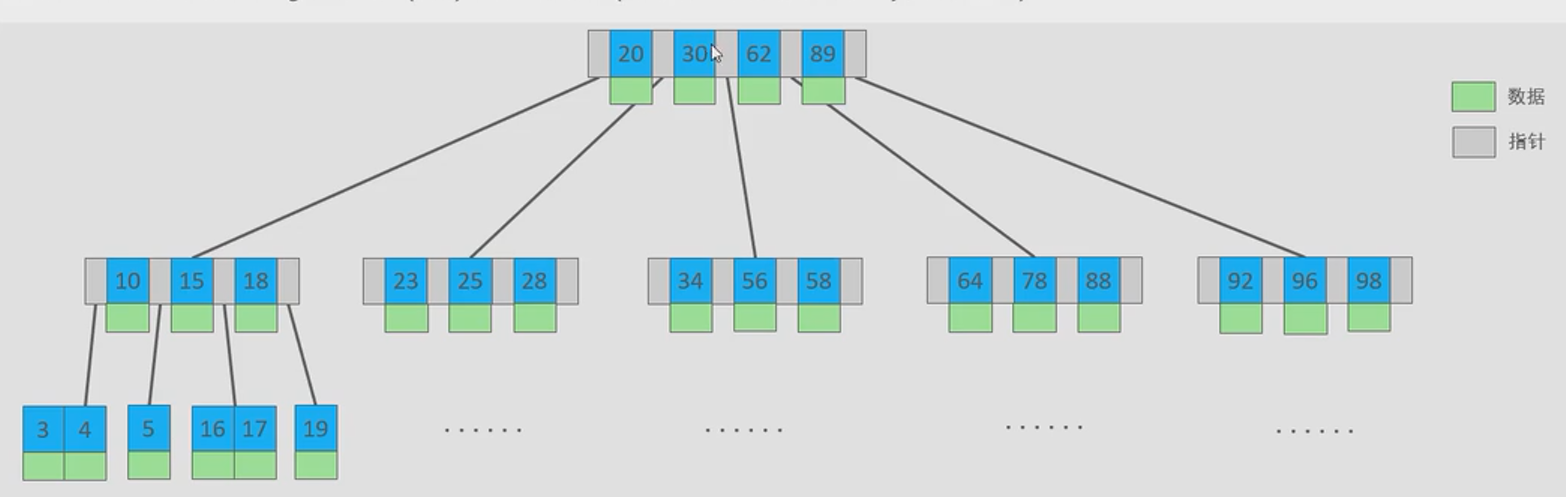
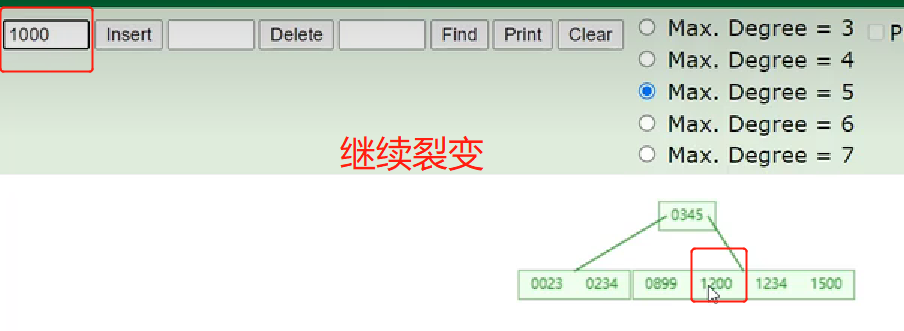
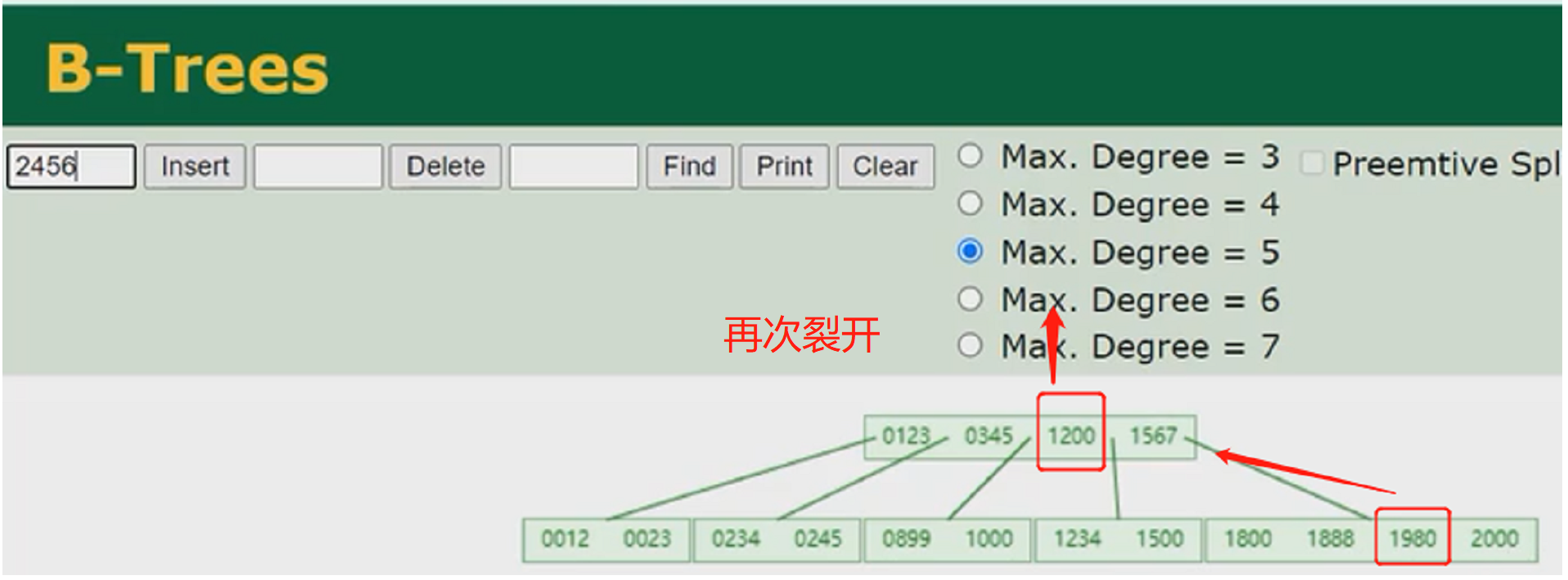
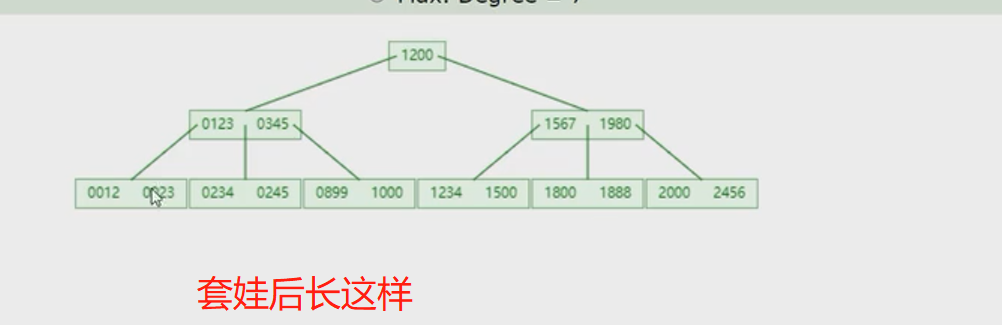
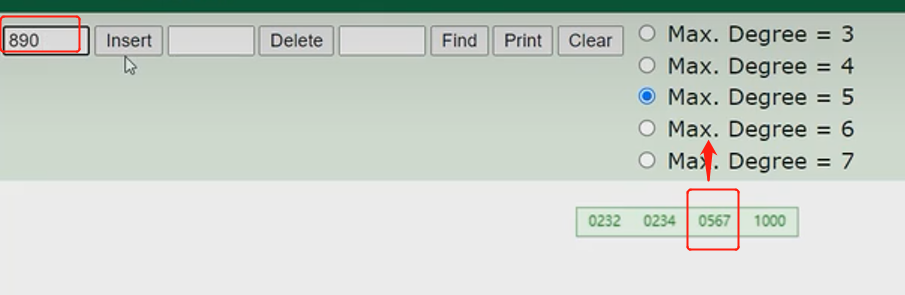
- 概念:以一颗最大度数(max-degree)为5(5阶)的b-tree为例,度数就是节点的子节点个数,那就表示5阶的b树每个节点最多存储4个key,5个指针
- 看图理解下:
- 5阶表示下面有有5个节点,图中根节点就是5个指针灰色的那边,第一个灰色的指针表示小于20这个key,第二个灰色的指针表示在20这个key和30这个key之间,依次共5个,然后每个指针对应下面每个节点。因此得出结论,如果有n个key就有n+1个指针。
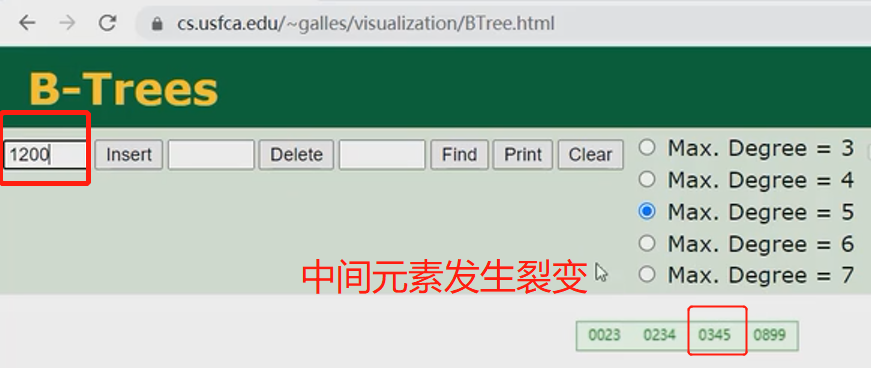
- 来个案例

- B+tree
-
概念:以一颗最大度数(max-degree)为4(4阶)的b+tree为例
-
看图理解
- 与btree的区别是,所有的数据存放都会出现在叶子的节点,并且形成了单项链表,上面的非叶子节点起到的作用是索引的作用
- 也来个例子

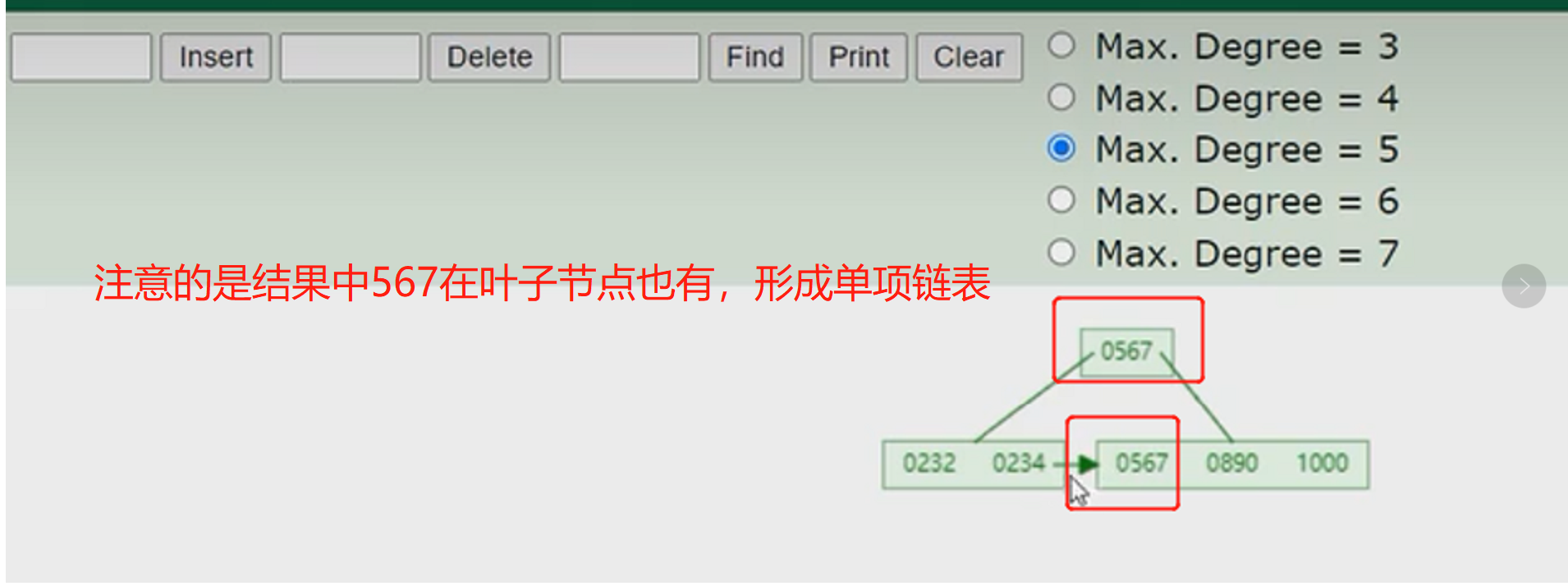
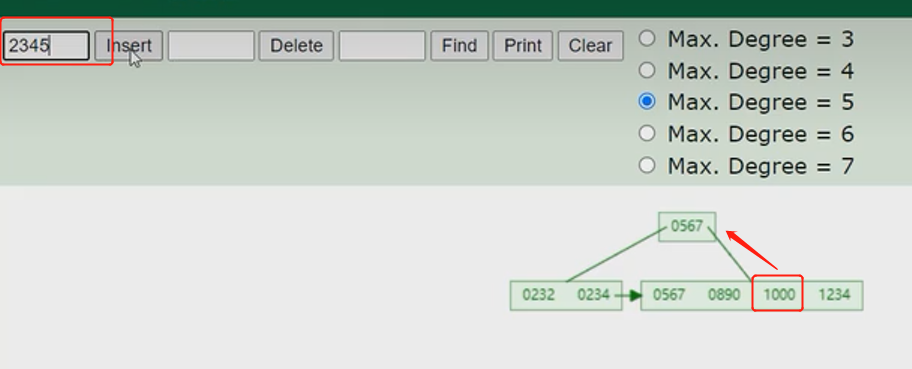
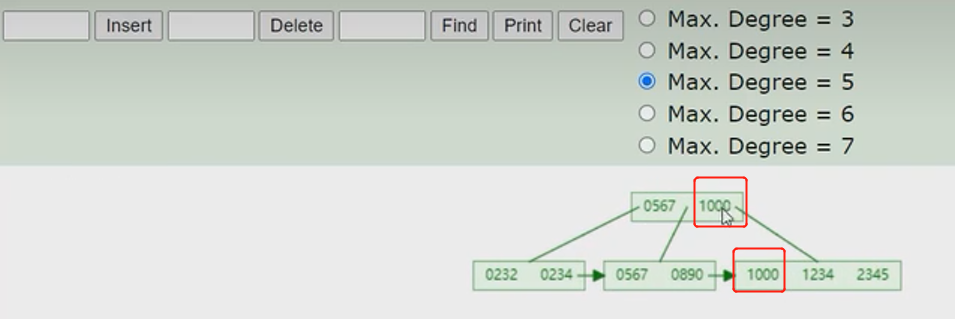
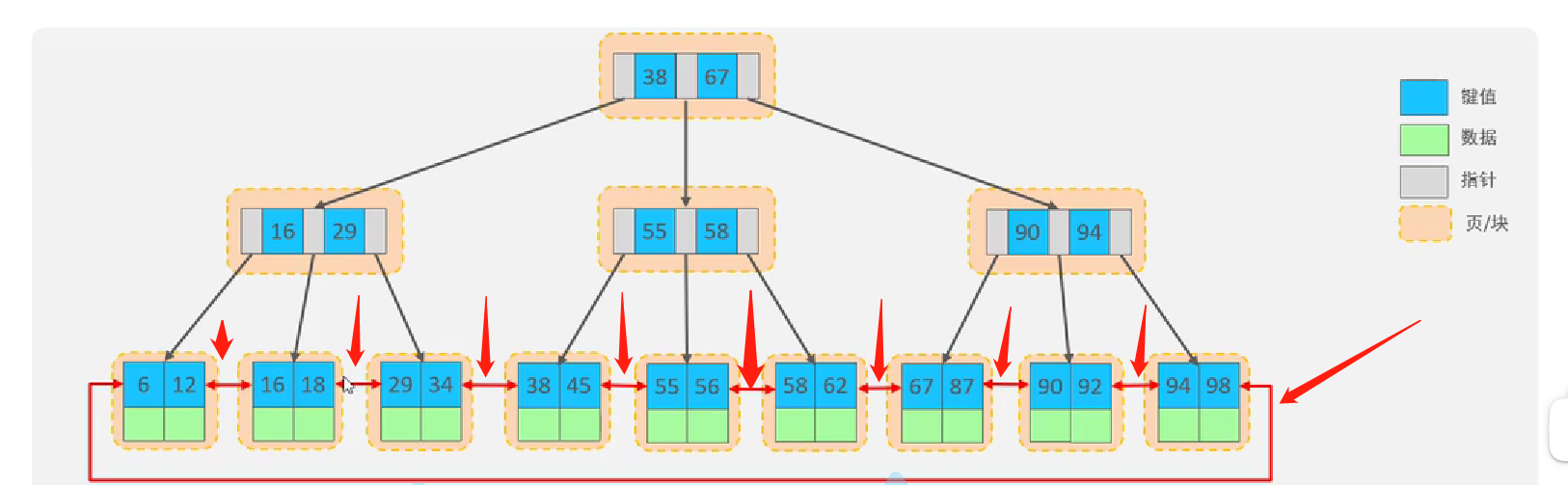
- MySQL的b+tree索引
- 概念:在原来的B+Tree上进行了优化,增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序的B+Tree,提高区间访问的性能。简单说就是把单项链表变成了双向链表
-
看图:
- 每个节点存储在页当中,回忆下前面的InnoDB的逻辑存储结构,表空间、段、区、页、行,一页默认16K,底层就是这么存储的。
- Hash索引
- 每个节点存储在页当中,回忆下前面的InnoDB的逻辑存储结构,表空间、段、区、页、行,一页默认16K,底层就是这么存储的。
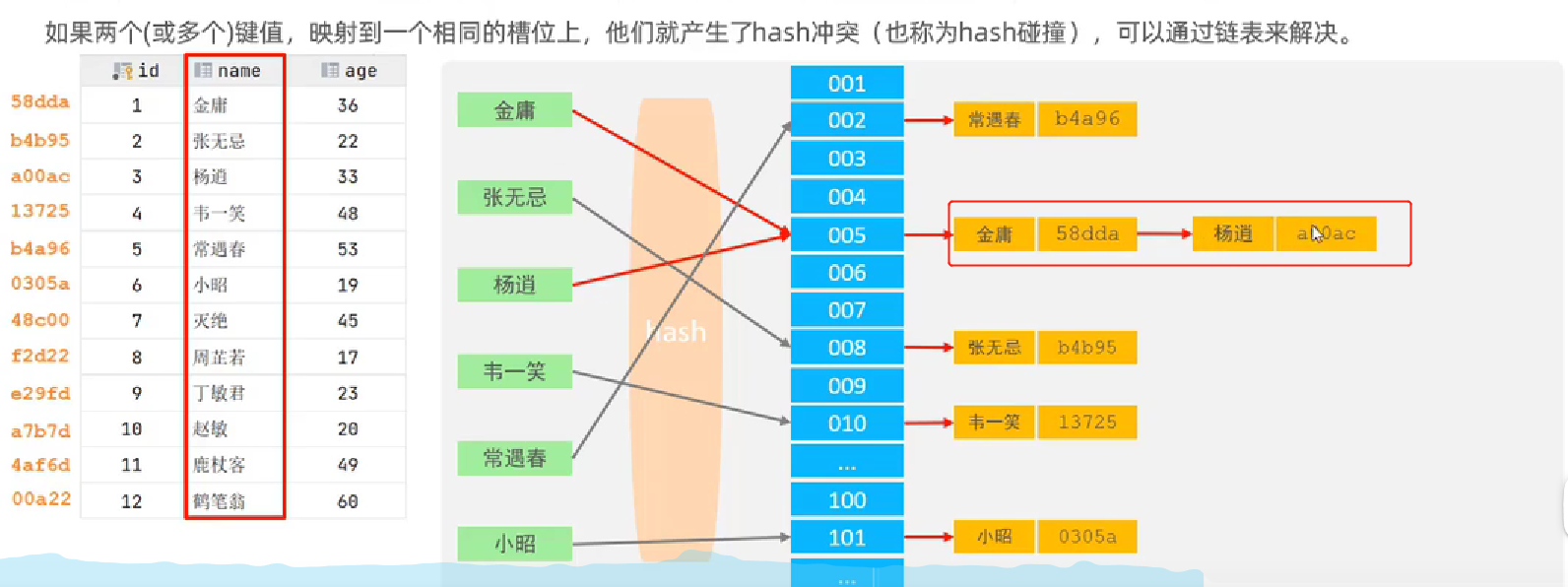
- 概念:哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,存储在hash表中。
- 看图理解
- 背景:id是主键,要为name创造一个哈希索引的数据结构
- 第一步:先计算出每一行数据的哈希值
- 第二步:name字段的所有值根据哈希函数去计算每一个name值应该放在哈希表的哪个槽位上。例如金庸算出来是槽位值005,对应的槽位就会存储金庸这个key,以及金庸这一行对应哈希值58dda,也就是第一步对应的值,怎么理解呢,就理解为58dda是一个引用,指向了金庸所处的那一行的地址

- 杨逍和金庸算出来的槽位一样,就叫做哈希冲突,用链表解决就可以啦
-
特点:
- 只能用于等值
- 无法排序,因为运算结果无序
- 但是查询效率高,通常一次检索匹配就可以了,效率通常高于B+Tree索引
- 支持哈希索引的引擎
- Memory引擎,但是InnoDB中具有的自适应hash功能,就是说有时候可以将B+Tree索引在指定条件下自动构建成哈希索引
- 灵魂一问:为啥InnoDB存储引擎选择B+Tree索引结构?
- 相对于二叉树,层级更少,搜索效率高
- B-tree,所有节点都会存储数据,导致存key和指针的存储的少
- 相对于Hash索引,支持范围匹配和排序操作
2.4 索引分类
- 分类

- 细节:PK不能为空,unique可以为空值,PK和unique在约束时候自动创建了索引
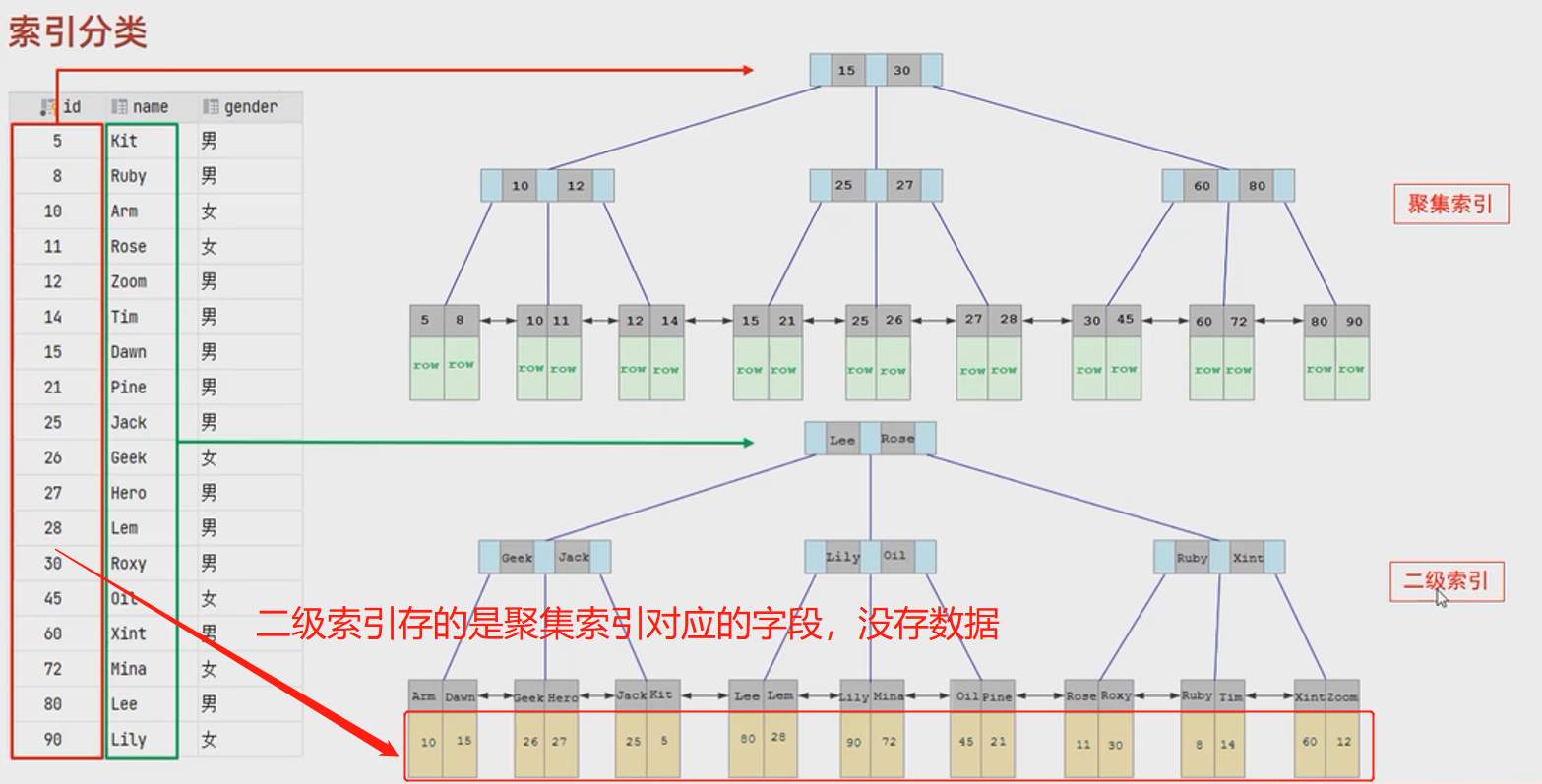
- 根据存储形式的分类

- 规则
- 如果存在主键,主键索引就是聚集索引
- 没有主键,将使用第一个唯一索引作为聚集索引
- 啥都没有咋办,会生成一个rowid所谓隐藏的聚集索引
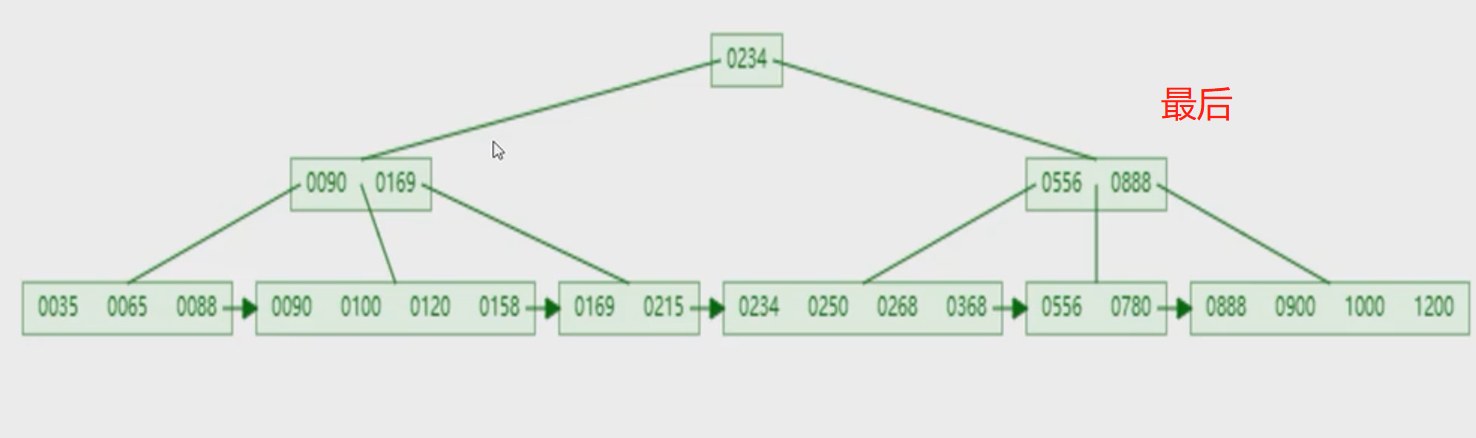
- 来张图理解下
- 聚集索引叶子挂着数据,二级索引下面挂着聚集索引字段
- 查name = 'Arm'的时候,走的是二级索引,字符是按照字典序序走的索引,找到id后,再到上面的聚集索引走一遍,定位10,再把整个数据返回出来,专业数据叫做回表查询
- 来道题
select * from user where id = 10;
select * from user where name = 'Arm';
备注:id为主键,name字段创建的时候有索引
问:哪个sql语句执行效率较高?答案:
- 第一句只要去聚集索引中走一遍,然后获取*的数据就好啦
- 第二句去二级索引中走一遍,然后再拿着id去聚集索引中再去获取*的数据,即回表查询,扫描了两个字段的索引,效率就不高
- 再来道题
问题:InnoDB主键索引的B+Tree高度为多高呀?
前提:假设一行数据为1k,一个指针占用6个字节,主键为bigint,占用8个字节。
解答:(n表示key的数量)
- n8+(n+1)6=16*1024 非叶的节点 n算出来1170个key,指针就有1171个
-
1171*16 = 18736 指针数乘最大的叶子下面最大的行数,高度为2
- 18736 *1171 = 21939856 高度为3 的时候 如下图的就是高度为3

2.5 索引的操作语法
- 创建索引
create [unique|fulltext] index index_name on table_name(index_col_name,...)- unique表示唯一索引,fulltext表示全文索引
- 一个索引可以关联多个字段的,一个字段叫单列索引,多个字段叫做联合索引
- 查看索引
show index from table_name;- 删除索引
drop index index_name on table_name;- 练习
-
name字段为姓名字段,该字段的值可能会重复,为该字段创建索引
-
看下现在有什么索引先
-
mysql> show index from tb_user\G; *************************** 1. row *************************** Table: tb_user Non_unique: 0 Key_name: PRIMARY Seq_in_index: 1 Column_name: id Collation: A Cardinality: 24 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL 1 row in set (0.00 sec) -
创建索引
-
mysql> create index idx_user_name on tb_user(name); Query OK, 0 rows affected (0.03 sec)
-
- phone手机号字段的值,是非空的且唯一的,给他创建唯一索引
mysql> create unique index idx_user_phone on tb_user(phone);
Query OK, 0 rows affected (0.01 sec)- 为profession、age、status创建联合索引
- 联合索引字段的讲究:使用最频繁的字段放在左侧。根据使用频繁程度从重到轻,要遵循''最左前缀原则''
mysql> create index idx_user_pro_age_status on tb_user(profession,age,status);
Query OK, 0 rows affected (0.01 sec)- 为email字段建立合适的索引来提升查询效率
mysql> create index idx_user_email on tb_user(email);
Query OK, 0 rows affected (0.01 sec)- 删除索引
mysql> drop index idx_user_email on tb_user;
Query OK, 0 rows affected (0.01 sec)









