练习4-Apply函数
探索1960 - 2014 美国犯罪数据

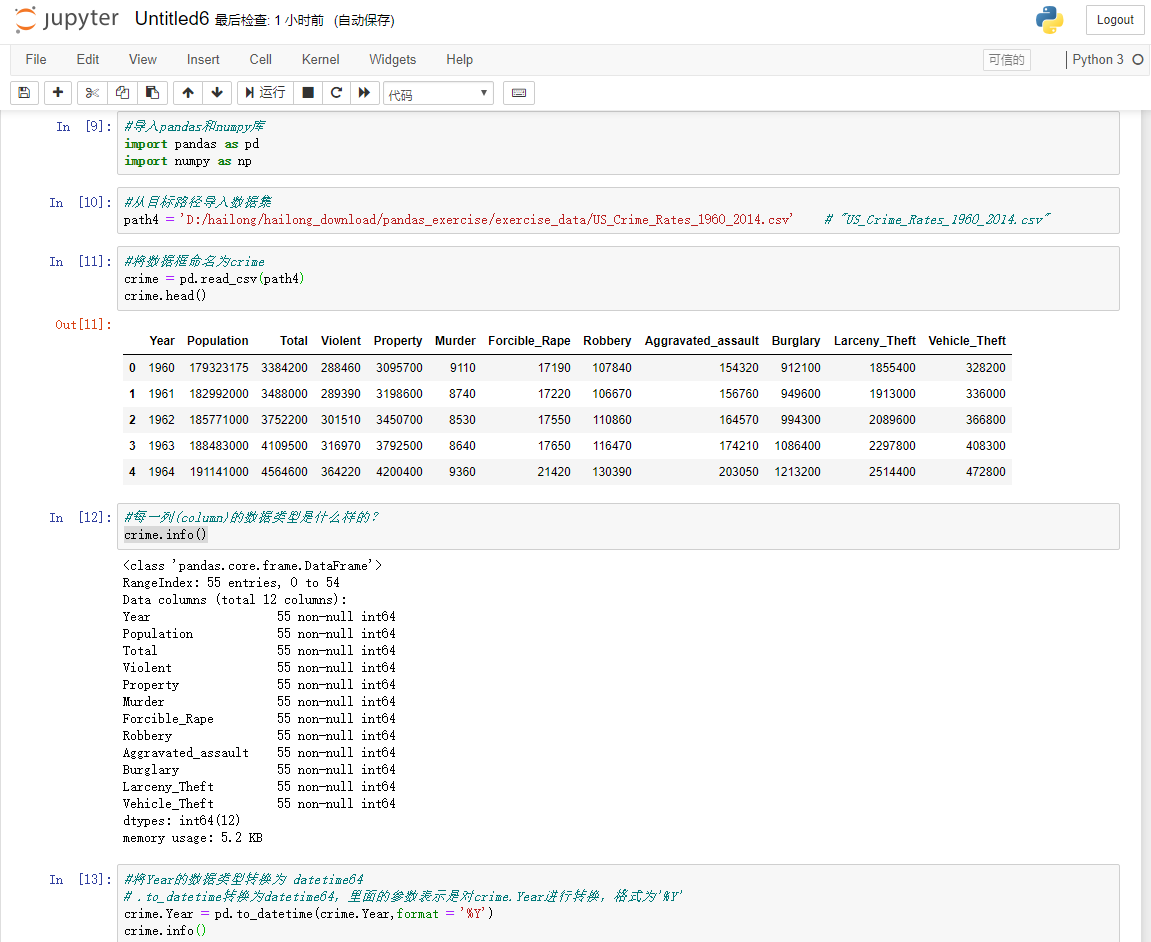
步骤1 导入必要的库
运行以下代码
import pandas as pd
import numpy as np
步骤2 从以下地址导入数据集
运行以下代码
# 本地对应的"US_Crime_Rates_1960_2014.csv"路径
path4 = 'D:/hailong/hailong_download/pandas_exercise/exercise_data/US_Crime_Rates_1960_2014.csv'
步骤3 将数据框命名为crime
运行以下代码
crime=pd.read_csv(path4)
crime.head()
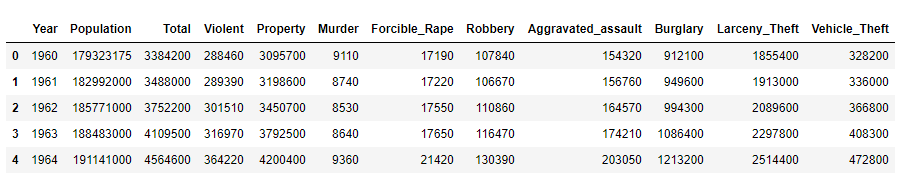
步骤4 每一列(column)的数据类型是什么样的?
运行以下代码
crime.info()
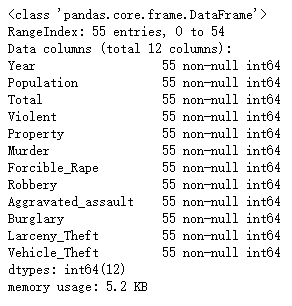
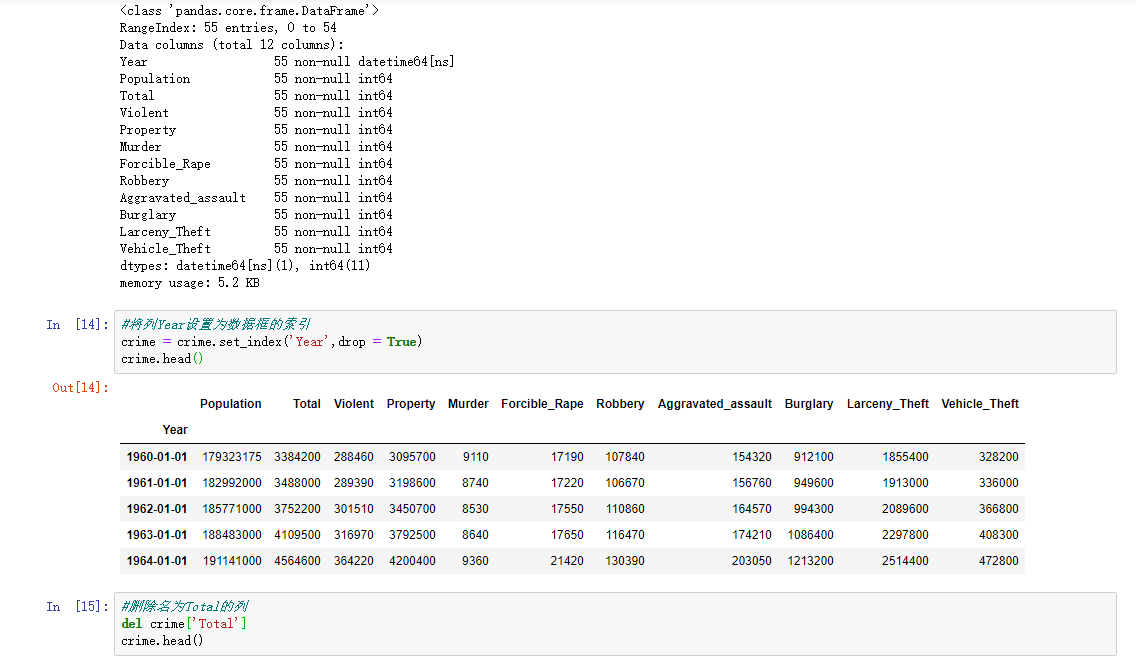
注意到了吗,此时Year的数据类型为 int64,但是pandas有一个不同的数据类型去处理时间序列(time series),我们现在来看看。
步骤5 将Year的数据类型转换为 datetime64
运行以下代码
crime.Year = pd.to_datetime(crime.Year,format = '%Y')
crime.info()

步骤6 将列Year设置为数据框的索引
运行以下代码
crime = crime.set_index('Year',drop = True)
crime.head()

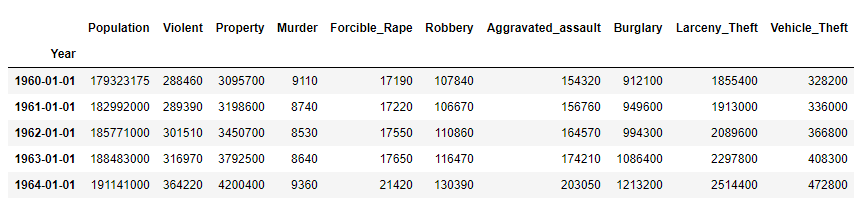
步骤7 删除名为Total的列
运行以下代码
del crime['Total']
crime.head()
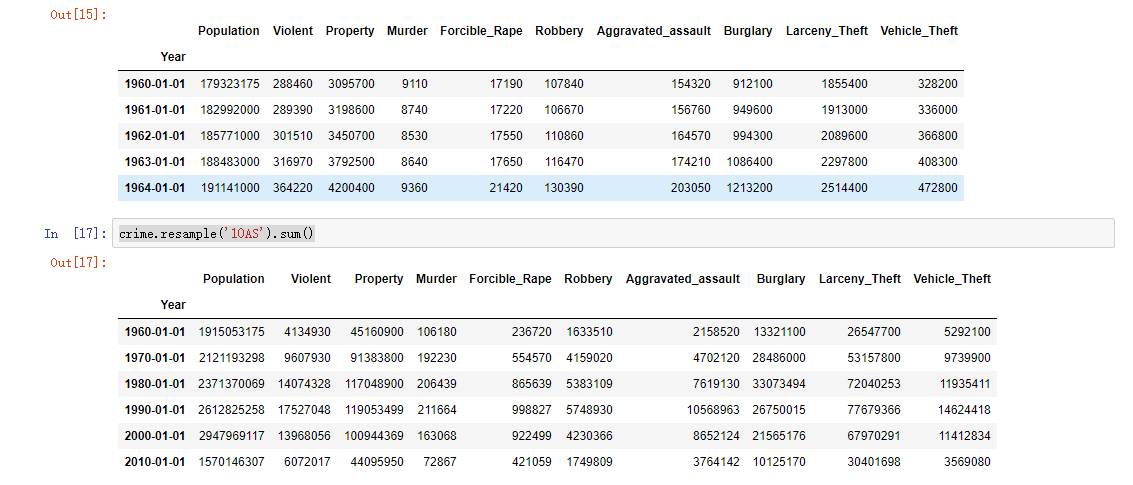
crime.resample('10AS').sum()
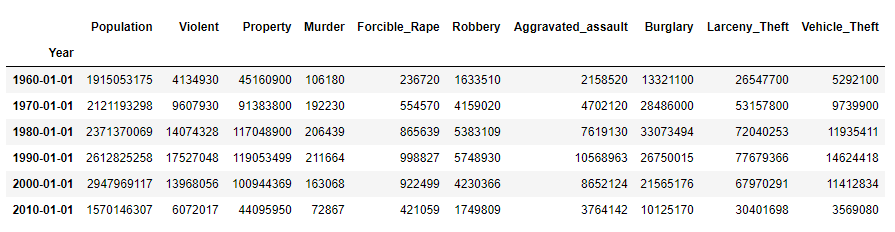
步骤8 按照Year对数据框进行分组并求和
*注意Population这一列,若直接对其求和,是不正确的**
运行以下代码
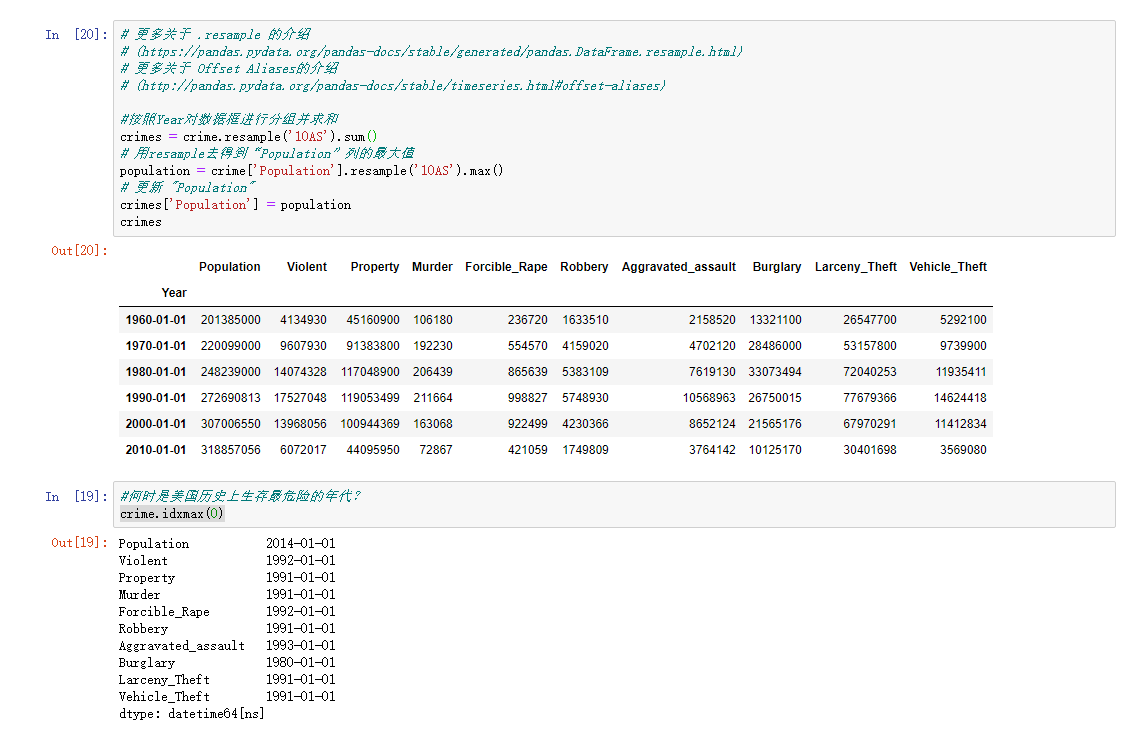
# 更多关于 .resample 的介绍
# (https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.resample.html)
# 更多关于 Offset Aliases的介绍
# (http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases)
crimes = crime.resample('10AS').sum()
population = crime['Population'].resample('10AS').max()
crimes['Population'] = population
crimes
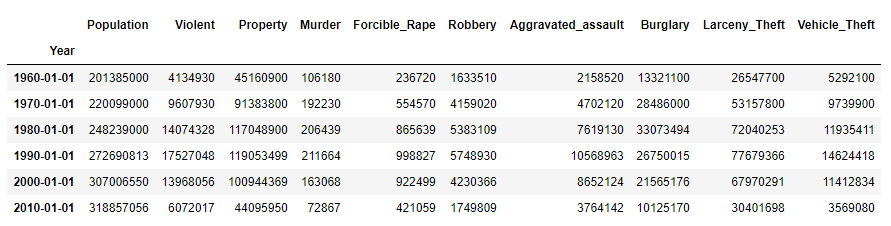
步骤9 何时是美国历史上生存最危险的年代?
运行以下代码
crime.idxmax(0)
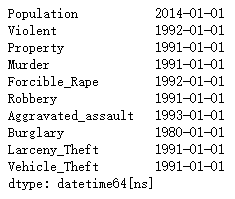
代码截图