Kafka集群部署并启动
在本文中将从演示如何搭建一个Kafka集群开始,然后简要介绍一下关于Kafka集群的一些基础知识点。但本文仅针对集群做介绍,对于Kafka的基本概念不做过多说明,这里假设读者拥有一定的Kafka基础知识。
首先,我们需要了解Kafka集群的一些机制:
- Kafka是天然支持集群的,哪怕是一个节点实际上也是集群模式
- Kafka集群依赖于Zookeeper进行协调,并且在早期的Kafka版本中很多数据都是存放在Zookeeper的
- Kafka节点只要注册到同一个Zookeeper上就代表它们是同一个集群的
- Kafka通过
brokerId来区分集群中的不同节点
Kafka的集群拓扑图如下:
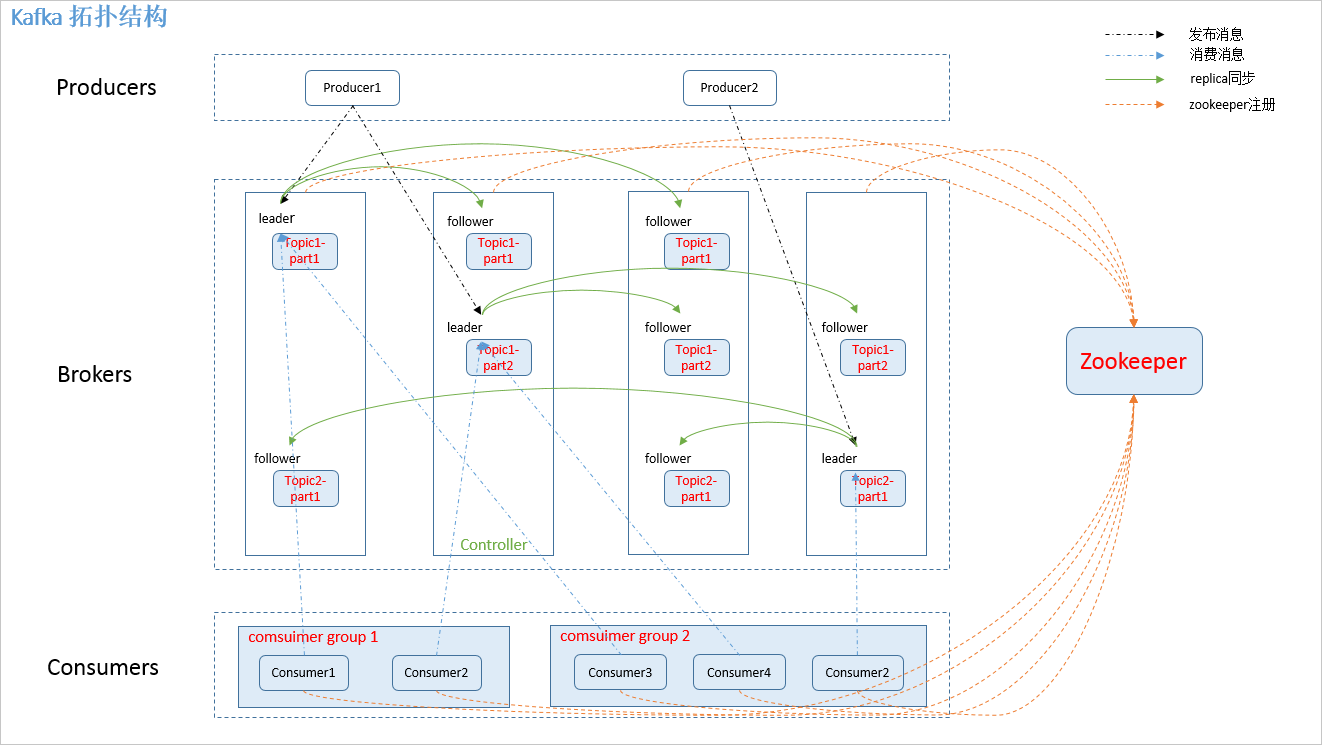
Kafka集群中的几个角色:
- Broker:一般指Kafka的部署节点
- Leader:用于处理消息的接收和消费等请求,也就是说producer是将消息push到leader,而consumer也是从leader上去poll消息
- Follower:主要用于备份消息数据,一个leader会有多个follower
在本例中,为了更贴近实际的部署情况,使用了四台虚拟机作演示:
| 机器IP | 作用 | 角色 | brokerId |
|---|---|---|---|
| 192.168.99.1 | 部署Kafka节点 | broker server | 0 |
| 192.168.99.2 | 部署Kafka节点 | broker server | 1 |
| 192.168.99.3 | 部署Kafka节点 | broker server | 2 |
| 192.168.99.4 | 部署Zookeeper节点 | 集群协调者 |
Zookeeper安装
Kafka是基于Zookeeper来实现分布式协调的,所以在搭建Kafka节点之前需要先搭建好Zookeeper节点。而Zookeeper和Kafka都依赖于JDK,我这里已经事先安装好了JDK:
[root@192.168.99.4 ~]# java --version
java 11.0.5 2019-10-15 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.5+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.5+10-LTS, mixed mode)
[root@txy-server2 ~]#
准备好JDK环境后,到Zookeeper的官网下载地址,复制下载链接:
然后到Linux中使用wget命令进行下载,如下:
[root@192.168.99.4 ~]# cd /usr/local/src
[root@192.168.99.4 /usr/local/src]# wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.gz
解压下载好的压缩包,并将解压后的目录移动和重命名:
[root@192.168.99.4 /usr/local/src]# tar -zxvf apache-zookeeper-3.6.1-bin.tar.gz
[root@192.168.99.4 /usr/local/src]# mv apache-zookeeper-3.6.1-bin ../zookeeper
进入到Zookeeper的配置文件目录,将zoo_sample.cfg这个示例配置文件拷贝一份并命名为zoo.cfg,这是Zookeeper默认的配置文件名称:
[root@192.168.99.4 /usr/local/src]# cd ../zookeeper/conf/
[root@192.168.99.4 /usr/local/zookeeper/conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@192.168.99.4 /usr/local/zookeeper/conf]# cp zoo_sample.cfg zoo.cfg
修改一下配置文件中的dataDir配置项,指定一个磁盘空间较大的目录:
[root@192.168.99.4 /usr/local/zookeeper/conf]# vim zoo.cfg
# 指定Zookeeper的数据存储目录,类比于MySQL的dataDir
dataDir=/data/zookeeper
[root@192.168.99.4 /usr/local/zookeeper/conf]# mkdir -p /data/zookeeper
- 如果只是学习使用的话,这一步其实可以忽略,采用默认配置即可
接下来就可以进入bin目录,使用启动脚本来启动Zookeeper了,如下示例:
[root@192.168.99.4 /usr/local/zookeeper/conf]# cd ../bin/
[root@192.168.99.4 /usr/local/zookeeper/bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@192.168.99.4 /usr/local/zookeeper/bin]#
启动完成后,可以通过查看是否正常监听端口号来判断是否启动成功,如下则是启动成功了:
[root@192.168.99.4 ~]# netstat -lntp |grep 2181
tcp6 0 0 :::2181 :::* LISTEN 7825/java
[root@192.168.99.4 ~]#
如果你的机器开启了防火墙的话,则需要开放Zookeeper的端口,否则其他节点无法注册上来:
[root@192.168.99.4 ~]# firewall-cmd --zone=public --add-port=2181/tcp --permanent
[root@192.168.99.4 ~]# firwall-cmd --reload
Kafka安装
安装完Zookeeper后,接下来就可以安装Kafka了,同样的套路首先去Kafka的官网下载地址,复制下载链接:
然后到Linux中使用wget命令进行下载,如下:
[root@192.168.99.1 ~]# cd /usr/local/src
[root@192.168.99.1 /usr/local/src]# wget https://mirror.bit.edu.cn/apache/kafka/2.5.0/kafka_2.13-2.5.0.tgz
解压下载好的压缩包,并将解压后的目录移动和重命名:
[root@192.168.99.1 /usr/local/src]# tar -xvf kafka_2.13-2.5.0.tgz
[root@192.168.99.1 /usr/local/src]# mv kafka_2.13-2.5.0 ../kafka
进入Kafka的配置文件目录,修改配置文件:
[root@192.168.99.1 /usr/local/src]# cd ../kafka/config/
[root@192.168.99.1 /usr/local/kafka/config]# vim server.properties
# 指定该节点的brokerId,同一集群中的brokerId需要唯一
broker.id=0
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.99.1:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.99.1:9092
# 指定kafka日志文件的存储目录
log.dirs=/usr/local/kafka/kafka-logs
# 指定zookeeper的连接地址,若有多个地址则用逗号分隔
zookeeper.connect=192.168.99.4:2181
[root@192.168.99.1 /usr/local/kafka/config]# mkdir /usr/local/kafka/kafka-logs
在完成配置文件的修改后,为了方便使用Kafka的命令脚本,我们可以将Kafka的bin目录配置到环境变量中:
[root@192.168.99.1 ~]# vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@192.168.99.1 ~]# source /etc/profile # 让配置生效
这样就可以使用如下命令启动Kafka了:
[root@192.168.99.1 ~]# kafka-server-start.sh /usr/local/kafka/config/server.properties &
执行以上命令后,启动日志会输出到控制台,可以通过日志判断是否启动成功,也可以通过查看是否监听了9092端口来判断是否启动成功:
[root@192.168.99.1 ~]# netstat -lntp |grep 9092
tcp6 0 0 192.168.99.1:9092 :::* LISTEN 31943/java
[root@192.168.99.1 ~]#
同样的,开启了防火墙的话,还需要开放相应的端口号:
[root@192.168.99.1 ~]# firewall-cmd --zone=public --add-port=9092/tcp --permanent
[root@192.168.99.1 ~]# firwall-cmd --reload
到此为止,我们就完成了第一个Kafka节点的安装,另外两个节点的安装步骤也是一样的,只需要修改一下配置文件中的brokerId和监听的ip就好了。所以我这里直接将该节点中的Kafka目录拷贝到另外两台机器上:
[root@192.168.99.1 ~]# rsync -av /usr/local/kafka 192.168.99.2:/usr/local/kafka
[root@192.168.99.1 ~]# rsync -av /usr/local/kafka 192.168.99.3:/usr/local/kafka
然后修改一下这两个节点的brokerId和监听的ip:
[root@192.168.99.2 /usr/local/kafka/config]# vim server.properties
# 修改brokerId
broker.id=1
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.99.2:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.99.2:9092
[root@192.168.99.2 /usr/local/kafka/config]#
[root@192.168.99.3 /usr/local/kafka/config]# vim server.properties
# 修改brokerId
broker.id=2
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.99.3:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.99.3:9092
[root@192.168.99.3 /usr/local/kafka/config]#
配置修改完成后,按之前所介绍的步骤启动这两个节点。启动成功后进入Zookeeper中,在/brokers/ids下有相应的brokerId数据代表集群搭建成功:
[root@192.168.99.4 ~]# /usr/local/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 4] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 5]
Kafka副本集
关于Kafka的副本集:
- Kafka副本集是指将日志复制多份,我们知道Kafka的数据是存储在日志文件中的,这就相当于数据的备份、冗余
- Kafka可以通过配置设置默认的副本集数量
- Kafka可以为每个Topic设置副本集,所以副本集是相对于Topic来说的
一个Topic的副本集可以分布在多个Broker中,当一个Broker挂掉了,其他的Broker上还有数据,这就提高了数据的可靠性,这也是副本集的主要作用。
我们都知道在Kafka中的Topic只是个逻辑概念,实际存储数据的是Partition,所以真正被复制的也是Partition。如下图:
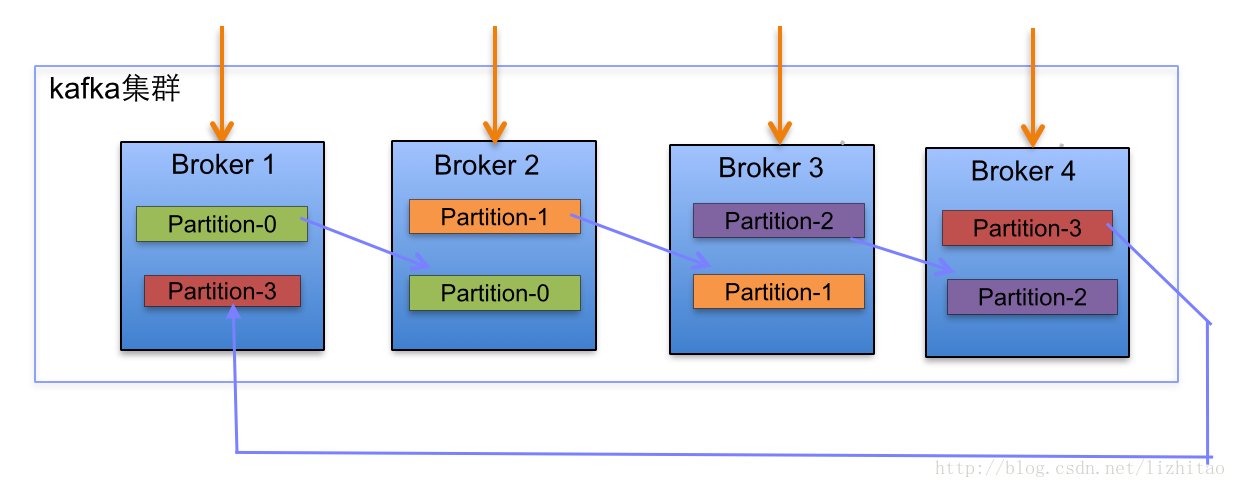
关于副本因子:
- 副本因子其实决定了一个Partition的副本数量,例如副本因子为1,则代表将Topic中的所有Partition按照Broker的数量复制一份,并分布到各个Broker上
副本分配算法如下:
- 将所有N Broker和待分配的
i个Partition排序 - 将第
i个Partition分配到第(i mod n)个Broker上 - 将第
i个Partition的第j个副本分配到第((i + j) mod n)个Broker上
Kafka节点故障原因及处理方式
Kafka节点(Broker)故障的两种情况:
- Kafka节点与Zookeeper心跳未保持视为节点故障
- 当follower的消息落后于leader太多也会视为节点故障
Kafka对节点故障的处理方式:
- Kafka会对故障节点进行移除,所以基本不会因为节点故障而丢失数据
- Kafka的语义担保也很大程度上避免了数据丢失
- Kafka会对消息进行集群内平衡,减少消息在某些节点热度过高
Kafka Leader选举机制简介
Kafka集群之Leader选举:
- 如果有接触过其他一些分布式组件就会了解到大部分组件都是通过投票选举来在众多节点中选举出一个leader,但在Kafka中没有采用投票选举来选举leader
- Kafka会动态维护一组Leader数据的副本(ISR)
- Kafka会在ISR中选择一个速度比较快的设为leader

“巧妇难为无米之炊”:Kafka有一种无奈的情况,就是ISR中副本全部宕机。对于这种情况,Kafka默认会进行unclean leader选举。Kafka提供了两种不同的方式进行处理:
- 等待ISR中任一Replica恢复,并选它为Leader
- 等待时间较长,会降低可用性,或ISR中的所有Replica都无法恢复或者数据丢失,则该Partition将永不可用
- 选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
- 并未包含所有已被之前Leader Commit过的消息,因此会造成数据丢失,但可用性较高
Leader选举配置建议:
- 禁用unclean leader选举
- 手动设置最小ISR
关于ISR更详细的内容可以参考:
- https://www.jianshu.com/p/ff296d51385a
- https://blog.csdn.net/qq_37502106/article/details/80271800










