2011年年初,美国领英公司(LinkedIn)开源了一款基础架构软件,以奥地利作家弗兰兹·卡夫卡(Franz Kafka)的名字命名,之后LinkedIn将其贡献给Apache基金会,随后该软件于2012年10月成功完成孵化并顺利晋升为Apache顶级项目——这便是大名鼎鼎的ApacheKafka。历经7年发展,2017年11月,Apache Kafka正式演进到1.0时代,本书就是基于1.0.0版本来展开介绍Kafka的设计原理与实战的。
在大数据时代飞速发展的当下,Kafka凭借着其高吞吐低延迟、高压缩性、持久性、可靠性、容错性以及高并发的优势,解决了“在巨大数据下进行准确收集并分析”的难题,也受到了不少大厂以及工程师的青睐,
但是有大部分的人,在学习以及面试的过程中才发现自己并没有完全掌握其奥义,对于常见问题仍旧一知半解,这主要是源码阅读的过程中存在问题
(1)源文件太多,不知道重点;
(2)源码量太大,无数次从开始到放弃;
(3)方法不对,遇到“技巧性”编码就蒙圈;
(4)不够体系化,不会将源文件归类阅读。
下面给大家介绍一份kafka的源码解析笔记。
源码解析
由于本书的篇幅限制,本书并没有详细介绍Kafka源码中涉及的所有基础知识,例如Java NIO、JUC包中工具类的使用、命令行参数解析器的使用等,为方便读者阅读,笔者仅介绍了一些必须且重要的基础知识。在开始源码分析之前,希望读者按照第1章的相关介绍完成Kafka源码环境的搭建,并了解Kafka的核心概念,这样也可以有更好的学习效果。

本书共五章,它们互相之间的联系并不是很强,读者可以从头开始阅读,也可以选择自己感兴趣的章节进行学习。
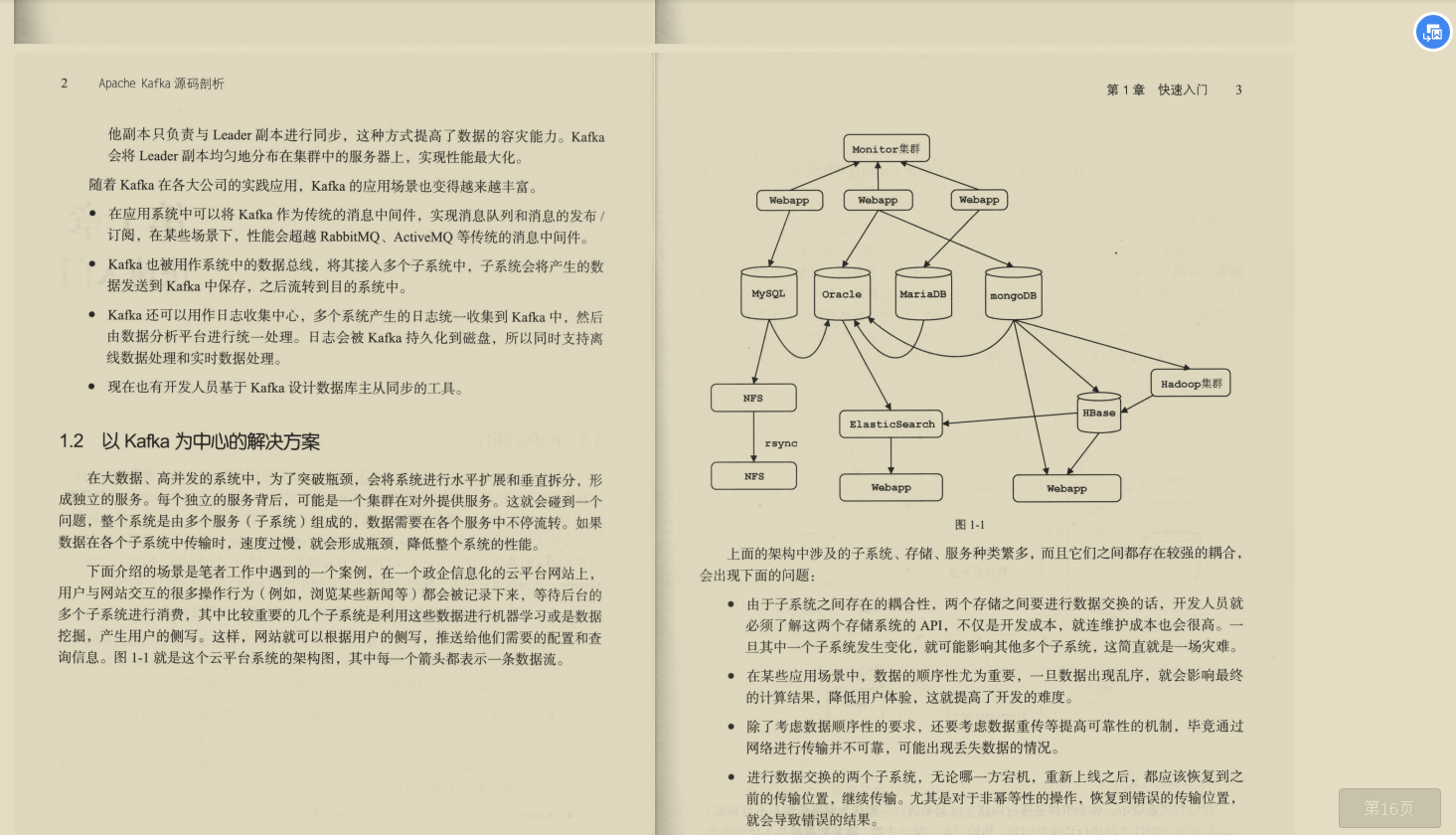
第1章是Kafka的快速入门,其中介绍了Kafka 的背景、特性以及应用场景。之后介绍了笔者在实践中遇到的一个以Kafka为中心的案例,并分析了在此案例中选择使用Kafka的具体原因和Kafka起到的关键作用。最后介绍了Kafka中的核心概念和Kafka源.码调试环境的搭建。
第2章介绍了生产者客户端的设计特点和实现细节,剖析了KafkaProducer拦截消息、序列化消息、路由消息等功能的源码实现,介绍了RecordAccumulator的结构和实现。最后剖析了KafkaProducer 中 Sender线程的源码。
第3章介绍了Kafka的消息传递保证语义并给出了相关的实践建议,还介绍了ConsumerGroup Rebalance操作各个版本方案的原理和弊端。最后详细剖析了KafkaConsumer相关组件的运行原理和实现细节。
第4章介绍了构成Kafka服务端的各个组件,依次分析了Kafka网络层、API层、日志存储、DelayedOperationPurgatory组件、Kafka的副本机制、KafkaController、 GroupCoordinator 、Kafka的身份认证与权限控制以及Kafka 监控相关的实现。本章是Kafka的核心内容,涉及较多的设计细节和编程技巧,希望读者阅读之后有所收获。
第5章介绍了Kafka提供的多个脚本工具的使用以及具体实现原理,了解这些脚本可以帮助管理人员快速完成一些常见的管理、运维、测试功能。
目录


详细展示


kafka实战
本书是涵盖Apache Kafka各方面的具有实践指导意义的工具书和参考书。作者结合典型的使用场景,对Kafka整个技术体系进行了较为全面的讲解,以便读者能够举一反三,直接应用于实践。同时,本书还对Kafka的设计原理及其流式处理组件进行了较深入的探讨,并给出了详实的案例。

本书共分为10章:第1章全面介绍消息引擎系统以及Kaka的基本概念与特性,快速带领读者走进Kafka的世界;第2章简要回顾了Apache Kafka的发展历史;第3章详细介绍了Kafka 集群环境的搭建;第4、5章深入探讨了Kalka 客户端的使用方法;第6章带领读者一览Kaka 内部设计原理;第7-9章以实例的方式讲解了Kalka集群的管理、监控与调优;第10章介绍了Kafka新引入的流式处理组件。
适应人群
本书适合所有对云计算、大数据处理感兴趣的技术人员阅读,尤其适合对消息引擎、流式处理技术及框架感兴趣的技术人员参考阅读。
Kafka线上环境部署

producer开发\consumer开发

Kafka设计原理、管理Kafka集群、监控Kafka集群、调优Kafka集群


Kafka Connect与Kafka Streams











