1. 深度学习奠基作:AlexNet
AlexNet 赢得了2012年ILSVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛,top1 error:36.7%, top5 error:15.4%
当时排名第二的传统机器学习方法SIFT+FVS,top 5 error: 26.2%,且传统机器学习已难以继续提升。
深度学习发展十年后的的今天,imagenet数据集上的SOTA方法:top1准确率:90.940%,top5准确率:99.020%(人top5的准确率:95%)。如今继续在imageNet数据集上刷点已没有太大意义,但另一方面它是一个使用最广泛、质量不错、数据量适中的数据集,如果你的模型在上面取得了不错的效果,那迁移到别的数据集上,效果很可能依然会很不错,所以很多时候仍然用它来评测模型。

网络图放到今天来看依然很复杂,表达了太多的细节,当时作者使用的gtx580内存仅有3GB,单个GPU难以加载整个网络,因此作者花费了大量的时间来设计如何将模型切分到多个GPU上且进行高效训练,随着GPU显存的提高,这项工程技术在随后几年并没有引起太多关注。而近两年随着一些超大模型的提出,如今即使是显存达数十G的GPU也难以加载这些模型,因此这项技术又开始引起关注。
相对于LeNet有哪些创新:
-
首次利用 GPU 进行网络加速训练
-
使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数(求导简单,计算量减小)
-
使用了LRN局部响应归一化(现在已不在使用这项技术,我也不是很清楚这是啥玩意)
-
使用了Dropout,有效减轻过拟合
-
采用了数据增强(随机裁剪、水平翻转)
-
使用了更深的网络:作者经过实验,发现去掉一层卷积层,准确度会降低2%,说明深度是很重要的。(今天来看不能证明深度是最重要的,AlexNet 可以去掉一些层、调节中间参数,效果不变。直接砍掉一层,掉 2% 可能是搜索参数做的不够,没调好参数。深度并不一定越深越好,只是简单堆叠深度,最深的几层可能值过小,容易发生梯度消失,可能导致只有前面几层有用,另外深度与宽度(输入的图片大小)同样重要, 特别深 + 特别窄 or 特别浅 + 特别宽 ❌)
-
证明不使用任何无监督数据做预训练,深度学习也能取得很好的效果(在这之前,神经网络在监督学习上打不过别人,大多数研究都是以从没有标号的数据中抽取特征为主,AlexNet之后,深度学习主流转到了监督学习领域,而近两年随着一些专业数据集的收集困难和成本限制,也越来越多的人开始研究,如何在通用数据集上做无监督预训练,再将模型通过微调迁移到自己收集的更小的数据集上)

证明了不同的卷积核确实是在学习不同的模式
9. 作者发现相似的图片经过卷积神经网络提取出的特征向量(嵌入表示)会比较相似,证明深度学习确实能学到非常好的特征

从网络结构上看,AlexNet与LeNet没有本质上的区别,只是做的更深,层数更多,采用了更大的图片输入(244x244x3),使用了更多的trick,但其中的实验与探讨,都对未来几年的深度学习发展产生了深远的影响。
"""与LeNet实现没有太大区别,补充了如何使用pytorch自定义网络层初始化;使用nn.Sequential()可以将网络层堆叠起来,堆叠起来的层之间进行正向传播不需要在forwad里显式定义,减少代码量 """
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5), # dropout只在训练时使用,验证及预测时不使用
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d): # 如果是卷积层,使用kaiming初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None: # 是否需要bias
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): # 如果是线性层,使用N(0, 0.01)初始化
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
2. VGG
来自于牛津大学VGG组,该网络获得了2014年ILSVRC 亚军,且VGG模型在多个迁移学习任务中的表现要优于googLeNet(2014年ILSVRC 冠军),单纯从图像中提取CNN特征的角度来讲,效果较好,因此今天仍然有些任务会使用该网络。
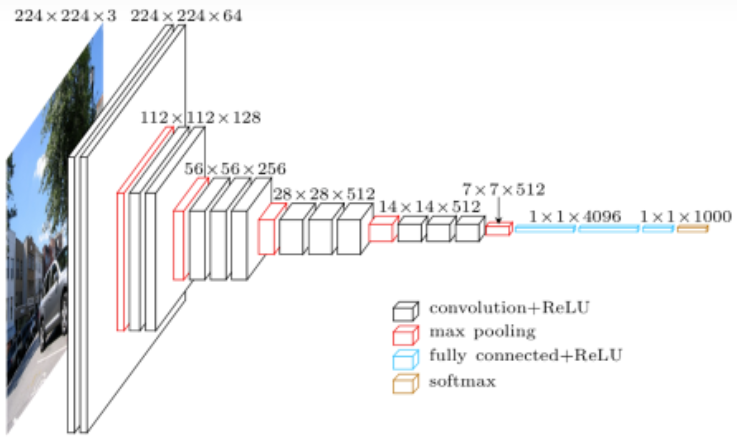
创新点:
-
使用了更多的卷积层,更多地使用3x3卷积核代替5x5卷积核(本质上是更大、更深的AlexNet)
-
采用了模块化设计:将多个卷积层组合成块,多个VGG块后连接全连接层,不同次数的重复块即可得到不同的架构VGG-16、11、19等,网络实现与管理更为方便简洁,有效减少代码量,奠定了今天的网络模型大多分为五个stage的雏形。

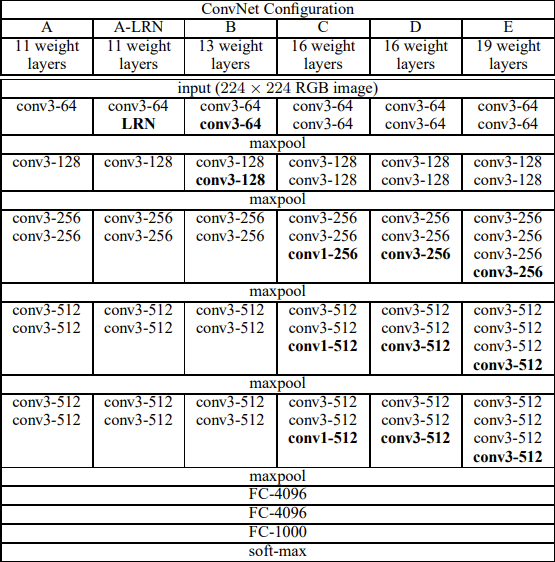
import torch.nn as nn
import torch
# 对应上图编写VGG卷积层部分的配置文件,数字代表对应的卷积层,M代表MaxPool
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# pytorch官方提供的预训练模型
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list): # 传入对应配置的cfg list
# 遍历cfg,如果是数字,则生成对应通道的卷积层,如果是M则生成2x2的Maxpool,最后通过nn.Sequential()堆叠在一起,*layers代表将list拆分为一个个元素后再传入,不加*号,会报错 TypeError: list is not a Module subclass
layers = []
in_channels = 3 # 输入图片为RGB
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
3. GoogleNet
2014年ILSVRC 冠军,想法来自于如何将网络变得更深,解决了什么样大小的卷积核最合适的问题(以前流行的网络使用小到1×1,大到11×11的卷积核,GoogleNet之后大多都使用3x3的卷积核)。在GoogleNet中,基本的基本的卷积块被称为Inception块(Inception block),命名来自于电影《盗梦空间》(Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。
提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合,也会大大增加计算量,因此GoogleNet设想在不提高参数的情况下,增加网络深度

Inception块主要思想:
1.将不同比例的不同卷积核组合可以降低参数数量,从而在相同的参数数量下,可以将网络做的更深。如 64组1x1卷积核、128组3x3卷积核、32组5x5卷积核、32组3x3 max pooling(2:4:1:1)其总体参数数量是要小于直接使用256组3x3的卷积核。
2.有时使用不同大小的卷积核组合是有利的,因为融合了不同尺度的特征信息(多次调参试出来的、大力出奇迹)
创新:
-
设计出Inception块,使得在不增加参数数量的情况下,将网络变得更深
-
同NiN一样使用全局平均汇聚层,在传入全连接层之前,将每个通道的高和宽变成1,大大减少了展平后的参数数量。
-
训练时增加了两个辅助分类器(预测时去掉),使用网络得以更稳定的训练(现在有了更好的训练方法,这个特性或许不是必要的)
GoogleNet有v1、v2、v3、v4多个版本,都大同小异,且都是在ImageNet上调参调出来的,迁移到别的数据集上效果一般,掌握主要思想和代码如何实现即可,不必太在意网络结构,下面根据下面的网络图,对v1版本进行pytorch代码实现
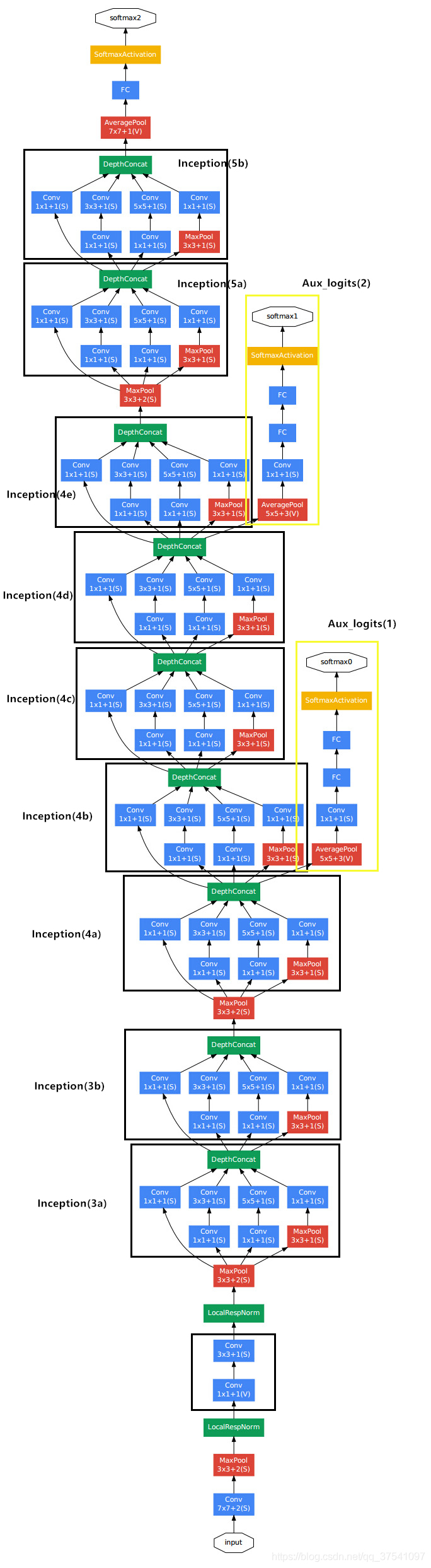
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits # 是否使用辅助分类器,训练时设置True启用,预测时,设置False丢弃
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x) # 通过全局平均池化,将7x7的特征图变为1x1,大大减少了展平后的参数数量
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # 仅训练时使用辅助分类器
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# Inception块
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
# 辅助分类器块
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module): # 最前面一层使用7x7卷积,使得图片大小更快地变小
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x










