好好学习,天天向上!
一、 AlexNet
1.结构
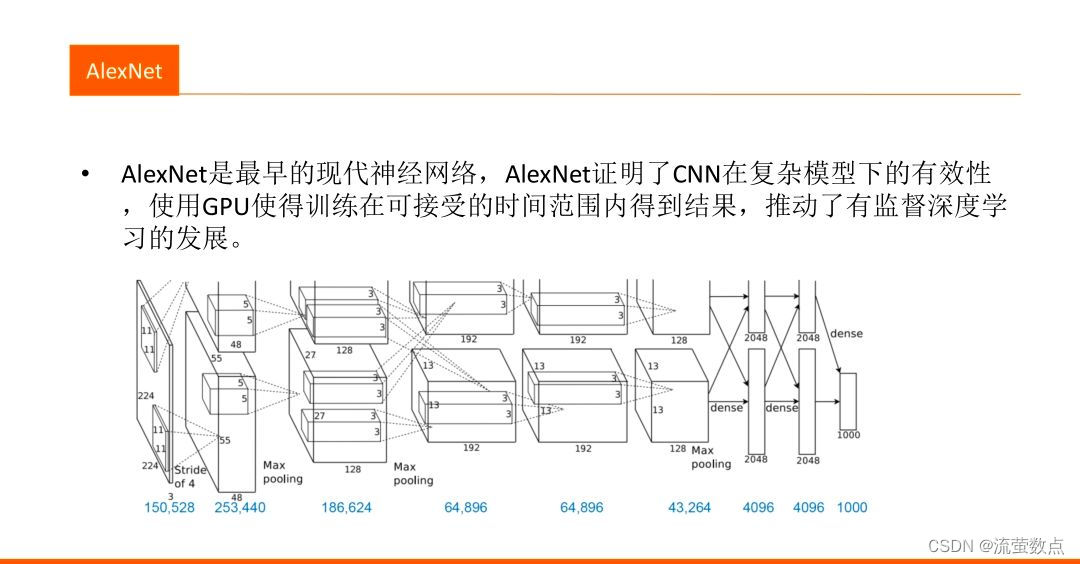
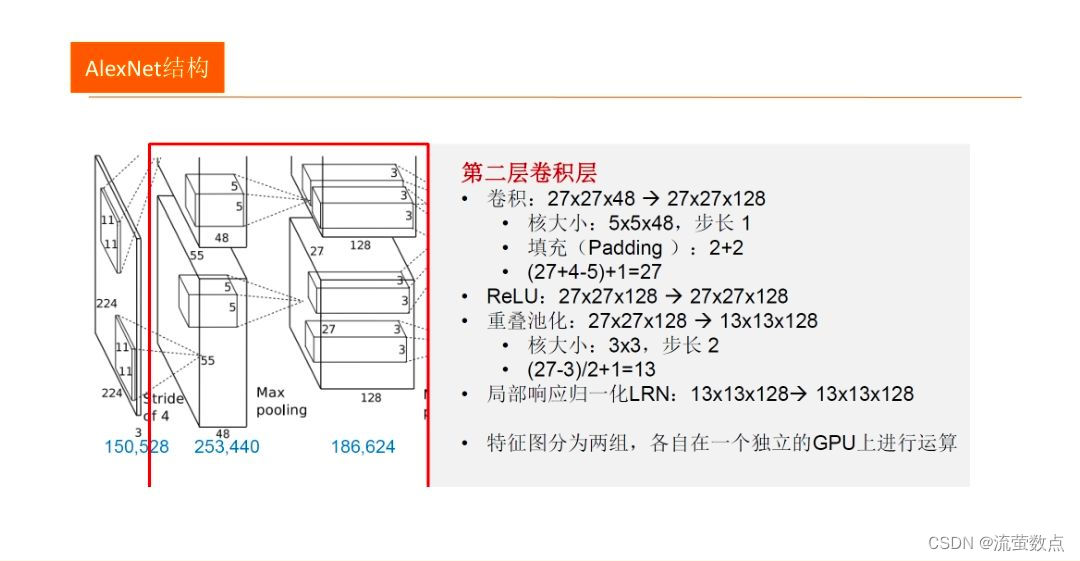
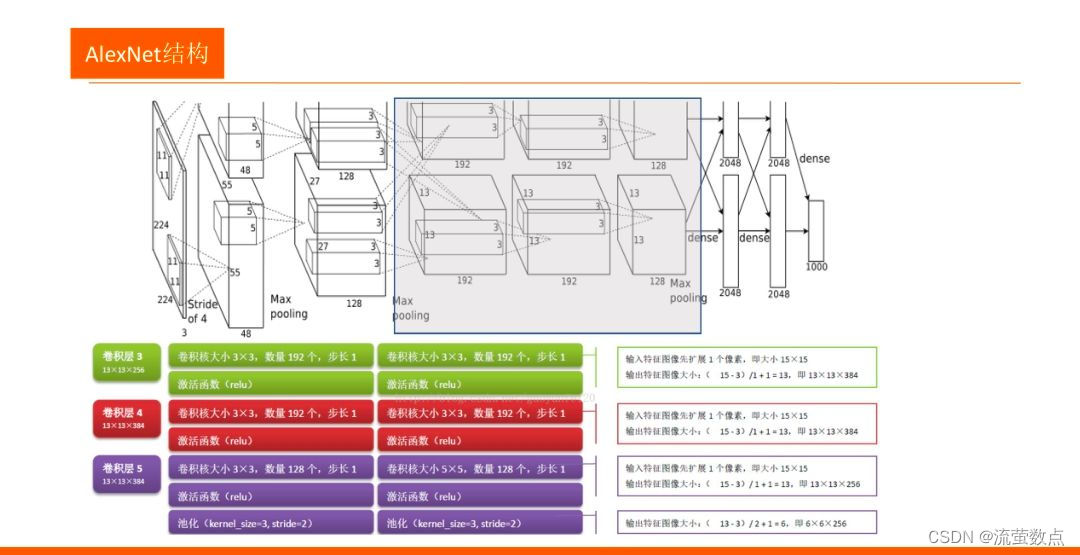
●AlexNet有八个带权层, 前五个是卷积层,剩下三层是全连接层。第一个卷积层利用96个大小为11X11X3、步长为4个像素的核,对大小为224X224X3的输入图像进行卷积。第二个卷积层接收第一个卷积层输出为输入,用5X5X48的核对其进行滤波。第三、四、五个卷积层彼此相连,中间没有池化层。第二、四、五个卷积层的核只连接到前一个卷积层也位于同一GPU中的那些核映射上。第三个卷积层的核被连接到第二个卷积层中的所有核映射上。全连接层中的神经元被连接到前一层中所有的神经元上。响应归一化层跟在第一、第二个卷积层后面。最大化池化层跟在响应归一化层以及第五个卷积层之后。RelU非线性应用于每个卷积层及全连接层的输出。

2.优势
- 采用非线性激活函数ReLU,比饱和函数训练更快,而且保留非线性表达能力,可以训练更深层的网络
- 采用数据增强和Dropout防止过拟合,数据增强采用图像平移和翻转来生成更多的训练图像,Dropout降低了神经元之间互适应关系,被迫学习更为鲁棒的特征
- 采用GPU实现,采用并行化的GPU进行训练,在每个GPU中放置一半核,GPU间的通讯只在某些层进行,采用交叉验证,精确地调整通信量,直到它的计算量可接。受限于当时计算能力,Alexnet使用两块GPU进行训练。
- 在CNN中使用重叠的最大池化(步长小于卷积核)。
- 提出LRN(Local Response Normalization,即局部响应归一化)层,逐渐被BN(Batch Nomalization)所代替。
二、VGG
1.结构

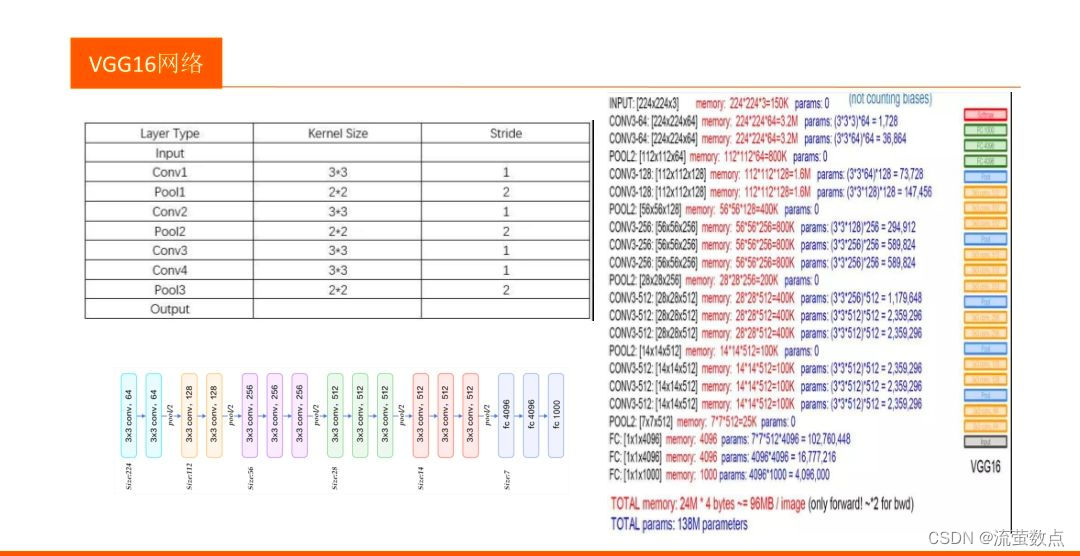
2.优势
- VGG模型以较深的网络结构,较小的卷积核和池化采样域,使得其能够在获得更多图像特征的同时控制参数的个数,避免过多的计算量以及过于复杂的结构。
- 使用了更小的3×3卷积核,和更深的网络。两个3×3卷积核的堆叠相对于5×5卷积核的视野,三个3×3卷积核的堆叠相当于77卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3×3结构只有77结构参数数量的(3×3×3)/(7×7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
- 在VGGNet的卷积结构中,引入1×1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
- 采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
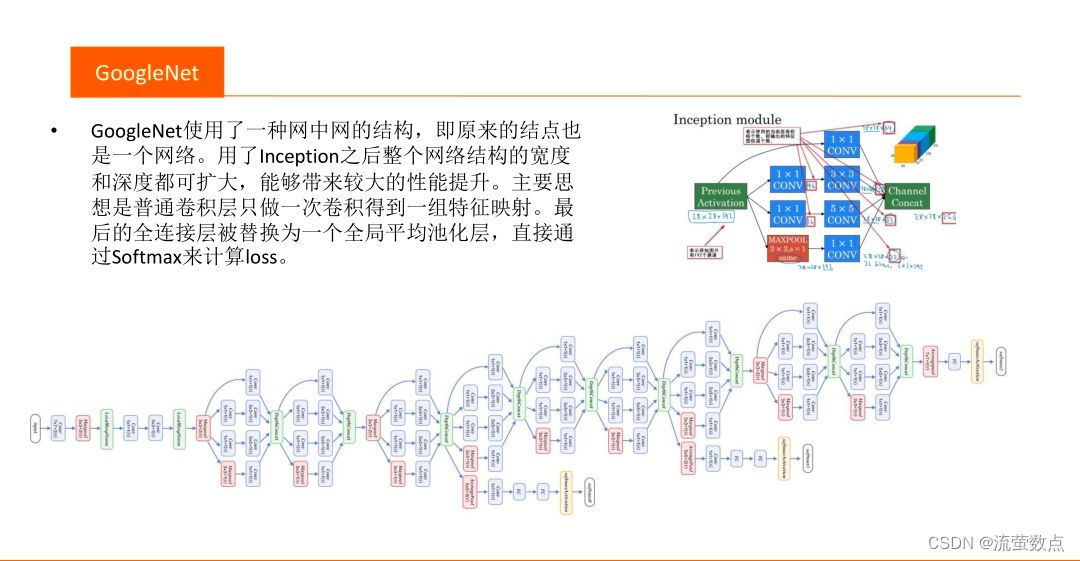
三、GoogLeNet
1.结构
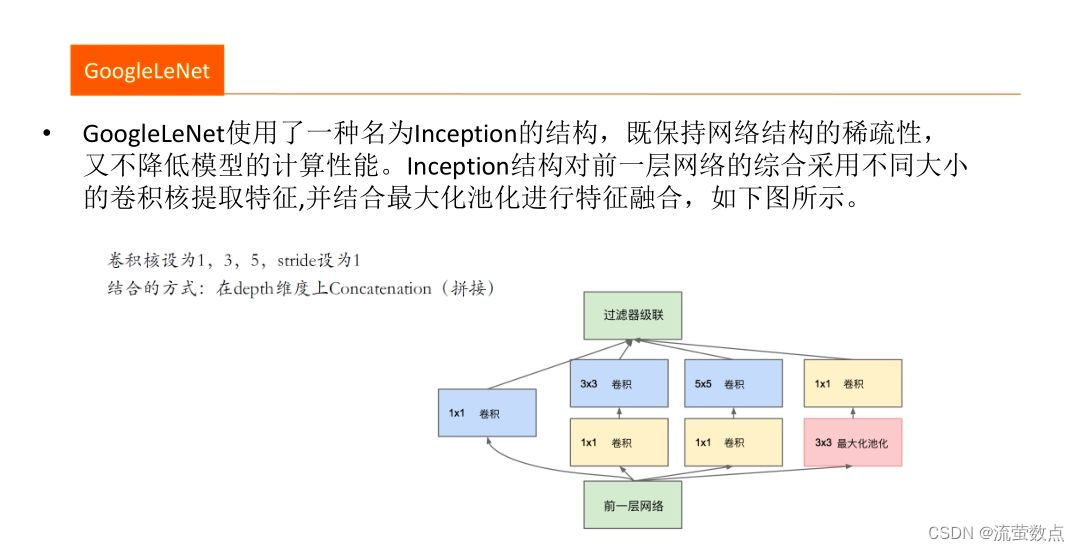
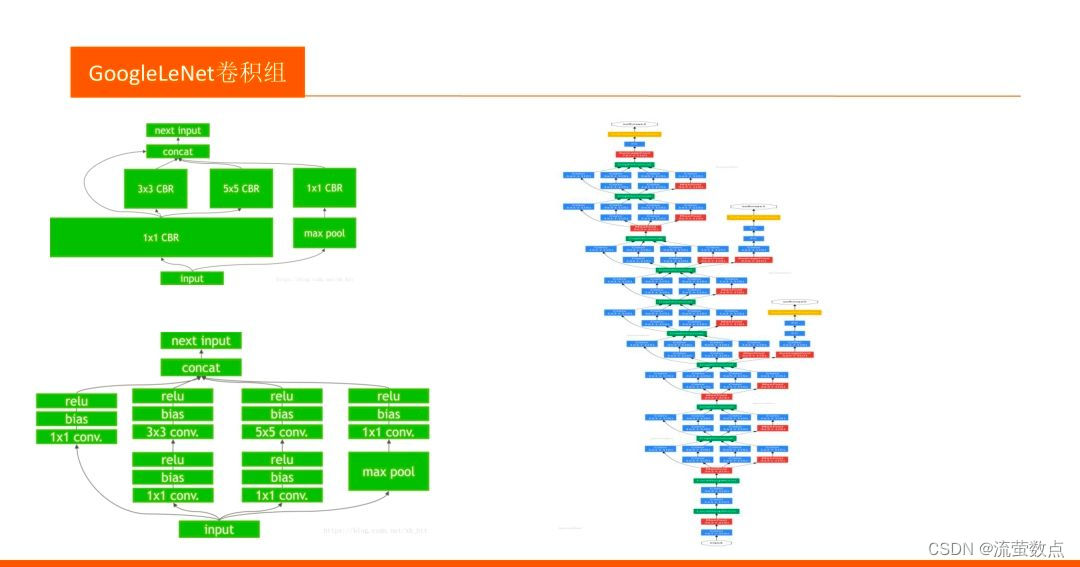
- 假设网络有28*28*192的输入,使用32个5*5*192的卷积核对其进行卷积,那么输出为28*28*32,对于输出中的每一个元素值都要执行5*5*192次计算,卷积的计算量为: 28* 28*32*5*5* 192=120422400。 看看1x1卷积。先用16个1*1*192的卷积核对输入进行卷积,输出尺寸为28* 28*16,再用32个5*5*16的卷积核对其进行卷积,输出为28*28*32。经历两次卷积同样得到28*28*32的输出,第一次 卷积计算量:28 * 28* 16* 192=2408448,第二次卷积计算量28* 28*32*5*5*16=10035200,两次卷积合计计算量约为120万。
2.优势
- 在保证网络性能的情况下极大幅度的节约计算成本
- 提出了Inception结构,这种结构的最大的特点就是提高了计算资源的利用率。虽然GoogLeNet只有22层,但是整个网络的尺寸却比AlexNet和VGGNet小很多。
四、ResNet
1.结构
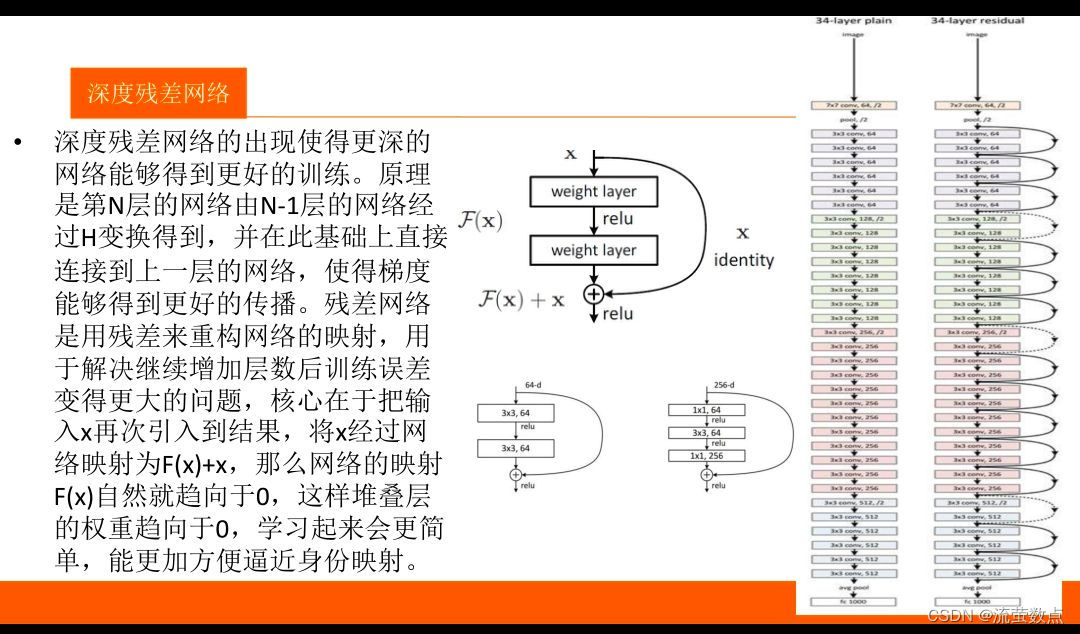
2.优势
- ResNet就解决了网络加深所带来的问题,从而使网络可以加深到更深的层次,即是说我们可以利用到更多的信息。
- 残差结构是为了解决网络退化的问题提出的,梯度消失/爆炸已经通过 normalized initialization 等方式得到解决。
五、DenseNet
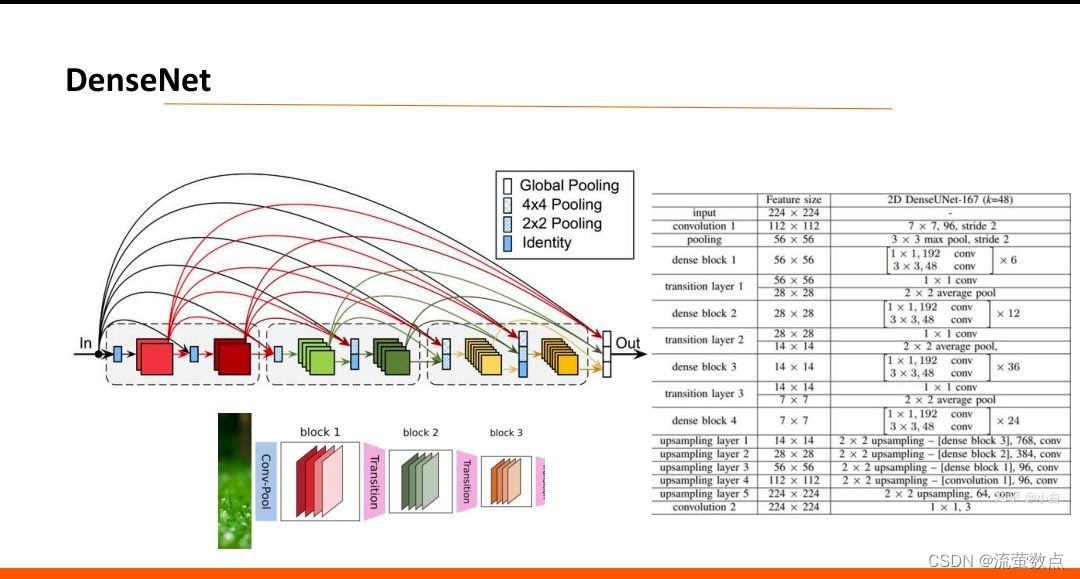
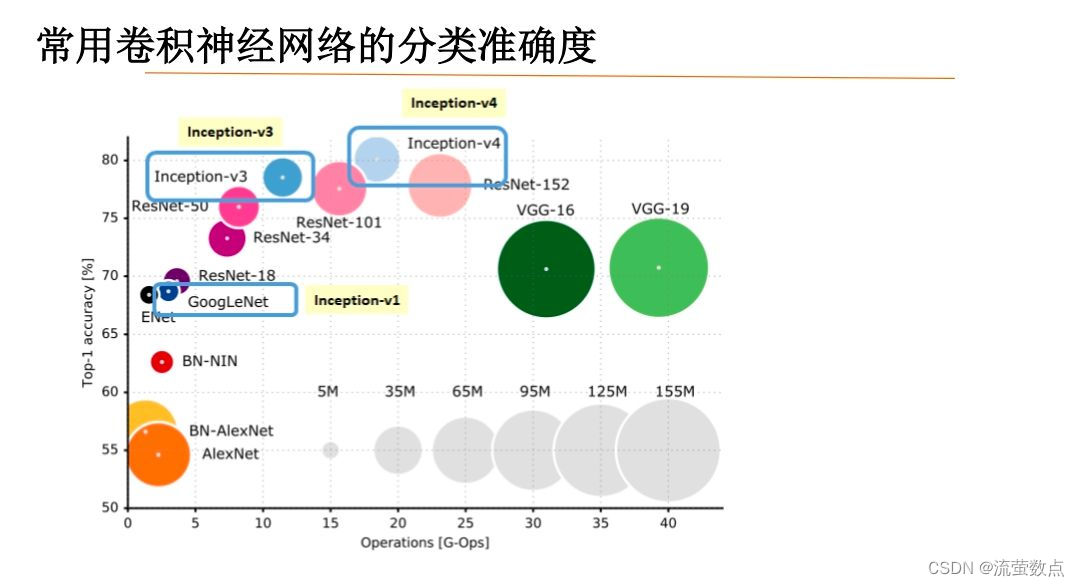
六、模型比较
AlexNet :AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。整个AlexNet有8个需要训练参数的层(不包括池化层和LRN层),前5层为卷积层,后3层为全连接层,AlexNet最后一层是有1000类输出的Softmax层用作分类。
GoogLeNet:该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。使用1x1的卷积块(NIN)来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担。每个池化层之前,增加feature maps, 增加每一层的宽度来增多特征的组合性
VGGNet :VGG的巨大进展是通过依次采用多个3*3卷积,能够模拟出更大的感受野(receptive field)的效果,两个3*3卷积可以模拟出5*5的感受野,三个3*3的卷积可以模拟出7*7的感受野。VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部会连接一个最大池化层用来缩小图片尺寸。每段内的卷积核数量一样,越靠后的段的卷积核数量越多:64 – 128 – 256 – 512 – 512。
ResNet :ResNet声名鹊起的一个很重要的原因是,它提出了残差学习的思想。与普通的CNN相比,ResNet 最大的不同在于 ResNet 有很多的旁路直线将输入直接连到网络后面的层中,使得网络后面的层也可以直接学习残差,这种网络结构成为 shortcut 或 skip connection。这样做解决了传统CNN在信息传递时,或多或少会丢失原始信息的问题,保护数据的完整性,整个网络只需要学习输入、输出差别的一部分,简化了学习的难度和目标。
DenseNet :它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。
MobileNet:MobileNet 的基本单元是深度级可分离卷积(depthwise separable convolution——DSC),其实这种结构之前已经被使用在Inception模型中。从概念上来说,MobileNetV1正试图实现两个基本目标,以构建移动第一计算视觉模型:1,较小的模型,参数数量更少;2,较小的复杂度,运算中乘法和加法更少。遵循这些原则,MobileNet V1 是一个小型,低延迟,低功耗的参数化模型,可以满足各种用例的资源约束。它们可以用于实现:分类,检测,嵌入和分割等功能。
ShuffleNet:新的架构利用两个操作:逐点群卷积(pointwise group convolution)和通道混洗(channel shuffle),与现有先进模型相比在类似的精度下大大降低计算量。在ImageNet和MS COCO上ShuffleNet表现出比其他先进模型的优越性能。
EfficientNet:对于ImageNet历史上的各种网络而言,可以说EfficientNet在效果上实现了碾压。普通人来训练和扩展EfficientNet实在过于昂贵,所以对于我们来说,最好的方法就是迁移学习。









