目录
广播残差网络块(BC-ResNet块(BC-ResNet Block))
广播残差学习用于有效的关键词识别
摘要
关键词识别是一个重要的研究领域,因为它在智能设备上的设备唤醒和用户交互中起着关键作用。然而,在移动电话等资源有限的设备中高效运行的同时,将错误最小化是一个挑战。
我们提出了一种广播残差学习方法,以较小的模型尺寸和计算量实现高精度。我们的方法将大多数残差函数配置为1D时间卷积,同时仍然允许使用广播残差连接将时间输出扩展到频率-时间维度,将2D卷积一起。
与传统的卷积神经网络相比,这种残差映射使网络能够以更少的计算量有效地表示有用的音频特征。我们还提出了一种基于广播残差学习的新型网络结构,即广播残差网络(BC-ResNet),并描述了如何根据目标设备的资源来扩展模型。
BC-ResNets在Google语音命令数据集v1和v2上分别达到了最先进的98.0%和98.7%的top-1精度,并且使用更少的计算和参数,始终优于以前的方法。
研究内容
对于旨在检测预定义关键字的关键字识别(KWS),网络效率至关重要,因为它通常在边缘设备中执行,同时要求低延迟。
最近高效的CNN[1,2,3,4]通常由相同结构的重复块组成,并基于残差学习[5]和深度可分离卷积[6]。这种趋势在基于CNN的KWS方法中仍在存在,它们使用1D时间或2D频率×时间卷积,各有利弊。
我们提出了广播残差学习,允许1D和2D特征结合在一起。广播残差学习重复平均2D特征到1D特征,并将1D特征扩展回2D。
即:2D特征上执行频率卷积。然后对二维特征进行频率平均,得到时间特征1D。经过一些时间计算后,我们可以通过广播1D残差信息将残差映射应用到输入的2D特征。
这种学习方法能够在频率方向上进行卷积处理,以获得2D CNN的优势,同时最小化计算成本。基于这种残差学习方法,我们提出了一种新的网络——广播残差网络。
提出的方法&模型架构
首先,我们定义了广播残差学习,并描述了一种新的网络结构,广播残差网络(BC-ResNet)。接下来,我们将通过通道缩放介绍一系列模型BC-ResNets。
广播残差学习
典型的残差块(residual block)[5]可以表示为 y = x + f(x),其中x和y是输入和输出特征,函数f计算残差。在这里,恒等式快捷键(identity shortcut) x和残差f ( x )通常在同一维度上,并通过简单的加法求和。
为了同时利用一维和二维特征,我们将函数f分解为f1和f2,分别是时间一维运算和二维运算。我们对f2之后的二维特征进行频率平均,以获得时间特征,并将时间特征扩展回f1之后的二维形状。我们反复对每个残差块进行平均和扩展,并提出广播残差学习。广播残差学习使另一种形式的残差块,
y = x + BC ( f1 ( avgpool ( f2 ( x ) ) ) ), (1)
如左图2所示,其中BC(广播)表示将计算扩展到频率维度,avgpool表示按频率维度划分的平均池。通过这种方式,广播残差学习扩展并向 恒等式快捷键x的更大维度 添加残差信息。
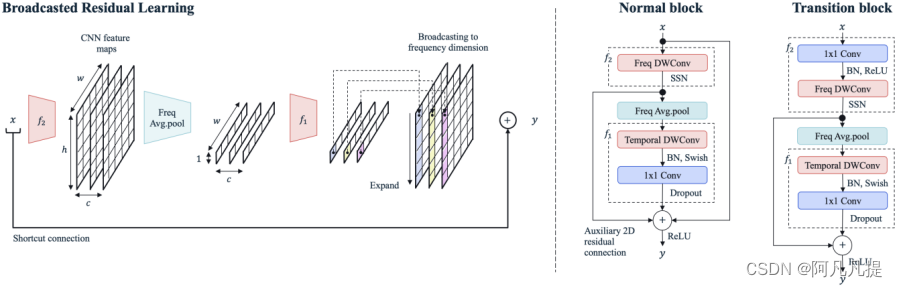
图2:左侧,方程式1中描述的广播残差学习,其中x ∈ Rc×h×w,带有通道数c。右侧,BC-ResBlock。BC-ResNet块包含一个具有子频谱归一化BN的频率深度卷积。然后对特征进行频率平均,然后进行时间深度可分离卷积。在残差连接处,时间特征被广播到2D特征。在一个过渡块(transition block)中,我们在前面有一个额外的1 x1卷积,以改变没有恒等式快捷键(identity shortcut)的通道数。
广播残差网络块(BC-ResNet块(BC-ResNet Block))
整体架构如图2所示。在方程1中,为了清晰起见,我们忽略了批次和通道维度,输入特征x是Rh×w,其中h和w分别对应于频率和时间维度。2D特征部分f2由3x1频率深度卷积和子频谱归一化(SSN)[13]组成,它将输入频率分成多个组,分别对它们进行归一化。在这里,我们使用SSN代替批量归一化(BN)[14]来实现频率感知的时间特征。频率平均后,我们得到R1×w的特征。f1是由1x3时间深度卷积、BN、swish激活[15]、1x1逐点卷积和信道dropout率p组成。广播(BC)操作将R1×w中的特征扩展为Rh×w.。
为了在块上感知频率卷积,我们从2D特征中添加了一个辅助2D残差连接。综上所述,所提出的BC-ResBlock(广播残差块)变为
y = x + f2 ( x ) + BC ( f1 ( avgpool ( f2 ( x ) ) ) ). (2)
我们还定义了一个带有两个额外修改的过渡块(transition block)(其中输入/输出通道的数量不同);
(a)添加逐点卷积,其中通道发生变化,随后BN和ReLU激活。(b) 没有恒等式快捷键x。
使用所提出的块,我们可以在保持二维特征的同时实现高效的KWS设计。在一个小型网络中,逐点卷积的计算量最大[3]。与二维深度可分离卷积相比,我们对时间特征执行时间深度卷积和逐点卷积,并将它们的计算量减少了h倍。
网络体系结构:广播残差网络(BC ResNet)
我们设计了基础模型BC-ResNet-1,参数小于10k,如表1所示。该模型前面有一个5x5卷积,用于按频率进行下采样,然后是总共12个BC-ResBlocks。我们将这些区块分为四个阶段,代表一系列BC-ResBlocks,其激活宽度相同。受[4]的启发,我们探索了几种选择,并得到了每个阶段的组合、2、2、4和4个块,这意味着模型更注重执行高级(high-level)特征。如果通道宽度c与输入宽度不同,则一个阶段的第一个块是过渡块,如右图2所示。为了进行残差学习,我们通过对每个深度卷积使用零填充来保持频率和时间维度。在BC-ResBlocks之后,有一个5x5深度卷积,在频率维度上没有零填充,然后是一个逐点卷积,在平均池之前增加通道数。在这里,我们添加5x5深度卷积,以减少其背后的逐点卷积的计算。

表1:BC-ResNet-1。每一行是一个或多个相同模块的序列,重复n次,输入形状为通道×频率×时间,总时间步长W,输出通道数c。通道数的变化和步幅s的下采样属于每个BC-ResBlocks序列的第一个块。所有BC-Resblocks中的时间卷积都使用d的扩展。
许多基于CNN的KWS方法使用扩展的卷积来获得所需的感受野[10,11,9],并且提出的BC ResNet也使用扩展的卷积。我们经验发现,保持时间维度是有益的。因此,我们在频率方向上使用了步幅s,在时间维度上使用了扩展d。
模型缩放
之前的KWS作品通常通过同时改变深度和宽度来缩放模型[7,9,8],这使得很难适应每个计算或内存约束。我们探索了混合[4],仅深度和仅宽度缩放,并决定通过增加通道宽度τ时间来扩展基本模型BC-ResNet-1,以获得BC-ResNet-τ。因此,该模型易于使用任何预定义的资源进行扩展。
文章贡献
(1) 我们引入了一个全新的框架,称为广播残差学习,它利用了一维时间和二维卷积的优点,同时最小化了计算量的增加。
(2) 我们提出了一种新的基于广播残差学习的模型体系结构BC-ResNet,并通过增加模型宽度获得了一系列网络BC-ResNets。
(3) 综合实验表明,我们的方法在关键词识别方面是有效的,我们的模型在减少模型参数和计算量的同时达到了最先进的精度。
数据集
我们在Google语音命令数据集v1和v2[12]上评估了所提出的BCResnet的性能。
版本1包含1881名说话者的64727句话。共有30个单词,我们使用了10个类别的“是”、“否”、“向上”、“向下”、“左”、“右”、“开”、“关”、“停”和“走”,另外两个类别的“未知单词(其余20个单词)”和“沉默(未检测到语音)”遵循[12]的设置。版本2共有2618人发表105829次演讲。
版本2共有35个单词,分为12类。每个语音的长度为1秒,采样率为16 kHz。
我们根据验证和测试文件列表将数据集划分为训练集、验证集和测试集[12]。我们根据[12,10,20]的常见设置,将“未知单词”和“沉默”与残差十个类别中的平均话语数重新平衡,尤其是我们使用谷歌语音命令数据集提供的标准测试集v1和v2。
结果
广播残差学习的影响
我们将BC-ResNet与完全1D(ResNet-1D)和完全2D(ResNet-2D)模型进行比较,以验证我们方法的有效性。这些模型由具有深度可分离卷积的残差块组成,而不是BC-ResBlock,同时保持BC-ResNet的基本网络结构。ResNet-2D使用3 x 3卷积核的深度可分离卷积,ResNet-1D使用1 x 3卷积核。ResNet-1D需要在相同宽度下进行1.1M的乘法累加(MAC)操作,这比BC-ResNet-1小,因此我们将模型的宽度扩大了一倍,以进行公平比较。表2显示了这些基线和我们的方法的比较结果。
ResNet-1D的参数大约是我们方法的三倍,但其精确度仍比我们的方法低1%以上。通过在深度卷积和逐点卷积之间使用批量归一化(batch normalization)(BN),ResNet-2D的参数比BC-ResNet少约16%,并且由于2D操作较多,它需要更高的计算量。这个2D模型的精确度比我们的方法低2%。当我们将SSN应用于ResNet-2D而非BN、ResNet-2D w/SSN时,模型大小与BC-ResNet-1相似,并且在不增加计算量的情况下,可以获得0.7%的精度改进提高。这一结果表明,即使在二维CNN中,我们也可以有效地应用SSN。 结果表明,广播残差学习减少了计算量,在关键词识别中可以代表更多的鉴别信息。
BC-ResNet-Attn表示使用注意力而不是广播残差映射的模型,如[26,27]。将Sigmoid应用于方程式2的f1,然后执行元素级乘法。它可以被认为是时间通道注意,因为f1的输出是一个时间特征。该模型的性能优于1D和2D基线,但BC-ResNet的精度仍高于0.6%。
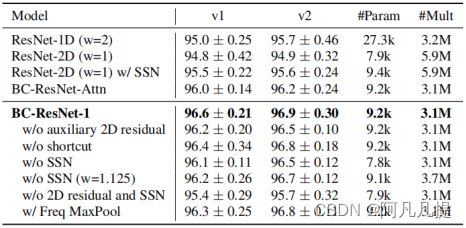
表2:广播残差学习和消融研究的影响。我们将在Google语音命令数据集v1和v2上演示每个组件如何影响基本模型BC-ResNet-1。我们展示了Top-1测试准确度(%)的平均值和标准偏差。(平均超过5粒种子)。
BC-Resblock的消融研究
广播残差学习在BCResNet中起着至关重要的作用,但BCResBlock由其他核心组件组成;辅助2D残差连接和SSN,用于BC-ResBlocks的频率感知。我们评估这些组件如何影响模型的性能。无辅助2D残差的BC-ResNet显示了准确的结果。然而,通过这种额外的连接,BC-ResNet可以在不增加模型大小的情况下获得约0.4%的性能改进。恒等式的快捷键连接对性能也有轻微影响。
“w/o SSN”显示了在BCResBlock中使用BN而不是SSN时的结果,这消除了频率间的失真,并提供了频率感知。我们可以通过移除SSN来减少一些参数,但会出现超过0.4%的精度下降。我们还比较了使用基本通道9,‘w/o SSN(w=1.125)’的模型,以补偿BN造成的参数损失。该模型需要大约20%的计算量,但性能仍低于BC ResNet。‘w/o 2D residual and SSN’ 是在BC-ResBlock中不使用2D残差和SSN的模型。由于消除了频率维度,这两个组件有助于减少信息损失。与逐个删除它们相比,删除所有它们会更显著地增加错误。这些结果表明,这两个组成部分在广播残差学习中起着至关重要的作用。我们还评估了模型“w/Freq MaxPool”,它使用最大池作为频率降维方法,而不是平均池。该模型记录的精度略低于BC-ResNet-1。然而,它仍然显示出比完全一维和二维模型更高的精度。这意味着广播残差学习可以与其他频率降维特征一起有效。
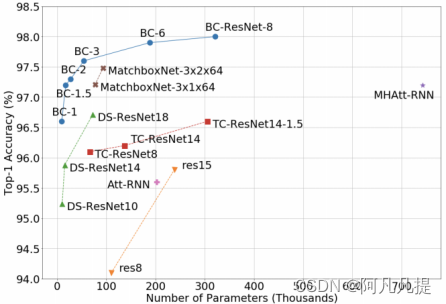
图1:模型尺寸与谷歌语音命令数据集v1测试精度。建议的BC Resnet显著优于其他KWS方法。最小的BC-ResNet-1在小于10k的参数下达到96.6%的精度。我们将BC-ResNet-1按通道宽度缩放8倍,BC-ResNet-8达到最先进的98.0%。详情见表3。
与基线比较
我们从两个方面比较了KWS模型的效率:每个参数的性能和每个MAC的性能。在图1中,就谷歌语音命令数据集v1的每个参数的准确性而言,BC-ResNets始终比其他方法有效。我们还比较了数据集v2上的MAC精度曲线,如图3所示。BC-Resnet比基于1D的MatchBoxNets[9]和最先进的MHAtt-RNN[20]实现了更高的精度,同时计算量更小。在MatchboxNet的情况下,与表3中的v2结果相比,数据集v1的效率更高,但BC-ResNets需要x 2.6个更少的参数,同时实现更高的精度。

图3:MACs vs. 谷歌语音命令数据集v2的准确性。详情见表3。

表3:BC-ResNets在谷歌语音命令数据集v1和v2上的测试准确率(%)。在第4.3节中,每个BC-ResNet都按τ系数放大,KWS方法按精度分组,以便于比较。
具体数字见表3。我们得到了BC-ResNets在10个随机种子(random seeds )中的平均性能。最小的模型BC-ResNet-1与基于1D卷积的方法TC-ResNet14-1.5[7]和TENENE12[8]的性能相匹配,参数数量减少了x 10.9,同时使用了1D方法级别的倍数。BC-ResNet-3比最先进的方法MHAtt RNN[20]工作得更好,参数数量为x 13.7。最大的模型在谷歌语音命令数据集v1和v2上达到了最先进的精度,分别为98.0%和98.7%,仍然比MHAtt-RNN[20]小x 2.3。
总结
现有的基于CNN的KWS方法通常通过1D或2D卷积处理所有特征,并考虑其优缺点。
使用一维卷积可以在参数数量和计算量方面实现高效设计,但它缺乏诸如频率方向上的平移等特性。
另一方面,与一维方法相比,二维卷积需要更多的计算。
为了解决这些问题,我们提出了广播残差学习,允许1D和2D特征结合在一起。广播残差学习重复平均2D特征到1D特征,并将1D特征扩展回2D。
利用广播残差学习和简单的宽度缩放,我们设计了一系列名为BC-ResNets的网络,并在Google语音命令数据集v1和v2上超越了最先进的技术。









