1 实战
1.1 案例介绍
目标:通过实时采集处理不同系统注册用户的信息,获得各个城市用户注册总量数据。
系统结构如下图所示。
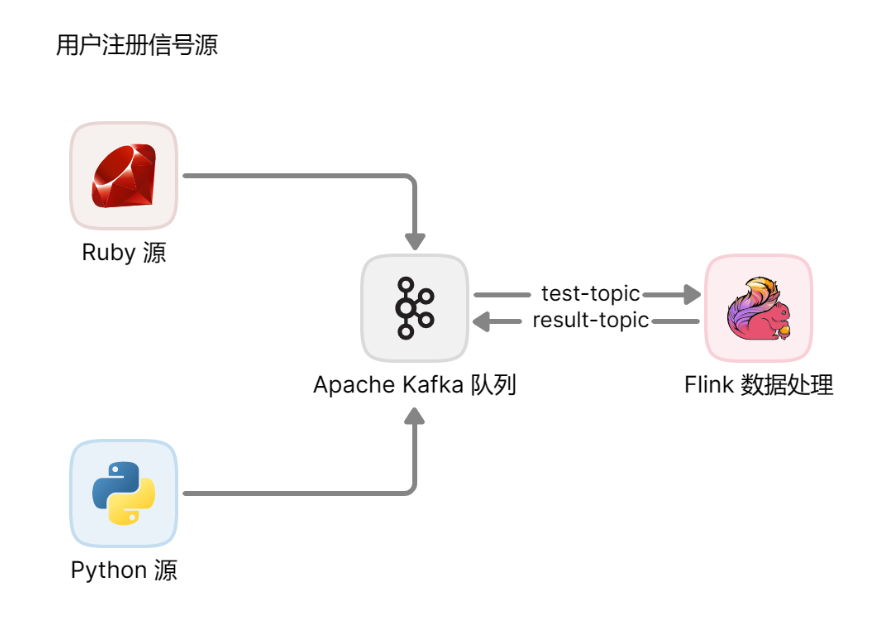
这里使用 Python 脚本和 Ruby 脚本模拟产生用户注册的日志信息,使用 kafka 接收到 test-topic 主题,经由 Flink 处理,最终存储回 kafka 的 result-topic 主题。
1.2 实现方式
开发人员配置环境,决定开发任务,再使用 ChatGPT 帮助编写主要代码,然后由开发人员 review,决定是否重写或者修改,最后由开发人员集成后运行,检测代码可用。
本次运行环境为 wsl。
2 开发
2.1 初始化项目
使用 gitee 创建 kafka-flink-case 仓库,并克隆到本地。
2.2 配置 kafka 并运行
# 切换到工作目录
cd kafka_2.13-3.4.0
# 启动 zookeeper (左上窗口)
bin/zookeeper-server-start.sh config/zookeeper.properties
# 启动 kafka (左下窗口)
bin/kafka-server-start.sh config/server.properties
# 创建主题 (右上窗口)
bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092
# Created topic test-topic.
# 启动消费服务 (右上窗口)
bin/kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost:9092
# 启动生产服务 (右下窗口)
bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092
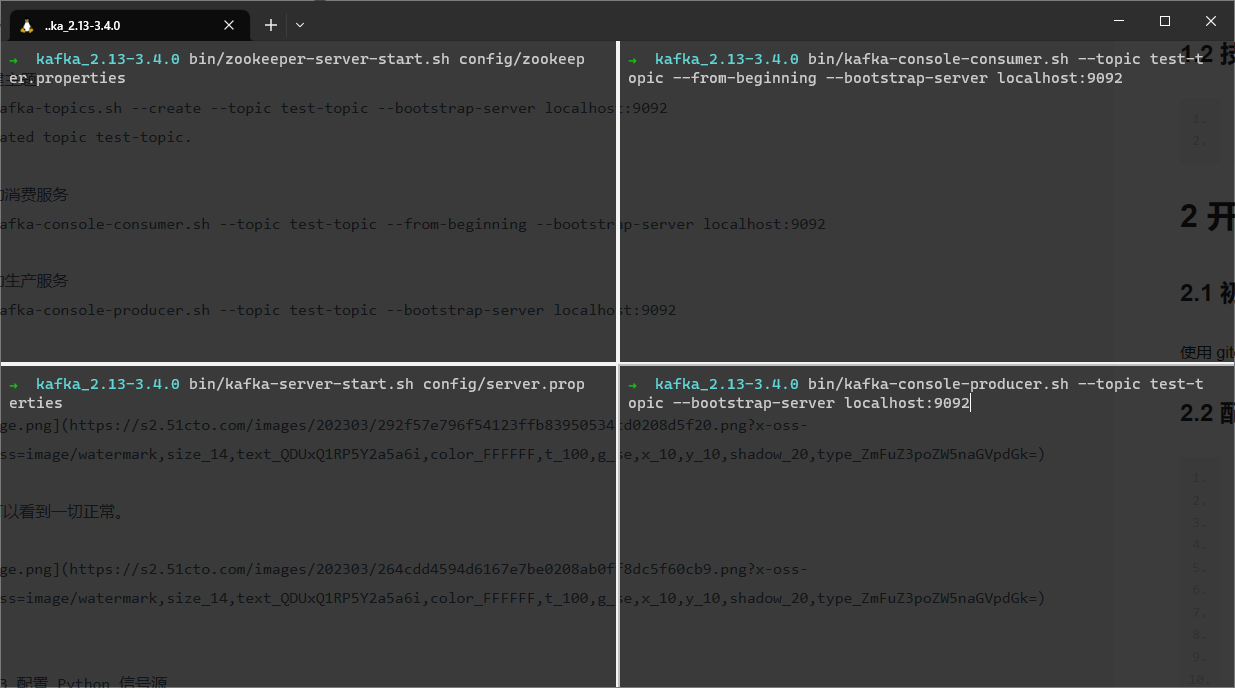
我们可以看到一切正常,测试结果正确。
2.3 配置 Python 信号源
2.3.1 编写信号源文件
通过 ChatGPT-3 编写脚本
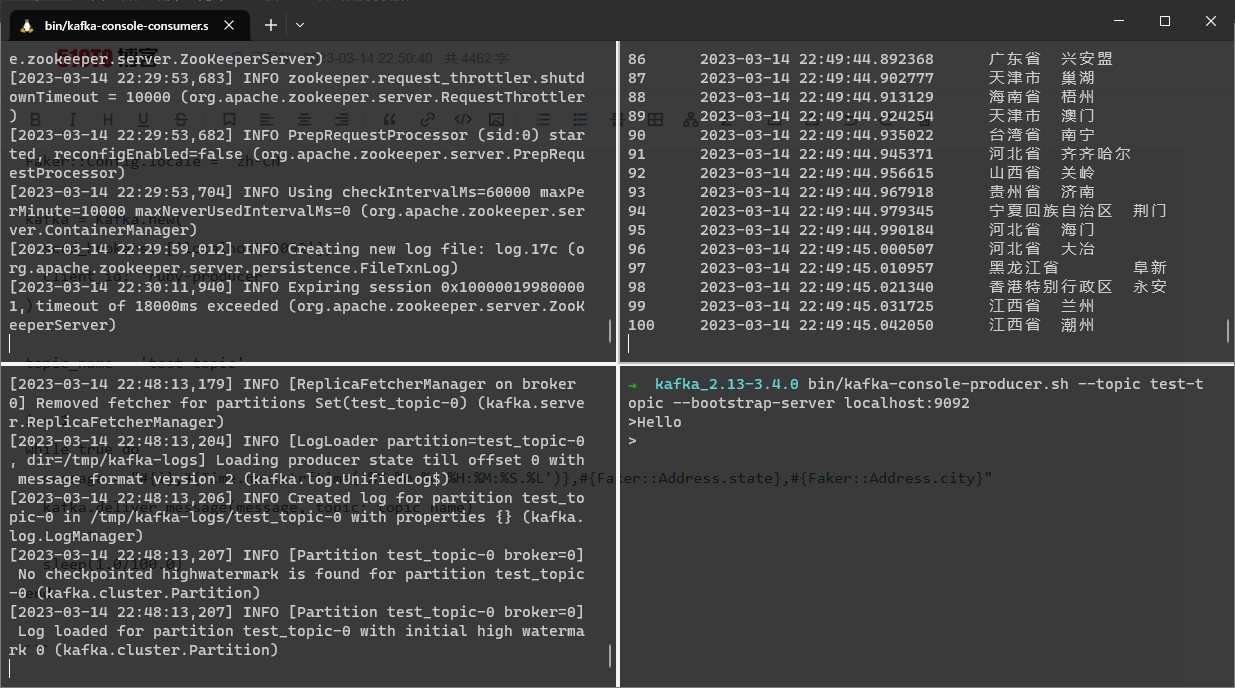
python 输出信息到 kafka,包含序号、时间戳(精确到毫秒)、模拟的用户信息(包含中国省份和城市),每秒100条
import time
import datetime
import random
from faker import Faker
from kafka import KafkaProducer
# Kafka 相关配置
bootstrap_servers = ['localhost:9092'] # Kafka broker 地址和端口
topic_name = 'test_topic' # Kafka topic 名称
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
# Faker 生成器,用于生成随机的用户信息
faker = Faker('zh_CN')
# 模拟生产 100 条消息,每秒发送一次
for i in range(1, 101):
# 获取当前时间戳(精确到毫秒)
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# 生成随机的省份和城市信息
province = faker.province()
city = faker.city_name()
# 组装消息内容
message = f'{i}\t{timestamp}\t{province}\t{city}'.encode('utf-8')
# 发送消息到 Kafka
producer.send(topic_name, message)
# 每秒发送一次消息
time.sleep(1 / 100)
producer.flush()
producer.close()
创建工作目录并切换进去,将内容保存到 app.py
mkdir producer01 && cd producer01 && vim app.py
# i
# p
# :wq
2.3.2 检查环境和安装依赖
python --version
# Python 3.9.13
pip --version
# pip 22.2.2 from ~/anaconda3/lib/python3.9/site-packages/pip (python 3.9)
pip install kafka-python
# Requirement already satisfied: kafka-python in ~/anaconda3/lib/python3.9/site-packages (2.0.2)
pip install faker
# Requirement already satisfied: faker in ~/anaconda3/lib/python3.9/site-packages (8.8.1)
2.3.3 生产信息
在 producer01 目录下
python app.py
文件内容和运行命令展示
运行结果展示
2.4 配置 ruby 信号源
2.4.1 编写 ruby 脚本
使用 ChatGPT-3 编写
使用ruby实现
require 'kafka'
require 'faker'
Faker::Config.locale = 'zh-CN'
kafka = Kafka.new(
seed_brokers: ['localhost:9092'],
client_id: 'ruby-producer'
)
topic_name = 'test-topic'
i = 1
while true do
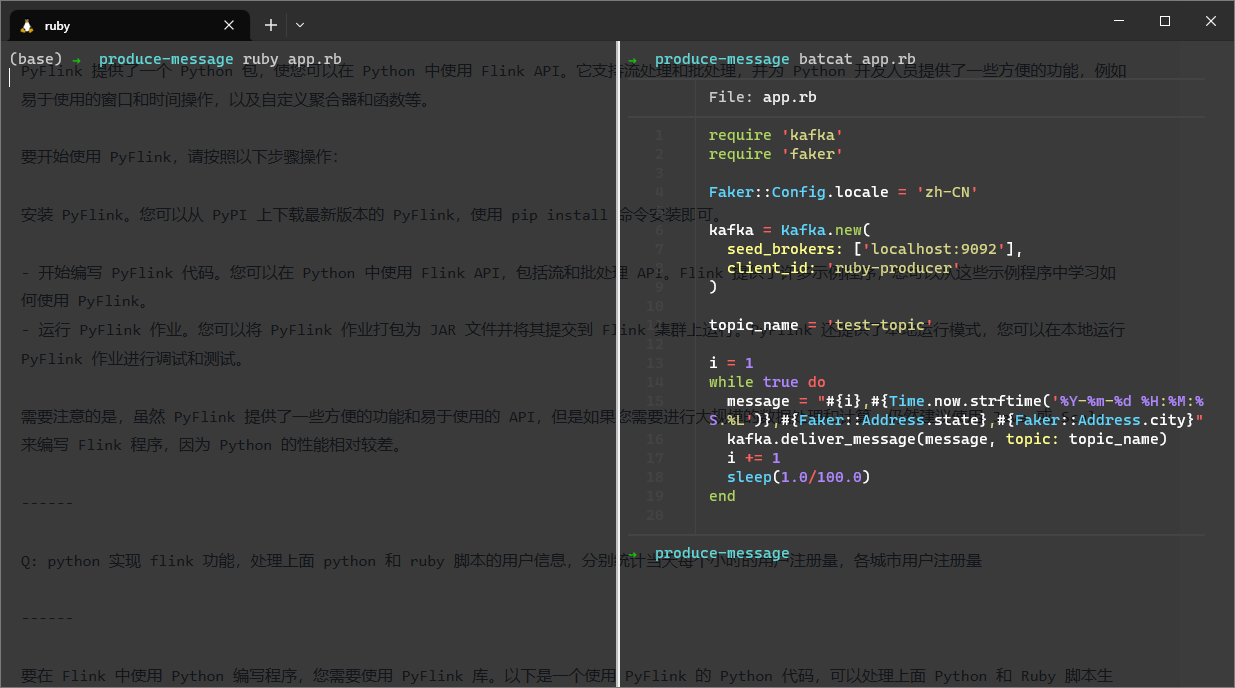
message = "#{i},#{Time.now.strftime('%Y-%m-%d %H:%M:%S.%L')},#{Faker::Address.state},#{Faker::Address.city}"
kafka.deliver_message(message, topic: topic_name)
i += 1
sleep(1.0/100.0)
end
ruby 下的 kafka 使用哪个类库
在 Ruby 中,可以使用 ruby-kafka 库来与 Kafka 进行交互。这个库提供了一个高级别的 API,简化了 Kafka 生产者和消费者的使用。
将文件保存为 app.rb
2.4.2 检查环境和安装依赖
ruby --version
#ruby 2.7.4p191 (2021-07-07 revision a21a3b7d23) [x86_64-linux-gnu]
gem --version
# 3.2.5
gem install ruby-kafka faker
# Fetching ...
# ...
# ... gems installed
2.4.3 生产信息
运行文件
ruby app.rb
文件内容和运行命令展示
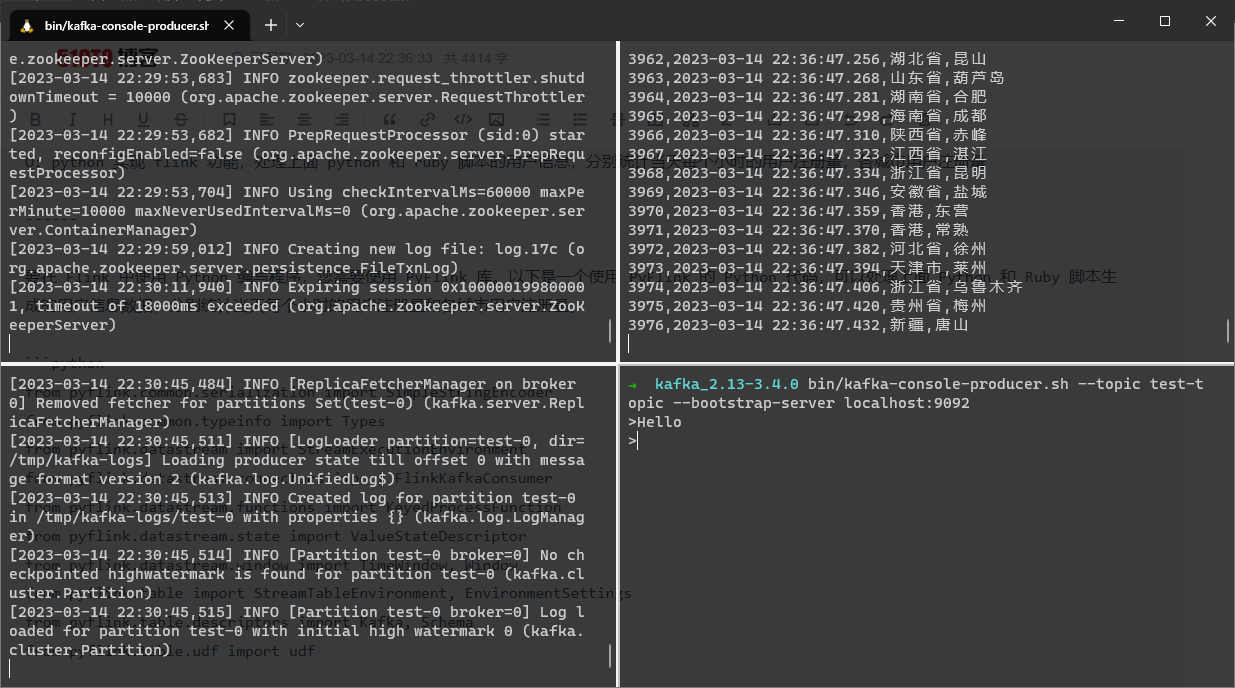
运行结果展示
2.5 信息生产小结
从上面的日志格式我们可以发现, Python 信息源中各项信息间隔为\t,Ruby 信息源中各项信息间隔为,。
2.6 Flink 数据分析
2.6.1 编写 Flink 处理脚本
使用 ChatGPT-3 编写
Q: flink 处理 kafka test-topic 队列的消息,格式为 "100 2023-03-14 22:49:45.042050 江西省 潮州",输出每分钟各城市的注册数量,追加信息来源为python
A: 可以使用Flink的DataStream API处理Kafka中的消息,并且使用Flink提供的窗口函数将每分钟的数据聚合起来。具体实现步骤如下:
- 导入Flink和Kafka相关依赖
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
- 创建Flink的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- 创建Kafka数据源,并将数据转换成Tuple2格式
String kafkaTopic = "test-topic";
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(kafkaTopic, new SimpleStringSchema(), properties);
DataStream<Tuple2<String, Integer>> dataStream = env
.addSource(kafkaConsumer)
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] parts = value.split("\\s+");
String timeStr = parts[1];
String city = parts[3];
// 将时间戳转换为分钟
long timestamp = Instant.parse(timeStr).toEpochMilli();
long minute = TimeUnit.MILLISECONDS.toMinutes(timestamp);
out.collect(new Tuple2<>(city + "@" + minute, 1));
}
});
- 使用窗口函数将每分钟数据聚合起来,并且输出结果
dataStream
.keyBy(0)
.timeWindow(Time.minutes(1))
.sum(1)
.map(tuple -> tuple.f0 + "\t" + tuple.f1 + "\t" + "python")
.print();
在上面的代码中,使用keyBy(0)指定了按照城市和时间进行分组,timeWindow(Time.minutes(1))指定了按照1分钟的时间窗口进行聚合,sum(1)指定了对每个窗口内的数据进行求和,最后使用map将结果格式化为指定的输出格式,并输出到标准输出流中。
Q: 同时支持格式“162,2023-03-14 23:05:21.009,江西省,苏州”,标记来源为ruby,标记原来的信息来源为python
A: 如果要同时支持格式为"100 2023-03-14 22:49:45.042050 江西省 潮州"和"162,2023-03-14 23:05:21.009,江西省,苏州",并且要标记来源为"ruby",同时保留原来的信息来源"python",可以在代码中使用一个if语句来判断数据的格式,然后分别处理。以下是修改后的代码:
DataStream<Tuple3<String, Integer, String>> dataStream = env
.addSource(kafkaConsumer)
.flatMap(new FlatMapFunction<String, Tuple3<String, Integer, String>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, Integer, String>> out) {
String[] parts;
String source;
if (value.contains(",")) {
parts = value.split(",");
source = "ruby";
} else {
parts = value.split("\\s+");
source = "python";
}
String timeStr = parts[1];
String city = parts[3];
// 将时间戳转换为分钟
long timestamp = Instant.parse(timeStr).toEpochMilli();
long minute = TimeUnit.MILLISECONDS.toMinutes(timestamp);
out.collect(new Tuple3<>(city + "@" + minute, 1, source));
}
});
这个程序是有问题的,无法执行。恰逢官方升级到 ChatGPT-4,再试。
使用 ChatGPT-4 编写
Q: flink 处理 kafka test-topic 队列的消息,格式为 "100 2023-03-14 22:49:45.042050 江西省 潮州",拆分为时间戳、省份、城市,标记信息来源为python,输出各城市的注册总数
好的,你可以使用 Flink 的 Kafka Consumer API 读取 Kafka 中的消息,并将消息进行解析和处理。以下是一个处理 Kafka 消息的 Flink 应用程序的示例代码:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class KafkaToCityCount {
public static void main(String[] args) throws Exception {
// 设置执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 Kafka Consumer 配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
// 创建一个 Kafka 数据源
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("test-topic", new SimpleStringSchema(), props);
// 从 Kafka 中读取数据
DataStream<String> kafkaStream = env.addSource(kafkaConsumer);
// 解析数据
DataStream<Tuple3<String, String, Integer>> cityCount = kafkaStream.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception {
// 解析每一条消息,将时间戳、省份和城市拆分出来
String[] fields = value.split("\\s+");
if (fields.length == 4) {
String timestamp = fields[1];
String province = fields[2];
String city = fields[3];
// 将城市名和计数值作为输出
out.collect(new Tuple3<>(city, "python", 1));
}
}
});
// 按城市统计注册数
DataStream<Tuple3<String, String, Integer>> cityCountSum = cityCount.keyBy(0).sum(2);
// 输出结果
cityCountSum.print();
// 执行 Flink 程序
env.execute("KafkaToCityCount");
}
}
上述代码将从 Kafka 的 test-topic 队列中读取消息,按照空格拆分消息,将时间戳、省份和城市拆分出来,并将城市名和计数值作为输出。然后将输出的数据按城市进行分组,统计每个城市的注册总数,并将结果打印到控制台上。
在上面的代码中,如果数据包含逗号,则判断为第二种格式,否则判断为第一种格式。然后根据不同的格式选择不同的处理方式,同时使用source变量来记录数据来源。最终将城市和时间的组合、注册数量和来源保存到Tuple3类型中,输出到下一个算子中进行计算。
Q: 将 cityCountSum 数据存入到 kafka 的 result-topic
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
public class KafkaToCityCount {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// kafka consumer 配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test-group");
// 创建 Kafka consumer,从 test-topic 中读取数据
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("test-topic", new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(consumer);
// 对消息进行拆分,获取城市名称
DataStream<Tuple2<String, Integer>> cityCounts = stream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] parts = value.split("\\s+");
if (parts.length < 4) {
// 格式不符合要求,跳过
return;
}
String source = parts[3];
if (!source.equals("python") && !source.equals("ruby")) {
// 不是 python 或 ruby 数据,跳过
return;
}
String city = parts[parts.length - 1];
out.collect(new Tuple2<>(city, 1));
}
});
// 对城市注册数进行求和
DataStream<Tuple2<String, Integer>> cityCountSum = cityCounts.keyBy(0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
});
// 将城市注册数存入 kafka 的 result-topic
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(
"localhost:9092",
"result-topic",
new SimpleStringSchema()
);
cityCountSum.map(cityCount -> cityCount.f0 + "," + cityCount.f1.toString())
.addSink(producer);
env.execute("KafkaToCityCount");
}
}
这里没有想到的是,一天之后的 ChatGPT 对原代码进行了改写,去除了复杂的无用的部分,拆分,然后直接汇总结果。虽然拆分的判断阈值不正确,但思路没毛病。
2.6.2 启用 Flink
# 切换到工作目录
cd ~/utils/flink-1.16.1
# 启动 flink
./bin/start-cluster.sh
2.6.3 启动统计服务
# 建立工程
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.16.0
# 进入工程目录
cd quickstart
# 修改 DataStreamJob.java 文件,粘贴 ChatGPT 生成的代码
# 打包代码生成可执行文件
mvn clean package
# 运行文件
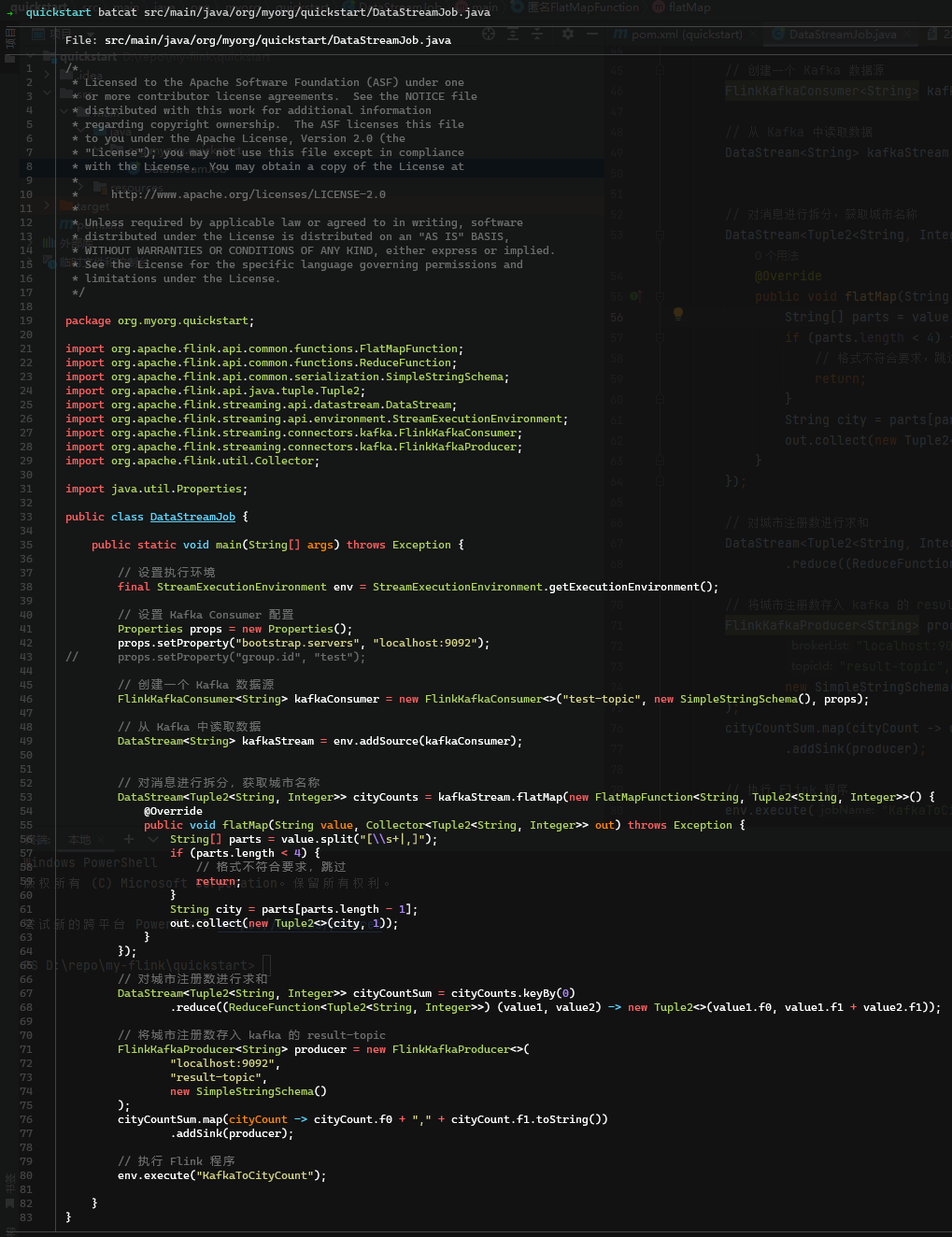
~/utils/flink-1.16.1/bin/flink run target/quickstart-0.1.jar
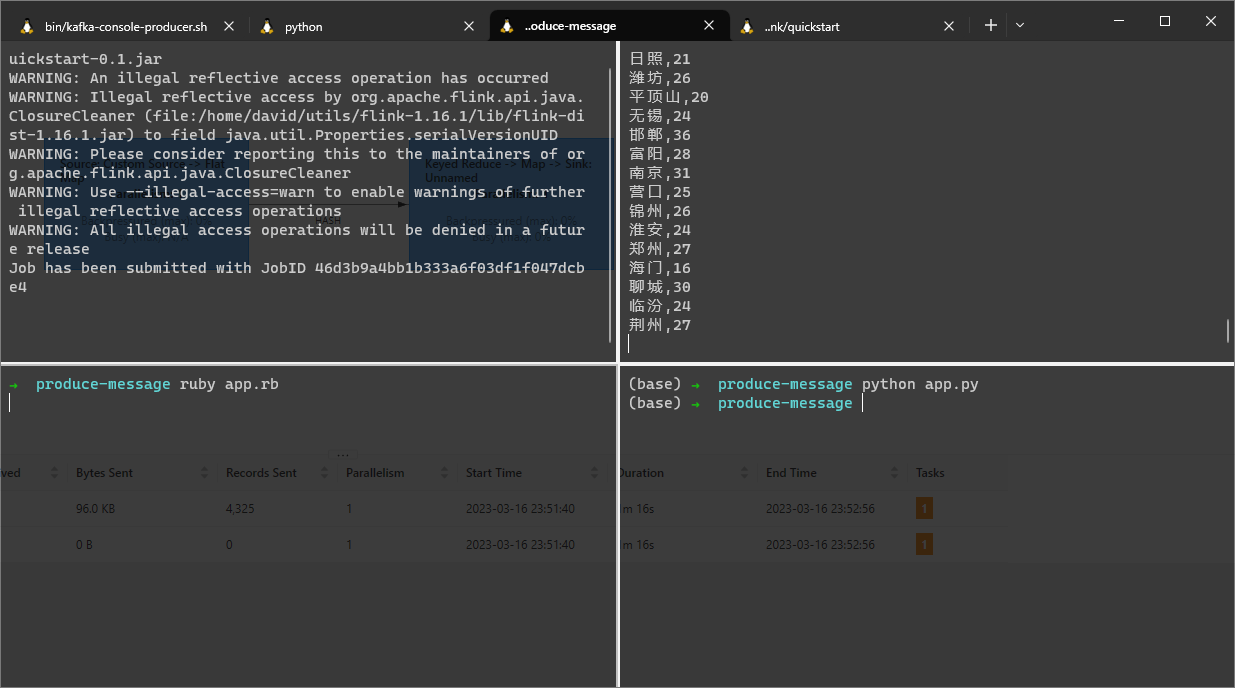
运行后,我们已经可以从图中(右上角)看到 result-topic主题的数据了。
小结
在任务明确、数据内容结构清晰的情况下,ChatGPT 较为轻松的编写出了所需代码,完成了预期任务,但仍有缺点,列举如下:
(1)一次编写不能完成时,后续编写往往是全新的,也可能出现多次编写不能完成的情况。
(2)ChatGPT 4 比 ChatGPT 3更加灵活,“思考”的细节更多,但细节的错漏也多,比如判断性的阈值基本错误。
(3)使用作废 API 现象比较严重,有些无法编译,需要重新编写代码。这对于更新较快的项目不太友好。










